CVPR2023 |
您所在的位置:网站首页 › imagenet预训练权重 › CVPR2023 |
CVPR2023
 论文链接:https://arxiv.org/pdf/2303.11331.pdf 开源代码:https://github.com/baaivision/EVA/ 引言 视觉预训练在视觉领域一直发挥着重要作用,尤其是在一些小样本任务上,一个好的预训练权重可以降低训练难度的同时显著提升任务性能。而最常用的视觉预训练权重来自ImageNet 1K图像分类数据集上训练的模型,因此从ImageNet数据集发布以来,视觉领域学者一直在提升模型在该数据集上的识别精度。 问题背景 而仅依靠ImageNet 1K上的有监督学习很难再提升精度,伴随着无监督和自监督学习方法的快速发展,大家发现使用一些自监督学习方法进行预训练能够进一步提升ImageNet 1K上的精度,继而也能提升视觉下游检测,分割等任务的指标。在这些方法中,风靡一时的莫过于适用于视觉Transformer结构的MIM自监督方法,如BEIT[1],MAE[2],BEIT v2[3], BEIT v3[3]等。  图1:经典MIM自监督方法 图1:经典MIM自监督方法EVA[4]是智源去年基于MVP以及BEIT V2提出的用多模态视觉Encoder作为Teacher来进行MIM蒸馏的一篇论文,EVA v1发布时就超过了BEIT V3,取得了视觉领域的多项SOTA。而最近,智源基于自训练的更大多模态Encoder作为Teacher,更新了EVA-2,在ViT Large 的结构上ImageNet精度达到90.0。同时,作为超越BEIT V3的新型多边形战士,更是将视觉等多项领域的任务刷爆了! 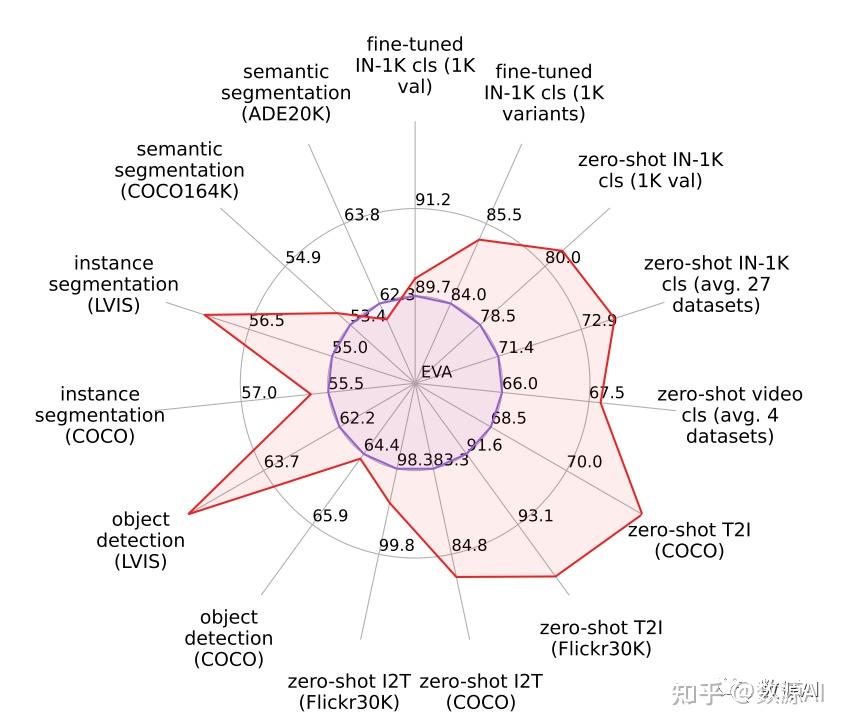 图2:EVA 2在各项任务上的性能指标 图2:EVA 2在各项任务上的性能指标模型结构 视觉Trnasformer结构由于其最小的视觉结构prior 和biases,以及它与基于掩码建模策略的天然兼容性,被证明是一种简单强大且可以scale的模型。但是原始ViT从2020年以来并未有过太多结构上的变化,尤其是借鉴一些Transformer在NLP领域上的改进。 论文通过实验发现原始ViT base规模在论文策略下出现性能下降,因此对原始ViT做了如下改进(借鉴NLP上的一些改进Tricks): gated linear unitwith sigmoid linear unit (SiLU) / swich activation (SwiGLU) as the feedforward networksub-LN as the normalization layer2D rotary position embedding (RoPE) for positional information injection并基于这些改进,提出了新的Transformer结构TrV,如下图所示:  图3:改进的TrV与原始ViT对比 图3:改进的TrV与原始ViT对比预训练方案 EVA系列方法均按照MVP[5]提出的基于多模态视觉Encoder作为Teacher来生成Mask Token的特征作为Student模型的监督信息,训练时的Loss使用Teacher输出的特征和Student输出的特征负余弦相似度(negative cosine similarity)。对于256个视觉Token,随机Mask的比例设置在40%左右,即102个。  图4:MVP中提出的多模态蒸馏MIM 图4:MVP中提出的多模态蒸馏MIM不同于EVA V1使用CLIP模型的视觉Encoder作为Teacher,EVA V2使用了智源自己训练的gaint规模多模态模型EVA-CLIP作为Teacher。EVA-CLIP相对于CLIP提升较大,尤其是在ImageNet上的Zeroshot分类能力。 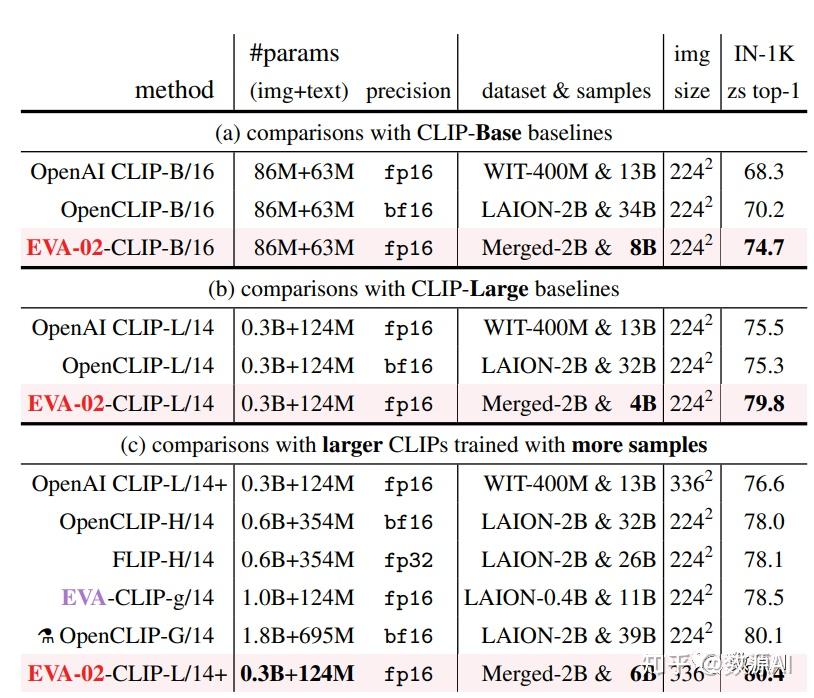 图5:EVA 多模态模型及Zero-shot分类结果 图5:EVA 多模态模型及Zero-shot分类结果可以看到,通过使用原始CLIP权重进行初始化,在更多的数据集上进行进一步训练可以显著提升ImageNet 1k上的zeroshot分类精度。 数据与训练 EVA V2在进行MIM蒸馏时用了比V1更多的38M数据( Merged-38M),即包括多模态数据集(CC12M,CC3M),还包含纯图像数据(ImageNet 21K,ImageNet 1K,COCO,AED20K, Object365),其中多模态数据集仅使用图像数据,COCO,AED20K, Object365等仅使用训练集图像。 训练分为多阶段,第一阶段在Merged-38M上进行MIM预训练,接着再在ImageNet21K上进行中均的finetuning,最后在ImageNet1K上做最后的finetuning。  图6:EVA多阶段训练 图6:EVA多阶段训练同时EVA V2还在目标检测,语义分割等多项下游任务上进行了finetuning测评。 结果分析 通过三阶段训练(不包含多模态预训练),最终EVA V2在Large规模上取得了ImgaeNet 1K 90.0的精度,比V1提升了0.3个百分点,同时下游目标检测及语义分割任务也均有一定提升。  图7:EVA各任务指标 图7:EVA各任务指标更多实验结果可以看原文,里面包含pretraining以及各个任务finetuning的超参设置。 参考文献 [1] BEiT: BERT Pre-Training of Image Transformers https://arxiv.org/abs/2106.08254 [2] Masked Autoencoders Are Scalable Vision Learners https://arxiv.org/abs/2111.06377 [3] BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizershttps://arxiv.org/abs/2208.06366 https://arxiv.org/abs/2102.03334v1 [4] Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Taskshttps://arxiv.org/abs/2208.10442 [5] MVP: Multimodality-guided Visual Pre-training https://arxiv.org/abs/2203.05175 |
【本文地址】
今日新闻 |
推荐新闻 |