ImageNet数据集和ILSVRC2012介绍以及如何通过python使用 |
您所在的位置:网站首页 › imagenet预处理 › ImageNet数据集和ILSVRC2012介绍以及如何通过python使用 |
ImageNet数据集和ILSVRC2012介绍以及如何通过python使用
|
介绍
ImageNet是一个图像数据集,关于它的详细介绍可以参考这篇文章:Dataset之ImageNet:ImageNet数据集简介、下载、使用方法之详细攻略。 ILSVRC是ImageNet Large Scale Visual Recognition Challenge的缩写,是基于ImageNet的一个图像识别大赛,每年都会举办。ILSVRC2012就是2012年举办的,比赛组织者会发布一整套数据,包括 training data from ImageNet (TRAINING),validation data specific to this competition (VALIDATION),and test data specific to this competition (TEST),以及一些元数据,在ILSVRC2012_devkit_t12/data/meta.mat中,包括 synsets = 1x1 struct array with fields: ILSVRC2012_ID WNID words gloss num_children children wordnet_height num_train_images对每个array的详细介绍在ILSVRC2012_devkit_t12/readme.txt可以看到,这里我进行一个搬运: 可以通过官网下载,比较可靠,但是好像现在已经下载不了了。有很多好心人都有百度网盘分享,比如这个文章,下载比较方便(如果你有网盘会员的话),基本也没啥问题,数据集不会少。 使用一般需要用到的文件包括这些(也有可能是文件夹): ILSVRC2012_img_train.tarILSVRC2012_img_val.tarILSVRC2012_img_test.tarILSVRC2012_devkit_t12.tar(.gz)其他可能还有一些bbox文件我暂时还没有用到,以后用到了再来更新。 ILSVRC2012_img_trainILSVRC2012_img_train是训练集,有1,281,167个图片,总共有1000个种类,是ImageNet 的子集,其中每种类型都有732 到 1300张图片,这个文件夹下面是1000个子文件夹,每个文件夹都以WNID来命名,比如n01440764,如下图: 其中preprocess方法是对图片的预处理,直接用官网给出的代码示例 preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ])感觉官网讲的非常的不详细,比如root下面的结构是怎么样的,返回的target到底是WNID还是ILSVRC2012_ID还是将种类按照WNID排序之后的index,我通过阅读源码才搞清楚: root文件夹下面应该有这些文件或者文件夹: ILSVRC2012_img_train.tar或者train文件夹 ILSVRC2012_img_val.tar或者val文件夹 ILSVRC2012_devkit_t12.tar.gz或者meta.bin 如果是压缩文件,它会自动解压成需要的结构,如果已经是解压好的文件夹,确保名字要正确,训练集放在train文件夹下面,验证集放在val文件夹下面。 返回的target是将种类按照WNID排序之后的index,即 想要知道每一个target对应的种类可以通过这个文件:imagenet1000_clsidx_to_labels.txt 也可以手动解压到train目录下,如果是在linux上就直接运行如下命令: mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar(如果不想删掉压缩文件的话亦可以mv ILSVRC2012_img_train.tar ../) find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done cd .. ILSVRC2012_img_valILSVRC2012_img_val是验证集,共50,000张图片,每个类型都有50张,直接就放在ILSVRC2012_img_val文件夹下面: 同理,用ImageNet类,代码如下: valid_ds = ImageNet(root=r'数据集的路径', split='val', transform=preprocess)不管是ImageNet类自动解压还是手动解压,最后都有一个val文件夹,结构是这样的: root val n01440764n01443537……手动解压的话,如果在linux上可以直接运行如下命令: mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash 如果要删掉压缩文件的话 rm -f ILSVRC2012_img_val.tar,如果不想删掉的话就mv ILSVRC2012_img_val.tar ../,反正最好不要吧压缩文件留在这个文件里面 ILSVRC2012_img_testILSVRC2012_img_test是测试集,不会在比赛刚开始就发布的,现在比赛结束很久了所以我们可以拿到。总共有100,000张图片,每个类型有100张,和验证集的结构很像: 但是其实我并没有找到测试集的标签,即test对应的ground truth文件,所以我都是从训练集分割一点出来作为测试集,如果有人找到的可以在评论里告诉我,谢谢。 ILSVRC2012_devkit_t12这是一个工具包,最重要的肯定是readme.txt,来了解整个数据集的结构,真心建议仔细阅读一下。然后是meta.mat,记录了ImageNet数据集的各种信息,readme介绍了如何用matlab来访问,下面我就介绍如何通过python来访问。 首先: import os import scipy.io synsets = scipy.io.loadmat(os.path.join(r'你的数据集路径\ILSVRC2012_devkit_t12', 'data', 'meta.mat'))['synsets'] print(len(synsets)) print(synsets)输出如下: 1860 array([[(array([[1]], dtype=uint8), array(['n02119789'], dtype=' |
 一个要注意的点就是, ILSVRC2012_ID是1-1000,最终提交的结果应该是预测的种类对应的ILSVRC2012_ID,而我们平常的预测结果都是从0开始的,即最大的概率对应的index,而且如果使用pytorch的ImageNet类来处理数据集的话,它的label是0-999的整数,而且是按照WNID从小到大排列的,和ILSVRC2012_ID的顺序不一样,比如,ILSVRC2012_ID最小的是’kit fox, Vulpes macrotis’,WNID是n02119789;而WNID最小的是’tench, Tinca tinca’,WNID是n01440764。反正就是要进行一个转换,一定要注意!比如预训练好的VGG模型的预测的结果是该类型的WNID的index(0-999),不是ILSVRC2012_ID(1-1000) 当然光看这些可能会有点乱,还是要自己下载下来然后加载到内存中看看里面有什么东西才会比较清楚。
一个要注意的点就是, ILSVRC2012_ID是1-1000,最终提交的结果应该是预测的种类对应的ILSVRC2012_ID,而我们平常的预测结果都是从0开始的,即最大的概率对应的index,而且如果使用pytorch的ImageNet类来处理数据集的话,它的label是0-999的整数,而且是按照WNID从小到大排列的,和ILSVRC2012_ID的顺序不一样,比如,ILSVRC2012_ID最小的是’kit fox, Vulpes macrotis’,WNID是n02119789;而WNID最小的是’tench, Tinca tinca’,WNID是n01440764。反正就是要进行一个转换,一定要注意!比如预训练好的VGG模型的预测的结果是该类型的WNID的index(0-999),不是ILSVRC2012_ID(1-1000) 当然光看这些可能会有点乱,还是要自己下载下来然后加载到内存中看看里面有什么东西才会比较清楚。 文件夹下面是该种类JPEG格式的图片:
文件夹下面是该种类JPEG格式的图片: 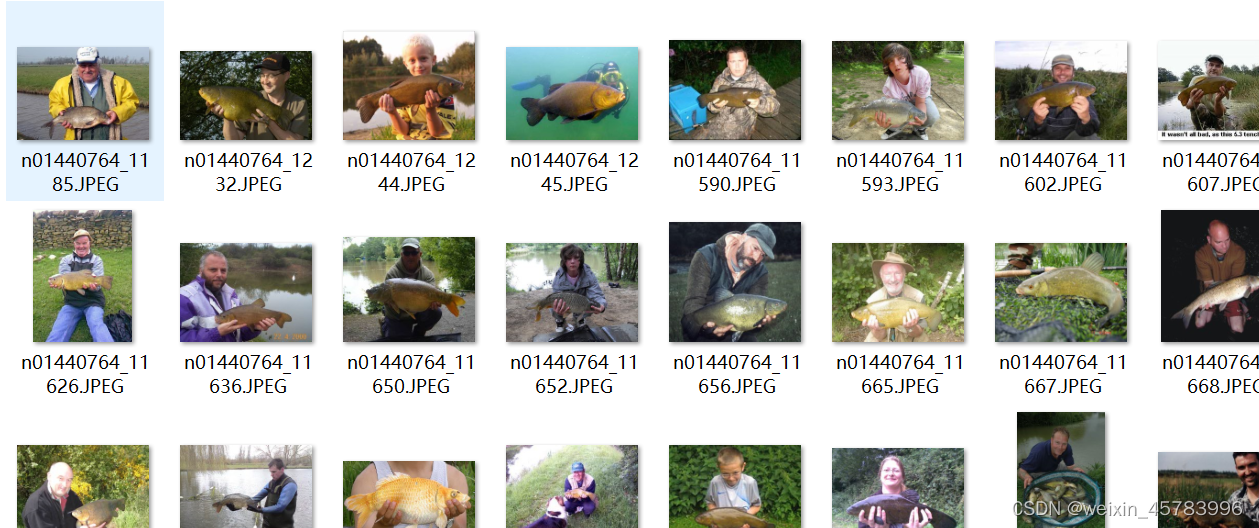 直接通过pytorch提供的ImageNet类来使用,想要更详细的了解这个类可以看我的这篇:pytorch的ImageNet类,但是不看也完全不影响这一篇的阅读。使用代码如下:
直接通过pytorch提供的ImageNet类来使用,想要更详细的了解这个类可以看我的这篇:pytorch的ImageNet类,但是不看也完全不影响这一篇的阅读。使用代码如下: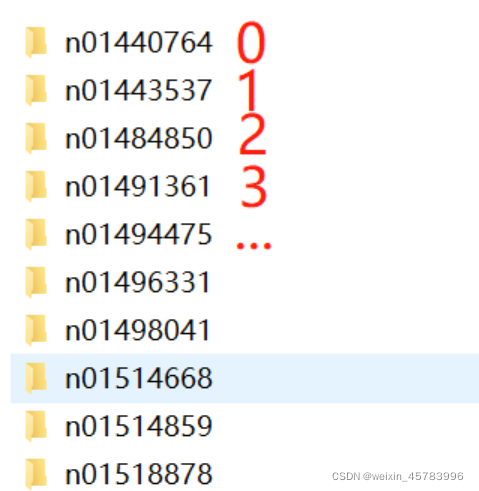 比如,n01440764文件夹下面的图片的target都是0。
比如,n01440764文件夹下面的图片的target都是0。 每个图片对应的种类放在ILSVRC2012_devkit_t12/data/ILSVRC2012_validation_ground_truth.txt里面:
每个图片对应的种类放在ILSVRC2012_devkit_t12/data/ILSVRC2012_validation_ground_truth.txt里面:  这里面的数字是ILSVRC2012_ID,是1-1000的数字,是和ILSVRC2012这个比赛相对应的,最后提交的分类结果也是这个,但是训练的时候不是把这个作为target!!!注意,WNID和ILSVRC2012_ID不一样,而且顺序也不一样。ILSVRC2012_ID的范围是ILSVRC2012这个比赛里的图片,WNID是整个WordNet的图片。
这里面的数字是ILSVRC2012_ID,是1-1000的数字,是和ILSVRC2012这个比赛相对应的,最后提交的分类结果也是这个,但是训练的时候不是把这个作为target!!!注意,WNID和ILSVRC2012_ID不一样,而且顺序也不一样。ILSVRC2012_ID的范围是ILSVRC2012这个比赛里的图片,WNID是整个WordNet的图片。 可以通过pytorch提供的ImageNet类来实现自定义的数据集,关于这个类的详细介绍可以参考这篇文章:两文读懂PyTorch中Dataset与DataLoader(一)打造自己的数据集,只要实现__len()__和__getitem()__两个方法即可。
可以通过pytorch提供的ImageNet类来实现自定义的数据集,关于这个类的详细介绍可以参考这篇文章:两文读懂PyTorch中Dataset与DataLoader(一)打造自己的数据集,只要实现__len()__和__getitem()__两个方法即可。【本文地址】
今日新闻 |
推荐新闻 |