MySQL 编码不一致竟导致无法命中数据? |
您所在的位置:网站首页 › id无法复制出版物怎么办 › MySQL 编码不一致竟导致无法命中数据? |
MySQL 编码不一致竟导致无法命中数据?
|
[[402050]] 本文转载自微信公众号「码农私房话」,作者Liew。转载本文请联系码农私房话公众号。 由于组内技术栈转型,需要使用 Java 重构一个 NodeJS 编写的业务后台模块,模块包含一个根据名称模糊查询触点标签的功能,这是一个非常普通的 CRUD 操作,但让人百思不得其解的是模糊查询并没有把数据查出来。 项目使用的是 MySQL 数据库,配置的编码是 utf8,具体表结构语句如下: CREATE TABLE `t_touch_label` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `label_name` varchar(100) DEFAULT NULL COMMENT '标签名', `state` tinyint(1) DEFAULT '1' COMMENT '是否启用', `merchant_id` int(11) NOT NULL COMMENT '用户ID', `remark` int(11) DEFAULT NULL COMMENT '备注' PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;当客户端与 MySQL 服务器编码一致时,执行下面语句是能正常查询到数据的。 select id,label_name from t_touch_label where merchant_id=10086 and label_name like %B轮标签%;但如果未在数据库 jdbc-url 配置中指定编码 characterEncoding=utf8 就会导致 like 模糊查询无法命中数据,这是因为在客户端操作数据的编码与 MySQL Server 存储引擎使用的编码格式不一致导致的。 问题复现首先,通过日志定位有问题的 SQL: select id,label_name from t_touch_label where merchant_id=10086 and label_name like %B轮标签%;并在测试库上验证 SQL 是否正常查询、过滤数据,令我震惊的是一切正常。
接下来本地查看 MyBatis 生成的 SQL 日志,确实查询出来的是 0 条数据,而且代码也正常运行没有报错,奇了个怪。 于是我产生了一个大胆的猜测:可能是中文参数导致的问题,我把参数改为英文字符会不会就正常呢?
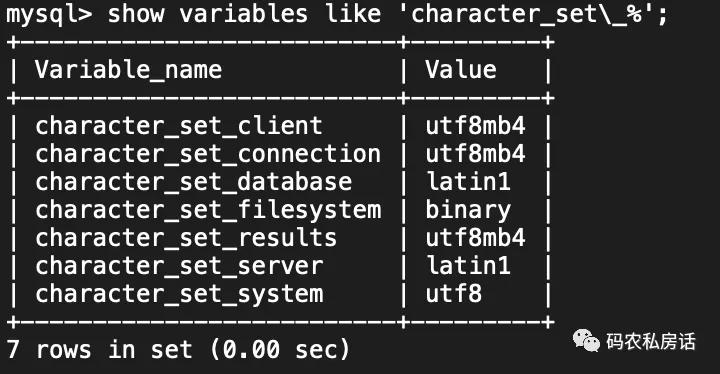
果不其然,当参数输入为英文字符时,一切都变得如此正常了,同时也验证了我那“大胆的猜测”是正确的。 按照这个思路,我检查了 MySQL 服务端:
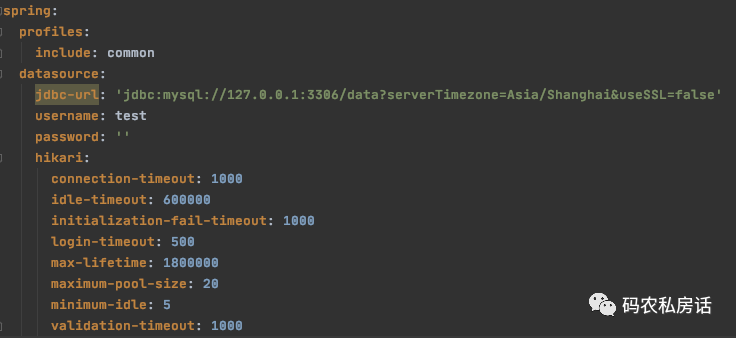
在项目中,配置的 MySQL 数据库连接池:
观察上面 jdbc-url 项的配置不难发现,在 url 中是没有配置 characterEncoding 字符集编码。 于是在数据库的 jdbc-url 中添加配置 characterEncoding=utf8 后再次使用中文模糊查询就恢复正常。
由此可见,MySQL 使用 like 模糊查询时,无法命中数据的问题是由于 MySQL 服务端与客户端字符集编码集不一致导致的。 编码不一致,无法命中数据?MySQL 在存储数据与查询数据时,对数据编解码流程如下: MySQL Client 根据 jdbc-url 中设定的 characterEncoding 字符编码(没有配置则使用 MySQL Server 配置的 character_set_server )转换成二进制流,并传输到 MySQL Server。 MySQL Server 收到请求时将请求数据 data 从 character_set_client 转换为 character_set_connection。 在内部操作数据前将请求数据从 character_set_connection 转换为内部操作的字符集,其编码确定顺序: 使用表字段的 character set 值。 当上述值不存在,则使用数据表的 default character set 值。 若上述值不存在,则使用数据库的 default character set 值。 若上述值不存在,则使用 character_set_server 值。 引擎层读写存储文件,涉及内部操作字符集与二进制流之间的相互转换; 将操作结果从内部操作字符集转换为 character_set_results 。 MySQL Client 接收到数据后,根据本地配置的字符编码 characterEncoding 渲染查询结果。数据文件到存储引擎的编解码:执行 select left(name,2) from table 语句时,存储引擎加载数据文件时读入的 name 值是 E4B8ADE69687,而 left(name,2) 操作需要对内容进行分词处理: 如果按照GBK 编码,该值则分割成E4B8、ADE6、9687 三个字,并返回客户端的值是 E4B8ADE6; 如果按照 UTF8 编码,就会分割成E4B8AD、E69687,返回客户端为 E4B8ADE69687 两个字。由此可见,从数据文件读入数据后,如果不进行编解码,存储引擎内部是无法进行字符维度的操作。 MySQL 存取数据乱码除了上述编码不一致导致无法命中数据外,还可能引起存取数据乱码的问题,例如向数据表字符集为 utf8 插入 utf8 编码的数据,查询时设置连接字符集为 utf8。 另外在 MySQL Server 的字符集配置中,character_set_client、character_set_results、character_set_connection 等变量的默认值均为 latin1。 插入操作的数据将经过 latin1 -> latin1 -> utf8 的字符集转换流程,过程中每个汉字会从原始的 3 个字节变成 6 个字节存储。 查询的数据将经过 utf8 -> utf8 的字符集转换,将保存的 6 个字节返回,产生乱码。 当单个流程中编码不一致,且两个字符集之间无法进行无损编码转换,也会出现乱码。 例如 MySQL Client 使用的编码是 utf8,而 MySQL Server 的 character_set_client 为 gbk,表的字符集为 utf8,则一定出现乱码。 客户端的字符编码和最终表的字符编码格式虽然不同,但是只要保证存储和查询两个操作的字符集编码一致且能无损编码转换时,就不会产生乱码的问题。 避免编码不一致的措施1、在建立数据库、表结构或者数据库操作时,应尽量显式指定使用的字符集。而 character_set_client、character_set_result、character_set_connection 等变量值与库表字段字符集定义相同,不依赖于MySQL 的默认设置,否则升级 MySQL 时可能带来很大困扰。 2、当数据库和连接字符集都使用 latin1 时,大部分情况下可以解决乱码问题,但缺点是无法以字符为单位来进行 SQL 操作。一般情况下将数据库和连接字符集都置为 utf8 ,可避免出现编码问题。 3、my.cnf 文件中的 default_character_set 设置只影响命令连接服务器时的连接字符集。 4、对字段进行的 SQL 函数操作时,通常都是以内部操作字符集进行的,不受连接字符集设置的影响。 5、SQL 语句中的字符串会受到连接字符集或 introducer (即在 SQL 中对查询列直接指定字符集)设置的影响,因此对比较的操作可能产生不同的结果。
|



【本文地址】