IDEA项目实践 |
您所在的位置:网站首页 › idea怎么创建java类 › IDEA项目实践 |
IDEA项目实践
|
系列文章目录
IDEA上面书写wordcount的Scala文件具体操作 IDEA创建项目的操作步骤以及在虚拟机里面创建Scala的项目简单介绍 目录 系列文章目录 前言 一 准备工作 1.1 安装Maven 1.1.1 Maven安装配置步骤 1.1.2 解压相关的软件包 1.1.3 Maven 配置环境变量 1.1.4 配置Maven的私服 1.2 创建一个本地的MySQL数据库和数据表 二 创建Java项目 2.1 方式一 数据库连接池druid 2.1.1 MySQL-connector-java资源分享链接 2.1.2 druid资源链接 2.2 创建Java项目步骤如下 2.2.1 创建项目目录 2.2.2 创建一个新的Java类 2.2.3 导入jar包 2.2.4 将jar包加载到library 2.2.5 编写Java代码 版本一 版本二 2.3 方式二 配置文件的形式加载 2.3.1 在src目录之下创建配置文件 2.3.2 在配置文件当中添加如下的信息 2.3.3 创建一个demo2的Java文件 2.3.4 编辑Java代码 三 在IDEA上创建Maven项目来实现上述的功能 3.1 创建项目 3.2 创建一个Java类 3.3 编辑Java代码和配置文件 3.4 Java代码模块讲解 3.4.1 Java Scanner 类 3.4.2 系统添加数据模块方法 3.4.3 编辑MySQL与druid依赖 3.4.4 编辑插入数据方法 3.4.5 编辑查询代码 3.4.6 完整的优化后的代码 思考——如何优化上述的Java代码? 总结 前言本文主要介绍IDEA项目实践,创建Java项目以及创建Maven项目案例、使用数据库连接池创建项目简介 一 准备工作 1.1 安装MavenMaven资源分享包 链接:https://pan.baidu.com/s/1D3SHLKTMTTUDYLv45EXgeg?pwd=kmdf 提取码:kmdf 1.1.1 Maven安装配置步骤 1. 解压 apache-maven-3.6.1.rar 既安装完成 2. 配置环境变量 MAVEN_HOME 为安装 路径,在 Path 添加 %MAVEN_HOME%/bin 目录 3. 配置本地仓库:修改 conf /settings.xml 中的 为一个指定目录 4. 配置阿里云私服:修改 conf /settings.xml 中的 标签,为其添加如下子标签 1.1.2 解压相关的软件包解压你的Maven包,放在你的文件夹里面,配置相关的本地仓库文件
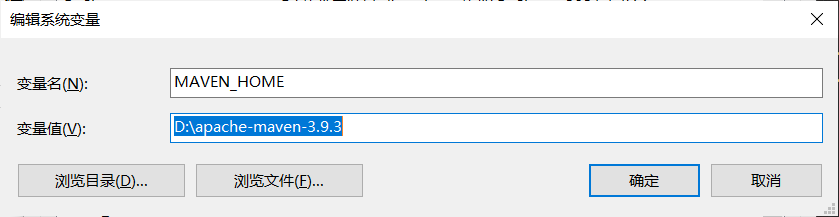
打开Windows1的高级设置,配置相关的环境变量 第一处 MAVEN_HOME D:\apache-maven-3.9.3
第二处 Path %MAVEN_HOME%/bin
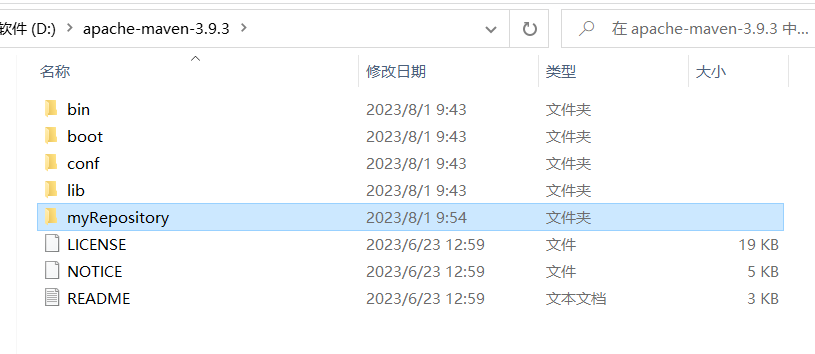
需要添加的内容如下: alimaven aliyun maven http://maven.aliyun.com/nexus/content/groups/public/ central先创建一个本地仓库文件夹【myRepository】你的仓库创建在你安装了Maven的地方。
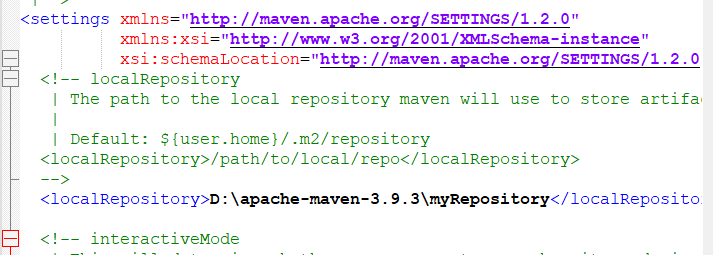
在notepad++查找本地的【localRepository】 没有notepad++也可以使用记事本编辑,只要将内容修改完,并且保存完成即可。
在setting文件夹里面加入本地仓库位置 D:\apache-maven-3.9.3\myRepository
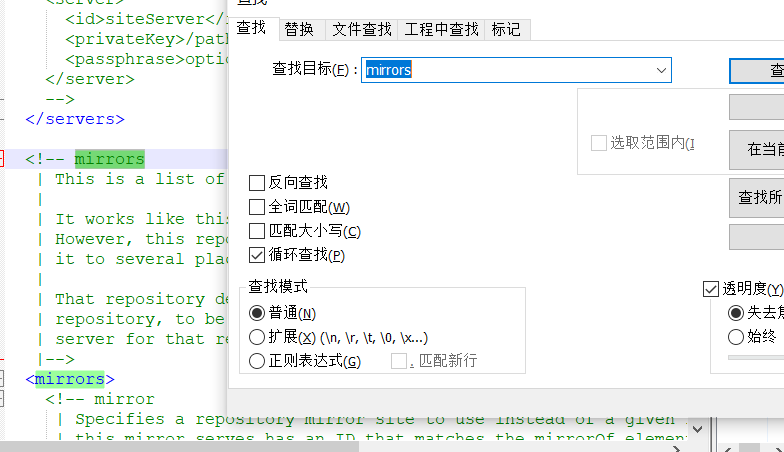
查找mirrors位置,修改为阿里的私服。
添加完成之后记得保存~
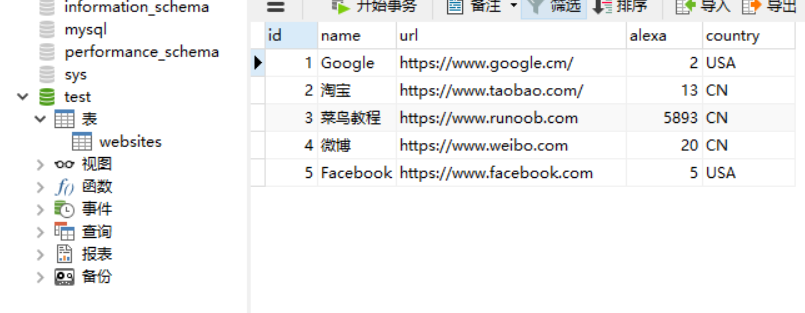
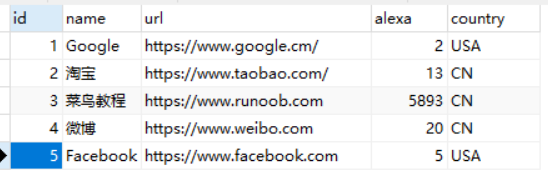
编辑完成之后退出。本地仓库就配置完成了。 1.2 创建一个本地的MySQL数据库和数据表在此之前,需要配置本地MySQL服务的连接如下: MySQL以及MySQL workbench的安装与配置【超详细安装教程】 创建数据库和数据表的SQL语句 // 创建名为 test 的数据库 CREATE DATABASE test; // 使用 test 数据库 USE test; // 创建名为 websites 的表 CREATE TABLE `websites` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` char(20) NOT NULL DEFAULT '' COMMENT '站点名称', `url` varchar(255) NOT NULL DEFAULT '', `alexa` int(11) NOT NULL DEFAULT '0' COMMENT 'Alexa 排名', `country` char(10) NOT NULL DEFAULT '' COMMENT '国家', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8; // 在 websites 中插入数据 INSERT INTO `websites` VALUES ('1', 'Google', 'https://www.google.cm/', '2', 'USA'), ('2', '淘宝', 'https://www.taobao.com/', '13', 'CN'), ('3', '菜鸟教程', 'http://www.runoob.com', '5892', 'CN'), ('4', '微博', 'http://weibo.com/', '20', 'CN'), ('5', 'Facebook', 'https://www.facebook.com/', '3', 'USA'), ('6', 'JueJin', 'https://www.juejin.cn/', '2213', 'CN');创建之后的数据库如下图所示的界面:
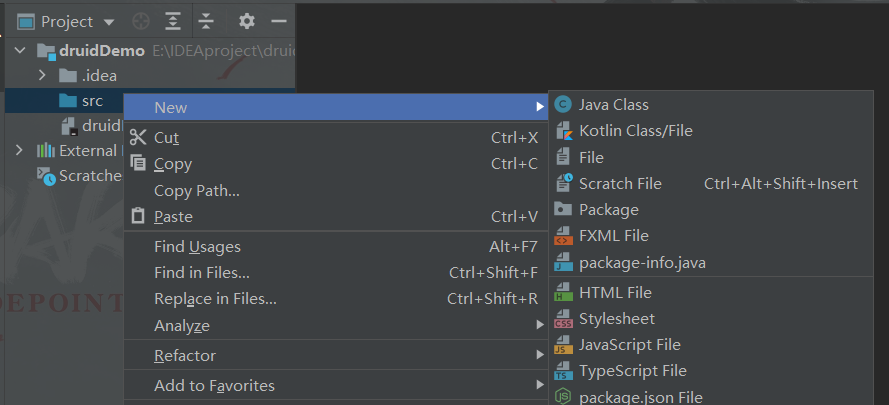
创建步骤如下: 1. 导入jar包(mysql-connection-java.jar,druid.jar),同时加入到类加载路径中 2. 直接创建连接池对象:new对象 DruidDataSource 3. 然后设置属性。 1. setDriverClassName() 2. setUrl() 3. setUsername() 4. setPassword() 5. setInitialSize() //初始连接数 6. setMaxSize() //最大连接数 7. setMaxWait() //最大等待时间 4. 通过连接池对象,获取数据库连接 方式一的缺点:将MySQL的URL和用户以及密码是写死的,当你要修改的时候不好修改 2.1.1 MySQL-connector-java资源分享链接MySQL-connector-java-8.0.31版本百度网盘连接 链接:https://pan.baidu.com/s/1A2NtVswiJjvxFB68GZ77Vw?pwd=wcmo 提取码:wcmo MySQL-connector-java-5.1.49版本百度网盘连接 链接:https://pan.baidu.com/s/1FPL23h6Ca7_Y0N_HYZSm0Q?pwd=6kwi 提取码:6kwi 2.1.2 druid资源链接druid-1.1.12版本 链接:https://pan.baidu.com/s/13Bwl-R3gN0fU5qHAGFHzwA?pwd=gu9g 提取码:gu9g 2.2 创建Java项目步骤如下 2.2.1 创建项目目录选择创建Java文件
继续下一步
创建你的问价存储位置,此处建议专门写一个存放IDEA项目的文件夹。
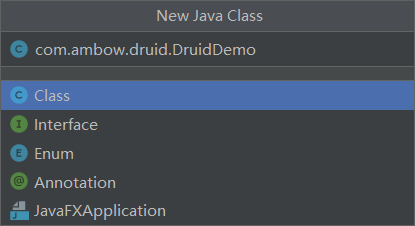
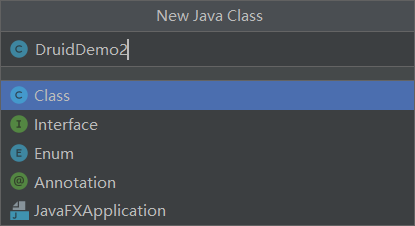
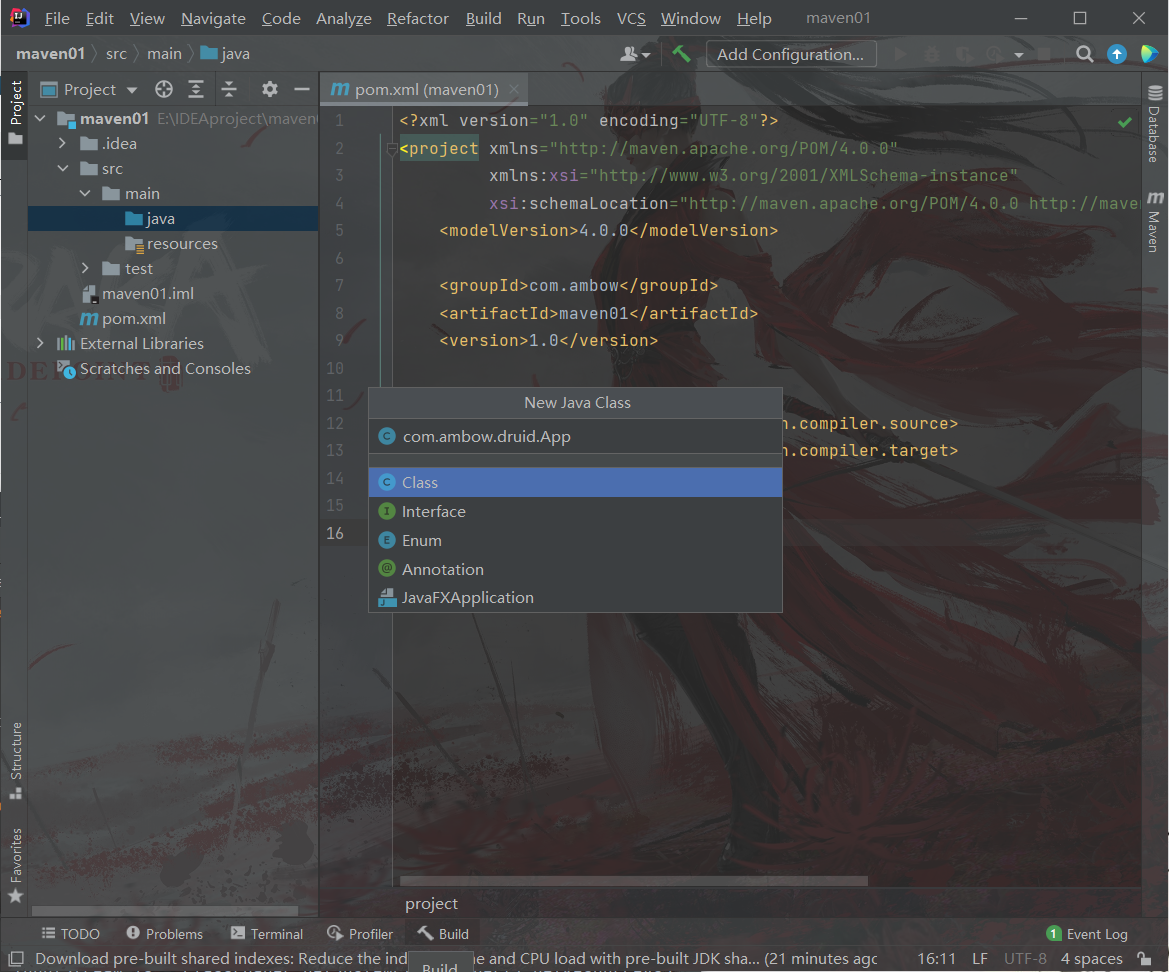
在src文件里面创建一个新的Java类
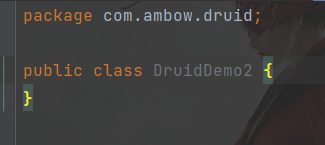
名字为: com.ambow.druid.DruidDemo 解释——前三个为包名称,后面为类名称。
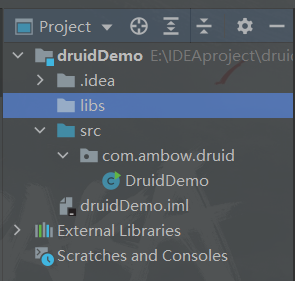
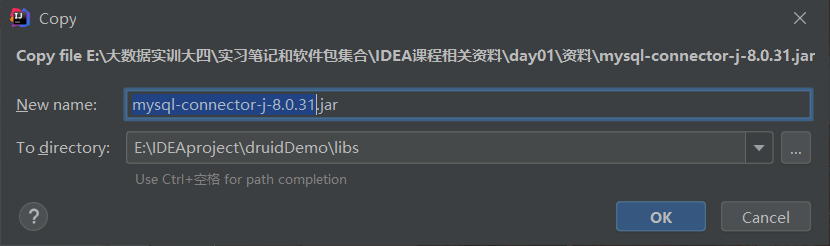
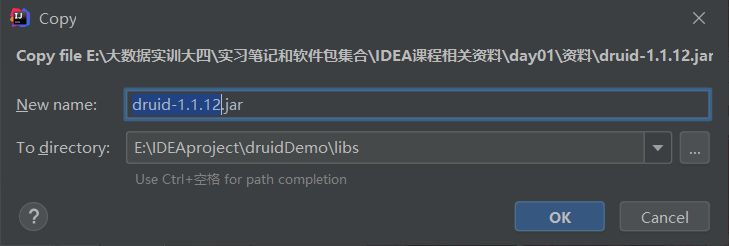
在项目里面新建一个文件夹导入前面的两个jar包【MySQL-connector-java-8.0.31和druid-1.1.12 】,需要自己创建一个libs文件夹存放这两个jar包。
此处记得选择自己的MySQL对应的Java包,下载之后,将两个jar包复制,将其粘贴在libs文件夹里面即可。
此处点击ok即可。
同上
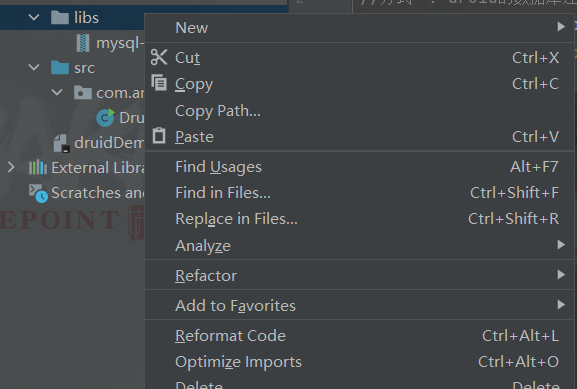
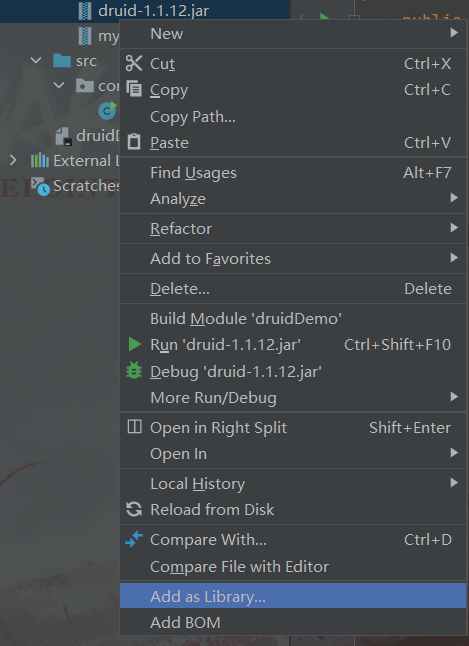
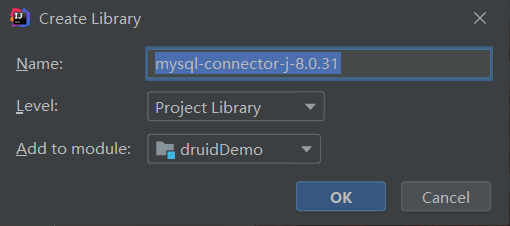
在两个jar包上面,鼠标右键,选择as a library加载
点击OK即可
运行结果如下:
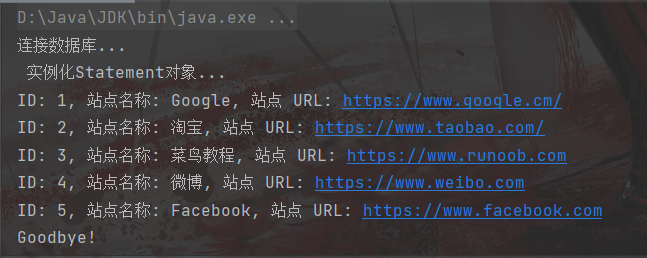
代码演示 package com.ambow.druid; import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.pool.DruidPooledConnection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; /* 方式一: 直接创建DruidDataSource ,然后设置属性 */ public class DruidDemo { public static void main(String[] args) throws SQLException { DruidDataSource dds = new DruidDataSource(); dds.setDriverClassName("com.mysql.cj.jdbc.Driver"); dds.setUrl("jdbc:mysql://localhost:3306/test?serverTimezone=UTC"); dds.setUsername("root"); dds.setPassword("root"); dds.setInitialSize(5);//初识连接数 dds.setMaxActive(10);//最大连接数 dds.setMaxWait(3000);//最大等待时间 //获取连接 DruidPooledConnection connection = dds.getConnection(); System.out.println(connection); //获取执行语句对象 String sql = "select * from websites"; PreparedStatement pstmt = connection.prepareStatement(sql); //获取结果集 ResultSet rs = pstmt.executeQuery(); while (rs.next()){ System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3) + "-" + rs.getInt(4) + "-" + rs.getString(5)); } /* jdbc连接的四个参数: driver url username password */ } }运行结果:
此处的代码实现,首先也需要先将druid的jar包放到项目下的lib下并添加为库文件,与前面一样的形式创建。 2.3.1 在src目录之下创建配置文件
文件名称为: druid.properties PS:Java里面的配置文件为properties类型
将用户以及密码哪些信息写入配置文件 此处为8.0以上版本的书写方法 driverClassName=com.mysql.cj.jdbc.Driver url=jdbc:mysql:///test?serverTimezone=UTC username=root password=root # 初始化连接数量 initialSize=5 # 最大连接数 maxActive=10 # 最大等待时间 maxWait=3000以下为5.1 版本的写法【举例如下】 driverClassName=com.mysql.cj.jdbc.Driver url=jdbc:mysql://182.168.1.1/test username=root password=root # ??????? initialSize=5 # ????? maxActive=10 # ?????? maxWait=3000 //前面的是IP地址以及数据库的名称 2.3.3 创建一个demo2的Java文件
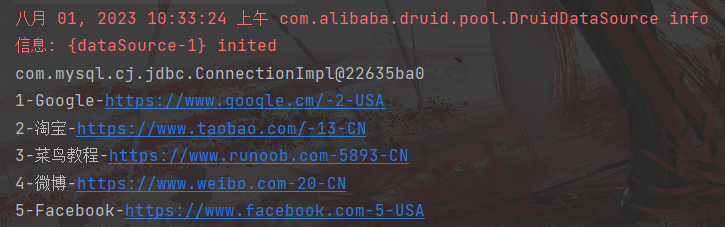
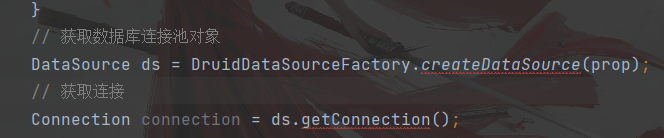
此处只是一个获取连接的代码 package com.ambow.druid; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.sql.Connection; import java.util.Properties; /* 方式二:提取配置文件(把连接数据库的参数,抽取出来) */ public class DruidDemo2 { public static void main(String[] args) throws Exception { //获取当前项目的根目录 System.out.println(System.getProperty("user.dir")); // 加载配置文件 Properties prop = new Properties(); //FileInputStream is = new FileInputStream("src/druid.properties"); InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties"); prop.load(is); // 获取数据库连接池对象 DataSource ds = DruidDataSourceFactory.createDataSource(prop); // 获取连接 Connection connection = ds.getConnection(); System.out.println(connection); } }运行结果:
注意: System.getProperty("user.dir"),在web项目,返回值就不是项目的根目录了,而是tomcat的bin目录。 三 在IDEA上创建Maven项目来实现上述的功能 3.1 创建项目在file里面选择创建新的项目,选择Maven项目
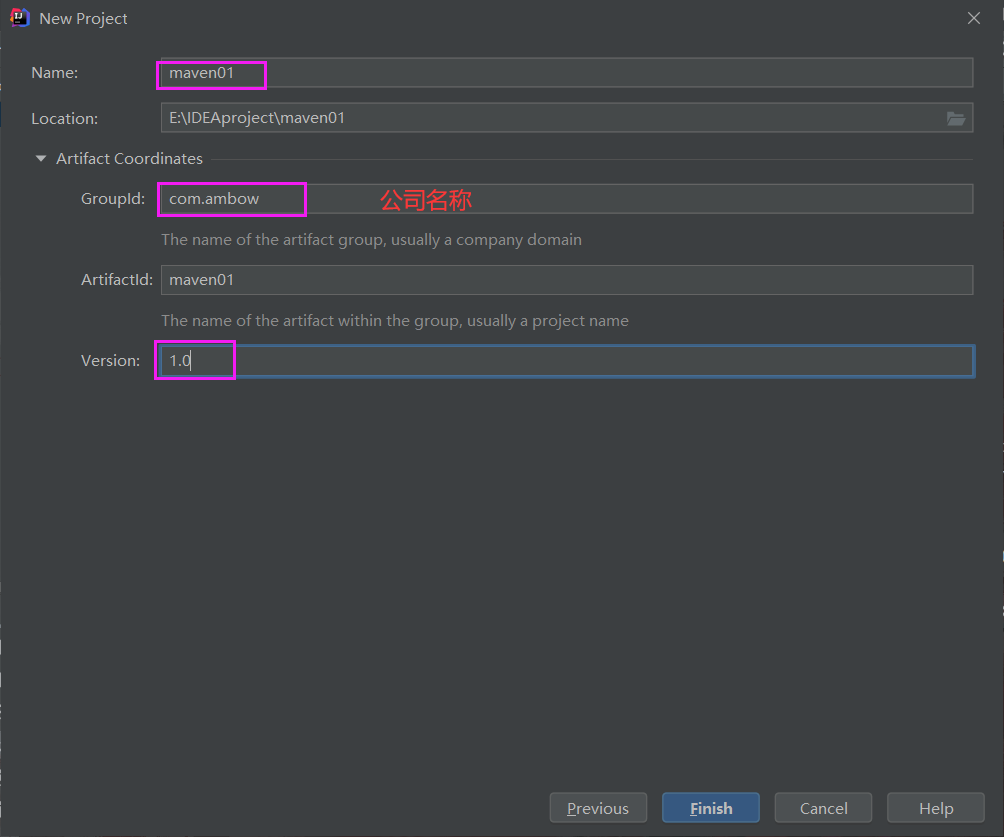
填写项目的名称,以及公司名称
点击finsh即可。 此处补全一个资源文件夹
编辑配置文件的方法与2.3.2 一样,此处不再赘述。 在刚才的类里面编辑Java代码 package com.ambow.druid; import java.sql.*; import java.util.Scanner; public class App { static final String JDBC_DRIVER="com.mysql.cj.jdbc.Driver"; static final String DB_URL="jdbc:mysql://localhost:3306/test"; static final String USER = "root"; static final String PASS ="root"; static Scanner sc =new Scanner(System.in);//成为类成员前面加入static修饰 public static void main(String[] args) throws SQLException { // DruidDataSource dds = new DruidDataSource(); // dds.setDriverClassName("com.mysql.jdbc.Driver"); // dds.setUrl("jdbc:mysql://192.168.127.100:3306/db2"); // dds.setUsername("root"); // dds.setPassword("Admin2023!"); // dds.setInitialSize(5); // dds.setMaxActive(10); // dds.setMaxWait(3000); // DruidPooledConnection connection = dds.getConnection(); // System.out.println(connection); //加入循环 while (true) { System.out.println("***********************************"); System.out.println("*********** 站点管理系统 ***********"); System.out.println("*********** 1.新增站点 ***********"); System.out.println("*********** 2.修改站点 ***********"); System.out.println("*********** 3.删除站点 ***********"); System.out.println("*********** 4.查询站点 ***********"); System.out.println("*********** 0.退出系统 ***********"); System.out.println("**********************************"); System.out.println("请选择:"); //静态方法只能访问静态变量 int choose = sc.nextInt(); switch (choose){ case 1: addWebSite(); break; case 2: modifyWebSite(); break; case 3: dropWebSite(); break; case 4: queryWebSite(); break; case 0: System.out.println("退出系统"); System.exit(0); break; default: System.out.println("对不起,您的选择有误!"); break; } } } // String sql ="select * from websites"; // PreparedStatement pstmt =connection.prepareStatement(sql); // ResultSet rs = pstmt.executeQuery(); // while (rs.next()){ // System.out.println(rs.getInt(1) +"-"+ rs.getString(2) +"-"+ rs.getString(3) // +"-"+ rs.getInt(4) +"-"+ rs.getString(5)); // } // rs.close(); // pstmt.close(); // connection.close(); // } private static void addWebSite() { System.out.println("请输入站点名称:"); String name = sc.next(); System.out.println("请输入站点URL:"); String url = sc.next(); System.out.println("请输入站点alexa:"); int alexa = sc.nextInt(); System.out.println("请输入站点所属国家:"); String country = sc.next(); Connection conn = null; PreparedStatement pstmt = null; try { Class.forName((JDBC_DRIVER)); conn = DriverManager.getConnection(DB_URL, USER, PASS); String sql ="insert into websites values(null,?,?,?,?)"; pstmt = conn.prepareStatement(sql); pstmt.setString(1,name); pstmt.setString(2,url); pstmt.setInt(3,alexa); pstmt.setString(4,country); pstmt.executeUpdate(); System.out.println("添加站点成功!"); }catch (SQLException se){ se.printStackTrace(); }catch (Exception e){ e.printStackTrace(); }finally { try{ if(pstmt!=null) pstmt.close(); }catch (SQLException se2){ } try{ if(conn!=null) conn.close(); }catch (SQLException se){ se.printStackTrace(); } } } private static void modifyWebSite() { System.out.println("请输入要修改的站点名称:"); String name = sc.next(); System.out.println("请输入新站点URL:"); String url = sc.next(); System.out.println("请输入新站点alexa:"); int alexa = sc.nextInt(); System.out.println("请输入新站点所属国家:"); String country = sc.next(); Connection conn = null; PreparedStatement pstmt = null; try { Class.forName((JDBC_DRIVER)); conn = DriverManager.getConnection(DB_URL, USER, PASS); String sql ="update websites set url=?,alexa= ?,country=? where name=?"; pstmt = conn.prepareStatement(sql); pstmt.setString(1,name); pstmt.setString(2,url); pstmt.setInt(3,alexa); pstmt.setString(4,country); pstmt.executeUpdate(); System.out.println("修改站点成功!"); }catch (SQLException se){ se.printStackTrace(); }catch (Exception e){ e.printStackTrace(); }finally { try{ if(pstmt!=null) pstmt.close(); }catch (SQLException se2){ } try{ if(conn!=null) conn.close(); }catch (SQLException se){ se.printStackTrace(); } } } private static void dropWebSite() { System.out.println("请输入要删除的站点名称:"); String name = sc.next(); // System.out.println("请输入站点URL:"); // String url = sc.next(); // System.out.println("请输入站点alexa:"); // int alexa = sc.nextInt(); // System.out.println("请输入站点所属国家:"); // String country = sc.next(); Connection conn = null; PreparedStatement pstmt = null; try { Class.forName((JDBC_DRIVER)); conn = DriverManager.getConnection(DB_URL, USER, PASS); String sql ="delete from websites where name=?"; pstmt = conn.prepareStatement(sql); pstmt.setString(1,name); // pstmt.setString(2,url); // pstmt.setInt(3,alexa); // pstmt.setString(4,country); pstmt.executeUpdate(); System.out.println("删除站点成功!"); }catch (SQLException se){ se.printStackTrace(); }catch (Exception e){ e.printStackTrace(); }finally { try{ if(pstmt!=null) pstmt.close(); }catch (SQLException se2){ } try{ if(conn!=null) conn.close(); }catch (SQLException se){ se.printStackTrace(); } } } private static void queryWebSite() { // System.out.println("请输入要查询的站点名称:"); // String name = sc.next("name"); // System.out.println("请输入站点URL:"); // String url = sc.next("url"); // System.out.println("请输入站点alexa:"); // int alexa = sc.nextInt(Integer.parseInt("alexa")); // System.out.println("请输入站点所属国家:"); // String country = sc.next("country"); Connection conn = null; PreparedStatement pstmt = null; try { Class.forName((JDBC_DRIVER)); conn = DriverManager.getConnection(DB_URL, USER, PASS); Statement stmt = conn.createStatement(); String sql ="SELECT id,name,url FROM websites"; ResultSet rs = stmt.executeQuery(sql); //pstmt = conn.prepareStatement(sql); // pstmt.setString(name); // pstmt.setString(2,url); // pstmt.setInt(3,alexa); // pstmt.setString(4,country); // System.out.print("name"); // System.out.print("url"); // System.out.print("alexa"); // System.out.print("country"); // System.out.print("\n"); //pstmt.executeQuery(); // System.out.println("查询站点成功!"); while (rs.next()){ int id =rs.getInt("id"); String name = rs.getString("name"); String url = rs.getString("url"); System.out.print("id"+":"+id+"-"); System.out.print("name"+":"+name+"-"); System.out.print("url"+":"+url); System.out.print("\n"); System.out.println("查询站点成功!"); } rs.close(); stmt.close(); conn.close(); }catch (SQLException se){ se.printStackTrace(); }catch (Exception e){ e.printStackTrace(); }finally { try{ if(pstmt!=null) pstmt.close(); }catch (SQLException se2){ } try{ if(conn!=null) conn.close(); }catch (SQLException se){ se.printStackTrace(); } } } }运行结果如下:
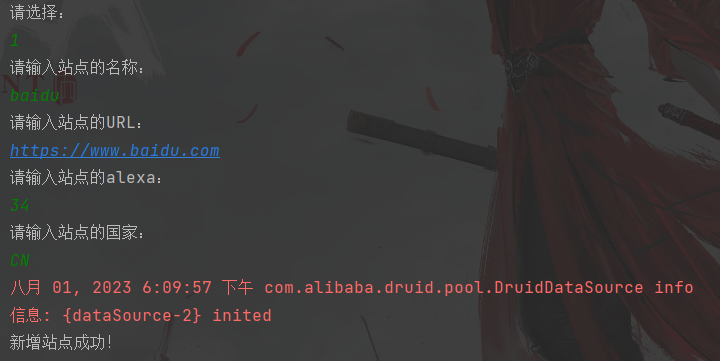
查看MySQL里面的表信息可以看到信息添加成功了。 修改站点信息
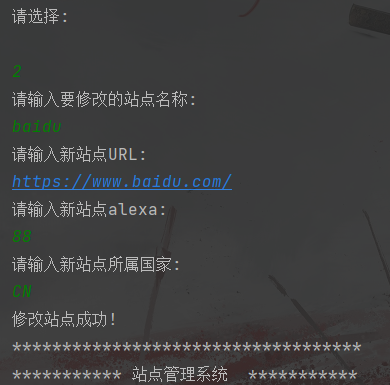
删除站点
删除之后的恢复为原来的情况
最后退出系统。
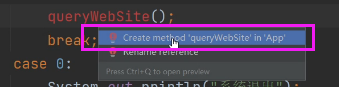
java.util.Scanner 是 Java5 的新特征,我们可以通过 Scanner 类来获取用户的输入。 下面是创建 Scanner 对象的基本语法: Scanner s = new Scanner(System.in);Scanner 类的 next() 与 nextLine() 方法获取输入的字符串,在读取数据前我们一般需要 使用 hasNext 与 hasNextLine 判断是否还有输入的数据。 next() 、nextInt() 、nextLine() 区别 next(): 1、一定要读取到有效字符后才可以结束输入。2、对输入有效字符之前遇到的空白,next() 方法会自动将其去掉。3、只有输入有效字符后才将其后面输入的空白作为分隔符或者结束符。next() 不能得到带有空格的字符串。nextLine(): 1、以Enter为结束符,也就是说 nextLine()方法返回的是输入回车之前的所有字符。2、可以获得空白。如果要输入 int 或 float 类型的数据,在 Scanner 类中也有支持,但是在输入之前最好先使用 hasNextXxx() 方法进行验证,再使用 nextXxx() 来读取。 nextInt()、nextLine()区别: 1.nextInt()只会读取数值,剩下"\n"还没有读取,并将cursor放在本行中。2.nextLine()会读取"\n",并结束(nextLine() reads till the end of line \n)。3.如果想要在nextInt()后读取一行,就得在nextInt()之后额外加上cin.nextLine()nextInt() 一定要读取到有效字符后才可以结束输入,对输入有效字符之前遇到的空格键、Tab键或Enter键等结束符,nextInt() 方法会自动将其去掉,只有在输入有效字符之后,nextInt()方法才将其后输入的空格键、Tab键或Enter键等视为分隔符或结束符。简单地说,nextInt()查找并返回来自此扫描器的下一个完整标记。完整标记的前后是与分隔模式匹配的输入信息,所以next方法不能得到带空格的字符串。 而nextLine() 方法的结束符只是Enter键,即nextLine() 方法返回的是Enter键之前的所有字符,它是可以得到带空格的字符串的。 可以看到,nextLine() 自动读取了被nextInt() 去掉的Enter作为他的结束符,所以没办法给s2从键盘输入值。经过验证,我发现其他的next的方法,如double nextDouble() , float nextFloat() , int nextInt() 等与nextLine() 连用时都存在这个问题,解决的办法是:在每一个 next() 、nextDouble() 、 nextFloat()、nextInt() 等语句之后加一个nextLine() 语句,将被next() 去掉的Enter结束符过滤掉。 此处使用的是scanner对象的nextInt()方法,使用switch-case分支进行判断需要执行的选项是那个。 Scanner sc =new Scanner(System.in); int choose = sc.nextInt(); switch (choose){ case 1: addWebSite(); break; case 2: modifyWebSite(); break; case 3: dropWebSite(); break; case 4: queryWebSite(); break; case 0: System.out.println("退出系统"); System.exit(0); break; default: System.out.println("对不起,您的选择有误!"); break; }在新定义的方法上面按住alt+回车既可以出现快捷方式,点击第一个创建一个方法。
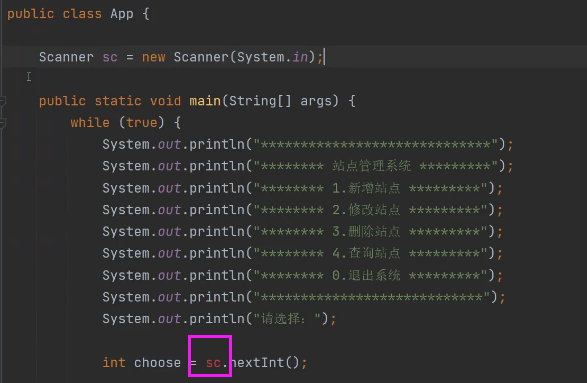
创建完成之后新增while(true)让程序可以一直执行,程序的中断将会由输入的0来决定退出去。 完整的这一块代码 public static void main(String[] args) throws SQLException { while (true) { System.out.println("***********************************"); System.out.println("*********** 站点管理系统 ***********"); System.out.println("*********** 1.新增站点 ***********"); System.out.println("*********** 2.修改站点 ***********"); System.out.println("*********** 3.删除站点 ***********"); System.out.println("*********** 4.查询站点 ***********"); System.out.println("*********** 0.退出系统 ***********"); System.out.println("**********************************"); System.out.println("请选择:"); Scanner sc =new Scanner(System.in); int choose = sc.nextInt(); switch (choose){ case 1: addWebSite(); break; case 2: modifyWebSite(); break; case 3: dropWebSite(); break; case 4: queryWebSite(); break; case 0: System.out.println("退出系统"); System.exit(0); break; default: System.out.println("对不起,您的选择有误!"); break; } } } 3.4.2 系统添加数据模块方法例如以下的方法 private static void dropWebSite() { System.out.println("请输入要删除的站点名称:"); //sc.next方法将不会用到 //前面设置的sc变量是只能在main方法里面使用,要想使用需要将sc变量放在外面使用 }解决方法:将sc变量放在main方法外面即可。变成整个类的作用方法
虽然提出来了,但是scanner的方法仍然不能使用,会出错,原因是sc为成员变量,main是静态的方法,静态的方法只能访问静态的方法,不能访问类里面的变量,需要将scanner变成一个静态的变量。
加入关键字static即可访问其方法 接下来继续编写方法原来实现相关功能 3.4.3 编辑MySQL与druid依赖官方的网站链接如下: Maven Repository: Search/Browse/Explore (mvnrepository.com) 在官方网站里面直接搜素需要的依赖即可
选择mysql搜素,选择访问比较多的即可
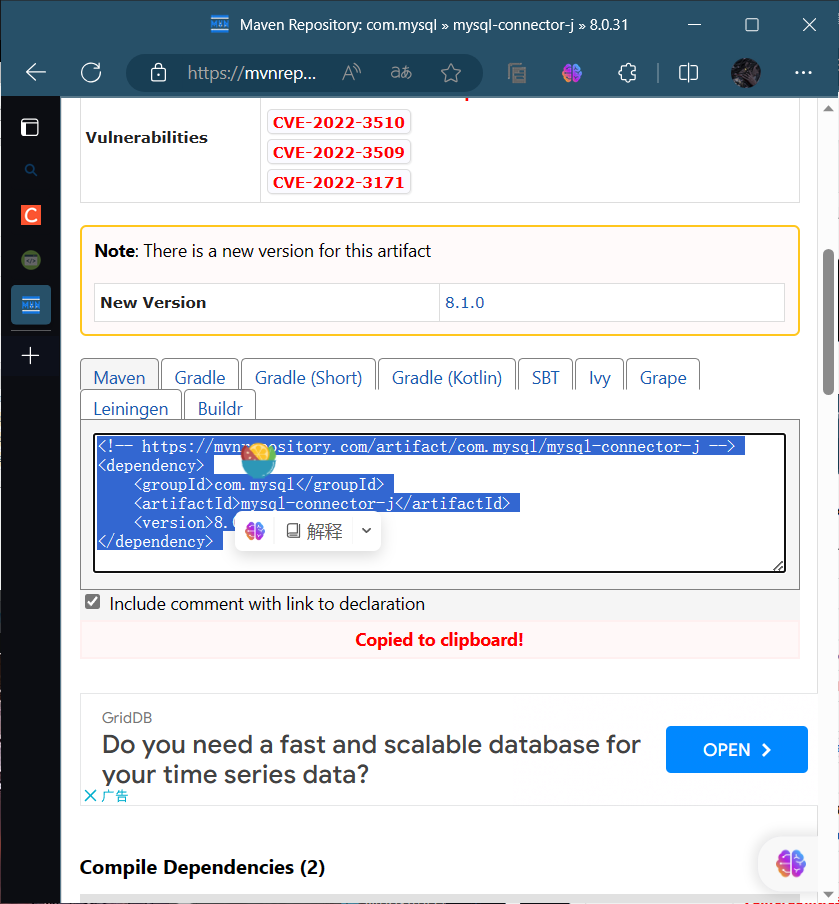
点击此处蓝色框住的部分即可复制,出现红色的提示即是复制成功
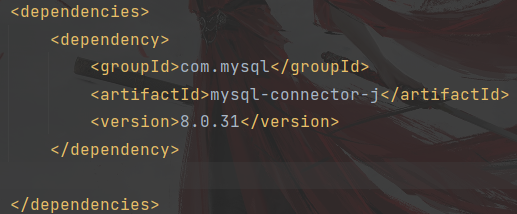
代码部分 com.mysql mysql-connector-j 8.0.31粘贴过来的显示为红色,如果之前未安装此组件的话,会有一个刷新的图标,点击一下,完成安装,安装完成之后红色部分会变成白色。
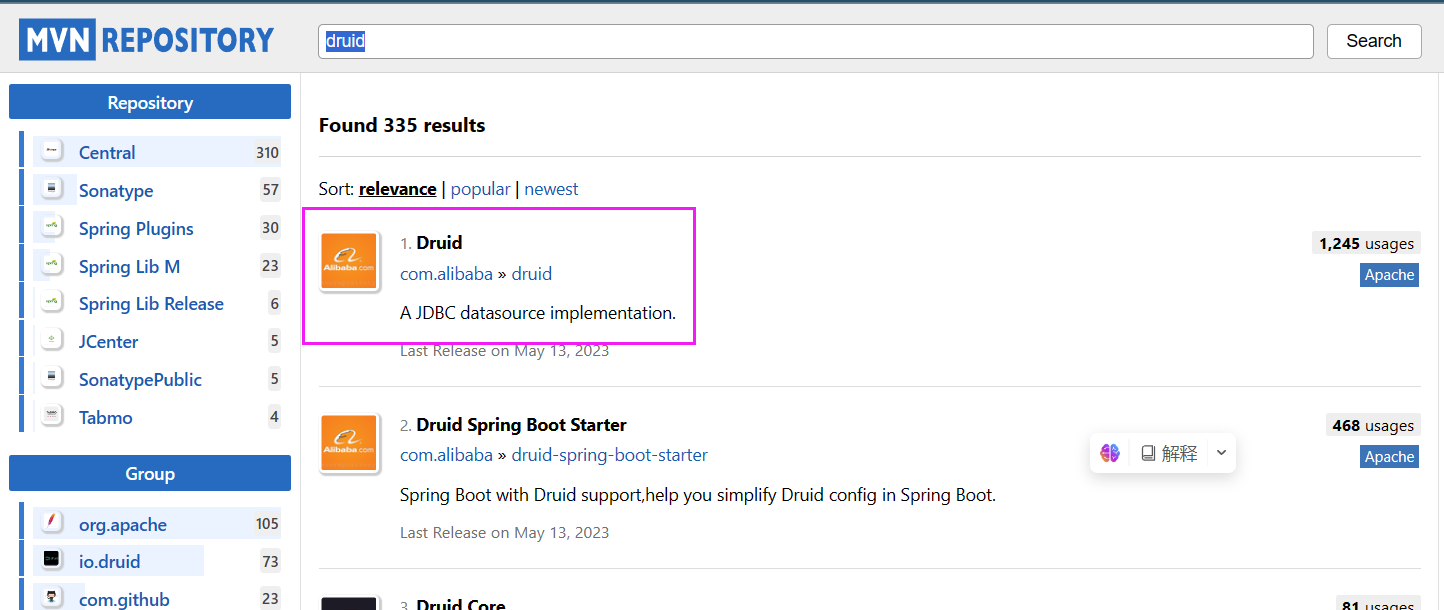
出现这种情况既是安装完成。 搜索druid依赖,点击第一个即可
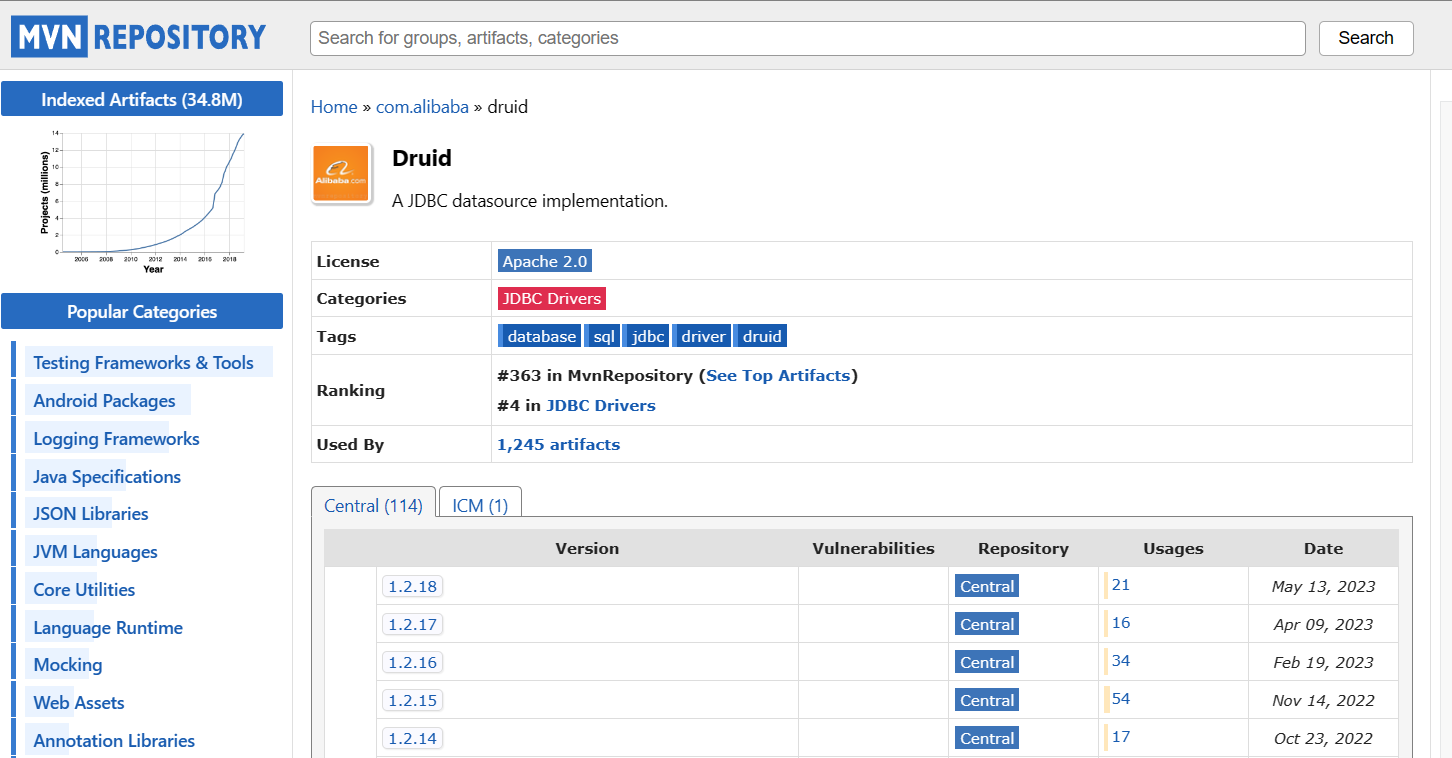
选择自己的对应版本
代码部分如下: com.alibaba druid 1.2.8粘贴上述代码即可。 3.4.4 编辑插入数据方法前面先给用户一个输入区,并且将输入的内容编辑为相关的变量暂时存在内存区,此时的数据并没有保存到数据库里面。
下面加入配置文件原来访问数据库,设置与前面的2.3.2 编辑配置文件相同。 利用类加载器原来加载配置文件,让文件以流的形式读进来,
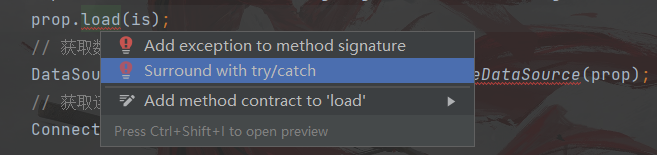
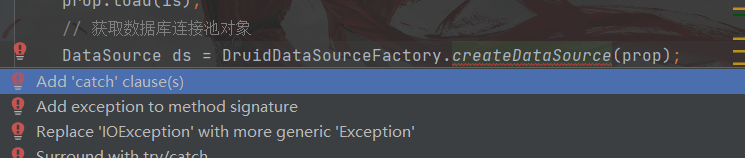
选择alt+enter,选择第二个,让异常抛出 此处还有异常,将异常的这段代码放在try-catch里面捕获一下抛出
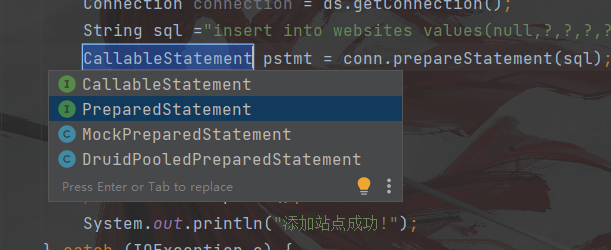
这样捕获异常 捕获完成之后会自动放在catch语句里面 // 加载配置文件 Properties prop = new Properties(); InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties"); try { prop.load(is); // 获取数据库连接池对象 DataSource ds = DruidDataSourceFactory.createDataSource(prop); // 获取连接 Connection connection = ds.getConnection(); } catch (IOException e) { e.printStackTrace(); } catch (SQLException throwables) { throwables.printStackTrace(); } catch (Exception e) { e.printStackTrace(); }此处创建一个预编译对象
完成之后使用其方法获取相关的数据,将其插入到数据库里面。 完整的插入代码 private static void addWebSite() { System.out.println("请输入站点名称:"); String name = sc.next(); System.out.println("请输入站点URL:"); String url = sc.next(); System.out.println("请输入站点alexa:"); int alexa = sc.nextInt(); System.out.println("请输入站点所属国家:"); String country = sc.next(); // 1 加载配置文件 Properties prop = new Properties(); InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties"); try { prop.load(is); // 2 获取数据库连接池对象 DataSource ds = DruidDataSourceFactory.createDataSource(prop); // 3 获取连接 Connection connection = ds.getConnection(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="insert into websites values(null,?,?,?,?)"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置参数 stmt.setString(1,name); stmt.setString(2,url); stmt.setInt(3,alexa); stmt.setString(4,country); stmt.executeUpdate(); // 获取插入完成的值,一般插入完成之后会出现·插入影响的行数 // 将返回变量的类型设置为int型 int row = stmt.executeUpdate(); //提示一下 if (row != 0){ System.out.println("添加站点成功!"); } } catch (IOException e) { e.printStackTrace(); } catch (SQLException throwables) { throwables.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } 3.4.5 编辑查询代码PS:此处为未经优化的代码段 ,后续有优化之后的代码段。 在上述的插入代码的基础之上编辑查询代码即可。 private static void queryWebSite() { // 1 加载配置文件 Properties prop = new Properties(); InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties"); try { prop.load(is); // 2 获取数据库连接池对象 DataSource ds = DruidDataSourceFactory.createDataSource(prop); // 3 获取连接 Connection connection = ds.getConnection(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="select * from websites"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置返回的参数,此处的返回值为结果集 ResultSet rs = stmt.executeQuery(); // 获取查询到的结果集 while (rs.next()){ // 将结果集拼接起来 System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3) + "-" + rs.getInt(4) + "-" + rs.getString(5)); } } catch (IOException e) { e.printStackTrace(); } catch (SQLException throwables) { throwables.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } }此处的获取数据库连接可以创建一个DruidUtil类来专门获取数据库连接 工具类的完整代码【此处就是将获取数据库连接的部分一一个类的形式创建,此时可以优化一下之前的代码】 优化之后的插入数据代码 private static void addWebSite() { System.out.println("请输入站点名称:"); String name = sc.next(); System.out.println("请输入站点URL:"); String url = sc.next(); System.out.println("请输入站点alexa:"); int alexa = sc.nextInt(); System.out.println("请输入站点所属国家:"); String country = sc.next(); try { // 3 获取连接,此处使用类方法进行调用。 Connection connection = DruidUtil.getConn(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="insert into websites values(null,?,?,?,?)"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置参数 stmt.setString(1,name); stmt.setString(2,url); stmt.setInt(3,alexa); stmt.setString(4,country); stmt.executeUpdate(); // 获取插入完成的值,一般插入完成之后会出现·插入影响的行数 // 将返回变量的类型设置为int型 int row = stmt.executeUpdate(); //提示一下 if (row != 0){ System.out.println("添加站点成功!"); } // 原先的异常处理也就不再需要,直接删除即可 } catch (SQLException throwables) { throwables.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } }优化之后的查询代码 private static void queryWebSite() { try { // 3 获取连接 Connection connection = DruidUtil.getConn(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="select * from websites"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置返回的参数,此处的返回值为结果集 ResultSet rs = stmt.executeQuery(); // 获取查询到的结果集 while (rs.next()){ // 将结果集拼接起来 System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3) + "-" + rs.getInt(4) + "-" + rs.getString(5)); } } catch (SQLException throwables) { throwables.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } 3.4.6 完整的优化后的代码 package com.ambow.druid; import java.sql.*; import java.util.Scanner; public class work01 { static Scanner sc =new Scanner(System.in); public static void main(String[] args){ while(true) { System.out.println("***********************************"); System.out.println("*********** 站点管理系统 ***********"); System.out.println("*********** 1.新增站点 ***********"); System.out.println("*********** 2.修改站点 ***********"); System.out.println("*********** 3.删除站点 ***********"); System.out.println("*********** 4.查询站点 ***********"); System.out.println("*********** 0.退出系统 ***********"); System.out.println("**********************************"); System.out.println("请选择:"); Scanner sc = new Scanner(System.in); int choose = sc.nextInt(); switch (choose) { case 1: addWebSite(); break; case 2: modifyWebSite(); break; case 3: dropWebSite(); break; case 4: queryWebSite(); break; case 0: System.out.println("退出系统"); System.exit(0); break; default: System.out.println("对不起,您的选择有误!"); break; } } } private static void addWebSite() { System.out.println("请输入站点名称:"); String name = sc.next(); System.out.println("请输入站点URL:"); String url = sc.next(); System.out.println("请输入站点alexa:"); int alexa = sc.nextInt(); System.out.println("请输入站点所属国家:"); String country = sc.next(); try { // 3 获取连接,此处使用类方法进行调用。 Connection connection = DruidUtil.getConn(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="insert into websites values(null,?,?,?,?)"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置参数 stmt.setString(1,name); stmt.setString(2,url); stmt.setInt(3,alexa); stmt.setString(4,country); stmt.executeUpdate(); // 获取插入完成的值,一般插入完成之后会出现·插入影响的行数 // 将返回变量的类型设置为int型 int row = stmt.executeUpdate(); //提示一下 if (row != 0){ System.out.println("添加站点成功!"); } // 原先的异常处理也就不再需要,直接删除即可 } catch (SQLException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } private static void modifyWebSite() { System.out.println("请输入要修改的站点名称:"); String name = sc.next(); System.out.println("请输入新站点URL:"); String url = sc.next(); System.out.println("请输入新站点alexa:"); int alexa = sc.nextInt(); System.out.println("请输入新站点所属国家:"); String country = sc.next(); try { // 3 获取连接 Connection connection = DruidUtil.getConn(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="update websites set url=?,alexa= ?,country=? where name=?"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置参数 stmt = connection.prepareStatement(sql); stmt.setString(1,name); stmt.setString(2,url); stmt.setInt(3,alexa); stmt.setString(4,country); stmt.executeUpdate(); int row = stmt.executeUpdate(); //提示一下 if (row != 0){ System.out.println("修改站点成功!"); } } catch (SQLException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } private static void dropWebSite() { System.out.println("请输入要删除的站点名称:"); String name = sc.next(); try { // 3 获取连接 Connection connection = DruidUtil.getConn(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="delete from websites where name=?"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置参数 stmt.setString(1,name); stmt.executeUpdate(); // 获取插入完成的值,一般插入完成之后会出现·插入影响的行数 // 将返回变量的类型设置为int型 int row = stmt.executeUpdate(); //提示一下 if (row != 0){ System.out.println("删除站点成功!"); } } catch (SQLException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } private static void queryWebSite() { try { // 3 获取连接 Connection connection = DruidUtil.getConn(); // 4 执行SQL //插入SQL语句,?为占位符 String sql ="select * from websites"; //创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。 PreparedStatement stmt = connection.prepareStatement(sql); //设置返回的参数,此处的返回值为结果集 ResultSet rs = stmt.executeQuery(); // 获取查询到的结果集 while (rs.next()){ // 将结果集拼接起来 System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3) + "-" + rs.getInt(4) + "-" + rs.getString(5)); } } catch (SQLException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } } 思考——如何优化上述的Java代码?优化方案——使用分层将代码分为几个模块 1、视图层 2、持久层 / 数据访问层 Dao -- Data Access Object 数据访问层 优化的方案将会在后续的文章当中给出具体的操作。 jdbc是硬编码的方式 SQL语句也是硬编码,缺点是不易维护
mybatis框架 以上就是今天的内容~ 欢迎大家点赞👍,收藏⭐,转发🚀, 如有问题、建议,请您在评论区留言💬哦。 最后:转载请注明出处!!! |

















 红色框住的是8.0版本以上的,选择自己的对应版本即可。此处小编的版本为8.0的版本,选择这个即可
红色框住的是8.0版本以上的,选择自己的对应版本即可。此处小编的版本为8.0的版本,选择这个即可

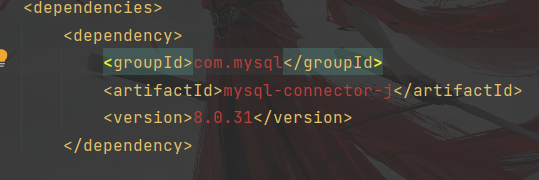





【本文地址】
今日新闻 |
推荐新闻 |