Apache Iceberg 是什么? |
您所在的位置:网站首页 › iceberg架构原理 › Apache Iceberg 是什么? |
Apache Iceberg 是什么?
|
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据技术体系 WHAT
Apache Iceberg 是一种用于庞大分析数据集的开放表格式。 表格式(Table Format)的功能是确定该如何管理、组织和跟踪构成表的所有文件。可以将其视为物理数据文件(用 Parquet 或 ORC 等编写)以及它们如何结构形成表之间的抽象层。 Iceberg 使用类似于 SQL 表的高性能表格式为计算引擎添加了表,包括 Spark、Trino、PrestoDB、Flink、Hive 和 Impala。 好处使用快照模式意味着 Iceberg 可以保证读写的隔离性。 读者将始终看到数据的一致版本(即没有“脏读”),而无需锁表。 写入器单独工作,不影响实时表,并且仅在写入完成时执行元数据交换,在一个原子提交中进行更改。 使用快照还可以启用时间旅行操作,因为用户可以通过指定要使用的快照对表的不同版本执行各种操作。 使用 Iceberg 也有巨大的性能优势。 在作业规划期间,Iceberg 并没有采用 O(n) 的时间复杂度来列出表中的分区,而是执行时间复杂度是 O(1) 的 RPC 来读取快照。 文件修剪和谓词下推也可以分发到作业中,因此 Hive 元存储不再是一个瓶颈。 这也消除了使用细粒度分区的障碍。 由于每个数据文件存储的统计数据,可用的文件修剪也大大加快了查询规划。 特性 模式演变(Schema Evolution) 支持添加、删除、更新或重命名,并且没有副作用隐藏分区(Hidden Partitioning) 可以防止用户错误地造成静默不正确的结果或者极慢的查询分区布局演变(Partition Layout Evolution) 可以随着数据量或查询模式的变化更新表的布局时间旅行(Time Travel) 允许使用完全相同的表快照的可重现查询,或允许用户轻松检查更改版本回滚(Version Rollback) 允许用户通过将表重置为良好状态来快速纠正问题 可靠性和性能Iceberg 是因庞大数据表而诞生的。 生产环境中 Iceberg 单表可以包含几十 PB 的数据,即使在没有分布式 SQL 引擎的情况下这些大表也可以读取。 扫描计划速度很快——读取表或查找文件不需要分布式 SQL 引擎高级过滤-使用表元数据用分区和列级统计信息修剪数据文件Iceberg 旨在解决最终一致的云对象存储中的正确性问题。 适用于任何云存储,并通过避免 list 和重命名来减少 HDFS 中的 NameNode 拥塞串行化的隔离性——表更改是原子的,读者永远不会看到部分或未提交的更改多个并发编写者使用乐观的并发性,并且在写入冲突的情况下也能重试以确保兼容的更新成功 内部细节Iceberg 项目最初是在 Netflix 开发的,旨在解决他们使用庞大的 PB 规模表的长期问题。 它于 2018 年作为 Apache 孵化器项目开源,并于 2020 年 5 月 19 日从孵化器毕业 🎉 Iceberg 一开始就被设计用于云端,一个关键考虑因素是解决 Hive 在与位于 S3 中的数据一起使用时遇到的各种数据一致性和性能问题。 Hive 在“文件夹”级别(即非文件级别)跟踪数据,因此在处理表中的数据时需要执行文件列表(file list)操作。 当需要执行其中许多操作时,这可能会导致性能问题。 当文件列表操作在 S3 等最终一致的对象存储中执行文件列表操作时,数据也可能丢失。 Iceberg 通过使用持久树结构跟踪表中所有文件的完整列表来避免这种情况。 对表的更改使用原子的对象/文件级别的提交,将路径更新为包含一个新元数据文件,包含所有独立数据文件的位置。
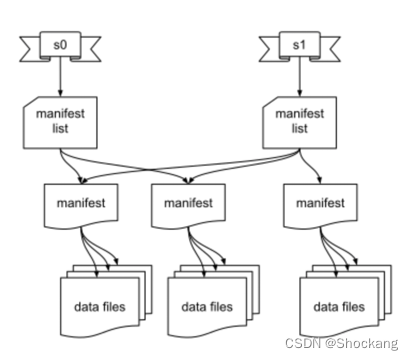
Iceberg 跟踪单个文件而不是文件夹的另一个优势是,不再需要昂贵的列表操作,这导致在执行查询表中数据等操作时性能的提高。 表状态存储在许多不同的元数据文件中,这些文件如上图所示,并在下面更详细地描述: 快照元数据文件:包含有关表的元数据,如表模式(Schema)、分区规范以及清单列表的路径。清单列表:包含与快照关联的每个清单文件的条目。每个条目都包含一个清单文件的路径和有关文件的一些元数据,包括分区统计和数据文件计数。这些统计数据可用于避免读取操作不需要的清单。清单文件:包含相关数据文件的路径列表。数据文件的每个条目都包含一些关于该文件的元数据,例如每列的上限和下限,可用于在查询规划期间修剪文件。数据文件:物理数据文件,以 Parquet、ORC、Avro 等格式编写。 |

【本文地址】
今日新闻 |
推荐新闻 |