无所不能的requests |
您所在的位置:网站首页 › html代理页面 › 无所不能的requests |
无所不能的requests
|
官网介绍
全面支持解析JavaScript!
CSS 选择器 (jQuery风格, 感谢PyQuery).
XPath 选择器, for the faint at heart.
自定义user-agent (就像一个真正的web浏览器).
自动追踪重定向.
连接池与cookie持久化.
令人欣喜的请求体验,魔法般的解析页面.
异步支持
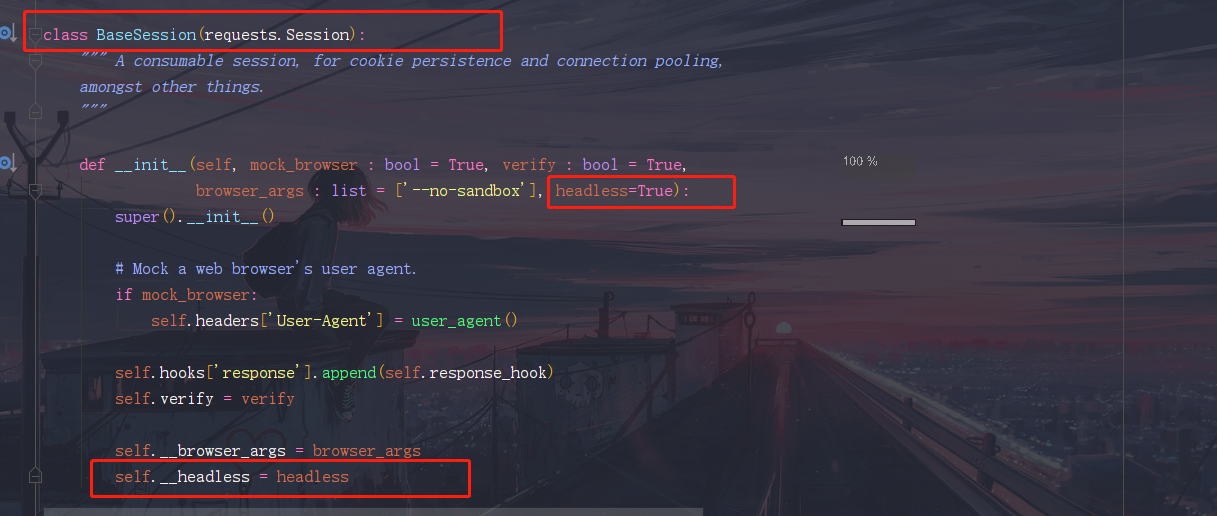
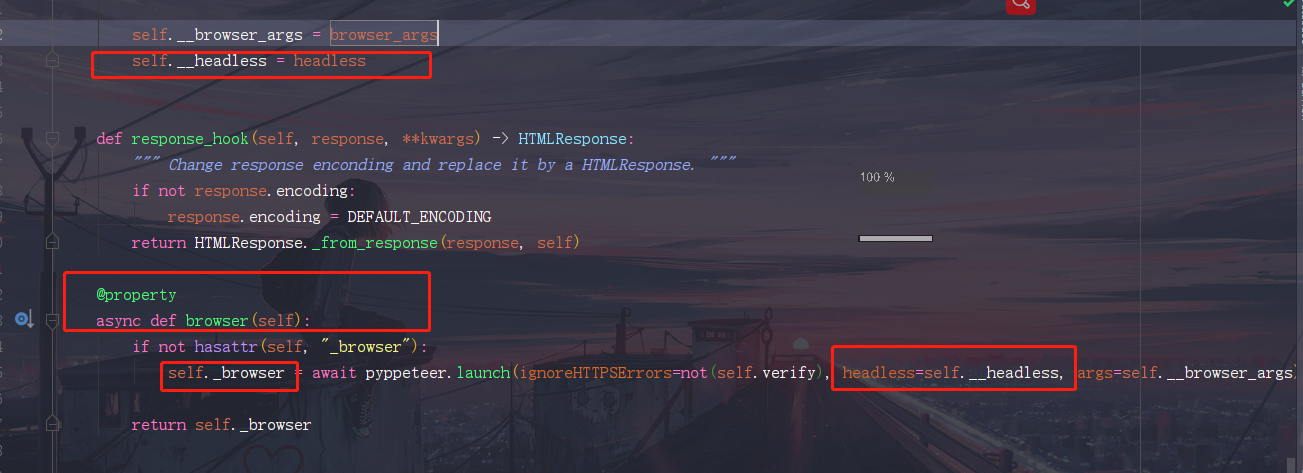
GitHub地址 一、安装 $ pip install requests-html只支持python3.6及以上 二、使用方法构造一个访问python.org的GET请求,从源码可以知道其实是使用requests的get方法 from requests_html import HTMLSession session = HTMLSession() r = session.get('https://python.org/') # 响应对象 = session.request(......) # 响应对象 = session.get(......) # 响应对象 = session.post(......) r 的属性参数 r1 = session.get('https://python.org/') # 相当于 r2 = requests.get('https://python.org/')所以,r1和r2属性参数都是一样的,都可以使用r.url r.text等属性方法,跟requests模块使用方法是一样的,因为其内部是使用requests模块的。 2.HTMLSession()的参数 session = HTMLSession( browser_args=[ '--no-sand', # 沙箱环境 '--user-agent=XXXXX' # 自定义UA ], headless=False # 需要修改源码才能设置该参数,默认不能启动浏览器模拟,改了之后设置headless=False就可以模拟 )headless源码修改: --->HTMLSession---->BaseSession 在BaseSession的__init__方法添加一个关键字参数headless=True,再实例化对象添加多一个参数self.__headless = headless
在BaseSession的browser方法的返回对象self._browser实例化传入该参数即可
注意:如果想要模拟启动浏览器,必须执行r.html.render()方法 三、r.html对象(HTML类)r.html事实上就是一个解析后的html对象,是基于HTML类的 from requests_html import HTML r.html属性和方法: absolute_links页面上所有可被获取到的超链接,都会被转成绝对路径形式。 base_url页面的基准URL,支持``标签(了解更多)。 encoding用于编码 从HTML和html响应头中提取的内容进行编码的格式 findfind(selector: str = '*', *, containing: Union[str, typing.List[str]] = None, clean: bool = False, first: bool = False,_encoding: str = None) → Union[typing.List[_ForwardRef('Element')], _ForwardRef('Element')] 接收一个css选择器参数,返回一个Element对象或Element对象组成的列表。 *参数说明*: selector - css选择器 clean - 对找到的和是否进行处理 containing - 如果指定,则只会返回包含指定文本的Element对象 first - 是否只返回第一个结果 _encoding - 编码格式CSS选择器示例: a a.someClass a#someID a[target=_blank]查看CSS选择器的更多详细内容 如果first参数被置为True, 则只返回找到的第一个Element对象 full_text返回Element对象或HTML中的所有文本(包括链接) html返回Unicode行式的HTML内容(了解更多) links返回页面所有链接,并保留链接的原本形式 lxml返回lxml行式的HTML内容或lxml对象 pq返回PyQuery 行式的HTML内容 raw_html返回字节行式的HTML内容(了解更多) renderrender(retries: int = 8, script: str = None, wait: float = 0.2, scrolldown=False, sleep: int = 0, reload: bool = True, timeout: Union[float, int] = 8.0, keep_page: bool = False) 执行JavaScript,在Chromium里重新加载响应,并用最新获取到的HTML替换掉原来的HTML。 r.html.render() 首次执行该方法是,模块会检查依赖,并下载chromium,chromium是什么鬼,看起来很像chrome? 搞过selenium的应该知道,这里简单对比下chrome和chromium: Chromium是谷歌的开源项目,开发者们可以共同去改进它,然后谷歌会收集改进后的Chromium并发布改进后安装包。Chrome不是开源项目,谷歌会把Chromium的东西更新到Chrome中。你也可以这么理解Chromium是体验版,Chrome是正式版; Chromium不用安装,下载下来的是压缩包,解压后直接就可以使用。Chrome需要安装; Chromium功能比Chrome多,因为新功能都是先在Chromium中使用,等完善后才添加到Chrome中。相对的Chrome就要比Chromium稳定很多不容易出错; Chromium不开放自动更新功能,所以用户需手动下载更新,而Chrome则可自动连上Google的服务器更新,但新版的推出很慢。*参数说明*: retries - 在Chromium里加载页面的重试次数 script - 执行页面上的JavaScript(可选参数) wait - 页面加载前的等待时间,防止超时(单位:秒,可选参数) scrolldown - 接收整数参数n。如果提供参数n,表示向后翻n页 sleep - 接收整数参数n。如果提供参数n,则在render初始化后,程序会暂停n秒 reload - 如果为False,则不会重新从浏览器加载内容,而是读取内存里的内容 keep_page - 如果为True,将会允许你通过r.html.page与浏览器页面交互如果scrolldown和sleep都指定,那么程序会在暂停相应时间后,再往后翻页面(如:scrolldown=10, sleep=1) 如果仅指定了sleep,程序会暂停相应时间,再返回数据 如果指定script,他将会在运行时执行提供的JavaScript。如: script = """ () => { return { width: document.documentElement.clientWidth, height: document.documentElement.clientHeight, deviceScaleFactor: window.devicePixelRatio, } } """返回一段JavaScript的返回值: >>> r.html.render(script=script) {'width': 800, 'height': 600, 'deviceScaleFactor': 1}*警告*:如果你使用keep_page, 你最好关闭已经使用过的页面,如果打开过多页面会造成浏览器崩溃。 *警告*:如果你第一次运行这个方法,它将会下载Chromium保存在你的家目录下。 最后,因为在爬虫中,我们使用了webdriver,浏览器会默认识别到,会去告诉服务器我们是webdriver,会进行反爬措施,所以我们需要,关掉浏览器的识别,加入下面这条js代码即可 绕过网站对webdriver的检测: ''' () =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => undefined } }) } ''' search**search*(template: str*) → parse.Result 根据传入的模板参数,查找Element对象 参数说明: template - 模板参数 search_allsearch_all(template: str) → Union[typing.List[_ForwardRef('Result')], _ForwardRef('Result')] 根据传入的模板参数,查找所有的Element对象 参数说明: template - 模板参数 xpathxpath(selector: str, *, clean: bool = False, first: bool = False, _encoding: str = None) → Union[typing.List[str], typing.List[_ForwardRef('Element')], str, _ForwardRef('Element')] 传入一个XPath选择器参数,返回所有的Element对象 *参数说明*: selector - xpath选择器 clean - 对找到的和是否进行处理 first - 是否只返回第一个结果 _encoding - 编码格式如果指定了一个子选择器(如://a/@href),将返回一个简单的结果列表 查看更多细节Xpath示例 如果first参数被置为True, 则只返回找到的第一个Element对象 四、Element类class requests_html.Element(*, element, url: str, default_encoding: str = None) → None 源码 HTML的一个element对象。 *参数说明*: element - 根据该参数进行解析 url - HTML对应的URL,absolute_links函数会调用该参数 default_encoding - 指定字符编码 Element对象方法及属性 absolute_links页面上所有可被获取到的超链接,都会被转成绝对路径形式。 attrs 返回一个字典,该字典包括**Element对象**的所有html属性。 base_url页面的基准URL,支持``标签(了解更多)。 encoding用于编码从HTML和html响应头中提取的内容 find**find*(selector: str = '', *, containing: Union[str, typing.List[str]] = None, clean: bool = False, first: bool = False,_encoding: str = None) → Union[typing.List[_ForwardRef('Element')], _ForwardRef('Element')] 接收一个css选择器参数,返回一个Element对象或Element对象组成的列表。 参数说明: selector - css选择器 clean - 对找到的和是否进行处理 containing - 如果指定,则只会返回包含指定文本的Element对象 first - 是否只返回第一个结果 _encoding - 编码格式CSS选择器示例: a a.someClass a#someID a[target=_blank]查看CSS选择器的更多详细内容 如果first参数被置为True, 则只返回找到的第一个Element对象 full_text返回Element对象或HTML中的所有文本(包括链接) html返回Unicode行式的HTML内容(了解更多) links返回页面所有链接,并保留链接的原本形式 lxml返回lxml行式的HTML内容 pq返回PyQuery 行式的HTML内容 raw_html返回字节行式的HTML内容(了解更多) searchsearch(template: str) → parse.Result 根据传入的模板参数,查找Element对象 *参数说明*: template - 模板参数 search_allsearch_all(template: str) → Union[typing.List[_ForwardRef('Result')], _ForwardRef('Result')] 根据传入的模板参数,查找所有的Element对象 *参数说明*: template - 模板参数 text返回Element对象或HTML对象的文本内容(不包含html标签) xpathxpath(selector: str, *, clean: bool = False, first: bool = False, _encoding: str = None) → Union[typing.List[str], typing.List[_ForwardRef('Element')], str, _ForwardRef('Element')] 传入一个XPath选择器参数,返回所有的Element对象 *参数说明*: selector - xpath选择器 clean - 对找到的和是否进行处理 first - 是否只返回第一个结果 _encoding - 编码格式如果指定了一个子选择器(如://a/@href),将返回一个简单的结果列表 查看更多细节Xpath示例 如果first参数被置为True, 则只返回找到的第一个Element对象 五、比较实用的方法 user_agent*requests_html.user_agent*(style=None) → str 源码 返回一个指定风格的合法的用户代理,默认是Chrome风格的用户代理 六、HTML Sessions这些sessions用于构造http请求。 class requests_html.HTMLSession(mock_browser=True) 源码 它是一个可被销毁的session,可用于cookie持久化和连接池,以及其他地方。 close()关闭一个已经被创建的浏览器 delete(url, **kwargs)发送一个DELETE请求,返回一个Response对象 *参数说明*: url - 新的请求对象的URL **kwargs - request携带的参数(可选)*返回类型*: requests.Response get_adapter(url)返回指定url的一个合适的连接适配器 *返回类型*: requests.adapters.BaseAdapter get_redirect_target(resp)接收一个响应,返回重定向后的URL或none head(url, **kwargs)发送一个HEAD请求,返回一个Response对象 *参数说明*: url - 新的请求对象的URL **kwargs - request携带的参数(可选)*返回类型*: requests.Response merge_environment_settings(url, proxies, stream, verify, cert)检查环境变量并与其他设置合并 *返回类型*:字典 mount(prefix, adapter)在前缀上注册连接适配器 适配器根据前缀长度降序排序 options(url, **kwargs)发送一个OPTIONS请求,返回一个Response对象 *参数说明*: url - 新的请求对象的URL **kwargs - request携带的参数(可选)*返回类型*: requests.Response patch(url, data=None, **kwargs)发送一个PATCH请求,返回一个Response对象 *参数说明*: url - 新的请求对象的URL data - 它被包含在请求对象中,它可以是字典、字节、文件(可选参数) **kwargs - request携带的参数(可选)*返回类型*: requests.Response post(url, data=None, json=None, **kwargs)发送一个POST请求,返回一个Response对象 *参数说明*: url - 新的请求对象的URL data - 它被包含在请求对象中,它可以是字典、字节、文件(可选参数) json - 它被包含在请求对象中,它是json(可选参数) **kwargs - request携带的参数(可选)*返回类型*: requests.Response prepare_request(request)构造一个预请求对象(PreparedRequest)。这个预请求对象的设置来自于已经设置好session的请求实例。 *参数说明*: request - 已经设置好session的请求实例*返回类型*: requests.PreparedRequest put(url, data=None, **kwargs)发送一个PUT请求,返回一个Response对象 *参数说明*: url - 新的请求对象的URL data - 它被包含在请求对象中,它可以是字典、字节、文件(可选参数) **kwargs - request携带的参数(可选)*返回类型*: requests.Response rebuild_auth(prepared_request, response)当被重定向的时候,我们可能要从请求对象中去掉认证信息,避免认证信息泄露。 本方法会自动去掉认证信息,并且重新申请授权,来避免认证信息泄露 rebuild_method(prepared_request, response)当被重定向的时候,我们可能要修改请求的方法,用来请求某个特殊的页面,或者适应某个 特殊的浏览器习惯。 rebuild_proxies(prepared_request, response)本方法会根据环境变量重新设置代理的配置。如果我们被重定向到一个不需要代理的URL, 我们将去掉代理的配置,否则,我们将给该URL添加缺失的代理配置(防止由于之前重定向去掉了代理而造成的请求错误)。 必要时,本方法可以替换Proxy-Authorization头。 *返回类型*: 字典 request(*args, **kwargs)request(*args, **kwargs) → requests_html.HTMLResponse 使用欺骗性地User–Agent头,构造一个HTTP请求。返回HTTPResponse类对象。 resolve_redirectsresolve_redirects(resp, req, stream=False, timeout=None, verify=True, cert=None, proxies=None, yield_requests=False, **adapter_kwargs) 接收一个响应对象,返回响应对象或请求对象的生成器。 send(request, **kwargs)发送预请求对象。必要时,本方法可以替换Proxy-Authorization头。 *返回类型*: requests.Response 七、与浏览器进行交互附:requests-html库render方法的使用 |
【本文地址】