mapreduce实例代码详解(一行一行的注释) |
您所在的位置:网站首页 › hive类型转换源码详解 › mapreduce实例代码详解(一行一行的注释) |
mapreduce实例代码详解(一行一行的注释)
|
mapreduce的相关概念,以及运行原理网上都有很多,建议先大致掌握一下mapreduce的基础工作方式再来看代码。 初开始学mapreduce看那一堆代码的时候很是郁闷,现在把我对每一行代码的理解写下来,希望对你们有一点帮助。 那么第一个实例,就按惯例来写词汇统计好了。 import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class word{ public static class MyMapper extends Mapper{ protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ String l = value.toString(); context.write(new Text(l),new IntWritable(1)); } } public static class MyReduce extends Reducer{ protected void reduce(Text key,Iterable values,Context context) throws IOException,InterruptedException{ int sum=0; for(IntWritable i : values){ sum+=i.get(); } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) throws InterruptedException,IOException,ClassNotFoundException{ Configuration conf=new Configuration(); Job job=Job.getInstance(conf,"top"); job.setJobName("top"); job.setJarByClass(word.class); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); job.waitForCompletion(true); } }这是完整代码,作用是对文件中的词汇进行统计,统计不同的词汇分别有多少个。比如说文件内容是I love hadoop I love mapreduce。就会输出I 2, love 2这样的统计。下面是代码解析。 初开始先导入jar包 import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; 上面这三个包基本上每个mapreduce程序都要导入,像IOException包就是用来处理输入输出流中的异常问题 import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; 这三个包就是你在下面的代码中用到的数据类型 一般有Text,LongWritable,IntWritable,NullWritable等 Text:文本信息,字符串类型String LongWritable:偏移量Long,表示该行在文件中的位置(不能笼统的当作行号使用) IntWritable:int类型,用于整数等数字 NullWritable:NullWritable是Writable的一个特殊类,实现方法是空方法,只充当占位符,在一些地方会用到,但是本实例中没有使用 import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 以上五个jar包是写mapreduce程序必带的,每次写程序之前都要导入。 public class word{ public static class MyMapper extends Mapper{ 定义map类,这里是固定格式public static class 类名 extends Mapper{ Mapper后面的括号中跟的是数据类型,也就是我们在导入jar包阶段提到的。前两个数据类型是读取数据时的格式, 通常情况下是,也就是 后两个数据类型输出的格式,也就是map阶段得到的键值对的对应的数据类型。 这里我打算在文件中,每一行只输入一个单词,这样map阶段输出的键值对就类似 至于为什么会输出这样的结果,往下看代码 protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ 这里基本也是固定格式 //protected void map(数据类型 key,数据类型 value,Context context) throws IOException,InterruptedException{ key和value前面的数据类型,就是上一句代码Mapper后面里面的前两个数据类型 上面这两句话就相当于一个大体的map类框架,现在要想实现mapreduce程序目标就要开始往里面填充内容了 String line = value.toString(); 定义line为value的String对象值 value其实之前我说的,文件里每一行有一个单词,此时value里面装的就是读取到的单词,将其转换为String类型,然后放到line里面 context.write(new Text(line),new IntWritable(1)); 格式为context.write(a,b); 输出以a为key,b为value的数据,这是Mapper输出的结果 这句话就解释了为什么Mapper阶段输出的结果是形式,line装的是love的String类型, 因为我们一开始设置的输出类型(Mapper的后两个)是Text,IntWritable, 所以这里要把line套上一个New Text()转换为Text数据类型,那个数字1同理,套上一个New IntWritable() } } public static class MyReduce extends Reducer{ 现在是在定义一个Reduce类,Reducer后面跟的数据类型,前两个就是Mapper输出的数据类型,与其保持一致。 后两个是Reduce端要输出的数据类型。 protected void reduce(Text key,Iterable values,Context context) throws IOException,InterruptedException{ key前面的数据格式就是从Mapper端接收到的数据格式 Iterable是遍历,排序的意思,要注意这里是values而不是value, 至于为什么要加个s,mapreduce的工作原理一类的文章中应该会提到 int sum=0; 对词汇进行统计,sum就是针对一个单词的次数设置的变量,这个单词出现多少次,sum的值就有多少 reduce是按key来从map任务那里领取数据的,我们之前是把一个单词作为一个key, 一把钥匙开一把锁,所以一个reduce端里面只会有一个单词,不用担心sum把其他单词的次数也算进去 for(IntWritable i : values){ sum+=i.get(); } for循环,举个例子 for(String s:args)是String定义一个变量s,然后从数组args[]中,每循环一次取出一个值赋给s。 这里是每次循环,从values中取出一个值放入i,然后sum每次加上i里面的值。 context.write(key,new IntWritable(sum)); 与Mapper端同理,输出结果,这里的结果就是最终结果,也就是mapreduce程序处理后结果形式。 } } public static void main(String[] args) throws InterruptedException,IOException,ClassNotFoundException{ //main方法 Configuration conf=new Configuration(); Job job=Job.getInstance(conf,"top"); job.setJobName("top"); job.setJarByClass(word.class); //上面四句话是设置类信息,方便hadoop从jar文件中找到 job.setMapperClass(MyMapper.class); job.setReducerClass(MyReduce.class); //设置执行Map与Reduce的类,也就是你之前设置的类名 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置Map端输出的数据类型,这两句话也可以不写 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输出数据类型,这两句话必须写 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); //添加输入输出路径 job.waitForCompletion(true); 像主方法里面的这么多句话,基本每次写mapreduce程序都要用到, 可以复制粘贴然后改一改数据类型和类名什么的就能用。 但是要注意的是,我这里给出的语句是在linux环境下运行eclipse的代码,在windows底下用这样的代码是不行的。 } }结果类似于 |
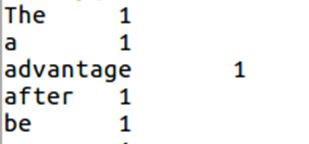
【本文地址】
今日新闻 |
推荐新闻 |