Hive命令行常用操作(数据库操作,表操作) |
您所在的位置:网站首页 › hive查看数据 › Hive命令行常用操作(数据库操作,表操作) |
Hive命令行常用操作(数据库操作,表操作)
|
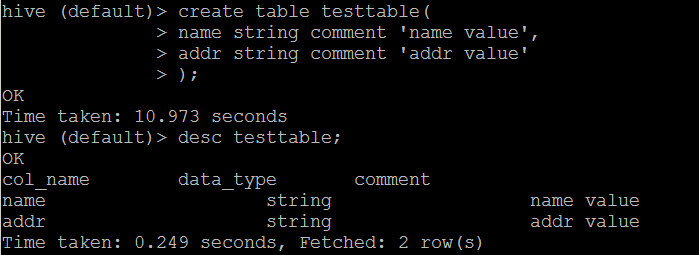
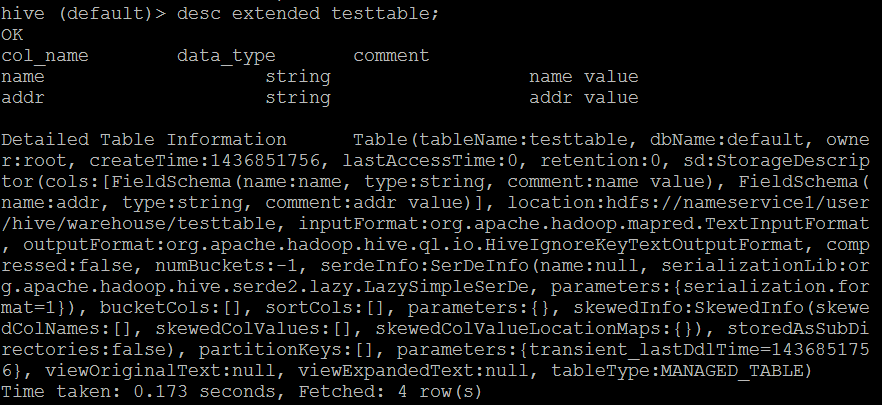
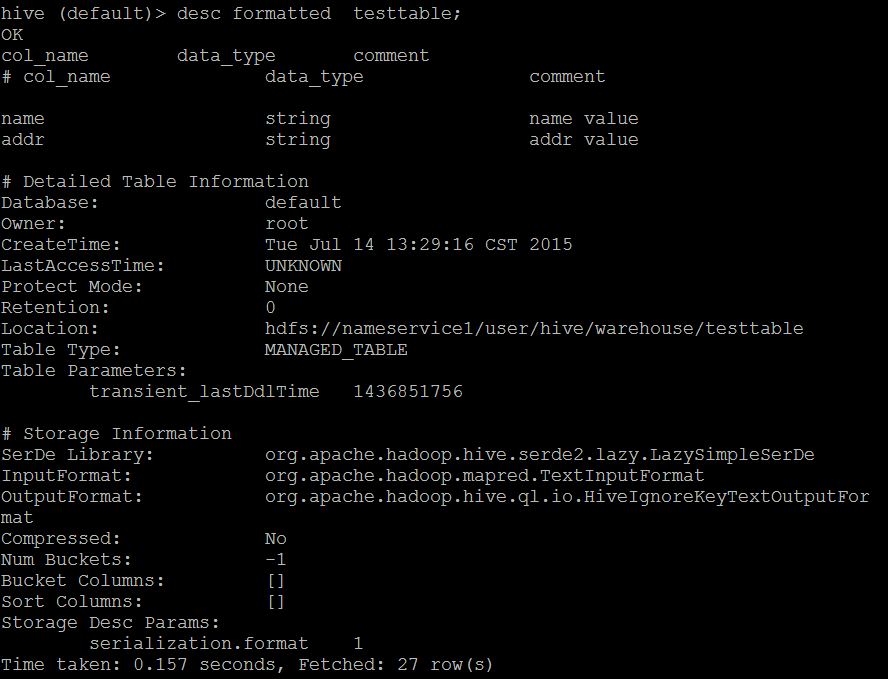
##数据库操作 ###查看所有的数据库 hive> show databases ; ###使用数据库default hive> use default; ###查看数据库信息 hive > describe database default; OK db_name comment location owner_name owner_type parameters default Default Hive database hdfs://hadoop1:8020/user/hive/warehouse public ROLE Time taken: 0.042 seconds, Fetched: 1 row(s) ###显示地展示当前使用的数据库 hive> set hive.cli.print.current.db=true; hive(default)> ###Hive显示列头 hive (default)> set hive.cli.print.header=true; hive (default)> desc addressall_2015_07_09; OK col_name data_type comment _c0 string addr1 bigint addr2 bigint addr3 bigint Time taken: 0.182 seconds, Fetched: 4 row(s) hive (default)> select * from addressall_2015_07_09; OK addressall_2015_07_09._c0 addressall_2015_07_09.addr1 addressall_2015_07_09.addr2 addressall_2015_07_09.addr3 2015_07_09 536 488 493 Time taken: 10.641 seconds, Fetched: 1 row(s) ###创建数据库命令 hive (default)> create database liguodong; OK Time taken: 10.128 seconds ###切换当前的数据库 hive (default)> use liguodong; OK Time taken: 0.031 seconds hive (liguodong)> ###删除数据库 删除数据库的时候,不允许删除有数据的数据库,如果数据库里面有数据则会报错。如果要忽略这些内容,则在后面增加CASCADE关键字,则忽略报错,删除数据库。 hive> DROP DATABASE DbName CASCADE(可选); hive> DROP DATABASE IF EXISTS DbName CASCADE; ##表操作 ###查看当前DB有啥表 hive> SHOW TABLES IN DbName; hive (liguodong)> SHOW TABLES IN liguodong; OK tab_name Time taken: 0.165 seconds 也可以使用正则表达式 hive> SHOW TABLES LIKE 'h*'; hive (default)> SHOW TABLES LIKE '*all*' ; OK tab_name addressall_2015_07_09 Time taken: 0.039 seconds, Fetched: 1 row(s)###获得表的建表语句 hive (default)> show create table address1_2015_07_09; OK createtab_stmt CREATE TABLE `address1_2015_07_09`( `addr1` bigint) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://nameservice1/user/hive/warehouse/address1_2015_07_09' TBLPROPERTIES ( 'COLUMN_STATS_ACCURATE'='true', 'numFiles'='1', 'numRows'='0', 'rawDataSize'='0', 'totalSize'='4', 'transient_lastDdlTime'='1436408451') Time taken: 0.11 seconds, Fetched: 17 row(s)###创建表 CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later) [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)] ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later) ] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later) [AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)hive (default)> create table test(id int); OK Time taken: 10.143 seconds ###获得表的建表语句 hive (default)> show create table test; OK createtab_stmt CREATE TABLE `test`( `id` int) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://nameservice1/user/hive/warehouse/test' TBLPROPERTIES ( 'transient_lastDdlTime'='1436799093') Time taken: 0.135 seconds, Fetched: 12 row(s)####创建内部表 其他获得表的信息
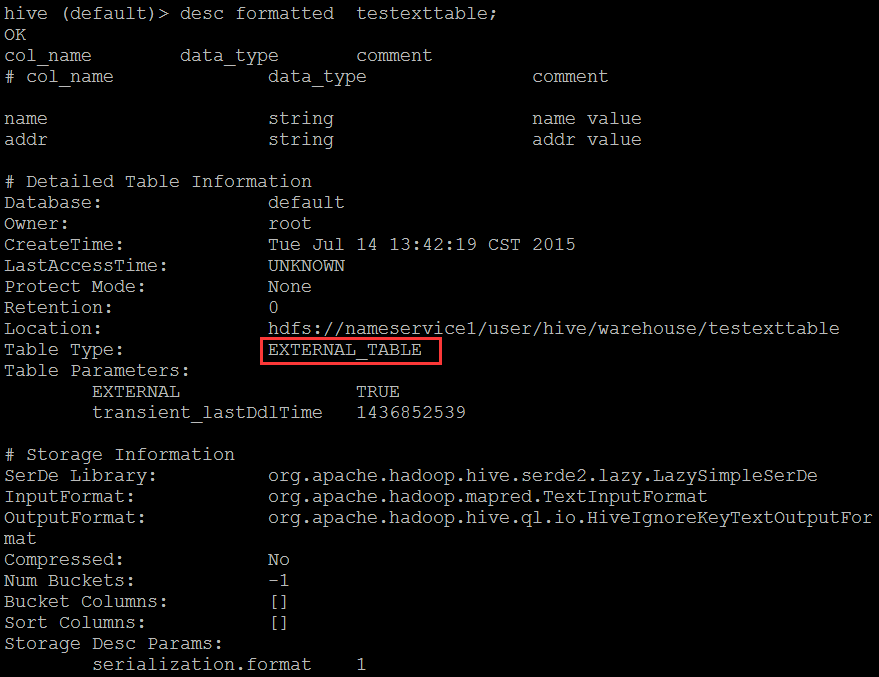
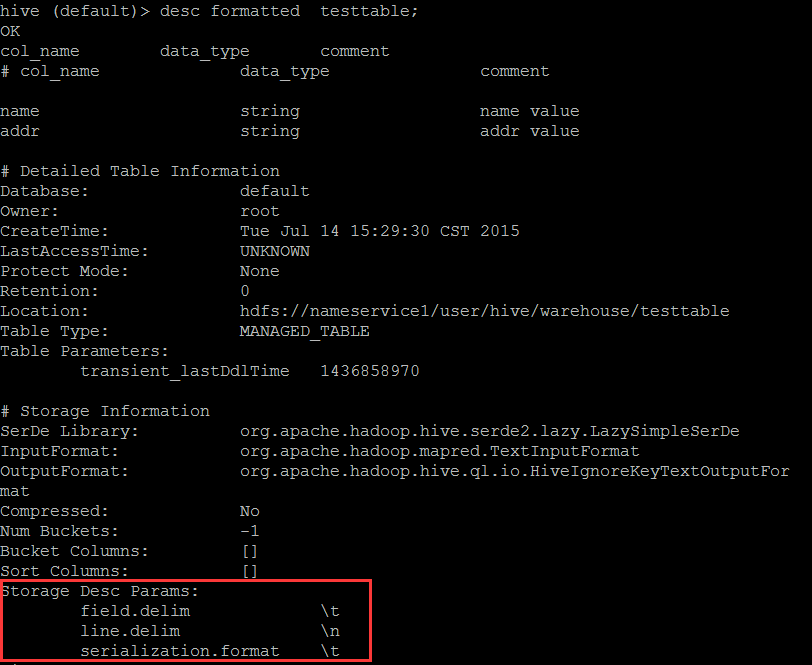
####创建外部表 hive (default)> create external table testexttable( > name string comment 'name value', > addr string comment 'addr value' > ); OK Time taken: 10.172 seconds
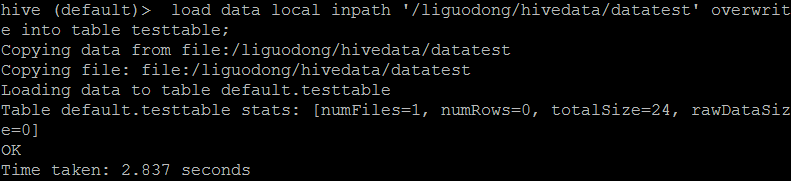
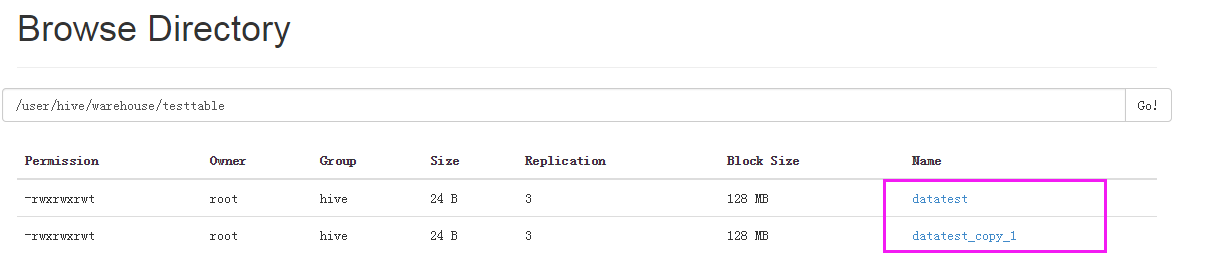
####加载数据 hive (default)> load data local inpath ‘/liguodong/hivedata/datatest’ overwrite into table testtable;
hive (default)> load data local inpath ‘/liguodong/hivedata/datatest’ into table testtable; 如果没有使用overwrite,则会再拷贝一份数据,不会覆盖原来的数据。
###查找表数据 hive> select * from employees; OK tony 1338 ["a1","a2","a3"] {"k1":1.0,"k2":2.0,"k3":3.0} {"street":"s1","city":"s2","state":"s3","zip":4} mark 5453 ["a4","a5","a6"] {"k4":4.0,"k5":5.0,"k6":6.0} {"street":"s4","city":"s5","state":"s6","zip":6} ivy 323 ["a7","a8","a9"] {"k7":7.0,"k8":8.0,"k9":9.0} {"street":"s7","city":"s8","state":"s9","zip":9} Time taken: 10.204 seconds, Fetched: 3 row(s) 查树组 hive> select subordinates[1] from employees; Total MapReduce CPU Time Spent: 2 seconds 740 msec OK a2 a5 a8 查map hive> select deductions["k2"] from employees; OK 2.0 NULL NULL Time taken: 75.812 seconds, Fetched: 3 row(s) 查结构体 hive> select address.city from employees; Total MapReduce CPU Time Spent: 2 seconds 200 msec OK s2 s5 s8 Time taken: 75.311 seconds, Fetched: 3 row(s)注意:select * 不执行mapreduce,只进行一个本地的查询。 而select 某个字段 生成一个job,执行mapreduce。 select * from employees; select * from employees limit 10;###删除表 内部表删除,会连同hdfs存储的数据一同删除,而外部表删除,只会删除外部表的元数据信息。 hive (default)> drop table testtable; OK Time taken: 10.283 seconds hive (default)> drop table testexttable; OK Time taken: 0.258 seconds###Hive建表的其他方式 ####有一个表,创建另一个表 (只是复制了表结构,并不会复制内容。) create table test3 like test2; 不需要执行mapreduce hive> desc testtable; OK name string name value addr string addr value Time taken: 0.267 seconds, Fetched: 2 row(s) hive> create table testtableNew like testtable; OK Time taken: 10.323 seconds hive> desc testtableNew; OK name string name value addr string addr value Time taken: 0.135 seconds, Fetched: 2 row(s)####从其他表查询,再创建表 (复制表结构的同时,把内容也复制过来了) create table test2 as select name,addr from test1; 需要执行mapreduce hive> create table testNewtable as select name,addr from testtable; hive> desc testNewtable; OK name string addr string Time taken: 0.122 seconds, Fetched: 2 row(s) hive> select * from testNewtable; OK liguodong cd aobama lsj Time taken: 10.226 seconds, Fetched: 4 row(s) |
【本文地址】
今日新闻 |
推荐新闻 |