【Hive】Windows下安装Hive(包安装成功)(附:常见错误解答FAQ(Frequently Asked Questions)) |
您所在的位置:网站首页 › hive数据库分区表 › 【Hive】Windows下安装Hive(包安装成功)(附:常见错误解答FAQ(Frequently Asked Questions)) |
【Hive】Windows下安装Hive(包安装成功)(附:常见错误解答FAQ(Frequently Asked Questions))
|
【Hive】Windows下安装Hive(包安装成功)(附:常见错误解答FAQ(Frequently Asked Questions))
前言一、Hive1.1、Hive简介1.2、Hive适用场景1.3、Hive设计特征1.4、Hive体系结构1.4.1、用户接口1.4.2、元数据存储1.4.3、解释器、编译器、优化器、执行器1.4.4、Hadoop
1.5、Hive数据模型1.5.1、Hive数据模型 - 表(Table)1.5.2、Hive数据模型 - 外部表(External Table)1.5.3、Hive数据模型 - 分区(Partition)1.5.4、Hive数据模型 - 桶(Bucket)
二、Hive下载2.1、官网下载Hive2.2、网盘下载Hive
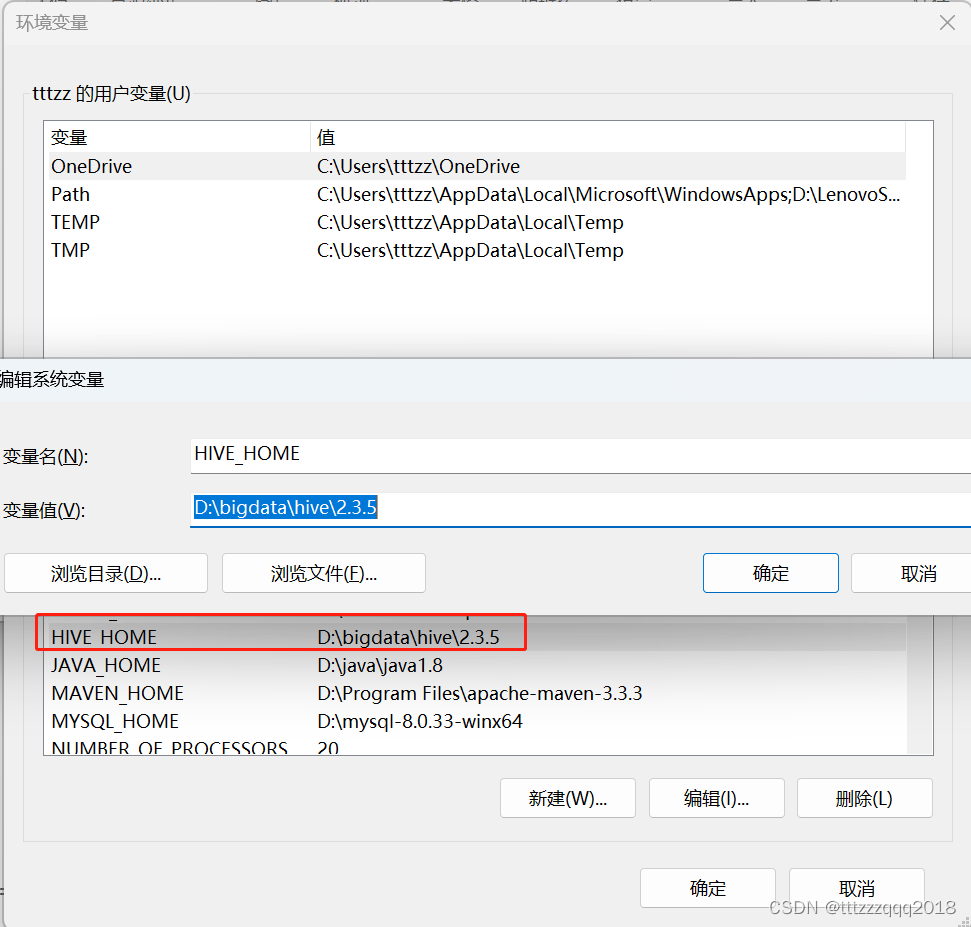
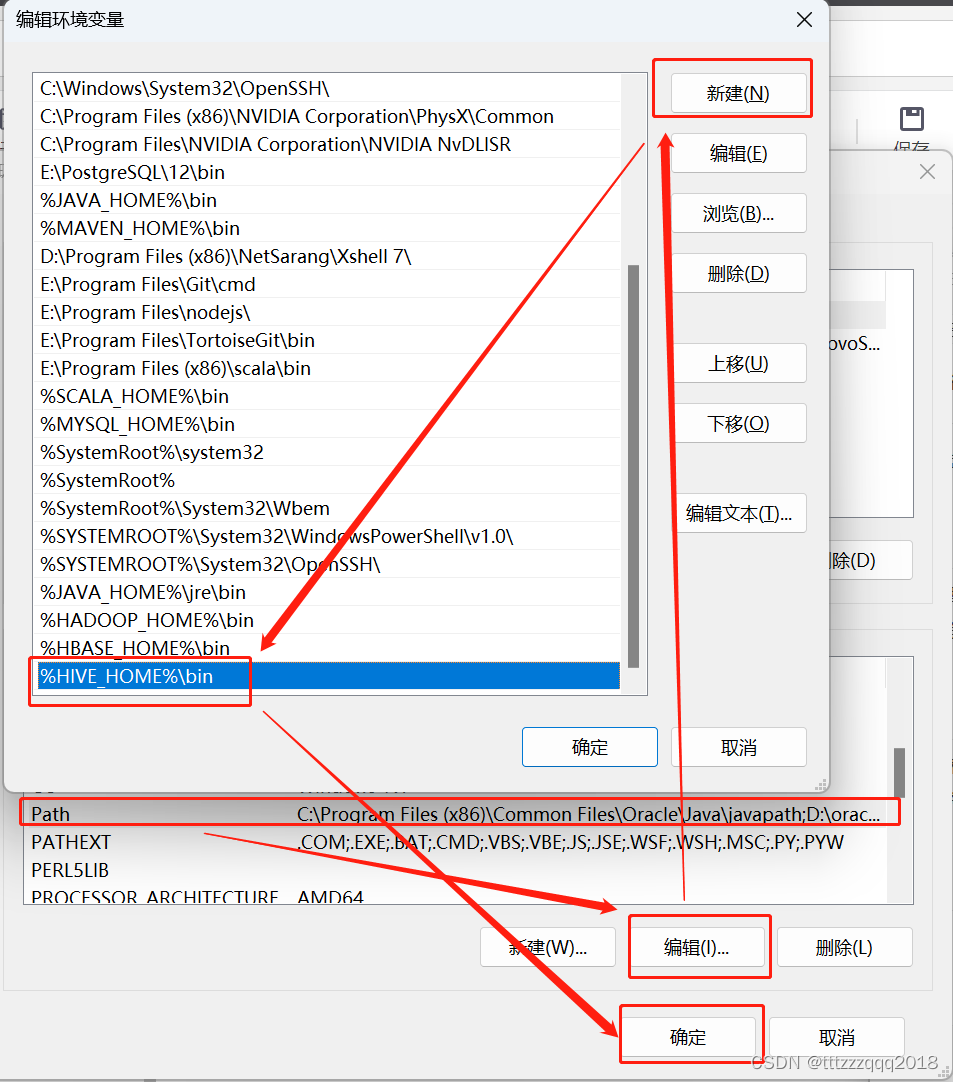
三、解压安装包,配置Hive环境变量3.1、环境变量新增:HIVE_HOME3.2、修改Path环境变量,增加Hive的bin路径
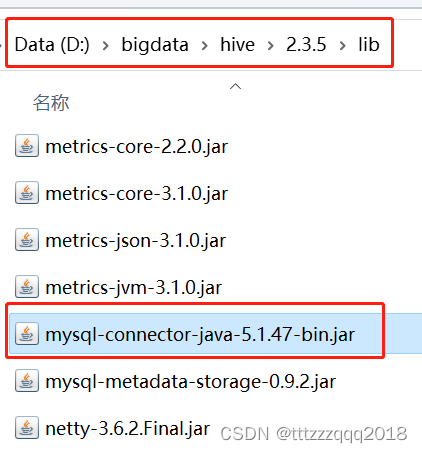
四、给Hive添加MySQL的jar包4.1、下载连接MySQL的依赖jar包“mysql-connector-java-5.1.47-bin.jar”4.2、拷贝到$HIVE_HOME/lib目录下
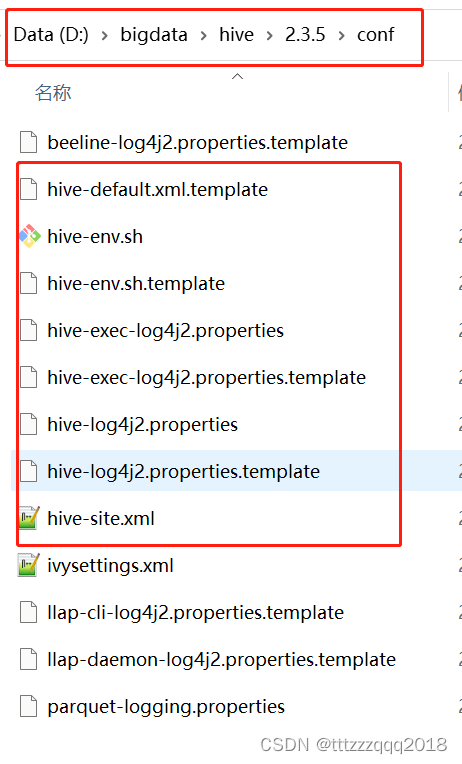
五、创建Hive配置文件(hive-site.xml、hive-env.sh、hive-log4j2.properties、hive-exec-log4j2.properties)六、新建Hive本地目录七、修改Hive配置文件7.1、修改Hive配置文件 hive-env.sh7.2、修改Hive配置文件 hive-site.xml
八、启动Hadoop8.1、启动Hadoop8.2、在Hadoop上创建HDFS目录并给文件夹授权(选做,可不做)
九、启动Hive服务9.1、初始化Hive元数据库(采用MySQL存储元数据)9.2、启动并进入Hive
十、常见错误解答FAQ(Frequently Asked Questions)10.1、解决“Windows环境中缺少Hive的执行文件和运行程序”的问题10.1.1、下载低版本Hive(apache-hive-2.0.0-src)10.1.2、将低版本Hive的bin目录替换Hive原有的bin目录(D:\bigdata\hive\2.3.5\bin)
10.2、解决“Class path contains multiple SLF4J bindings.”的问题10.2.1、报错信息10.2.2、产生原因10.2.3、解决方案
前言
Hive与Hadoop的版本选择很关键,千万不能选错,否则各种报错。 本篇安装版本 Hadoop版本为:2.7.2 Hive版本为:2.3.5 请严格按照版本来安装。 一、Hive 1.1、Hive简介 Hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。而mapreduce开发人员可以把自己写的mapper和reducer作为插件来支持Hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。它还提供了一系列的工具进行数据提取转化加载,用来存储、查询和分析存储在Hadoop中的大规模数据集,并支持UDF(User-Defined Function)、UDAF(User-Defined AggregateFunction)和UDTF(User-Defined Table-Generating Function),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。Hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。 1.2、Hive适用场景 Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要高实时性的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的hiveSQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。 1.3、Hive设计特征Hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的HiveSQL 语言实现数据查询,所有Hive 的数据都存储在Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。 支持创建索引,优化数据查询。不同的存储类型,例如,纯文本文件、HBase 中的文件。将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。可以直接使用存储在Hadoop 文件系统中的数据。内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。 1.4、Hive体系结构主要分为以下几个部分: 1.4.1、用户接口 用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 Cli,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。 1.4.2、元数据存储 Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 1.4.3、解释器、编译器、优化器、执行器 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。 1.4.4、Hadoop Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。 1.5、Hive数据模型Hive中包含以下四类数据模型:表(Table)、外部表(External Table)、分区(Partition)、桶(Bucket)。 1.5.1、Hive数据模型 - 表(Table) Hive中的Table和数据库中的Table在概念上是类似的。在Hive中每一个Table都有一个相应的目录存储数据。 1.5.2、Hive数据模型 - 外部表(External Table) 外部表是一个已经存储在HDFS中,并具有一定格式的数据。使用外部表意味着Hive表内的数据不在Hive的数据仓库内,它会到仓库目录以外的位置访问数据。外部表和普通表的操作不同,创建普通表的操作分为两个步骤,即表的创建步骤和数据装入步骤(可以分开也可以同时完成)。在数据的装入过程中,实际数据会移动到数据表所在的Hive数据仓库文件目录中,其后对该数据表的访问将直接访问装入所对应文件目录中的数据。删除表时,该表的元数据和在数据仓库目录下的实际数据将同时删除。外部表的创建只有一个步骤,创建表和装入数据同时完成。外部表的实际数据存储在创建语句。LOCATION参数指定的外部HDFS文件路径中,但这个数据并不会移动到Hive数据仓库的文件目录中。删除外部表时,仅删除其元数据,保存在外部HDFS文件目录中的数据不会被删除。 1.5.3、Hive数据模型 - 分区(Partition) 分区对应于数据库中的分区列的密集索引,但是hive中分区的组织方式和数据库中的很不相同。在Hive中,表中的一个分区对应于表下的一个目录,所有的分区的数据都存储在对应的目录中。 1.5.4、Hive数据模型 - 桶(Bucket) 桶对指定列进行哈希(hash)计算,会根据哈希值切分数据,目的是为了并行,每一个桶对应一个文件。 二、Hive下载 2.1、官网下载Hivehttps://dlcdn.apache.org/hive/ 2.2、网盘下载Hive如果嫌慢,可以网盘下载:链接: https://pan.baidu.com/s/1axk8C4Zw7CUuP1b1SGPyPg?pwd=yyds 三、解压安装包,配置Hive环境变量解压安装包到(D:\bigdata\hive\2.3.5),注意路径不要有空格。 3.1、环境变量新增:HIVE_HOME
下载和拷贝一个 mysql-connector-java-5.1.47-bin.jar 到 $HIVE_HOME/lib 目录下。 4.1、下载连接MySQL的依赖jar包“mysql-connector-java-5.1.47-bin.jar”官网下载地址:https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.47.zip 或者网盘下载:https://pan.baidu.com/s/1X6ZGyy3xNYI76nDoAjfVVA?pwd=yyds 4.2、拷贝到$HIVE_HOME/lib目录下
配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名 原文件名拷贝后的文件名hive-log4j.properties.templatehive-log4j2.propertieshive-exec-log4j.properties.templatehive-exec-log4j2.propertieshive-env.sh.templatehive-env.shhive-default.xml.templatehive-site.xml
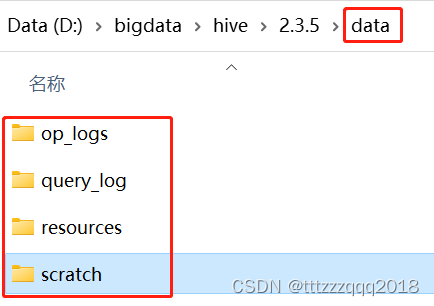
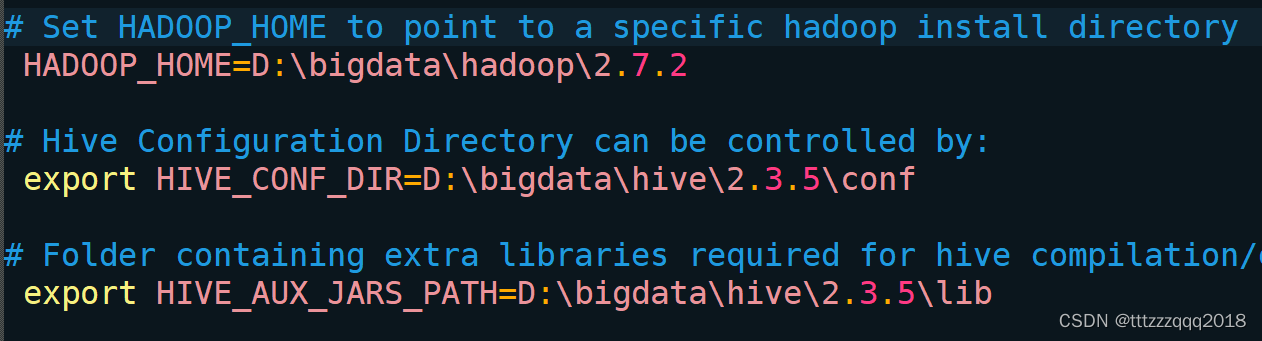
后面Hive的配置文件用到下面这些目录: 先在Hive安装目录下建立 data 文件夹, 然后再到在这个文件夹下建 op_logs query_log resources scratch 这四个文件夹,建完后如下图所示: 编辑 conf\hive-env.sh 文件: 根据自己的Hive安装路径(D:\bigdata\hive\2.3.5),添加三条配置信息: # Set HADOOP_HOME to point to a specific hadoop install directory HADOOP_HOME=D:\bigdata\hadoop\2.7.2 # Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=D:\bigdata\hive\2.3.5\conf # Folder containing extra libraries required for hive compilation/execution can be controlled by: export HIVE_AUX_JARS_PATH=D:\bigdata\hive\2.3.5\lib
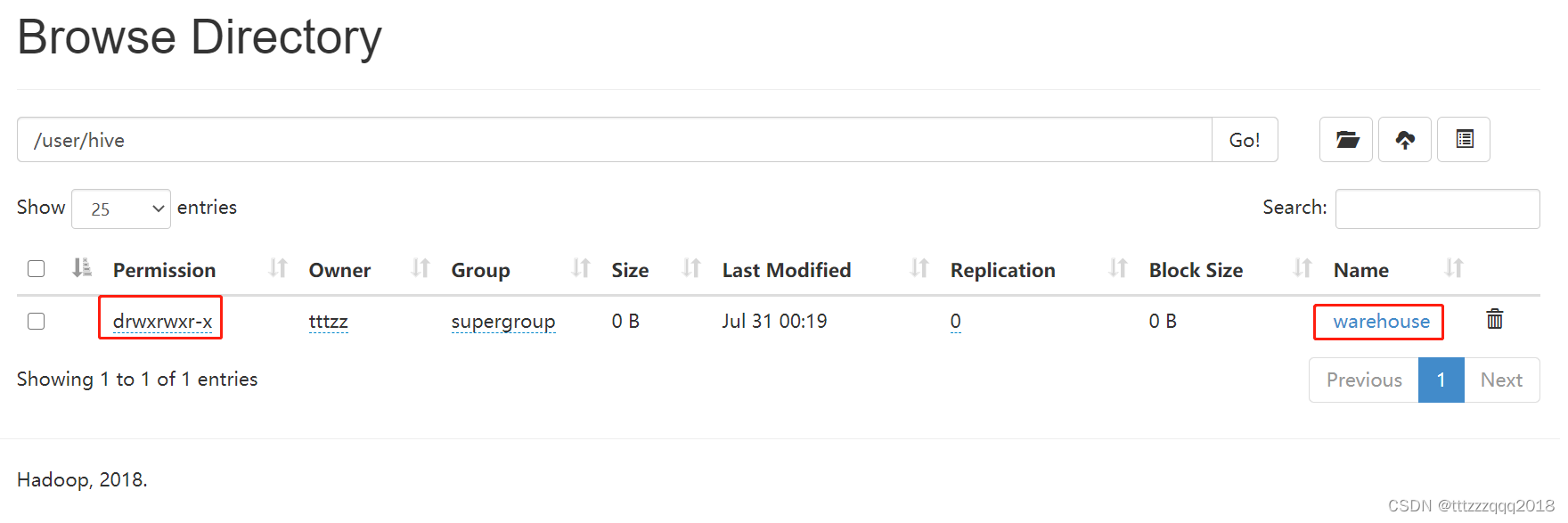
编辑 conf\hive-site.xml 文件: 根据自己的Hive安装路径(D:\bigdata\hive\2.3.5),修改下面几个参数的配置: hive.exec.local.scratchdir D:/bigdata/hive/2.3.5/data/scratch Local scratch space for Hive jobs hive.server2.logging.operation.log.location D:/bigdata/hive/2.3.5/data/op_logs Top level directory where operation logs are stored if logging functionality is enabled hive.downloaded.resources.dir D:/bigdata/hive/2.3.5/data/resources/${hive.session.id}_resources Temporary local directory for added resources in the remote file system. javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName root Username to use against metastore database javax.jdo.option.ConnectionPassword 123456 password to use against metastore database javax.jdo.option.ConnectionURL jdbc:mysql://localhost:3307/hive?createDatabaseIfNotExist=true;useSSL=false;useUnicode=true;characterEncoding=UTF-8 JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.修改后的 hive-site.xml 下载地址:https://pan.baidu.com/s/1PvTCc_6Cu-1HJ44E2vEFQg?pwd=yyds 八、启动Hadoop 8.1、启动HadoopHadoop安装及启动,请看这篇博文:Windows下安装Hadoop(手把手包成功安装) 使用命令: hadoop fs -mkdir /tmp hadoop fs -mkdir /user/ hadoop fs -mkdir /user/hive/ hadoop fs -mkdir /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse或者使用命令: hdfs dfs -mkdir /tmp hdfs dfs -chmod -R 777 /tmp
在%HIVE_HOME%/bin目录下执行下面的脚本: hive --service schematool -dbType mysql -initSchema
输入hive,进入hive: Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。 解决方法: 10.1.1、下载低版本Hive(apache-hive-2.0.0-src)下载地址:http://archive.apache.org/dist/hive/hive-2.0.0/apache-hive-2.0.0-bin.tar.gz 或者网盘下载:https://pan.baidu.com/s/1exyrc51P4a_OJv2XHYudCw?pwd=yyds 10.1.2、将低版本Hive的bin目录替换Hive原有的bin目录(D:\bigdata\hive\2.3.5\bin)替换后: 报错:类路径包含了多个SLF4J的绑定。 这个报错是因为hive里面的slf4j的包跟hadoop里面的包冲突了。 10.2.3、解决方案把hive里面的这个包删掉即可。 即删除hive安装目录lib下的log4j-slf4j-impl-x.x.x.jar这个jar包。 |
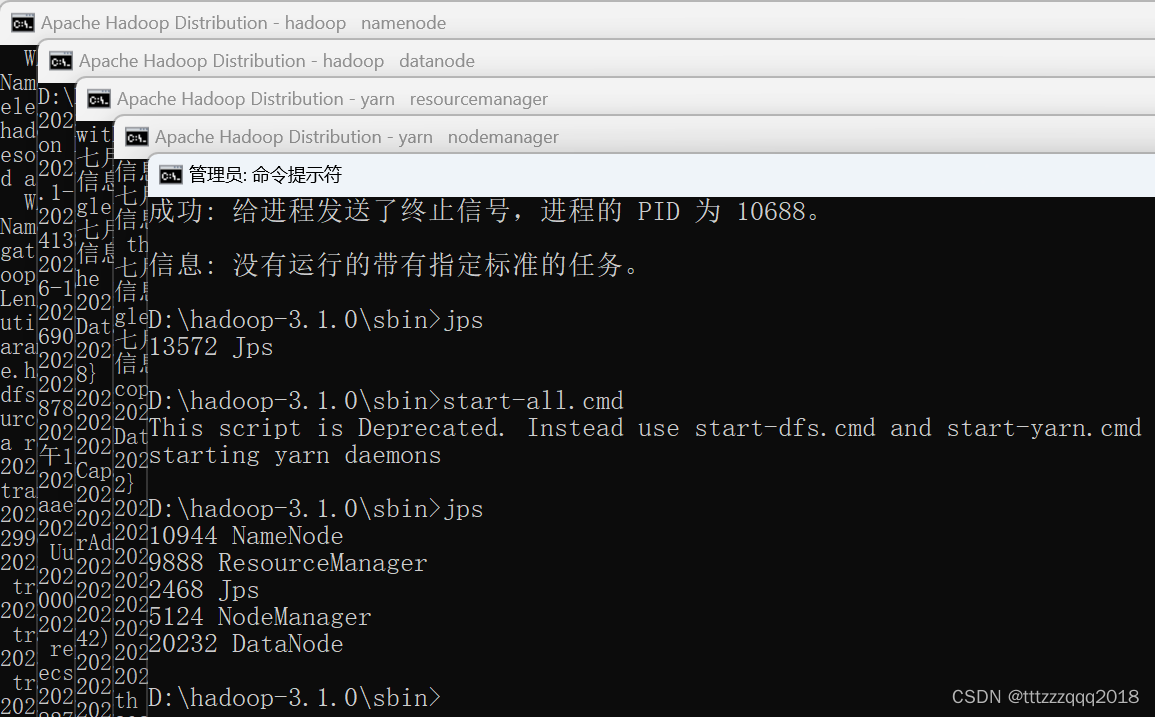 可以通过访问namenode和HDFS的Web UI界面(http://localhost:50070) 以及resourcemanager的页面(http://localhost:8088)
可以通过访问namenode和HDFS的Web UI界面(http://localhost:50070) 以及resourcemanager的页面(http://localhost:8088)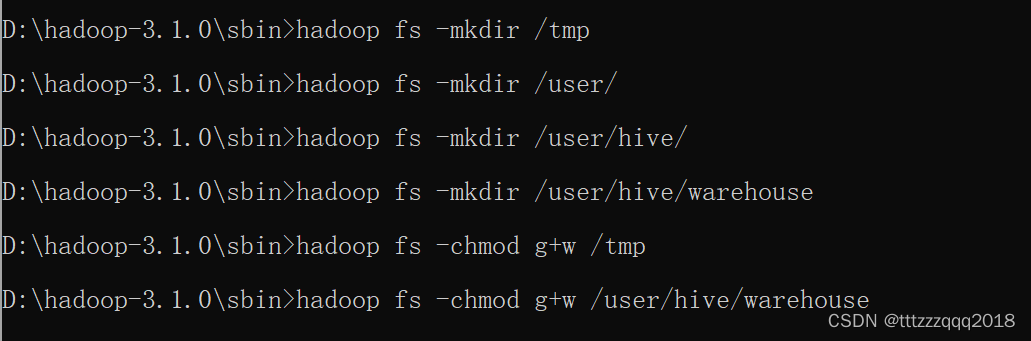 在Hadoop管理台(http://localhost:50070/explorer.html#/)可以看相应的情况:
在Hadoop管理台(http://localhost:50070/explorer.html#/)可以看相应的情况: 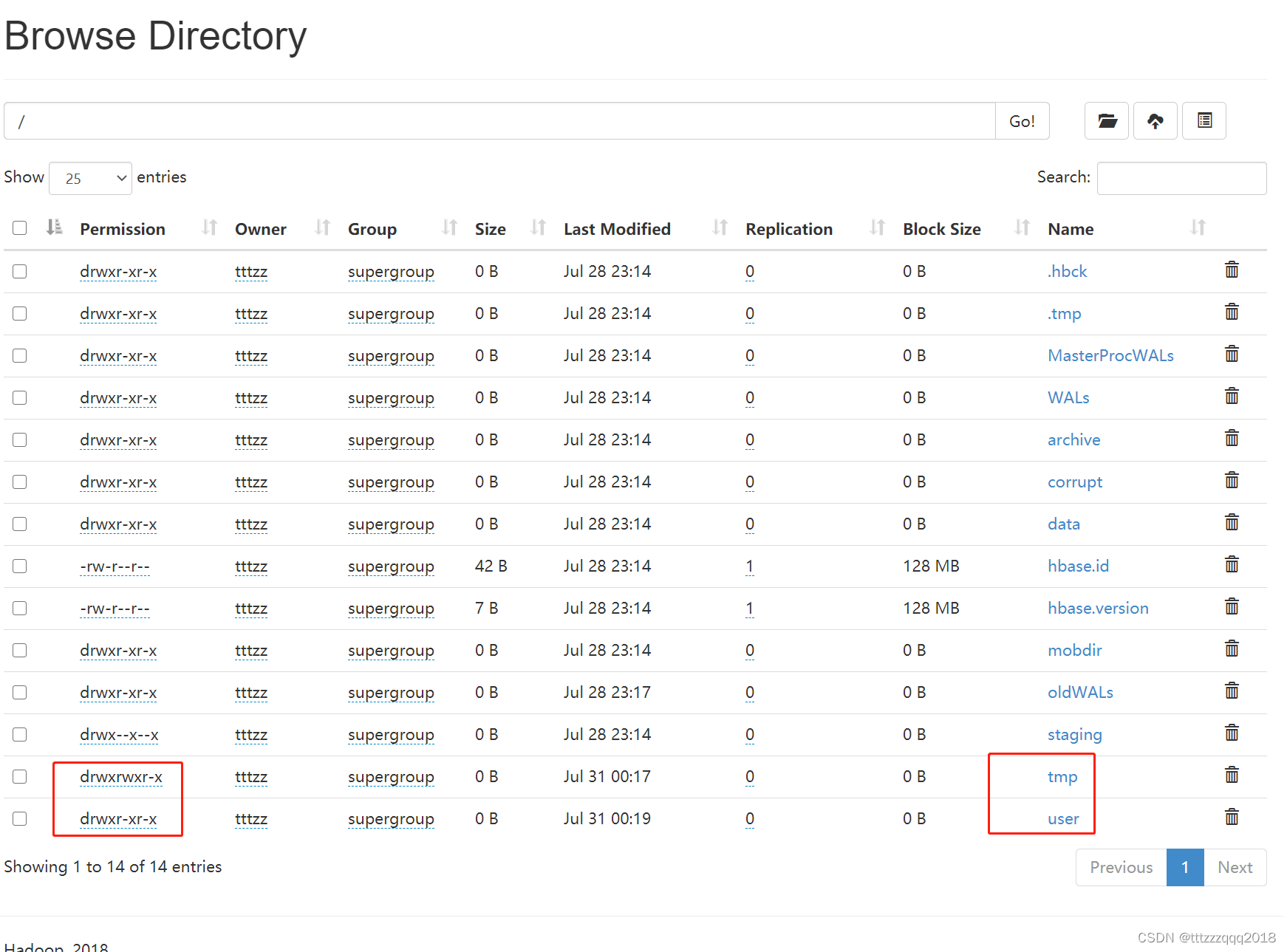
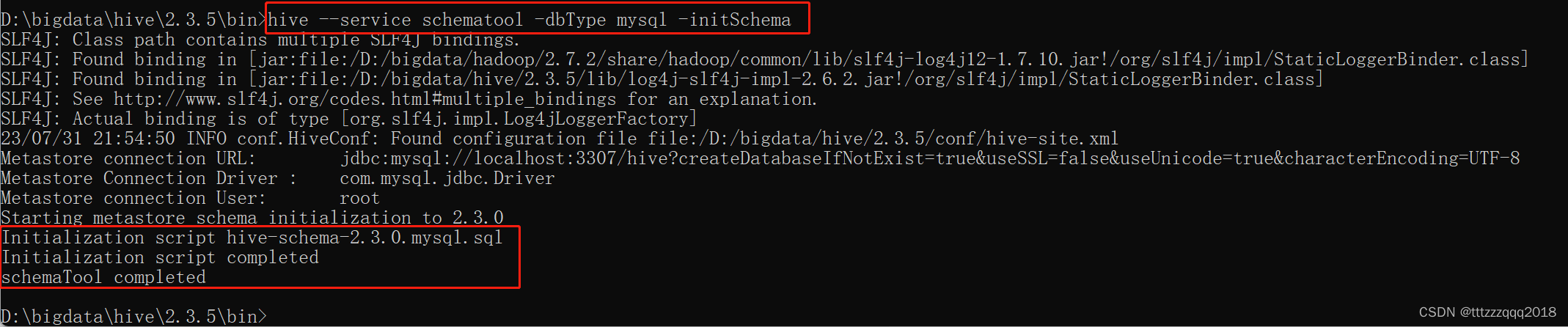 可以发现,Hive会自动连接MySQL去创建schema hive,并执行脚本。
可以发现,Hive会自动连接MySQL去创建schema hive,并执行脚本。 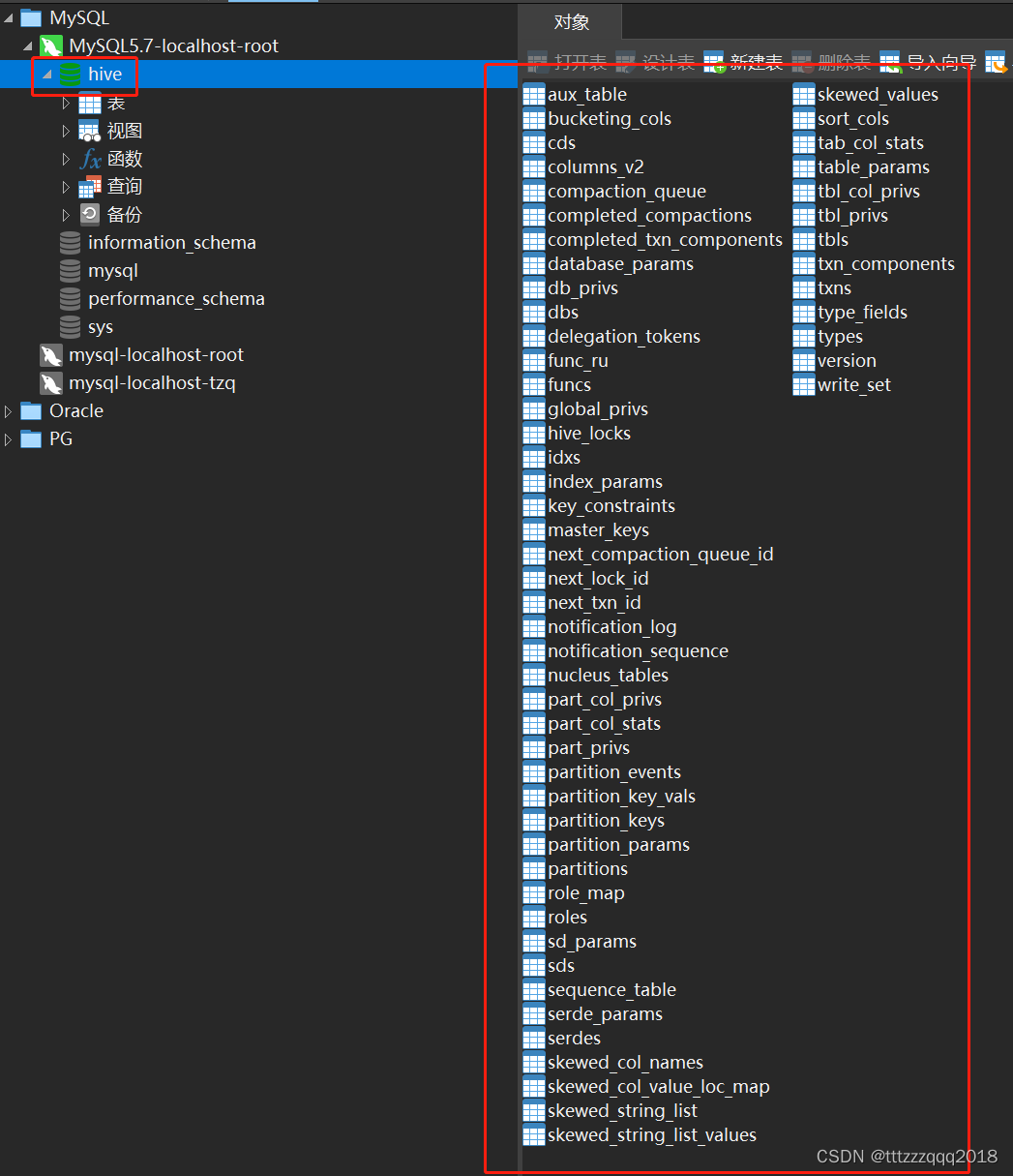
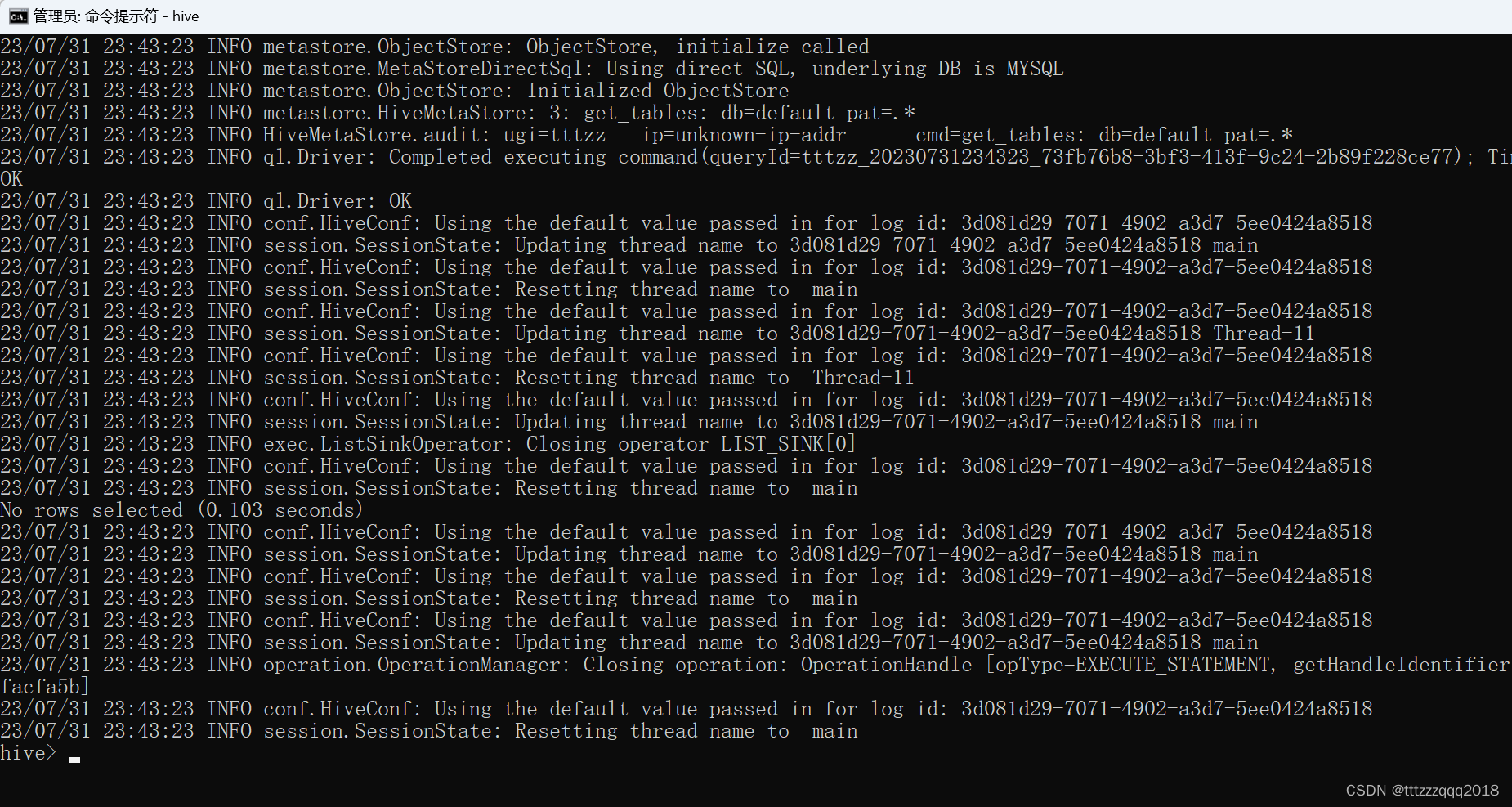 至此,Hive在Windows下安装成功了!
至此,Hive在Windows下安装成功了!
【本文地址】
今日新闻 |
推荐新闻 |