1.Hive表新增字段,一次讲明白 |
您所在的位置:网站首页 › hive增加一列的数据 › 1.Hive表新增字段,一次讲明白 |
1.Hive表新增字段,一次讲明白
|
1.概述
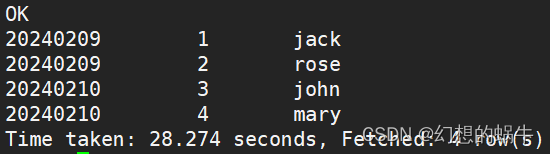
Hive表新增字段可以说是Hive中最常见的操作,但有些开发人员在新增字段并刷新历史数据的时候总会遇到问题,这里进行详细的讲解和演示。 在生产环境中,正式表一般选择建外部表,临时表一般选择建内部表,因此本文以外部表进行演示。 1.1.1新增字段语句 ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...) [CASCADE|RESTRICT] 1.1.2新增字段注意点(1)新增字段是添加在表字段的最后,分区字段之前。 (2)新增字段时字段名和字段类型必须指定,字段备注是可选的。 (3)新增字段操作只更改元数据信息,对存储的数据无影响。 (4)新增字段语句最后的[CASCADE|RESTRICT]关键字是可以选的,不指定时默认值是RESTRICT,表示新增字段只作用在表上;加上CASCADE表示新增字段同样作用在历史分区上。 2.新增字段不加CASCADE 2.1.1建一张公共表并插入数据(数据源) CREATE EXTERNAL TABLE IF NOT EXISTS bi.test_common_1 ( id INT COMMENT '编号' ,name STRING COMMENT '姓名' ) COMMENT '修改Location测试' PARTITIONED BY (pt_day STRING COMMENT '天分区') ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n' STORED AS ORC LOCATION 'hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_common_1' TBLPROPERTIES ("orc.compress"="ZLIB") ; INSERT OVERWRITE TABLE bi.test_common_1 PARTITION (pt_day = '20240209') VALUES (1, 'jack') ,(2, 'rose') ; INSERT OVERWRITE TABLE bi.test_common_1 PARTITION (pt_day = '20240210') VALUES (3, 'john') ,(4, 'mary') ; SELECT pt_day ,id ,name FROM bi.test_common_1 WHERE pt_day IN ('20240209', '20240210') ORDER BY pt_day ,id ;
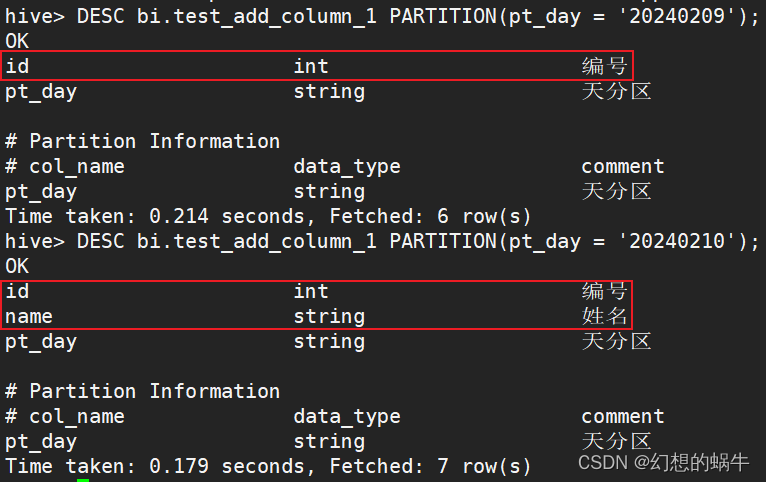
从查询结果可以看出,新增字段后,新的分区插入数据,以及重新刷新数据的历史分区,数据都可以正常查询。 这应该是这个版本的Hive做过优化,历史版本的Hive可能会出现pt_day = '20240209'查询结果为NULL的情况。 2.1.5查看表及分区的字段信息 DESC bi.test_add_column_1 PARTITION(pt_day = '20240209'); DESC bi.test_add_column_1 PARTITION(pt_day = '20240210');
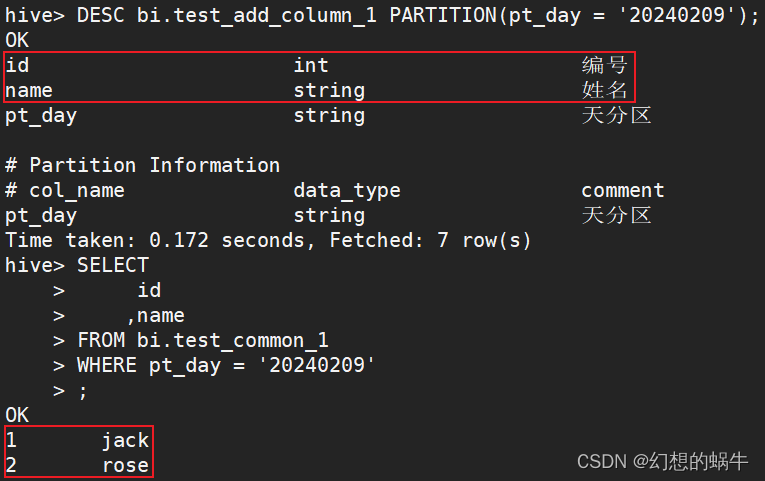
从上面的查询结果可以看出,pt_day = '20240209'和pt_day = '20240210'的分区字段信息不一致。 2.1.6删除历史分区并重刷数据为了解决历史分区pt_day = '20240209'元数据未修改的情况,可采用如下2种方法,这里只演示第一种: (1)删除历史分区,然后重新刷数据; (2)直接修改历史分区的元数据信息。 ALTER TABLE bi.test_add_column_1 DROP IF EXISTS PARTITION(pt_day = '20240209'); INSERT OVERWRITE TABLE bi.test_add_column_1 PARTITION (pt_day = '20240209') SELECT id ,name FROM bi.test_common_1 WHERE pt_day = '20240209' ; DESC bi.test_add_column_1 PARTITION(pt_day = '20240209'); SELECT id ,name FROM bi.test_common_1 WHERE pt_day = '20240209' ;
从上面的执行结果可以看出,删除分区后,再重新插入数据,会更新历史分区的元数据信息。 对于历史版本的Hive,如果重刷数据,查询数据显示为NULL,也可以使用删除分区后再重刷数据解决。 3.新增字段加CASCADE(建议)CASCADE的作用是级联的意思,修改表字段的同时级联修改历史分区的字段信息。执行过新增的字段的语句后即可正常刷数据,对于历史版本的Hive也适用。 |


【本文地址】
今日新闻 |
推荐新闻 |