|





DataX-Web

DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的
操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。后续还将提供更多的数据源支持、数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
Architecture diagram:

System Requirements
Language: Java 8(jdk版本建议1.8.201以上)
Python2.7(支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下)
Environment: MacOS, Windows,Linux
Database: Mysql5.7
Features
1、通过Web构建DataX Json;
2、DataX Json保存在数据库中,方便任务的迁移,管理;
3、Web实时查看抽取日志,类似Jenkins的日志控制台输出功能;
4、DataX运行记录展示,可页面操作停止DataX作业;
5、支持DataX定时任务,支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
6、调度采用中心式设计,支持集群部署;
7、任务分布式执行,任务"执行器"支持集群部署;
8、执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行;
9、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
10、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
11、任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务;
12、任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
13、任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
14、用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色;
15、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
16、运行报表:支持实时查看运行数据,以及调度报表,如调度日期分布图,调度成功分布图等;
17、指定增量字段,配置定时任务自动获取每次的数据区间,任务失败重试,保证数据安全;
18、页面可配置DataX启动JVM参数;
19、数据源配置成功后添加手动测试功能;
20、可以对常用任务进行配置模板,在构建完JSON之后可选择关联模板创建任务;
21、jdbc添加hive数据源支持,可在构建JSON页面选择数据源生成column信息并简化配置;
22、优先通过环境变量获取DataX文件目录,集群部署时不用指定JSON及日志目录;
23、通过动态参数配置指定hive分区,也可以配合增量实现增量数据动态插入分区;
24、任务类型由原来DataX任务扩展到Shell任务、Python任务、PowerShell任务;
25、添加HBase数据源支持,JSON构建可通过HBase数据源获取hbaseConfig,column;
26、添加MongoDB数据源支持,用户仅需要选择collectionName即可完成json构建;
27、添加执行器CPU、内存、负载的监控页面;
28、添加24类插件DataX JSON配置样例
29、公共字段(创建时间,创建人,修改时间,修改者)插入或更新时自动填充
30、对swagger接口进行token验证
31、任务增加超时时间,对超时任务kill datax进程,可配合重试策略避免网络问题导致的datax卡死。
32、添加项目管理模块,可对任务分类管理;
33、对RDBMS数据源增加批量任务创建功能,选择数据源,表即可根据模板批量生成DataX同步任务;
34、JSON构建增加ClickHouse数据源支持;
35、执行器CPU.内存.负载的监控页面图形化;
36、RDBMS数据源增量抽取增加主键自增方式并优化页面参数配置;
37、更换MongoDB数据源连接方式,重构HBase数据源JSON构建模块;
38、脚本类型任务增加停止功能;
39、rdbms json构建增加postSql,并支持构建多个preSql,postSql;
40、数据源信息加密算法修改及代码优化;
41、日志页面增加DataX执行结果统计数据;
Quick Start:
请点击:Quick Start
Linux:一键部署
Introduction:
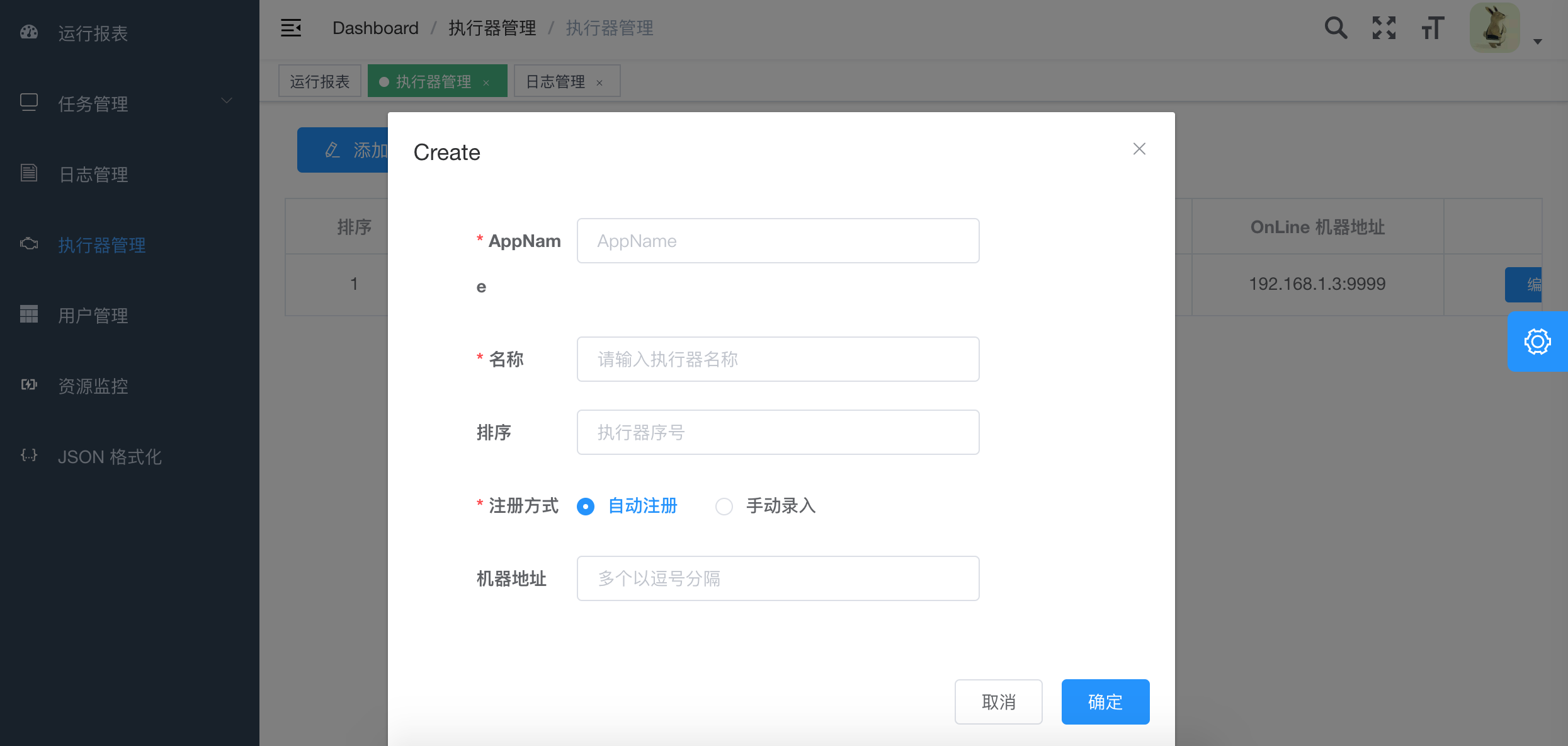
1.执行器配置(使用开源项目xxl-job)

1、"调度中心OnLine:"右侧显示在线的"调度中心"列表, 任务执行结束后, 将会以failover的模式进行回调调度中心通知执行结果, 避免回调的单点风险;
2、"执行器列表" 中显示在线的执行器列表, 可通过"OnLine 机器"查看对应执行器的集群机器;
执行器属性说明

1、AppName: (与datax-executor中application.yml的datax.job.executor.appname保持一致)
每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
2、名称: 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
3、排序: 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
4、注册方式:调度中心获取执行器地址的方式;
自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
5、机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
2.创建数据源

第四步使用
3.创建任务模版

第四步使用
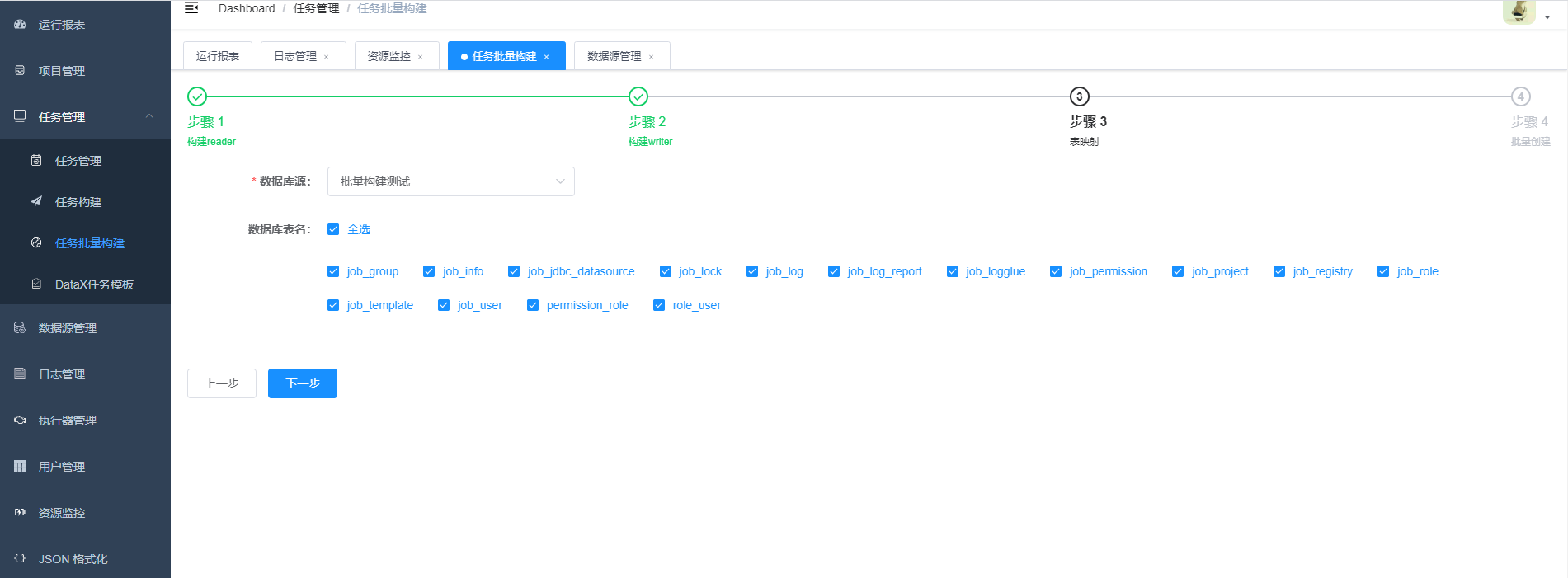
4. 构建JSON脚本
1.步骤一,步骤二,选择第二步中创建的数据源,JSON构建目前支持的数据源有hive,mysql,oracle,postgresql,sqlserver,hbase,mongodb,clickhouse 其它数据源的JSON构建正在开发中,暂时需要手动编写。

2.字段映射

3.点击构建,生成json,此时可以选择复制json然后创建任务,选择datax任务,将json粘贴到文本框。也可以点击选择模版,直接生成任务。

5.批量创建任务


6.任务创建介绍(关联模版创建任务不再介绍,具体参考4. 构建JSON脚本)
支持DataX任务,Shell任务,Python任务,PowerShell任务


阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行:调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
增量增新建议将阻塞策略设置为丢弃后续调度或者单机串行
设置单机串行时应该注意合理设置重试次数(失败重试的次数*每次执行时间 |