MagicDance:逼真的人类舞蹈视频生成 |
您所在的位置:网站首页 › him跳舞视频 › MagicDance:逼真的人类舞蹈视频生成 |
MagicDance:逼真的人类舞蹈视频生成
|
计算机视觉是人工智能行业中讨论最多的领域之一,因为它在广泛的实时任务中具有潜在的应用前景。近年来,计算机视觉框架发展迅速,现代模型现在能够在实时场景中分析面部特征、物体等。尽管有这些能力,人体运动转移对于计算机视觉模型来说仍然是一个巨大的挑战。此任务涉及将面部和身体运动从源图像或视频重新定位到目标图像或视频。人体运动迁移广泛应用于计算机视觉模型中,用于设计图像或视频样式、编辑多媒体内容、数字人体合成,甚至为基于感知的框架生成数据。 在本文中,我们重点关注 MagicDance,这是一种基于扩散的模型,旨在彻底改变人体运动传递。 MagicDance 框架的具体目标是将 2D 人类面部表情和动作转移到具有挑战性的人类舞蹈视频中。其目标是为特定目标身份生成新颖的姿势序列驱动的舞蹈视频,同时保持原始身份。 MagicDance 框架采用两阶段训练策略,重点关注人体动作解缠和肤色、面部表情和服装等外观因素。我们将深入研究 MagicDance 框架,探索其架构、功能和性能与其他最先进的人体运动传输框架的比较。让我们深入了解一下。 MagicDance:逼真的人体动作转移如前所述,人体动作转移是最复杂的计算机视觉任务之一,因为将人体动作和表情从源图像或视频转移到目标图像或视频非常复杂。传统上,计算机视觉框架通过训练特定任务的生成模型(包括 GAN 或 生成对抗网络 在面部表情和身体姿势的目标数据集上。尽管训练和使用生成模型在某些情况下可以提供令人满意的结果,但它们通常存在两个主要限制。 他们严重依赖图像扭曲组件,因此,由于视角的变化或自遮挡,他们经常难以插入源图像中不可见的身体部位。 它们无法推广到外部来源的其他图像,这限制了它们的应用,尤其是在野外的实时场景中。
现代扩散模型在不同条件下展示了卓越的图像生成能力,并且扩散模型现在能够通过从网络规模图像数据集学习来在视频生成和图像修复等一系列下游任务中呈现强大的视觉效果。由于其功能,扩散模型可能是人体运动传递任务的理想选择。尽管扩散模型可以用于人体运动传输,但它确实存在一些限制,无论是在生成内容的质量方面,还是在身份保存方面,或者由于模型设计和训练策略的限制而遭受时间不一致的影响。此外,基于扩散的模型没有表现出明显的优势 生成对抗网络框架 就普遍性而言。 为了克服基于扩散和 GAN 的框架在人体运动转移任务中面临的障碍,开发人员推出了 MagicDance,这是一种新颖的框架,旨在利用扩散框架在人体运动转移方面的潜力,展示出前所未有的身份保留水平、卓越的视觉质量、和领域的普遍性。 MagicDance 框架的核心概念是将问题分为两个阶段:外观控制和运动控制,这是图像扩散框架提供准确的运动传输输出所需的两种功能。
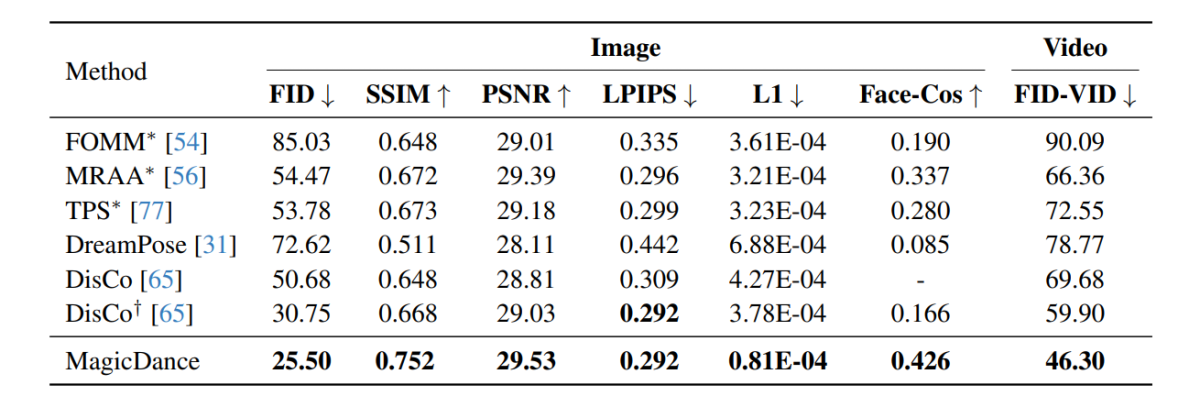
上图给出了MagicDance框架的简要概述,可以看出,该框架采用了 稳定扩散模型,并且还部署了两个额外的组件:外观控制模型和姿势控制网络,其中前者通过注意力从参考图像向 SD 模型提供外观指导,而后者从条件图像或视频向扩散模型提供表情/姿势指导。该框架还采用多阶段训练策略来有效地学习这些子模块,以解开姿势控制和外观。 总而言之,MagicDance 框架是一个 新颖有效的框架,包括外观解缠姿势控制和外观控制预训练。 MagicDance 框架能够在姿势条件输入和参考图像或视频的控制下生成逼真的人类面部表情和人体运动。 MagicDance 框架旨在通过引入多源注意力模块来生成外观一致的人类内容,该模块为稳定扩散 UNet 框架提供准确的指导。 MagicDance 框架还可以用作稳定扩散框架的便捷扩展或插件,并且还确保与现有模型权重的兼容性,因为它不需要对参数进行额外的微调。此外,MagicDance 框架在外观和运动泛化方面表现出卓越的泛化能力。 外观泛化:MagicDance 框架在生成不同外观方面表现出了卓越的能力。 运动泛化:MagicDance 框架还能够生成各种运动。 MagicDance:目标和架构对于给定的真人或风格化图像的参考图像,MagicDance 框架的主要目标是根据输入和姿势输入 {P, F} 生成输出图像或输出视频,其中 P 代表人体姿势骨骼和F代表面部标志。生成的输出图像或视频应该能够保留所涉及的人类的外观和身份以及参考图像中存在的背景内容,同时保留由姿势输入定义的姿势和表情。 建筑在训练期间,MagicDance 框架被训练为帧重建任务,以使用来自同一参考视频的参考图像和姿势输入重建地面实况。在实现运动转移的测试过程中,姿势输入和参考图像来自不同的来源。 MagicDance框架的整体架构可以分为四类:初级阶段、外观控制预训练、外观解缠姿势控制和运动模块。 预备阶段潜在扩散模型 (LDM) 代表独特设计的扩散模型,可在使用自动编码器促进的潜在空间内运行,稳定扩散框架是 LDM 的一个著名实例,它采用矢量量化变分法 自动编码器 和时态 U-Net 架构。稳定扩散模型采用基于 CLIP 的转换器作为文本编码器,通过将文本输入转换为嵌入来处理文本输入。稳定扩散框架的训练阶段将模型暴露于文本条件和输入图像,该过程涉及将图像编码为潜在表示,并将其置于高斯方法指导的预定义扩散步骤序列中。由此产生的序列产生一个噪声潜在表示,它提供了标准正态分布,稳定扩散框架的主要学习目标是将噪声潜在表示迭代地去噪为潜在表示。 外观控制预训练原始 ControlNet 框架的一个主要问题是它无法一致地控制空间变化运动中的外观,尽管它倾向于生成姿势与输入图像中的姿势非常相似的图像,并且整体外观主要受文本输入的影响。尽管此方法有效,但它不适合涉及任务的运动传输,其中不是文本输入,而是参考图像作为外观信息的主要来源。 MagicDance框架中的外观控制预训练模块被设计为辅助分支,为逐层方法的外观控制提供指导。整个模块不依赖文本输入,而是专注于利用参考图像的外观属性,旨在增强框架准确生成外观特征的能力,特别是在涉及复杂运动动力学的场景中。此外,在外观控制预训练期间,只有外观控制模型是可训练的。 外观分离的姿势控制控制输出图像中的姿态的一个简单的解决方案是将预训练的 ControlNet 模型与预训练的外观控制模型直接集成,无需进行微调。然而,集成可能会导致框架难以处理与外观无关的姿势控制,这可能导致输入姿势和生成的姿势之间存在差异。为了解决这种差异,MagicDance 框架对 Pose ControlNet 模型与预训练的外观控制模型进行了联合微调。 运动模块当一起工作时,外观解缠的姿势控制网络和外观控制模型可以实现准确有效的图像到运动的传输,尽管它可能会导致时间不一致。为了确保时间一致性,该框架将额外的运动模块集成到主要的稳定扩散 UNet 架构中。 MagicDance:预训练和数据集对于预训练,MagicDance 框架利用了 TikTok 数据集,该数据集包含 350 多个长度在 10 到 15 秒之间的舞蹈视频,捕捉到一个人跳舞,其中大部分视频包含面部和上半身。人类。 MagicDance 框架以 30 FPS 提取每个单独的视频,并在每个帧上单独运行 OpenPose 以推断姿势骨架、手部姿势和面部标志。 对于预训练,外观控制模型在 64 个 NVIDIA A8 GPU 上以 100 的批量大小预训练 10 步,图像尺寸为 512 x 512,然后联合微调姿态控制和外观控制模型批量大小为 16,步数为 20。在训练过程中,MagicDance 框架随机采样两帧,分别作为目标和参考,图像在相同高度的相同位置进行裁剪。在评估过程中,模型集中裁剪图像,而不是随机裁剪图像。 魔法舞蹈:结果下图展示了在 MagicDance 框架上进行的实验结果,可以看出,MagicDance 框架在所有指标的人体运动转移方面均优于 Disco 和 DreamPose 等现有框架。名称前面包含“*”的框架直接使用目标图像作为输入,并且与其他框架相比包含更多信息。
有趣的是,MagicDance框架的Face-Cos得分为0.426,比Disco框架提高了156.62%,与DreamPose框架相比提高了近400%。结果表明 MagicDance 框架具有强大的保存身份信息的能力,性能的明显提升表明 MagicDance 框架相对于现有最先进方法的优越性。 下图比较了 MagicDance、Disco 和 TPS 框架之间的人类视频生成质量。可以看出,GT、Disco 和 TPS 框架生成的结果存在人体姿势身份和面部表情不一致的问题。
此外,下图演示了 TikTok 数据集上面部表情和人体姿势迁移的可视化,MagicDance 框架能够在不同的面部标志和姿势骨架输入下生成逼真生动的表情和动作,同时准确保留参考输入中的身份信息图像。
值得注意的是,MagicDance 框架对未见过的姿势和风格的域外参考图像具有出色的泛化能力,即使没有对目标域进行任何额外的微调,也具有令人印象深刻的外观可控性,结果如下图所示。
下图展示了MagicDance框架在面部表情迁移和零样本人体运动方面的可视化能力。可以看出,MagicDance 框架完美地推广到了野外的人体动作。
OpenPose 是 MagicDance 框架的重要组成部分,因为它在姿势控制中发挥着至关重要的作用,显着影响生成图像的质量和时间一致性。然而,MagicDance 框架仍然发现准确检测面部标志和摆出骨骼姿势有点困难,特别是当图像中的物体部分可见或显示快速移动时。这些问题可能会导致生成的图像出现伪影。 结论在本文中,我们讨论了 MagicDance,这是一种基于扩散的模型,旨在彻底改变人体运动传递。 MagicDance 框架试图在具有挑战性的人类舞蹈视频上传输 2D 人类面部表情和动作,其具体目标是为特定目标身份生成新颖的姿势序列驱动的人类舞蹈视频,同时保持身份不变。 MagicDance 框架是一个两阶段训练策略,用于人体运动解开和肤色、面部表情和服装等外观。 MagicDance 是一种新颖的方法,通过结合面部和动作表情传输来促进逼真的人类视频生成,并在野外动画生成中实现一致,而不需要任何进一步的微调,这表明比现有方法有显着的进步。此外,MagicDance框架在复杂的运动序列和不同的人类身份方面表现出卓越的泛化能力,使MagicDance框架成为人工智能辅助运动传输和视频生成领域的领先者。  
|






【本文地址】