yolo3各部分代码详解(超详细) |
您所在的位置:网站首页 › head函数 › yolo3各部分代码详解(超详细) |
yolo3各部分代码详解(超详细)
|
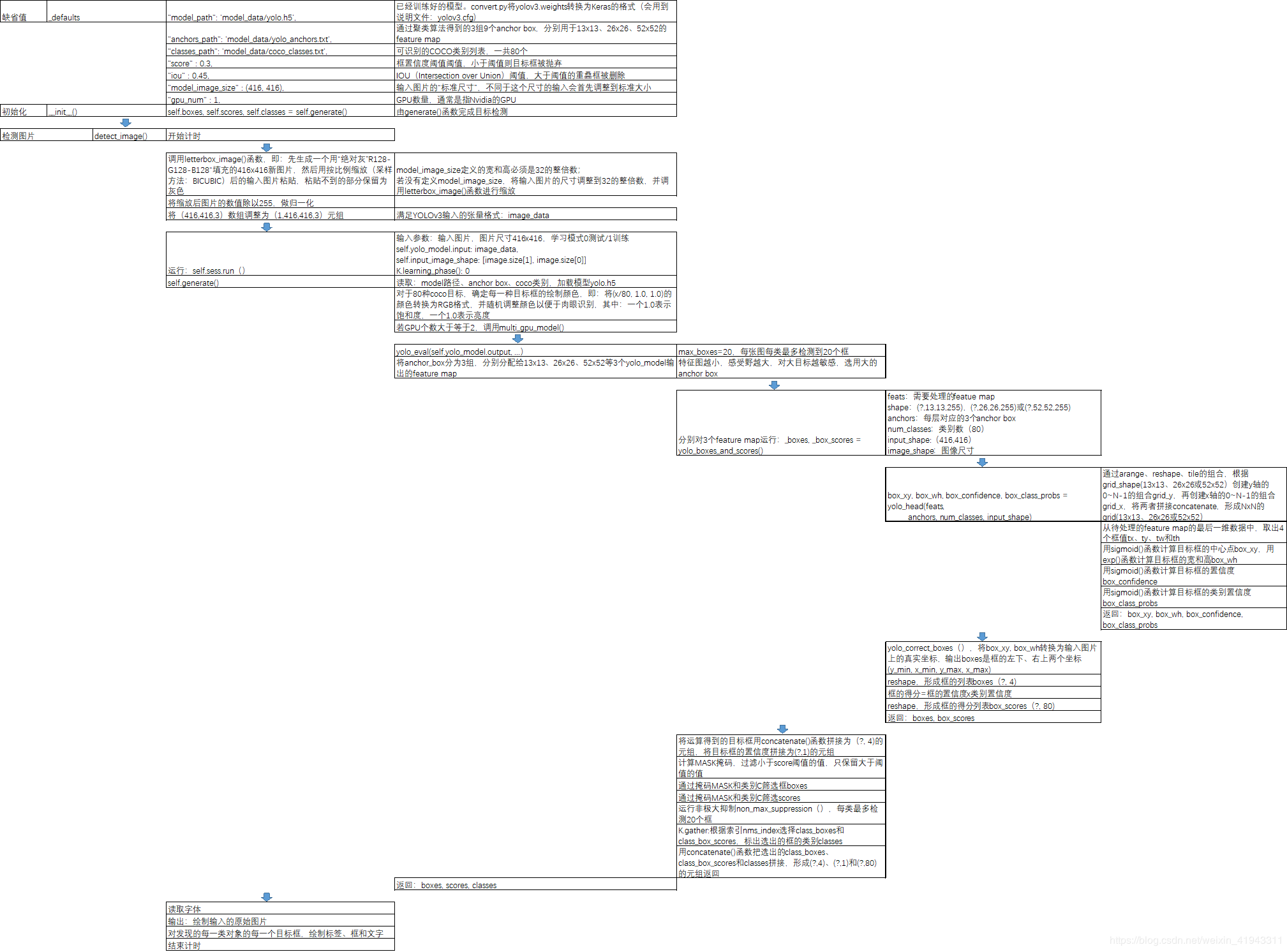
0.摘要 最近一段时间在学习yolo3,看了很多博客,理解了一些理论知识,但是学起来还是有些吃力,之后看了源码,才有了更进一步的理解。在这里,我不在赘述网络方面的代码,网络方面的代码比较容易理解,下面将给出整个yolo3代码的详解解析,整个源码中函数的作用以及调用关系见下图:
参考:https://blog.csdn.net/weixin_41943311/article/details/95672137?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
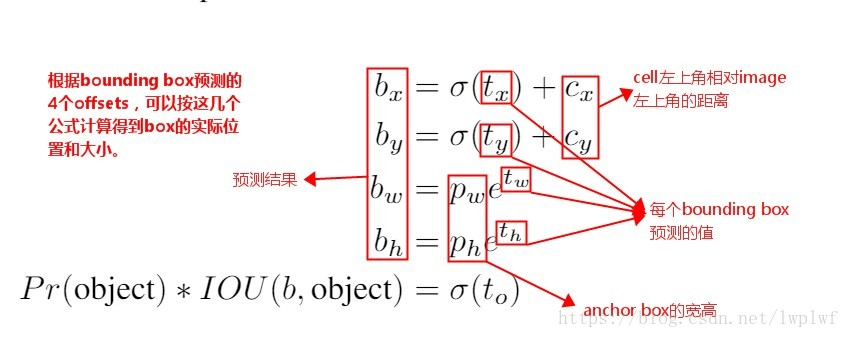
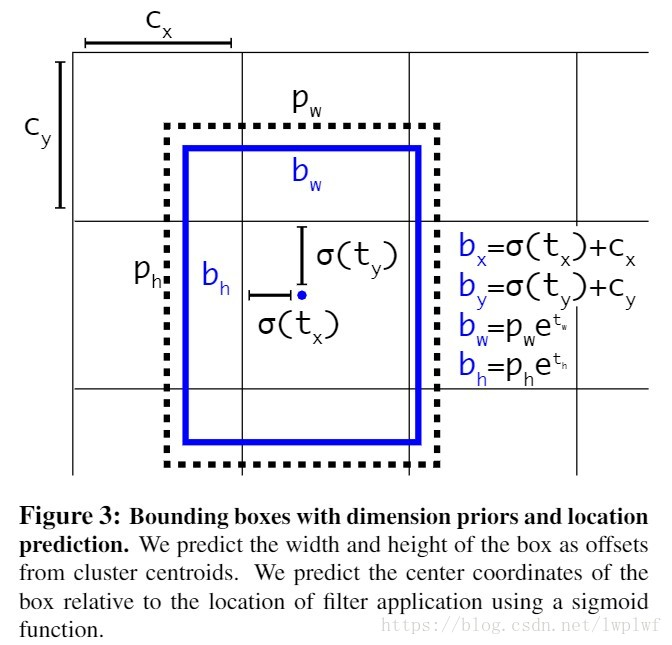
1.model.py 1.1 yolo_head() yolo_head()函数的输入是Darknet53的最后输出的三个特征图feats,anchors,num_class,input_shpe,此函数的功能是将特征图的进行解码,这一步极为重要,如其中一个特征图的shape是(13,13,255),其实质就是对应着(13,13,3,85),分别对应着13*13个网格,每个网格3个anchors,85=(x,y,w,h,confident),此时box的xy是相对于网格的偏移量,所以还需要经过一些列的处理,处理方式见下图:
def yolo_head(feats, anchors, num_classes, input_shape, calc_loss=False): """Convert final layer features to bounding box parameters.""" num_anchors = len(anchors)#num_anchors=3 # Reshape to batch, height, width, num_anchors, box_params. anchors_tensor = K.reshape(K.constant(anchors), [1, 1, 1, num_anchors, 2]) #anchors=anchors[anchors_mask[1]]=anchors[[6,7,8]]= [116,90], [156,198], [373,326] """#通过arange、reshape、tile的组合,根据grid_shape(13x13、26x26或52x52)创建y轴的0~N-1的组合grid_y,再创建x轴的0~N-1的组合grid_x,将两者拼接concatenate,形成NxN的grid(13x13、26x26或52x52)""" grid_shape = K.shape(feats)[1:3] # height, width,#13x13或26x26或52x52 grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]), [1, grid_shape[1], 1, 1]) grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]), [grid_shape[0], 1, 1, 1]) grid = K.concatenate([grid_x, grid_y]) grid = K.cast(grid, K.dtype(feats)) #cast函数用法:cast(x, dtype, name=None),x:待转换的张量,type:需要转换成什么类型 """grid形式:(0,0),(0,1),(0,2)......(1,0),(1,1).....(12,12)""" feats = K.reshape( feats, [-1, grid_shape[0], grid_shape[1], num_anchors, num_classes + 5]) """(batch_size,13,13,3,85)""" "此时的xy为中心坐标,相对于左上角的中心坐标" # Adjust preditions to each spatial grid point and anchor size. """将预测值调整为真实值""" "将中心点相对于网格的坐标转换成在整张图片中的坐标,相对于13/26/52的相对坐标" "将wh转换成预测框的wh,并处以416归一化" box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats))#实际上就是除以13或26或52 #box_xy = (K.sigmoid(feats[:,:,:,:2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats)) # ...操作符,在Python中,“...”(ellipsis)操作符,表示其他维度不变,只操作最前或最后1维; box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats)) box_confidence = K.sigmoid(feats[..., 4:5]) box_class_probs = K.sigmoid(feats[..., 5:]) #切片省略号的用法,省略前面左右的冒号,参考博客:https://blog.csdn.net/z13653662052/article/details/78010654?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task if calc_loss == True: return grid, feats, box_xy, box_wh return box_xy, box_wh, box_confidence, box_class_probs #预测框相对于整张图片中心点的坐标与预测框的wh
1.2 yolo_correct_box() 此函数的功能是将yolo_head()输出,也即是box相对于整张图片的中心坐标转换成box的左上角右下角的坐标 1 def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape): 2 '''Get corrected boxes''' 3 '''对上面函数输出的预测的坐标进行修正 4 比如 5 image_shape 6 为[600,800],input_shape 7 为[300, 500],那么 8 new_shape 9 为[300, 400] 10 11 offset 12 为[0, 0.125] 13 scales 14 为[0.5, 0.625]''' 15 16 17 # 将box_xy, box_wh转换为输入图片上的真实坐标,输出boxes是框的左下、右上两个坐标(y_min, x_min, y_max, x_max) 18 # ...操作符,在Python中,“...”(ellipsis)操作符,表示其他维度不变,只操作最前或最后1维; 19 # np.array[i:j:s],当s(?,4) ?:框的数目 7 box_scores = box_confidence * box_class_probs 8 box_scores = K.reshape(box_scores, [-1, num_classes])#reshape,将框的得分展平,变为(?,80); ?:框的数目 9 return boxes, box_scores#返回预测框的左下角与右上角的坐标与得分
1.4 yolo_eval() 此函数的作用是删除冗余框,保留最优框,用到非极大值抑制算法 1 def yolo_eval(yolo_outputs, 2 anchors, 3 num_classes, 4 image_shape, 5 max_boxes=20, 6 score_threshold=.6, 7 iou_threshold=.5): 8 """Evaluate YOLO model on given input and return filtered boxes.""" 9 """ yolo_outputs #模型输出,格式如下【(?,13,13,255)(?,26,26,255)(?,52,52,255)】 ?:bitch size; 13-26-52:多尺度预测; 255:预测值(3*(80+5)) 10 anchors, #[(10,13), (16,30), (33,23), (30,61), (62,45), (59,119), (116,90), (156,198),(373,326)] 11 num_classes, # 类别个数,coco集80类 12 image_shape, #placeholder类型的TF参数,默认(416, 416); 13 max_boxes=20, #每张图每类最多检测到20个框同类别框的IoU阈值,大于阈值的重叠框被删除,重叠物体较多,则调高阈值,重叠物体较少,则调低阈值 14 score_threshold=.6, #框置信度阈值,小于阈值的框被删除,需要的框较多,则调低阈值,需要的框较少,则调高阈值; 15 iou_threshold=.5): #同类别框的IoU阈值,大于阈值的重叠框被删除,重叠物体较多,则调高阈值,重叠物体较少,则调低阈值""" 16 num_layers = len(yolo_outputs)# #yolo的输出层数;num_layers = 3 -> 13-26-52 17 anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]] # default setting 18 # 每层分配3个anchor box.如13*13分配到[6,7,8]即[(116,90)(156,198)(373,326)] 19 input_shape = K.shape(yolo_outputs[0])[1:3] * 32 20 # 输入shape(?,13,13,255);即第一维和第二维分别*32 ->13*32=416; input_shape:(416,416) 21 #yolo_outputs=[(batch_size,13,13,255),(batch_size,26,26,255),(batch_size,52,52,255)] 22 #input_shape=416*416 23 boxes = [] 24 box_scores = [] 25 for l in range(num_layers): 26 _boxes, _box_scores = yolo_boxes_and_scores(yolo_outputs[l], 27 anchors[anchor_mask[l]], num_classes, input_shape, image_shape) 28 boxes.append(_boxes) 29 box_scores.append(_box_scores) 30 boxes = K.concatenate(boxes, axis=0) 31 box_scores = K.concatenate(box_scores, axis=0) #K.concatenate:将数据展平 ->(?,4) 32 33 #可能会产生很多个预选框,需要经过(1)阈值的删选,(2)非极大值抑制的删选 34 mask = box_scores >= score_threshold#得分大于置信度为True,否则为Flase 35 max_boxes_tensor = K.constant(max_boxes, dtype='int32') 36 boxes_ = [] 37 scores_ = [] 38 classes_ = [] 39 """ 40 # ---------------------------------------# 41 # 1、取出每一类得分大于score_threshold 42 # 的框和得分 43 # 2、对得分进行非极大抑制 44 # ---------------------------------------# 45 # 对每一个类进行判断""" 46 for c in range(num_classes): 47 # TODO: use keras backend instead of tf. 48 class_boxes = tf.boolean_mask(boxes, mask[:, c])#将输入的数组挑出想要的数据输出,将得分大于阈值的坐标挑选出来 49 #将第c类中得分大于阈值的坐标挑选出来 50 class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c]) 51 # 将第c类中得分大于阈值的框挑选出来 52 """非极大值抑制部分""" 53 # 非极大抑制,去掉box重合程度高的那一些 54 """原理:(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值; 55 56 (2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。 57 58 (3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。 59 60 就这样一直重复,找到所有被保留下来的矩形框。""" 61 nms_index = tf.image.non_max_suppression( 62 class_boxes, class_box_scores, max_boxes_tensor, iou_threshold=iou_threshold) 63 class_boxes = K.gather(class_boxes, nms_index) 64 class_box_scores = K.gather(class_box_scores, nms_index) 65 classes = K.ones_like(class_box_scores, 'int32') * c#将class_box_scores中的数变成1 66 boxes_.append(class_boxes) 67 scores_.append(class_box_scores) 68 classes_.append(classes) 69 boxes_ = K.concatenate(boxes_, axis=0) 70 scores_ = K.concatenate(scores_, axis=0) 71 classes_ = K.concatenate(classes_, axis=0) 72 #return 经过非极大值抑制保留下来的一个框 73 74 return boxes_, scores_, classes_
1.5 preprocess_true_box() 1 def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes): 2 ''' 3 在preprocess_true_boxes中,输入: 4 5 true_boxes:检测框,批次数16,最大框数20,每个框5个值,4个边界点和1个类别序号,如(16, 20, 5); 6 input_shape:图片尺寸,如(416, 416); 7 anchors:anchor box列表; 8 num_classes:类别的数量; 9 Preprocess true boxes to training input format 10 11 Parameters 12 ---------- 13 true_boxes: array, shape=(m, T, 5) 14 Absolute x_min, y_min, x_max, y_max, class_id relative to input_shape. 15 input_shape: array-like, hw, multiples of 32 16 anchors: array, shape=(N, 2), wh 17 num_classes: integer 18 19 Returns 20 ------- 21 y_true: list of array, shape like yolo_outputs, xywh are reletive value 22 23 ''' 24 # 检查有无异常数据 即txt提供的box id 是否存在大于 num_class的情况 25 # true_boxes.shape = (图片张数,每张图片box个数,5)(5是左上右下点坐标加上类别下标) 26 assert (true_boxes[..., 4]0 67 68 for b in range(m): 69 # Discard zero rows. 70 wh = boxes_wh[b, valid_mask[b]] 71 if len(wh)==0: continue 72 # Expand dim to apply broadcasting. 73 wh = np.expand_dims(wh, -2) 74 box_maxes = wh / 2. 75 box_mins = -box_maxes 76 # # 假设 bouding box 的中心也位于网格的中心 77 78 """计算标注框box与anchor box的iou值,计算方式很巧妙: 79 80 box_mins的shape是(7,1,2),anchor_mins的shape是(1,9,2),intersect_mins的shape是(7,9,2),即两两组合的值; 81 intersect_area的shape是(7,9); 82 box_area的shape是(7,1); 83 anchor_area的shape是(1,9); 84 iou的shape是(7,9); 85 IoU数据,即anchor box与检测框box,两两匹配的iou值""" 86 intersect_mins = np.maximum(box_mins, anchor_mins)#逐位比较 87 intersect_maxes = np.minimum(box_maxes, anchor_maxes) 88 intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.) 89 intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]#宽*高 90 box_area = wh[..., 0] * wh[..., 1] 91 anchor_area = anchors[..., 0] * anchors[..., 1] 92 iou = intersect_area / (box_area + anchor_area - intersect_area) 93 94 # Find best anchor for each true box 95 best_anchor = np.argmax(iou, axis=-1) 96 97 """设置y_true的值: 98 99 t是box的序号;n是最优anchor的序号;l是层号; 100 如果最优anchor在层l中,则设置其中的值,否则默认为0; 101 true_boxes是(16, 20, 5),即批次、box数、框值; 102 true_boxes[b, t, 0],其中b是批次序号、t是box序号,第0位是x,第1位是y; 103 grid_shapes是3个检测图的尺寸,将归一化的值,与框长宽相乘,恢复为具体值; 104 k是在anchor box中的序号; 105 c是类别,true_boxes的第4位; 106 将xy和wh放入y_true中,将y_true的第4位框的置信度设为1,将y_true第5~n位的类别设为1;""" 107 for t, n in enumerate(best_anchor): 108 # 遍历anchor 尺寸 3个尺寸 109 # 因为此时box 已经和一个anchor box匹配上,看这个anchor box属于那一层,小,中,大,然后将其box分配到那一层 110 for l in range(num_layers): 111 if n in anchor_mask[l]: 112 #因为grid_shape格式是hw所以是x*grid_shapes[l][1]=x*w,求出对应所在网格的横坐标,这里的x是相对于整张图片的相对坐标, 113 # 是在原先坐标上除以了w,所以现在要乘以w 114 i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32') 115 #np.around 四舍五入 116 #np.floor向下取整 117 #np.ceil向上取整 118 #np.where条件选取 119 # np.floor 返回不大于输入参数的最大整数。 即对于输入值 x ,将返回最大的整数 i ,使得 i (20,5) 37 if len(box)>0: 38 np.random.shuffle(box) 39 if len(box)>max_boxes: box = box[:max_boxes] 40 box[:, [0,2]] = box[:, [0,2]]*scale + dx 41 box[:, [1,3]] = box[:, [1,3]]*scale + dy 42 box_data[:len(box)] = box 43 44 return image_data, box_data 45 46 # resize image 47 #通过jitter参数,随机计算new_ar和scale,生成新的nh和nw, 48 # 将原始图像随机转换为nw和nh尺寸的图像,即非等比例变换图像。 49 #也即是数据增强 50 new_ar = w/h * rand(1-jitter,1+jitter)/rand(1-jitter,1+jitter) 51 scale = rand(.25, 2) 52 if new_ar < 1: 53 nh = int(scale*h) 54 nw = int(nh*new_ar) 55 else: 56 nw = int(scale*w) 57 nh = int(nw/new_ar) 58 image = image.resize((nw,nh), Image.BICUBIC) 59 60 # place image 61 dx = int(rand(0, w-nw)) 62 dy = int(rand(0, h-nh)) 63 new_image = Image.new('RGB', (w,h), (128,128,128)) 64 new_image.paste(image, (dx, dy)) 65 image = new_image 66 67 # flip image or not 68 #根据随机数flip,随机左右翻转FLIP_LEFT_RIGHT图片 69 flip = rand()1, box_h>1)] # discard invalid box 102 if len(box)>max_boxes: box = box[:max_boxes] 103 box_data[:len(box)] = box 104 105 return image_data, box_data4.yolo.py() 此函数主要用于检测图片或者视频 1 def generate(self): 2 """①加载权重参数文件,生成检测框,得分,以及对应类别 3 4 ②利用model.py中的yolo_eval函数生成检测框,得分,所属类别 5 6 ③初始化时调用generate函数生成图片的检测框,得分,所属类别(self.boxes, self.scores, self.classes)""" 7 model_path = os.path.expanduser(self.model_path) 8 assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.' 9 10 # Load model, or construct model and load weights. 11 num_anchors = len(self.anchors) 12 num_classes = len(self.class_names) 13 is_tiny_version = num_anchors==6 # default setting 14 try: 15 self.yolo_model = load_model(model_path, compile=False) 16 except: 17 self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \ 18 if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes) 19 self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match 20 else: 21 ##[-1]:网络最后一层输出。 output_shape[-1]:输出维度的最后一维。 -> (?,13,13,255) 22 # 255 = 9/3*(80+5). 9/3:每层特征图对应3个anchor box 80:80个类别 5:4+1,框的4个值+1个置信度 23 24 assert self.yolo_model.layers[-1].output_shape[-1] == \ 25 num_anchors/len(self.yolo_model.output) * (num_classes + 5), \ 26 'Mismatch between model and given anchor and class sizes' 27 #Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。 28 29 #断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况 30 31 print('{} model, anchors, and classes loaded.'.format(model_path)) 32 33 # Generate colors for drawing bounding boxes. 34 # Generate colors for drawing bounding boxes. 35 # 生成绘制边框的颜色。 36 # h(色调):x/len(self.class_names) s(饱和度):1.0 v(明亮):1.0 37 38 # 对于80种coco目标,确定每一种目标框的绘制颜色,即:将(x/80, 1.0, 1.0)的颜色转换为RGB格式,并随机调整颜色以便于肉眼识别, 39 # 其中:一个1.0表示饱和度,一个1.0表示亮度 40 41 hsv_tuples = [(x / len(self.class_names), 1., 1.) 42 for x in range(len(self.class_names))] 43 self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples)) #hsv转换为rgb 44 # hsv取值范围在【0,1】,而RBG取值范围在【0,255】,所以乘上255 45 self.colors = list( 46 map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), 47 self.colors)) 48 np.random.seed(10101) # Fixed seed for consistent colors across runs. 49 np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes. 50 np.random.seed(None) # Reset seed to default. 51 52 # Generate output tensor targets for filtered bounding boxes. 53 #为过滤的边界框生成输出张量目标 54 self.input_image_shape = K.placeholder(shape=(2, )) 55 if self.gpu_num>=2: 56 self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num) 57 boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors, 58 len(self.class_names), self.input_image_shape, 59 score_threshold=self.score, iou_threshold=self.iou) 60 return boxes, scores, classes 61 62 def detect_image(self, image): 63 """开始计时->①调用letterbox_image函数,即:先生成一个用“绝对灰”R128-G128-B128填充的416×416新图片,然后用按比例缩放(采样方式:BICUBIC)后的输入图片粘贴,粘贴不到的部分保留为灰色。②model_image_size定义的宽和高必须是32的倍数;若没有定义model_image_size,将输入的尺寸调整为32的倍数,并调用letterbox_image函数进行缩放。③将缩放后的图片数值除以255,做归一化。④将(416,416,3)数组调整为(1,416,416,3)元祖,满足网络输入的张量格式:image_data。 64 65 ->①运行self.sess.run()输入参数:输入图片416×416,学习模式0测试/1训练。 66 self.yolo_model.input: image_data,self.input_image_shape: [image.size[1], image.size[0]], 67 K.learning_phase(): 0。②self.generate(),读取:model路径、anchor box、coco类别、加载模型yolo.h5.,对于80中coco目标,确定每一种目标框的绘制颜色,即:将(x/80,1.0,1.0)的颜色转换为RGB格式,并随机调整颜色一遍肉眼识别,其中:一个1.0表示饱和度,一个1.0表示亮度。③若GPU>2调用multi_gpu_model() 68 69 ->①yolo_eval(self.yolo_model.output),max_boxes=20,每张图没类最多检测20个框。 70 ②将anchor_box分为3组,分别分配给三个尺度,yolo_model输出的feature map 71 ③特征图越小,感受野越大,对大目标越敏感,选大的anchor box-> 72 分别对三个feature map运行out_boxes, out_scores, out_classes,返回boxes、scores、classes。 73 """ 74 start = timer() 75 # # 调用letterbox_image()函数,即:先生成一个用“绝对灰”R128-G128-B128“填充的416x416新图片, 76 # 然后用按比例缩放(采样方法:BICUBIC)后的输入图片粘贴,粘贴不到的部分保留为灰色 77 78 if self.model_image_size != (None, None): #判断图片是否存在 79 assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required' 80 assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required' 81 # assert断言语句的语法格式 model_image_size[0][1]指图像的w和h,且必须是32的整数倍 82 boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size))) 83 # #letterbox_image对图像调整成输入尺寸(w,h) 84 else: 85 new_image_size = (image.width - (image.width % 32), 86 image.height - (image.height % 32)) 87 boxed_image = letterbox_image(image, new_image_size) 88 image_data = np.array(boxed_image, dtype='float32') 89 90 print(image_data.shape)#(416,416,3) 91 image_data /= 255.#将缩放后图片的数值除以255,做归一化 92 image_data = np.expand_dims(image_data, 0) # Add batch dimension. 93 # 批量添加一维 -> (1,416,416,3) 为了符合网络的输入格式 -> (bitch, w, h, c) 94 95 out_boxes, out_scores, out_classes = self.sess.run( 96 [self.boxes, self.scores, self.classes], 97 feed_dict={ 98 self.yolo_model.input: image_data,#图像数据 99 self.input_image_shape: [image.size[1], image.size[0]],#图像尺寸416x416 100 K.learning_phase(): 0#学习模式 0:测试模型。 1:训练模式 101 })#目的为了求boxes,scores,classes,具体计算方式定义在generate()函数内。在yolo.py第61行 102 103 print('Found {} boxes for {}'.format(len(out_boxes), 'img')) 104 # 绘制边框,自动设置边框宽度,绘制边框和类别文字,使用Pillow绘图库(PIL,头有声明) 105 # 设置字体 106 107 108 font = ImageFont.truetype(font='font/FiraMono-Medium.otf', 109 size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32')) 110 # 设置目标框线条的宽度 111 thickness = (image.size[0] + image.size[1]) // 300#厚度 112 ## 对于c个目标类别中的每个目标框i,调用Pillow画图 113 114 for i, c in reversed(list(enumerate(out_classes))): 115 predicted_class = self.class_names[c] #类别 #目标类别的名字 116 box = out_boxes[i]#框 117 score = out_scores[i]#置信度 118 119 label = '{} {:.2f}'.format(predicted_class, score) 120 draw = ImageDraw.Draw(image)#创建一个可以在给定图像上绘图的对象 121 label_size = draw.textsize(label, font)##标签文字 #返回label的宽和高(多少个pixels) 122 #返回给定字符串的大小,以像素为单位。 123 top, left, bottom, right = box 124 # 目标框的上、左两个坐标小数点后一位四舍五入 125 """防止检测框溢出""" 126 top = max(0, np.floor(top + 0.5).astype('int32')) 127 128 left = max(0, np.floor(left + 0.5).astype('int32')) 129 # 目标框的下、右两个坐标小数点后一位四舍五入,与图片的尺寸相比,取最小值 130 # 防止边框溢出 131 bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32')) 132 right = min(image.size[0], np.floor(right + 0.5).astype('int32')) 133 print(label, (left, top), (right, bottom)) 134 # 确定标签(label)起始点位置:标签的左、下 135 if top - label_size[1] >= 0: 136 text_origin = np.array([left, top - label_size[1]]) 137 else: 138 text_origin = np.array([left, top + 1]) 139 140 # My kingdom for a good redistributable image drawing library. 141 # 画目标框,线条宽度为thickness 142 for i in range(thickness):#画框 143 draw.rectangle( 144 [left + i, top + i, right - i, bottom - i], 145 outline=self.colors[c]) 146 # 画标签框 147 draw.rectangle( #文字背景 148 [tuple(text_origin), tuple(text_origin + label_size)], 149 fill=self.colors[c]) 150 # 填写标签内容 151 draw.text(text_origin, label, fill=(0, 0, 0), font=font)#文案 152 del draw 153 154 end = timer() 155 print(end - start) 156 return image 157 158 def close_session(self): 159 self.sess.close()
以上即是主要yolo3的主要部分,下面将会对模型进行测试 5.测试 在理解完原理与上述代码之后,下面进行测试(当然也可以不用理解源码也可以直接测试) (1) 首先需要下载yolo3.weights,下载地址: https://pjreddie.com/media/files/yolov3.weights (2) 在pycharm的终端中输入python convert.py yolov3.cfg yolov3.weights model_data/yolo_weights.h5 作用是将yolo3.weights文件转换成Keras可以处理的.h5权值文件,(3)随便在网上下载一张图片进行测试,比如笔者用一张飞机的照片(4)在源码中,不能直接运行yolo.py,因为在此代码中没有if__name__=='__main__':所以需要自己添加: 1 if __name__ == '__main__': 2 """测试图片""" 3 yolo = YOLO() 4 path = r'F:\chorme_download\keras-yolo3-master\微信图片_20200313132254.jpg' 5 try: 6 image = Image.open(path) 7 except: 8 print('Open Error! Try again!') 9 else: 10 r_image = yolo.detect_image(image) 11 r_image.show() 12 13 yolo.close_session() 14 """测试视频,将detect_video中的path置0即调用自己电脑的摄像头""" 15 yolo=YOLO() 16 detect_video(yolo,0)6.结果
本文为原创,制作不易,转载请标明出处,谢谢!!!
|

【本文地址】
今日新闻 |
推荐新闻 |