Hadoop(3)hdfs功能详解、hdfs架构剖析、hdfs优缺点 |
您所在的位置:网站首页 › hdfs特点描述 › Hadoop(3)hdfs功能详解、hdfs架构剖析、hdfs优缺点 |
Hadoop(3)hdfs功能详解、hdfs架构剖析、hdfs优缺点
|
hdfs功能详解
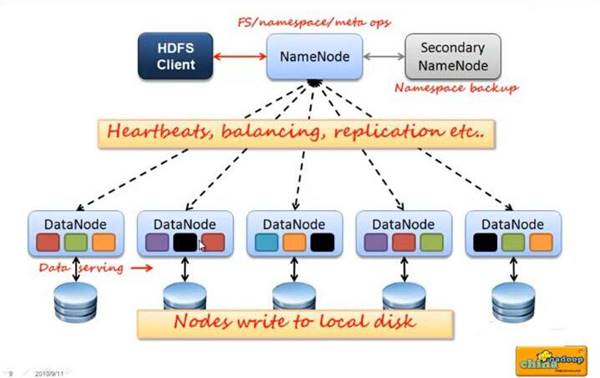
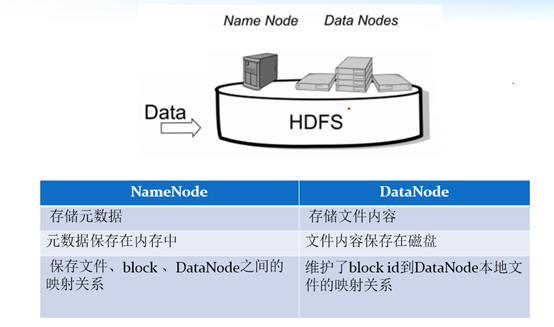
`HDFS(hadoop distributed filesystem)由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。 HDFS客户端:就是客户端。 1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。 2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。 NameNode:即Master, 1、管理 HDFS 的名称空间。 2、管理数据块(Block)映射信息 3、配置副本策略 4、处理客户端读写请求。 DataNode: 就是Slave。NameNode 下达命令,DataNode 执行实际的操作。 1、存储实际的数据块。 2、执行数据块的读/写操作。 Secondary NameNode: 并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。 1、辅助 NameNode,分担其工作量。 2、定期合并 fsimage和fsedits,并推送给NameNode。 3、在紧急情况下,可辅助恢复 NameNode。 hdfs的架构详细剖析HDFS分布式文件系统也是一个主从架构,主节点是我们的namenode,负责管理整个集群以及维护集群的元数据信息,从节点datanode,主要负责文件数据存储: 1)HDFS集群包括,NameNode和DataNode以及Secondary Namenode。 2)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。 3)DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。 4)Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要作用是辅助namenode管理元数据信息
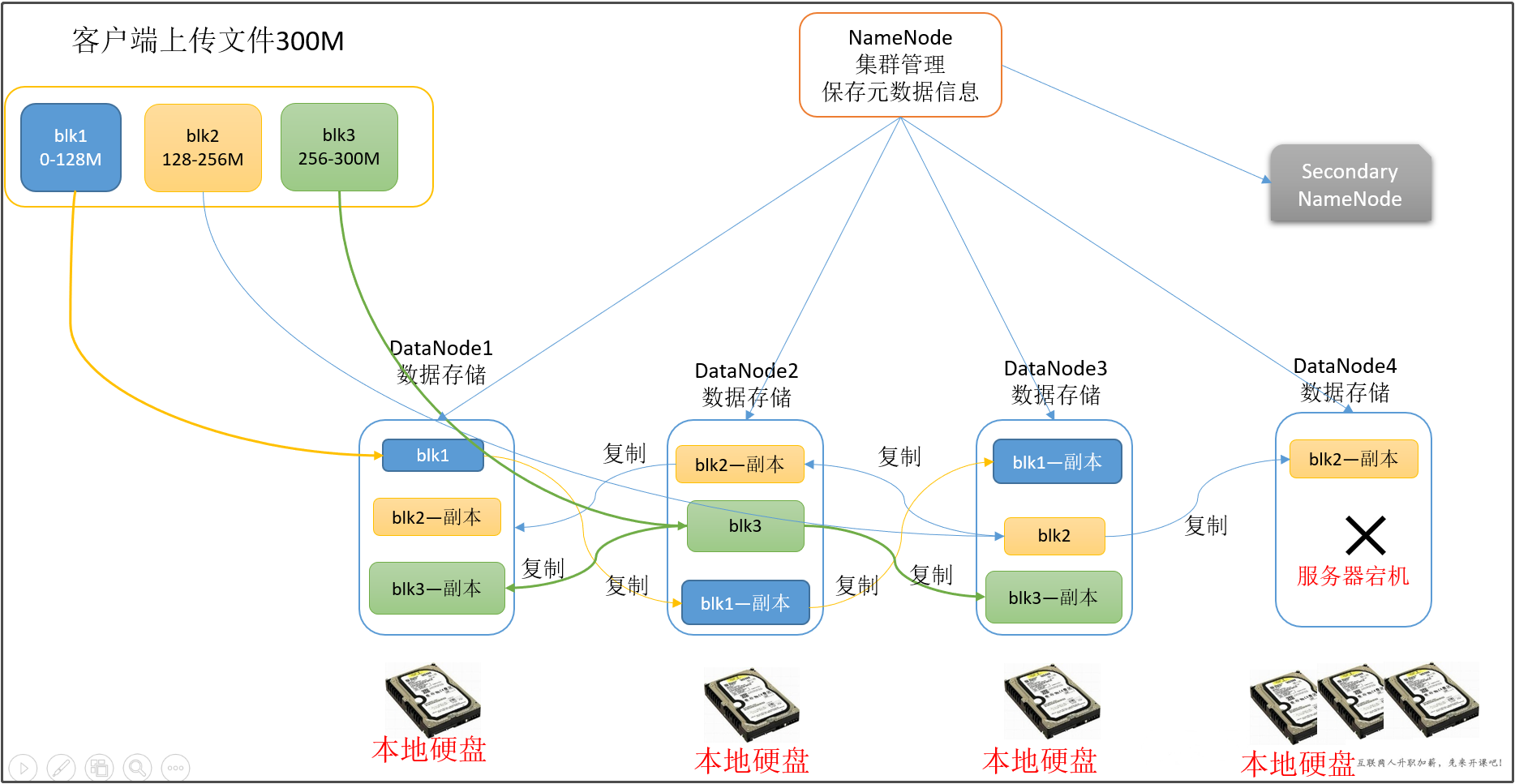
Namenode与Datanode的关系图示:
NameNode与Datanode的总结概述
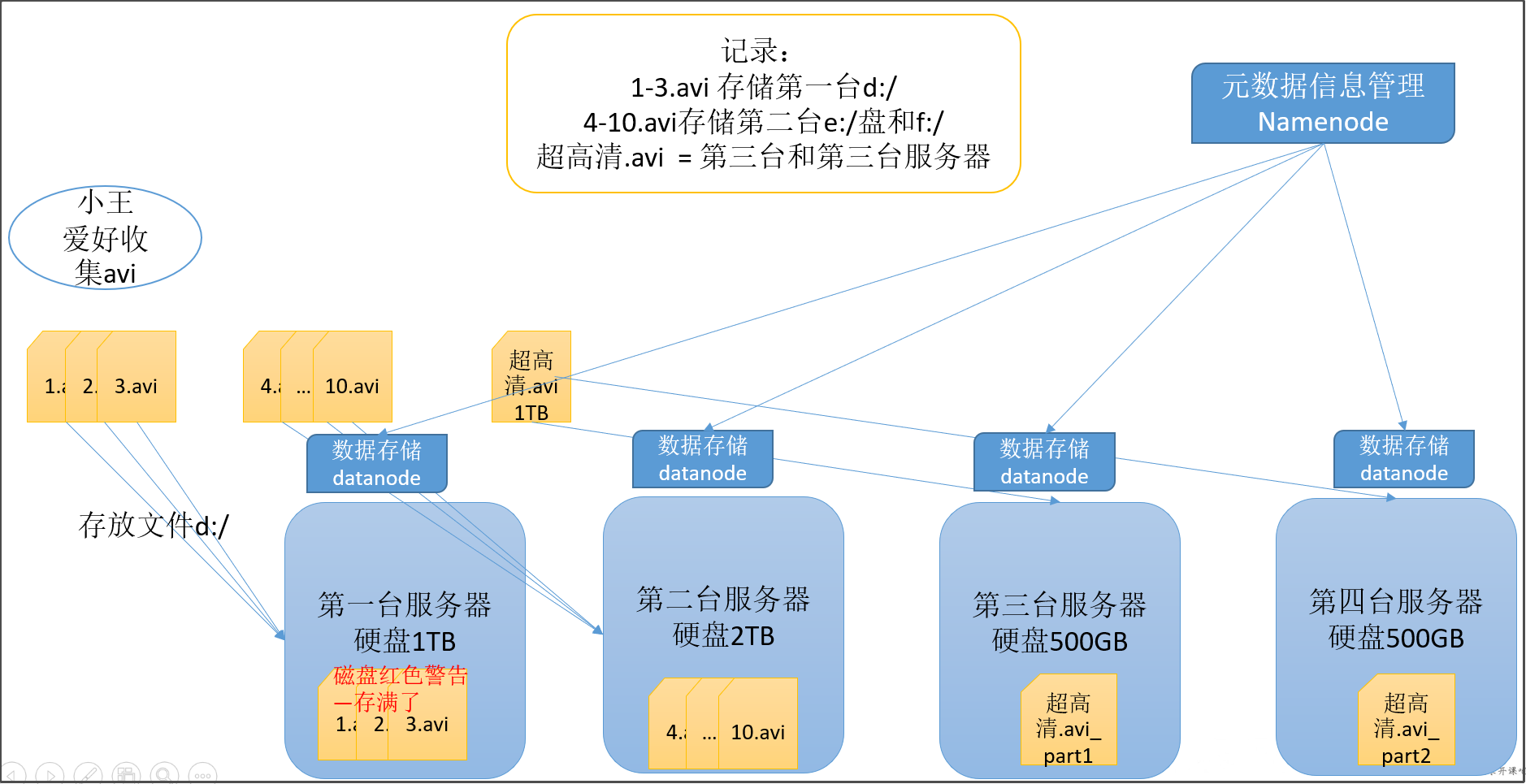
hdfs文件系统容量大小约等于各个服务器的容量大小之和得到,为什么是约等于?因为每个服务器都要留部分空间给自身系统等东西,不能全部用来做hdfs的容量。 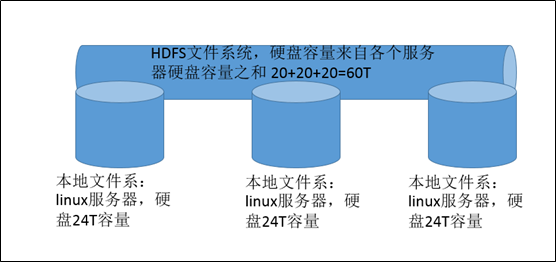 hdfs存储方式---block
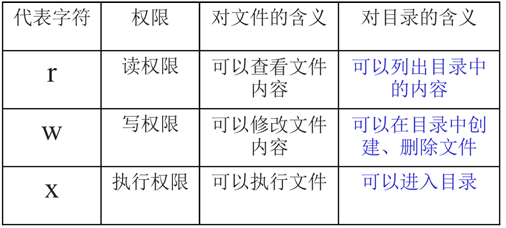
hdfs的数据以block块的形式进统一存储管理,每个block块默认最多可以存储128M的文件,如果有一个文件大小为1KB,也是要占用一个block块,但是实际占用磁盘空间还是1KB大小,类似于有一个水桶可以装128斤的水,但是我只装了1斤的水,那么我的水桶里面水的重量就是1斤,而不是128斤。除了些用不可分割算法进行压缩的文件不可被切分外,几乎所有文件都可以被切割。 每个block块的元数据大小大概为150字节 所有的文件都是以block块的方式存放在HDFS文件系统当中,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定: dfs.block.size 块大小 以字节为单位抽象成数据块的好处: 一个文件有可能大于集群中任意一个磁盘 10T*3/128 = xxx块 2T,2T,2T 文件方式存—–>多个block块,这些block块属于一个文件 使用块抽象而不是文件可以简化存储子系统 块非常适合用于数据备份进而提供数据容错能力和可用性hdfs的副本因子 为了保证block块的安全性,也就是数据的安全性,文件默认保存三个副本,我们可以更改副本数以提高数据的安全性,在hdfs-site.xml当中修改以下配置属性,即可更改文件的副本数: dfs.replication 3块缓存 通常DataNode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被缓存在DataNode的内存中,以堆外块缓存的形式存在。默认情况下,一个块仅缓存在一个DataNode的内存中,当然可以针对每个文件配置DataNode的数量。作业调度器通过在缓存块的DataNode上运行任务,可以利用块缓存的优势提高读操作的性能。 例如: 连接(join)操作中使用的一个小的查询表就是块缓存的一个很好的候选。 用户或应用通过在缓存池中增加一个cache directive来告诉namenode需要缓存哪些文件及存多久。缓存池(cache pool)是一个拥有管理缓存权限和资源使用的管理性分组。 hdfs的文件权限验证hdfs的文件权限机制与linux系统的文件权限机制类似:r:read w:write x:execute
删除一个文件需要的是具有该文件所在目录的写权限,而不是具有该文件的写权限,文件的写权限只能够修改文件内容,HDFS文件权限的目的,防止好人做错事,而不是阻止坏人做坏事。HDFS相信你告诉我你是谁,你就是谁 通过shell修改hdfs系统文件的权限和所有者: hdfs dfs -chown /文件 hdfs dfs -chmode /文件 hdfs的端口号查看core-site.xml配置文件,可以看到hdfs文件系统的端口号是8020 fs.defaultFS hdfs://node01:8020 hdfs的优缺点 hdfs的优点(1) 高容错性 数据自动保存多个副本。它通过增加副本的形式,提高容错性。 某一个副本丢失以后,它可以自动恢复,这是由 HDFS 内部机制实现的,我们不必关心。 (2) 适合批处理 它是通过移动计算而不是移动数据。 它会把数据位置暴露给计算框架。 (3) 适合大数据处理 数据规模:能够处理数据规模达到 GB、TB、甚至PB级别的数据。 文件规模:能够处理百万规模以上的文件数量,数量相当之大。 节点规模:能够处理10K节点的规模。 (4) 流式数据访问 一次写入,多次读取,不能修改,只能追加。 它能保证数据的一致性。 (5) 可构建在廉价机器上 它通过多副本机制,提高可靠性。 它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。 hdfs的缺点(1) 不适合低延时数据访问; 比如毫秒级的来存储数据,这是不行的,它做不到。 它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。 改进策略:使用Hbase (2) 无法高效的对大量小文件进行存储 存储大量小文件的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。 小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。 改进策略 (3) 不支持并发写入、不支持文件随机修改 一个文件只能有一个写,不允许多个线程同时写。(支持并发读取) 仅支持数据 append(追加),不支持文件的随机修改。 |
【本文地址】