Hadoop分布式文件系统HDFS笔记 |
您所在的位置:网站首页 › hbase分布式模式最好需要几个节点 › Hadoop分布式文件系统HDFS笔记 |
Hadoop分布式文件系统HDFS笔记
|
一、ITB大文件操作的思考(理解) 文件大小单位:B,KB,MB,GB,TB,PB,EB,ZB,YB... 1B=1Byte=8bit 1KB=1024B 1MB=1024KB 1GB=1024MB 1TB=1024GB 1PB=1024TB 1EB=1024PB 1ZB=1024EB 分治思想引入案例 单机处理大数据的问题 集群分布式处理大数据 集群分布式处理大数据优劣的辩证 1.1 分治思想引入案例十万个元素(单词)需要存储,如何存储?数组ArrayList、LinkedListHashMap如果想查找某一个元素,最简单的遍历方式的复杂度是多少? 3.如果我们期望复杂度是O(4)呢?  4.分而治之的思想非常重要,常见于以下技术: Redis集群 Hadoop Hbase ElasticSearch1.2 单机处理大数据的问题需求:  有一个非常大的文本文件,里面有非常多的行,只有两行内容一样,它们出现在未知的位置,需要查找到它们。硬件:单台机器,而且可用的内存很少,也就500MB。 • 假如IO速度是500MB/S 1000 000 MB/500(MB/S) = 1000*2S • 1T文件读取一遍需要约30分钟(2000S/60S) • 循环遍历需要N次IO时间 • 分治思想可以使时间降为2次IO 如何对1TB文件进行排序? • 假如IO速度是500MB/S • 1T文件读取一遍需要约30分钟 方式1:外部有序,内部无序,然后再逐一读入内存排序 方式2:逐一读取500M排序,内部有序,外部无序 ,然后进行归并排序  1.3 集群分布式处理大数据 1.3 集群分布式处理大数据需求: • 有一个非常大的文本文件,里面有几百亿行,只有两行内容一样,它们出现在未知的位置,需要查找到它们。 • 分钟、秒级别完成 • 硬件:*台机器,而且可用的内存500MB。  1.4 集群分布式处理大数据优劣的辩证 1.4 集群分布式处理大数据优劣的辩证2000台真的比一台快吗? 由于涉及到计算机之间文件传输,千兆带宽1000Mb/S也就是100MB/s 注意:1b = 1bit 1B=1Byte=8bit 拉取网卡100MB/S ,之前忽略了上传时间:1TB/100(MB/S) = 1000 000MB/100(MB/S) =10000S 10000S/3600S = 3H • 如果考虑分发上传文件的时间呢? • 如果考虑每天都有1TB数据的产生呢? • 如果增量了一年,最后一天计算数据呢? 时间(天)单机所需时间集群分布式所需时间12*30=1H3H1M2S22H3H1M4S33H3H1M6S44H3H1M8S.........300300H3H11M二、Hadoop概述2.1 Hadoop是什么?Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 Hadoop以一种可靠、高效、可伸缩的方式对大量数据存储和分析计算。 用户可以在不了解分布式底层细节的情况下,开发分布式程序。 Hadoop生态圈:  2.2 发展历史 2.2 发展历史 Doug Cutting 2002年10月,Doug Cutting和Mike Cafarella创建了开源网页爬虫项目Nutch。2003年10月,Google发表Google File System论文。2004年7月,Doug Cutting和Mike Cafarella在Nutch中实现了类似GFS的功能,即后来HDFS的前身。2004年10月,Google发表了MapReduce论文。2005年2月,Mike Cafarella在Nutch中实现了MapReduce的最初版本。2005年12月,开源搜索项目Nutch移植到新框架,使用MapReduce和HDFS在20个节点稳定运行。2006年1月,Doug Cutting加入雅虎,Yahoo!提供一个专门的团队和资源将Hadoop发展成一个可在网络上运行的系统。2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。2006年3月,Yahoo!建设了第一个Hadoop集群用于开发。2006年4月,第一个Apache Hadoop发布。2006年11月,Google发表了Bigtable论文,激起了Hbase的创建。2007年10月,第一个Hadoop用户组会议召开,社区贡献开始急剧上升。2007年,百度开始使用Hadoop做离线处理。2007年,中国移动开始在“大云”研究中使用Hadoop技术。2008年,淘宝开始投入研究基于Hadoop的系统——云梯,并将其用于处理电子商务相关数据。2008年1月,Hadoop成为Apache顶级项目。2008年2月,Yahoo!运行了世界上最大的Hadoop应用,宣布其搜索引擎产品部署在一个拥有1万个内核的Hadoop集群上。2008年4月,在900个节点上运行1TB排序测试集仅需209秒,成为世界最快。2008年8月,第一个Hadoop商业化公司Cloudera成立。2008年10月,研究集群每天装载10TB的数据。2009 年3月,Cloudera推出世界上首个Hadoop发行版——CDH(Cloudera's Distribution including Apache Hadoop)平台,完全由开放源码软件组成。2009年6月,Cloudera的工程师Tom White编写的《Hadoop权威指南》初版出版,后被誉为Hadoop圣经。2009年7月 ,Hadoop Core项目更名为Hadoop Common;2009年7月 ,MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。2009年8月,Hadoop创始人Doug Cutting加入Cloudera担任首席架构师。2009年10月,首届Hadoop World大会在纽约召开。2010年5月,IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。2011年3月,Apache Hadoop获得Media Guardian Innovation Awards媒体卫报创新奖2012年3月,企业必须的重要功能HDFS NameNode HA被加入Hadoop主版本。2012年8月,另外一个重要的企业适用功能YARN成为Hadoop子项目。2014年2月,Spark逐渐代替MapReduce成为Hadoop的缺省执行引擎,并成为Apache基金会顶级项目。2017年12月,Release 3.0.0 generally available更多版本信息见:https://hadoop.apache.org/release.html2.3 Hadoop三大发行版本(了解)Hadoop三大发行版本:Apache、Cloudera、Hortonworks。 Apache版本最原始(最基础)的版本,对于入门学习最好。 Cloudera内部集成了很多大数据框架。对应产品CDH。 Hortonworks文档较好。对应产品HDP。 1)Apache Hadoop 官网地址:http://hadoop.apache.org/releases.html 下载地址:https://archive.apache.org/dist/hadoop/common/ 2)Cloudera Hadoop 官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html 下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/ (1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。 (2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support (3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。 (4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。 3)Hortonworks Hadoop 官网地址:https://hortonworks.com/products/data-center/hdp/ 下载地址:https://hortonworks.com/downloads/#data-platform (1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。 (2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。 (3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。 (4)Hortonworks目前已经被Cloudera公司收购。 2.4 核心组件hadoop通用组件 - Hadoop Common包含了其他hadoop模块要用到的库文件和工具 分布式文件系统 - Hadoop Distributed File System (HDFS)运行于通用硬件上的分布式文件系统,高吞吐,高可靠 资源管理组件 - Hadoop YARN于2012年引入的组件,用于管理集群中的计算资源并在这些资源上调度用户应用。 分布式计算框架 - Hadoop MapReduce用于处理超大数据集计算的MapReduce编程模型的实现。 Hadoop Ozone: An object store for Hadoop. Hadoop Submarine: A machine learning engine for Hadoop 2.5 Hadoop关联项目 Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeepr、Sqoop和Hcatalog等的集中管理。也是5个顶级hadoop管理工具之一。 Avro™:数据序列化系统 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 Mahout 提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。 Apache Pig 是一个高级过程语言,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab开源的类Hadoop MapReduce的通用并行框架,拥有MapReduce所具有的优点;但是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。 Tez 是 Apache 最新的支持 DAG 作业的开源计算框架。它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。 HBase是一个分布式的、高可靠性、高性能、面向列、可伸缩的分布式存储系统,该技术来源于Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。 三、HDFS概述3.1 HDFS介绍产生背景 随着数据量越来越大,在一台电脑上存不下所有的数据,那么就分配到更多的电脑组成的集群上,但是不方便管理和维护,于是就需要一种可以在集群中来管理多台机器上文件的系统,即分布式文件关系系统。HDFS便是分布式文件管理系统中的一员。 定义: HDFS (Hadoop Distributed File System):分布式文件系统,用于存在文件,通过目录树来定位文件;构建在分布式集群上,集群中的服务器有各自的角色。 适用场景 适合一次写入,多次读取的场景。适合用来做大数据分析。 HDFS优点 可构建在廉价的机器上 高容错 数据自动保存多个副本,通过增加副本的形式,提高容错性。 2.5 Hadoop关联项目 Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeepr、Sqoop和Hcatalog等的集中管理。也是5个顶级hadoop管理工具之一。 Avro™:数据序列化系统 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 Mahout 提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。 Apache Pig 是一个高级过程语言,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab开源的类Hadoop MapReduce的通用并行框架,拥有MapReduce所具有的优点;但是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。 Tez 是 Apache 最新的支持 DAG 作业的开源计算框架。它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。 HBase是一个分布式的、高可靠性、高性能、面向列、可伸缩的分布式存储系统,该技术来源于Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。 三、HDFS概述3.1 HDFS介绍产生背景 随着数据量越来越大,在一台电脑上存不下所有的数据,那么就分配到更多的电脑组成的集群上,但是不方便管理和维护,于是就需要一种可以在集群中来管理多台机器上文件的系统,即分布式文件关系系统。HDFS便是分布式文件管理系统中的一员。 定义: HDFS (Hadoop Distributed File System):分布式文件系统,用于存在文件,通过目录树来定位文件;构建在分布式集群上,集群中的服务器有各自的角色。 适用场景 适合一次写入,多次读取的场景。适合用来做大数据分析。 HDFS优点 可构建在廉价的机器上 高容错 数据自动保存多个副本,通过增加副本的形式,提高容错性。  当某一个副本数据块丢失后,通过自动恢复保持副本数量。 当某一个副本数据块丢失后,通过自动恢复保持副本数量。  适合存储大量数据HDFS上的一个典型文件大小一般都在G字节至T字节。MB GB TB PB ZBHDFS支持大文件存储。单一HDFS实例能支撑数以千万计的文件。 简单的一致性模型HDFS应用遵循“一次写入多次读取”的文件访问模型。简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。HDFS缺点不适合低延迟的数据访问。无法高效的对大量小文件进行存储。不支持对同一个文件的并发写入。不支持文件的随机修改。3.2 HDFS架构剖析 适合存储大量数据HDFS上的一个典型文件大小一般都在G字节至T字节。MB GB TB PB ZBHDFS支持大文件存储。单一HDFS实例能支撑数以千万计的文件。 简单的一致性模型HDFS应用遵循“一次写入多次读取”的文件访问模型。简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。HDFS缺点不适合低延迟的数据访问。无法高效的对大量小文件进行存储。不支持对同一个文件的并发写入。不支持文件的随机修改。3.2 HDFS架构剖析HDFS架构图: 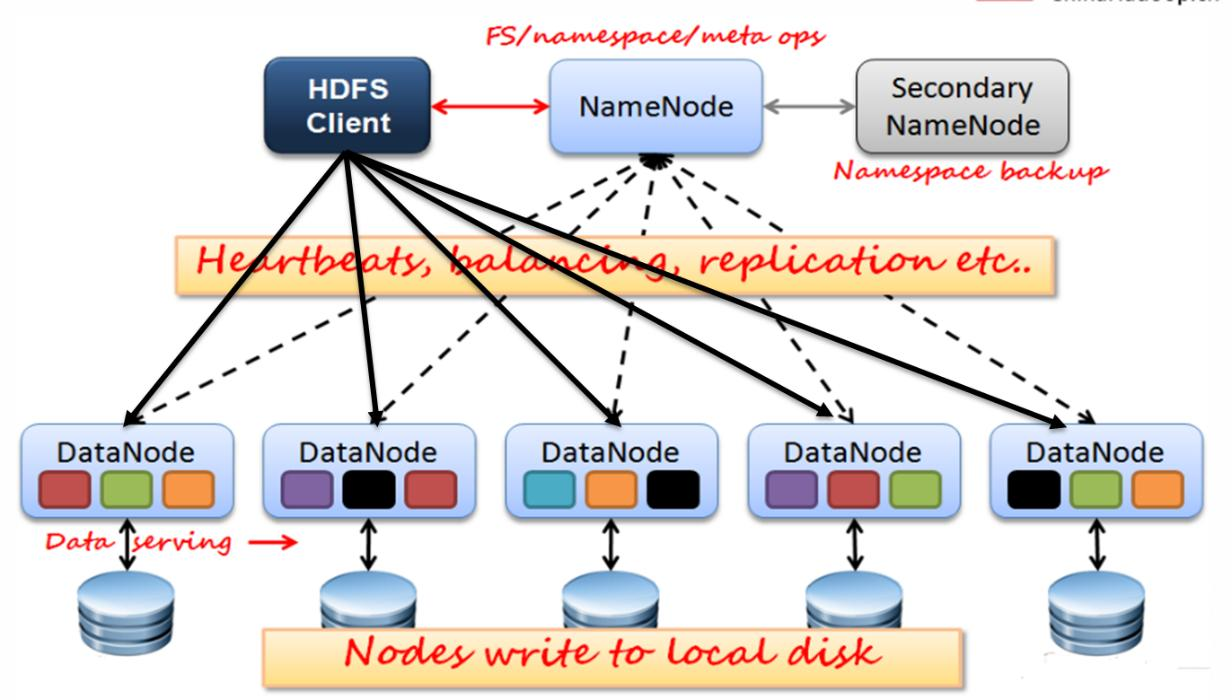 思考:100台服务器,存储空间单个8TB,总存储空间为800TB,那么5TB文件如何存储? 128MB一块 128MB8=1GB 12881024=1TB 5TB数据分成的128MB的块数8192 *5。 清单: 5TB文件分的块: 元数据: 文件名称:web.log,大小:5TB ,创建时间,权限,文件所有者,文件所属的用户组,文件类型等。 文件块列表信息: 0~12810241024 -1:128MB:node1:path,node3:path,node8:path 12810241024~212810241024 -1:128MB:node2:path,node4:path,node9:path 212810241024~312810241024 -1:128MB:node3:path,.... ......  四、HDFS完全分布式搭建 四、HDFS完全分布式搭建hadoop运行模式:本地模式、伪分布式模式、完全分布式模式、高可用的完全分布式模式。 4.1 规划首先将四台虚拟机均拍摄一个快照:hadoop完全分布式Pre。如果安装失败,那么很方便进行重置。 node1node2node3node4NameNodeSecondaryNameNodeDataNode-1DataNode-2DataNode-3注意:NameNode和SecondaryNameNode都比较消耗内存,所以不要将它们安装在同一台服务器上。 4.2 前置环境4.2.1 免密钥设置首先将node1和node2拍摄快照,并还原到初始化快照上。 由于后续hadoop等需要四台服务器之间互相均可以免密登录,所以本次直接配置四台服务器的彼此之间的免密登录。配置思路如下:  a、 首先在四台服务器上都要执行: ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsab、在node1上将node1 的公钥拷贝到authorized_keys中: cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给node2: scp ~/.ssh/authorized_keys node2:/root/.ssh/c、在node2中将node2的公钥追加到authorized_keys中: cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给node3: scp ~/.ssh/authorized_keys node3:/root/.ssh/d、在node3中将node3的公钥追加到authorized_keys中: cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给node4: scp ~/.ssh/authorized_keys node4:/root/.ssh/e、在node4中将node4的公钥追加到authorized_keys中: cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给node1、node2、node3: scp ~/.ssh/authorized_keys node1:/root/.ssh/ scp ~/.ssh/authorized_keys node2:/root/.ssh/ scp ~/.ssh/authorized_keys node3:/root/.ssh/f.测试是否实现了免密登录 ssh node[1、2、3、4] exit # 退出4.2.2 JDK安装环境变量配置node1-node4上目录的创建目录/opt/apps mkdir /opt/apps将jdk-8u221-linux-x64.rpm上传到node1/opt/apps 将/opt/apps下的jdk-8u221-linux-x64.rpm scp到node2、node3、node4的对应目录中 scp jdk-8u221-linux-x64.rpm node2:/opt/apps scp jdk-8u221-linux-x64.rpm node3:/opt/apps scp jdk-8u221-linux-x64.rpm node4:/opt/apps在node1、node2、node3、node4上安装jdk并配置profile文件 rpm -ivh jdk-8u221-linux-x64.rpmnode1上修改环境变量 vim /etc/profile export JAVA_HOME=/usr/java/default export PATH=$PATH:$JAVA_HOME/bin source /etc/profile将node1的/etc/profile拷贝到node2、node3、node4上并执行 source /etc/profile scp /etc/profile node[234]:`pwd`4.3 集群搭建实战4.3.1 hadoop安装包相关Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/ 将hadoop安装文件上传到node1的/opt/apps目录下,并解压到/opt目录下 #创建一个用户,默认会创建一个同名的用户组 [root@node1 ~]# useradd itbaizhan #解压 [root@node1 ~]# cd /opt/apps [root@node1 apps]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt重要目录 [root@node1 apps]# cd /opt [root@node1 opt]# ll 总用量 0 drwxr-xr-x 2 root root 33 10月 8 13:03 apps drwxr-xr-x 9 itbaizhan itbaizhan 149 9月 12 2019 hadoop-3.1.3 [root@node1 opt]# vim /etc/passwd [root@node1 opt]# cd hadoop-3.1.3/ [root@node1 hadoop-3.1.3]# ll 总用量 176 drwxr-xr-x 2 itbaizhan itbaizhan 183 9月 12 2019 bin drwxr-xr-x 3 itbaizhan itbaizhan 20 9月 12 2019 etc drwxr-xr-x 2 itbaizhan itbaizhan 106 9月 12 2019 include drwxr-xr-x 3 itbaizhan itbaizhan 20 9月 12 2019 lib drwxr-xr-x 4 itbaizhan itbaizhan 288 9月 12 2019 libexec -rw-rw-r-- 1 itbaizhan itbaizhan 147145 9月 4 2019 LICENSE.txt -rw-rw-r-- 1 itbaizhan itbaizhan 21867 9月 4 2019 NOTICE.txt -rw-rw-r-- 1 itbaizhan itbaizhan 1366 9月 4 2019 README.txt drwxr-xr-x 3 itbaizhan itbaizhan 4096 9月 12 2019 sbin drwxr-xr-x 4 itbaizhan itbaizhan 31 9月 12 2019 sharebin目录:存放对Hadoop相关服务(hadoop,hdfs,yarn)进行操作的脚本etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)sbin目录:存放启动或停止Hadoop相关服务的脚本share目录:存放Hadoop的依赖jar包、文档、和官方案例配置文件说明 Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。 默认配置文件:要获取的默认文件文件存放在Hadoop的jar包中的位置[core-default.xml]hadoop-common-3.1.3.jar/ core-default.xml[hdfs-default.xml]hadoop-hdfs-3.1.3.jar/ hdfs-default.xml自定义配置文件: core-site.xml、hdfs-site.xml两个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。 文件作用hadoop-env.sh找jdk环境变量workers(hadoop2.x中的名称slaves )指定datanode节点core-site.xml涉及到的参数如果没有配置,找对应的默认文件中的配置hdfs-site.xml涉及到的参数如果没有配置,找对应的默认文件中的配置常用端口号说明DaemonAppHadoop2Hadoop3NameNode PortHadoop HDFS NameNode8020 / 90009820Hadoop HDFS NameNode HTTP UI500709870Secondary NameNode PortSecondary NameNode500919869Secondary NameNode HTTP UI500909868DataNode PortHadoop HDFS DataNode IPC500209867Hadoop HDFS DataNode500109866Hadoop HDFS DataNode HTTP UI5007598644.3.2 HDFS集群配置node1-4关闭和禁用防火墙#检查防火墙的状态 [root@node1 ~]# systemctl status firewalld ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled) Active: inactive (dead) Docs: man:firewalld(1) #关闭防火墙 [root@node1 ~]# systemctl stop firewalld #禁用防火墙 [root@node1 ~]# systemctl disable firewalld环境变量配置#node1上修改环境变量 export HADOOP_HOME=/opt/hadoop-3.1.3 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #Node2上修改环境变量: export HADOOP_HOME=/opt/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #node1-2上让配置文件生效: source /etc/profile #将node2的/etc/profile拷贝到node3、node4上并执行 scp /etc/profile node[34]:`pwd` source /etc/profilehadoop-env.sh配置#进入$HADOOP_HOME/etc/hadoop cd /opt/hadoop-3.1.3/etc/hadoop/ #修改hadoop-env.sh export JAVA_HOME=/usr/java/default由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,需要手动指定。 workers配置修改workers(hadoop2.x为slaves)文件,指定datanode的位置 node2 node3 node4注意:该文件中不能出现空行,添加的内容结尾也不能出现空格。 core-site.xml配置 fs.defaultFS hdfs://node1:9820 hadoop.tmp.dir /var/itbaizhan/hadoop/full hdfs-site.xml配置 dfs.namenode.http-address node1:9870 dfs.namenode.secondary.http-address node2:9868 dfs.replication 2 拷贝到node2-node4上#先将之打成压缩包 [root@node1 opt]# tar -zcvf hadoop-3.1.3.tar.gz hadoop-3.1.3/ #将/opt/hadoop-3.1.3.tar.gz scp到node2、node3、node4的对应目录中 [root@node1 opt]# scp hadoop-3.1.3.tar.gz node2:/opt [root@node1 opt]# scp hadoop-3.1.3.tar.gz node3:/opt [root@node1 opt]# scp hadoop-3.1.3.tar.gz node4:/opt #node2、node3、node4分别解压 tar -zxvf hadoop-3.1.3.tar.gz #node1、node2、node3、node4测试 [root@node4 opt]# had #然后按下 Tab 制表符,能够自动补全为hadoop,说明环境变量是好的。 #获取通过hadoop version命令测试 [root@node4 opt]# hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /opt/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar4.3.3 格式化、启动和测试格式化#在node1上执行: [root@node1 ~]# hdfs namenode -format [root@node1 ~]# ll /var/itbaizhan/hadoop/full/dfs/name/current/ 总用量 16 -rw-r--r-- 1 root root 391 10月 8 20:36 fsimage_0000000000000000000 -rw-r--r-- 1 root root 62 10月 8 20:36 fsimage_0000000000000000000.md5 -rw-r--r-- 1 root root 2 10月 8 20:36 seen_txid -rw-r--r-- 1 root root 216 10月 8 20:36 VERSION #在node1-4四个节点上执行jps,jps作用显示当前系统中的java进程 [root@node1 ~]# jps 2037 Jps [root@node2 ~]# jps 1981 Jps [root@node3 ~]# jps 1979 Jps [root@node4 ~]# jps 1974 Jps #通过观察并没有发现除了jps之外并没有其它的java进程。 # [root@node1 ~]# vim /var/itbaizhan/hadoop/full/dfs/name/current/VERSION #Sat Oct 09 10:42:49 CST 2021 namespaceID=1536048782 clusterID=CID-7ecb999c-ef5a-4396-bdc7-c9a741a797c4 #集群id cTime=1633747369798 storageType=NAME_NODE #角色为NameNode blockpoolID=BP-1438277808-192.168.20.101-1633747369798#本次格式化后块池的id layoutVersion=-64启动HDFS#在node1启动HDFS集群 [root@node1 ~]# start-dfs.sh #启动时出现如下错误信息 Starting namenodes on [node1] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [node2] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation. #解决办法,就是修改start-dfs.sh,添加以下内容 [root@node1 ~]# vim /opt/hadoop-3.1.3/sbin/start-dfs.sh HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=root HDFS_SECONDARYNAMENODE_USER=root #查看四个节点上对应的角色是否启动 [root@node1 ~]# jps 3947 Jps 3534 NameNode [root@node2 ~]# jps 3386 Jps 3307 SecondaryNameNode 3148 DataNode [root@node3 ~]# jps 3303 Jps 3144 DataNode [root@node4 ~]# jps 3310 Jps 3151 DataNodeWeb端查看HDFS的NameNode相关信息在浏览器地址栏中输入:http://192.168.20.101:9870,查看HDFS上存储的数据信息,以及DataNode节点的相关信息。  DataNodes相关信息页面:http://192.168.20.101:9870/dfshealth.html#tab-datanode  HDFS文件系统目录列表信息页:  4.3.4 常见的HDFS命令行操作#在HDFS文件系统中创建一个目录
[root@node1 opt]# hdfs dfs -mkdir -p /user/root
#查看HDFS指定目录的文件列表
[root@node1 ~]# hdfs dfs -ls /user
Found 1 items
drwxr-xr-x - root supergroup 0 2021-10-09 11:07 /user/root
[root@node1 ~]# hdfs dfs -ls /user/root
#上传文件到指定目录
[root@node1 opt]# hdfs dfs -put hadoop-3.1.3.tar.gz /user/root
#创建一个文本文件并上传
[root@node2 ~]# vim test.txt
hello tom
hello itbaizhan
hello gtjin
[root@node2 ~]# hdfs dfs -put test.txt /usr/root
put: `/usr/root': No such file or directory: `hdfs://node1:9820/usr/root'#路径写错了。
#上传文件时需要指定存在的路径
[root@node2 ~]# hdfs dfs -put test.txt /user/root
#再次查看指定目录下的文件列表
[root@node2 ~]# hdfs dfs -ls /user/root
Found 2 items
-rw-r--r-- 2 root supergroup 338075860 2021-10-09 11:11 /user/root/hadoop-3.1.3.tar.gz
-rw-r--r-- 2 root supergroup 38 2021-10-09 11:12 /user/root/test.txt 4.3.4 常见的HDFS命令行操作#在HDFS文件系统中创建一个目录
[root@node1 opt]# hdfs dfs -mkdir -p /user/root
#查看HDFS指定目录的文件列表
[root@node1 ~]# hdfs dfs -ls /user
Found 1 items
drwxr-xr-x - root supergroup 0 2021-10-09 11:07 /user/root
[root@node1 ~]# hdfs dfs -ls /user/root
#上传文件到指定目录
[root@node1 opt]# hdfs dfs -put hadoop-3.1.3.tar.gz /user/root
#创建一个文本文件并上传
[root@node2 ~]# vim test.txt
hello tom
hello itbaizhan
hello gtjin
[root@node2 ~]# hdfs dfs -put test.txt /usr/root
put: `/usr/root': No such file or directory: `hdfs://node1:9820/usr/root'#路径写错了。
#上传文件时需要指定存在的路径
[root@node2 ~]# hdfs dfs -put test.txt /user/root
#再次查看指定目录下的文件列表
[root@node2 ~]# hdfs dfs -ls /user/root
Found 2 items
-rw-r--r-- 2 root supergroup 338075860 2021-10-09 11:11 /user/root/hadoop-3.1.3.tar.gz
-rw-r--r-- 2 root supergroup 38 2021-10-09 11:12 /user/root/test.txt也可以通过浏览器进行查看:http://192.168.20.101:9870/explorer.html#/user/root  删除文件或目录[root@node2 ~]# hdfs dfs -mkdir /test
[root@node2 ~]# hdfs dfs -put test.txt /test
[root@node2 ~]# hdfs dfs -rm /test
rm: `/test': Is a directory
[root@node2 ~]# hdfs dfs -rm /test/test.txt
Deleted /test/test.txt
[root@node2 ~]# hdfs dfs -put test.txt /test
[root@node2 ~]# hdfs dfs -rm -r /test
Deleted /test4.3.5 集群启动和停止总结HDFS各个角色一起停止[root@node1 ~]# stop-dfs.sh
#出现以下异常信息
Stopping namenodes on [node1]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Stopping datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Stopping secondary namenodes [node2]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
#解决办法:修改stop-dfs.sh文件,添加以下内容
[root@node1 ~]# vim /opt/hadoop-3.1.3/sbin/stop-dfs.sh
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 再次执行停止操作
[root@node1 ~]# stop-dfs.sh
Stopping namenodes on [node1]
上一次登录:六 10月 9 10:50:25 CST 2021pts/0 上
Stopping datanodes
上一次登录:六 10月 9 11:38:02 CST 2021pts/0 上
Stopping secondary namenodes [node2]
上一次登录:六 10月 9 11:38:03 CST 2021pts/0 上单独启动某角色进程hdfs --daemon start namenode/secondarynamenode/datanode#在node1上启动namenode
[root@node1 ~]# hdfs --daemon start namenode
[root@node1 ~]# jps
7235 NameNode
7304 Jps
#在node2上启动2nn和dn
[root@node2 ~]# hdfs --daemon start secondarynamenode
[root@node2 ~]# hdfs --daemon start datanode
[root@node2 ~]# jps
6672 DataNode
6629 SecondaryNameNode
#在node3和node4上分别启动DataNode
[root@node3 ~]# hdfs --daemon start datanode
[root@node3 ~]# jps
6034 Jps
5962 DataNode
[root@node4 ~]# hdfs --daemon start datanode
[root@node4 ~]# jps
6009 DataNode
6078 Jps单独关闭某角色进程hdfs --daemon stop namenode/secondarynamenode/datanode[root@node4 ~]# hdfs --daemon stop datanode
[root@node4 ~]# jps
6251 Jps
[root@node3 ~]# hdfs --daemon stop datanode
[root@node3 ~]# jps
6247 Jps
[root@node2 ~]# hdfs --daemon stop datanode
[root@node2 ~]# hdfs --daemon stop secondarynamenode
[root@node2 ~]# jps
7327 Jps
[root@node1 ~]# hdfs --daemon stop namenode
[root@node1 ~]# jps
7710 JpsHDFS各个角色一起启动[root@node1 ~]# start-dfs.sh
Starting namenodes on [node1]
上一次登录:六 10月 9 11:38:06 CST 2021pts/0 上
Starting datanodes
上一次登录:六 10月 9 11:48:18 CST 2021pts/0 上
Starting secondary namenodes [node2]
上一次登录:六 10月 9 11:48:20 CST 2021pts/0 上五、HDFS角色分析5.1 NameNode5.1.1 NameNode 分析 文件和目录的元数据:(运行时,元数据放内存) 文件的block副本个数 修改和访问的时间 访问权限 block大小以及组成文件的block信息列表 以两种方式在NameNode本地进行持久化: 命名空间镜像文件(fsimage)和编辑日志(edits log)。 删除文件或目录[root@node2 ~]# hdfs dfs -mkdir /test
[root@node2 ~]# hdfs dfs -put test.txt /test
[root@node2 ~]# hdfs dfs -rm /test
rm: `/test': Is a directory
[root@node2 ~]# hdfs dfs -rm /test/test.txt
Deleted /test/test.txt
[root@node2 ~]# hdfs dfs -put test.txt /test
[root@node2 ~]# hdfs dfs -rm -r /test
Deleted /test4.3.5 集群启动和停止总结HDFS各个角色一起停止[root@node1 ~]# stop-dfs.sh
#出现以下异常信息
Stopping namenodes on [node1]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Stopping datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Stopping secondary namenodes [node2]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
#解决办法:修改stop-dfs.sh文件,添加以下内容
[root@node1 ~]# vim /opt/hadoop-3.1.3/sbin/stop-dfs.sh
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 再次执行停止操作
[root@node1 ~]# stop-dfs.sh
Stopping namenodes on [node1]
上一次登录:六 10月 9 10:50:25 CST 2021pts/0 上
Stopping datanodes
上一次登录:六 10月 9 11:38:02 CST 2021pts/0 上
Stopping secondary namenodes [node2]
上一次登录:六 10月 9 11:38:03 CST 2021pts/0 上单独启动某角色进程hdfs --daemon start namenode/secondarynamenode/datanode#在node1上启动namenode
[root@node1 ~]# hdfs --daemon start namenode
[root@node1 ~]# jps
7235 NameNode
7304 Jps
#在node2上启动2nn和dn
[root@node2 ~]# hdfs --daemon start secondarynamenode
[root@node2 ~]# hdfs --daemon start datanode
[root@node2 ~]# jps
6672 DataNode
6629 SecondaryNameNode
#在node3和node4上分别启动DataNode
[root@node3 ~]# hdfs --daemon start datanode
[root@node3 ~]# jps
6034 Jps
5962 DataNode
[root@node4 ~]# hdfs --daemon start datanode
[root@node4 ~]# jps
6009 DataNode
6078 Jps单独关闭某角色进程hdfs --daemon stop namenode/secondarynamenode/datanode[root@node4 ~]# hdfs --daemon stop datanode
[root@node4 ~]# jps
6251 Jps
[root@node3 ~]# hdfs --daemon stop datanode
[root@node3 ~]# jps
6247 Jps
[root@node2 ~]# hdfs --daemon stop datanode
[root@node2 ~]# hdfs --daemon stop secondarynamenode
[root@node2 ~]# jps
7327 Jps
[root@node1 ~]# hdfs --daemon stop namenode
[root@node1 ~]# jps
7710 JpsHDFS各个角色一起启动[root@node1 ~]# start-dfs.sh
Starting namenodes on [node1]
上一次登录:六 10月 9 11:38:06 CST 2021pts/0 上
Starting datanodes
上一次登录:六 10月 9 11:48:18 CST 2021pts/0 上
Starting secondary namenodes [node2]
上一次登录:六 10月 9 11:48:20 CST 2021pts/0 上五、HDFS角色分析5.1 NameNode5.1.1 NameNode 分析 文件和目录的元数据:(运行时,元数据放内存) 文件的block副本个数 修改和访问的时间 访问权限 block大小以及组成文件的block信息列表 以两种方式在NameNode本地进行持久化: 命名空间镜像文件(fsimage)和编辑日志(edits log)。 fsimage文件不记录每个block所在的DataNode信息,这些信息在每次系统启动的时候从DataNode重建。之后DataNode会周期性地通过心跳包向NameNode报告block信息。DataNode向NameNode注册的时候NameNode请求DataNode发送block列表信息。 1、文件名称和路径 2、文件的大小 3、文件的所属关系 4、文件的block块大小128MB 5、文件的副本个数3MR10个副本 6、文件的修改时间 7、文件的访问时间 8、文件的权限 9、文件的block列表 存储结构 一个运行的NameNode如下的目录结构,该目录结构在第一次格式化的时候创建 如果属性dfs.namenode.name.dir指定了多个路径,则每个路径中的内容是一样的,尤其是当其中一个是挂载的NFS的时候,这种机制为管理提供了一些弹性。备份数据 in_use.lock文件用于NameNode锁定存储目录。这样就防止其他同时运行的NameNode实例使用相同的存储目录。 [root@node1 name]# pwd /var/itbaizhan/hadoop/full/dfs/name [root@node1 name]# ll 总用量 8 drwxr-xr-x 2 root root 4096 10月 9 15:49 current -rw-r--r-- 1 root root 10 10月 9 11:48 in_use.lock [root@node1 name]# cat in_use.lock 7939@node1 [root@node1 name]# jps 7939 NameNode 22536 Jps edits表示edits log日志文件 fsimage表示文件系统元数据镜像文件 NameNode在checkpoint之前首先要切换新的edits log文件,在切换时更新seen_txid的值。上次合并fsimage和editslog之后的第一个操作编号 [root@node1 current]# ll 总用量 3124 -rw-r--r-- 1 root root 42 10月 9 15:49 edits_0000000000000000050-0000000000000000051 -rw-r--r-- 1 root root 1048576 10月 9 15:49 edits_inprogress_0000000000000000052 -rw-r--r-- 1 root root 722 10月 9 14:49 fsimage_0000000000000000049 -rw-r--r-- 1 root root 62 10月 9 14:49 fsimage_0000000000000000049.md5 -rw-r--r-- 1 root root 722 10月 9 15:49 fsimage_0000000000000000051 -rw-r--r-- 1 root root 62 10月 9 15:49 fsimage_0000000000000000051.md5 -rw-r--r-- 1 root root 3 10月 9 15:49 seen_txid -rw-r--r-- 1 root root 219 10月 9 10:42 VERSION [root@node1 current]# cat seen_txid 52VERSION文件 [root@node1 current]# cat VERSION #Sat Oct 09 10:42:49 CST 2021 namespaceID=1536048782 clusterID=CID-7ecb999c-ef5a-4396-bdc7-c9a741a797c4 cTime=1633747369798 storageType=NAME_NODE blockpoolID=BP-1438277808-192.168.20.101-1633747369798 layoutVersion=-64namespaceID是该文件系统的唯一标志符,当NameNode第一次格式化的时候生成。 clusterID是HDFS集群使用的一个唯一标志符,在HDFS联邦的情况下,就看出它的作用了,因为联邦情况下,集群有多个命名空间,不同的命名空间由不同的NameNode管理。 cTime标记着当前NameNode创建的时间。对于刚格式化的存储,该值永远是0,但是当文件系统更新的时候,这个值就会更新为一个时间戳。 storageType表示当前目录存储NameNode内容。 blockpoolID是block池的唯一标志符,一个NameNode管理一个命名空间,该命名空间中的所有文件存储的block都在block池中。 layoutVersion是一个负数,定义了HDFS持久化数据结构的版本。这个版本数字跟hadoop发行的版本无关。当layout改变的时候,该数字减1(比如从--63到-64)。当对HDFS进行了升级,就会发生改变。 5.1.2 Fsimage和Edits log文件分析查看oiv和oev命令 [root@node1 ~]# hdfs|grep o.v oev apply the offline edits viewer to an edits file oiv apply the offline fsimage viewer to an fsimageoiv查看Fsimage文件(1)查看oiv命令 [root@node1 ~]# hdfs oiv --help Usage: bin/hdfs oiv [OPTIONS] -i INPUTFILE -o OUTPUTFILE Offline Image Viewer View a Hadoop fsimage INPUTFILE using the specified PROCESSOR, saving the results in OUTPUTFILE. -i,--inputFile FSImage or XML file to process. Optional command line arguments: -o,--outputFile Name of output file. If the specified file exists, it will be overwritten. (output to stdout by default) If the input file was an XML file, we will also create an .md5 file. -p,--processor Select which type of processor to apply against image file. (XML|FileDistribution| ReverseXML|Web|Delimited) The default is Web.(2)基本语法 hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出的全路径名 (3)案例实操 [root@node1 current]# pwd /var/itbaizhan/hadoop/full/dfs/name/current [root@node1 current]# ll|grep fsimage -rw-r--r-- 1 root root 722 10月 9 13:49 fsimage_0000000000000000047 -rw-r--r-- 1 root root 62 10月 9 13:49 fsimage_0000000000000000047.md5 -rw-r--r-- 1 root root 722 10月 9 14:49 fsimage_0000000000000000049 -rw-r--r-- 1 root root 62 10月 9 14:49 fsimage_0000000000000000049.md5 [root@node1 current]# hdfs oiv -p XML -i fsimage_0000000000000000049 -o /opt/hadoop-3.1.3/fsimage49.xml 2021-10-09 15:20:24,428 INFO offlineImageViewer.FSImageHandler: Loading 3 strings [root@node1 current]# vim /opt/hadoop-3.1.3/fsimage49.xml #格式化该xml文件:Ctrl+v-> !xmllint -format - -> 删除生成的 ->保存并退出 [root@node1 current]# cat /opt/hadoop-3.1.3/fsimage49.xml部分显示结果如下: 16392 5 16385 DIRECTORY 1633749749273 root:supergroup:0755 9223372036854775807 -1 16386 DIRECTORY user 1633748876034 root:supergroup:0755 -1 -1 16387 DIRECTORY root 1633749176246 root:supergroup:0755 -1 -1 16388 FILE hadoop-3.1.3.tar.gz 2 1633749066652 1633749010986 134217728 root:supergroup:0644 1073741825 1001 134217728 1073741826 1002 134217728 1073741827 1003 69640404 0 16389 FILE test.txt 2 1633749176236 1633749175593 134217728 root:supergroup:0644 1073741828 1004 38 0 ......思考:观察发现Fsimage中没有记录块所对应DataNode,为什么? 在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。 oev查看Edits log文件 (1)查看oiv命令 ```sh [root@node1 current]# hdfs oev --help Usage: bin/hdfs oev [OPTIONS] -i INPUT_FILE -o OUTPUT_FILE Offline edits viewer Parse a Hadoop edits log file INPUT_FILE and save results in OUTPUT_FILE. Required command line arguments: -i,--inputFile edits file to process, xml (case insensitive) extension means XML format, any other filename means binary format. XML/Binary format input file is not allowed to be processed by the same type processor. -o,--outputFile Name of output file. If the specified file exists, it will be overwritten, format of the file is determined by -p option Optional command line arguments: -p,--processor Select which type of processor to apply against image file, currently supported processors are: binary (native binary format that Hadoop uses), xml (default, XML format), stats (prints statistics about edits file) ``` (2)基本语法 hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径 (3)案例实操[root@node1 current]# ll|grep edits -rw-r--r-- 1 root root 515 10月 9 11:10 edits_0000000000000000001-0000000000000000008 -rw-r--r-- 1 root root 1048576 10月 9 11:22 edits_0000000000000000009-0000000000000000038 -rw-r--r-- 1 root root 42 10月 9 11:42 edits_0000000000000000039-0000000000000000040 -rw-r--r-- 1 root root 1048576 10月 9 11:42 edits_0000000000000000041-0000000000000000041 -rw-r--r-- 1 root root 42 10月 9 11:49 edits_0000000000000000042-0000000000000000043 -rw-r--r-- 1 root root 42 10月 9 12:49 edits_0000000000000000044-0000000000000000045 -rw-r--r-- 1 root root 42 10月 9 13:49 edits_0000000000000000046-0000000000000000047 -rw-r--r-- 1 root root 42 10月 9 14:49 edits_0000000000000000048-0000000000000000049 -rw-r--r-- 1 root root 1048576 10月 9 14:49 edits_inprogress_0000000000000000050 [root@node1 current]# hdfs oev -p XML -i edits_0000000000000000001-0000000000000000008 -o /opt/hadoop-3.1.3/editslog18.xml [root@node1 current]# cat /opt/hadoop-3.1.3/editslog18.xml显示结果如下: -64 OP_START_LOG_SEGMENT 1 OP_MKDIR 2 0 16386 /user 1633748876031 root supergroup 493 OP_MKDIR 3 0 16387 /user/root 1633748876034 root supergroup 493 OP_ADD 4 0 16388 /user/root/hadoop-3.1.3.tar.gz._COPYING_ 2 1633749010986 1633749010986 134217728 DFSClient_NONMAPREDUCE_1752542758_1 192.168.20.101 true root supergroup 420 0 d021df05-6937-4fc7-9474-ffcbf27f0f14 3 OP_ALLOCATE_BLOCK_ID 5 1073741825 OP_SET_GENSTAMP_V2 6 1001 OP_ADD_BLOCK 7 /user/root/hadoop-3.1.3.tar.gz._COPYING_ 1073741825 0 1001 -2 OP_END_LOG_SEGMENT 8 当文件系统客户端进行了写操作(例如创建或移动了文件),这个事务首先在edits log中记录下来。NameNode在内存中有文件系统的元数据,当edits log记录结束后,就更新内存中的元数据。内存中的元数据用于响应客户端的读请求。 edits log在磁盘上表现为一定数量的文件。每个文件称为片段(Segment),前缀“edits”,后缀是其中包含的事务ID(transaction IDs)。每个写操作事务都仅仅打开一个文件(比如:edits_inprogress_00000000000010),写完后冲刷缓冲区并同步到磁盘,然后返回客户端success状态码。如果NameNode的元数据需要写到多个目录中,则对于每个写事务需要所有的写操作都完成,并冲刷缓冲区同步到磁盘才返回success状态码。这样就可以保证在发生宕机的时候没有事务数据丢失。 用户的操作是一个事务,每个操作NN都要先将操作记录到edits log中,如果给NN指定了多个目录,则在多个目录中都存在edits log文件,用户的操作要在多个目录中都写完成,才让NN同步数据到内存中。当NN在内存中也同步了数据,就返回客户端success。 每个fsimage文件都是系统元数据的一个完整的持久化检查点(checkpoint)(后缀表示镜像中的最后一个事务)。写操作不更新这个数据,因为镜像文件通常为GB数量级,写到磁盘很慢。如果NameNode宕机,可以将最新fsimage加载到内存,同时执行edits log对应于该fsimage之后的操作,就可以重建元数据的状态。而这正是每次启动NameNode的时候NameNode要做的工作。 5.2 SecondaryNameNode存在的意义 edits log会随着对文件系统的操作而无限制地增长,这对正在运行的NameNode而言没有任何影响,如果NameNode重启,则需要很长的时间执行edits log的记录以更新fsimage(元数据镜像文件)。在此期间,整个系统不可用。定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits log的合并。 SecondaryNameNode要和NameNode拥有相同的内存。对大的集群,SecondaryNameNode运行于一台专用的物理主机。 存储结构 [root@node1 name]# pwd /var/itbaizhan/hadoop/full/dfs/name |-current | |-edits_0000000000000000001-0000000000000000008 | |-edits_0000000000000000009-0000000000000000038 | |-edits_0000000000000000039-0000000000000000040 | |-edits_0000000000000000041-0000000000000000041 | |-edits_0000000000000000042-0000000000000000043 | |-edits_0000000000000000044-0000000000000000045 | |-edits_0000000000000000046-0000000000000000047 | |-edits_0000000000000000048-0000000000000000049 | |-edits_0000000000000000050-0000000000000000051 | |-edits_0000000000000000052-0000000000000000053 | |-edits_0000000000000000054-0000000000000000054 | |-edits_0000000000000000055-0000000000000000056 | |-fsimage_0000000000000000054 | |-fsimage_0000000000000000054.md5 | |-fsimage_0000000000000000056 | |-fsimage_0000000000000000056.md5 | |-edits_inprogress_0000000000000000057 | |-seen_txid #57 | |-VERSION |-in_use.lock [root@node2 namesecondary]# pwd /var/itbaizhan/hadoop/full/dfs/namesecondary |-current | |-edits_0000000000000000001-0000000000000000008 | |-edits_0000000000000000009-0000000000000000038 | |-edits_0000000000000000039-0000000000000000040 | |-edits_0000000000000000041-0000000000000000041 | |-edits_0000000000000000042-0000000000000000043 | |-edits_0000000000000000044-0000000000000000045 | |-edits_0000000000000000046-0000000000000000047 | |-edits_0000000000000000048-0000000000000000049 | |-edits_0000000000000000050-0000000000000000051 | |-edits_0000000000000000052-0000000000000000053 | |-edits_0000000000000000055-0000000000000000056 | |-fsimage_0000000000000000054 | |-fsimage_0000000000000000054.md5 | |-fsimage_0000000000000000056 | |-fsimage_0000000000000000056.md5 | |-VERSION |-in_use.lock1、SecondaryNameNode中checkpoint目录布局(dfs.namenode.checkpoint.dir)和NameNode中的基本一样。 2、如果NameNode完全坏掉,可以快速地从SecondaryNameNode恢复。有可能丢数据 3、如果SecondaryNameNode直接接手NameNode的工作,需要在启动NameNode进程的时候添加-importCheckpoint选项。该选项会让NameNode从由dfs.namenode.checkpoint.dir属性定义的路径中加载最新的checkpoint数据,但是为了防止元数据的覆盖,要求dfs.namenode.name.dir定义的目录中没有内容。 工作流程  edits_inprogress_00000000001_0000000019 seen_txid=20 1、secondarynamenode请求namenode生成新的edits log文件(edits_inprogress_...)并向其中写日志。NameNode会在所有的存储目录中更新seen_txid文件 2、SecondaryNameNode通过HTTP GET的方式从NameNode下载fsimage和edits文件到本地。 3、SecondaryNameNode将fsimage加载到自己的内存,并根据edits log更新内存中的fsimage信息,然后将更新完毕之后的fsimage写到磁盘上。 4、SecondaryNameNode通过HTTP PUT将新的fsimage文件发送到NameNode,NameNode将该文件保存为.ckpt的临时文件备用。 5、NameNode重命名该临时文件并准备使用。此时NameNode拥有一个新的fsimage文件和一个新的很小的edits log文件(可能不是空的,因为在SecondaryNameNode合并期间可能对元数据进行了读写操作)。管理员也可以将NameNode置于safemode,通过hdfs dfsadmin -saveNamespace命令来进行edits log和fsimage的合并。 检查点创建时机:对于创建检查点(checkpoint)的过程,有三个参数进行配置: dfs.namenode.checkpoint.period 3600s dfs.namenode.checkpoint.txns 1000000 操作动作次数 dfs.namenode.checkpoint.check.period 60s 1分钟检查一次操作次数合并条件总结:1、每小时一次,2、不足一小时,则只要edits log中记录的事务数达到了1000000,则合并。 hdfs-default.xml,如果想修改这几个参数的话,直接在hdfs-site.xml中进行配置即可。 5.3 NameNode故障处理(扩展)NameNode故障后,可以采用如下两种方法恢复数据。 1)将SecondaryNameNode中数据拷贝到NameNode存储数据的目录; (1)kill -9 NameNode进程id(可以通过jps查看nodename进程的id) (2)删除NameNode存储的数据 [root@node1 hadoop-3.1.3]# rm -rf /var/itbaizhan/hadoop/full/dfs/name/*(3)拷贝SecondaryNameNode中数据到原NameNode存储数据目录 [root@node1 dfs]# scp -r root@node2:/var/itbaizhan/hadoop/full/dfs/namesecondary/* ./name/(4)重新启动NameNode [root@node1 hadoop-3.1.3]# hdfs --daemon start namenode2)使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。 (1)修改hdfs-site.xml中的 dfs.namenode.checkpoint.period 120 dfs.namenode.name.dir /var/itbaizhan/hadoop/full/dfs/name(2)kill -9 NameNode进程id (3)删除NameNode存储的数据(/var/itbaizhan/hadoop/full/dfs/name) [root@node1 ~]# rm -rf /var/itbaizhan/hadoop/full/dfs/name/*(4)如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件 [root@node1 dfs]# scp -r root@node2:/var/itbaizhan/hadoop/full/dfs/namesecondary ./ [root@node1 namesecondary]# rm -rf in_use.lock [root@node1 dfs]# pwd /var/itbaizhan/hadoop/full/dfs [root@node1 dfs]# ls data name namesecondary(5)导入检查点数据(等待一会ctrl+c结束掉) [root@node1 dfs]# hdfs namenode -importCheckpoint(6)启动NameNode [root@node1 dfs]# hdfs --daemon start namenode5.4 NameNode多目录配置(了解)1.NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性 2.具体配置如下: (1)停止集群,在四台节点的hdfs-site.xml文件中添加如下内容 dfs.namenode.name.dir file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2(2)删除四台节点的/var/itbaizhan/hadoop/full和/opt/hadoop-3.1.3/logs中所有数据。 [root@node1 ~]# rm -rf /var/itbaizhan/hadoop/full/ /opt/hadoop-3.1.3/logs/ [root@node2 ~]# rm -rf /var/itbaizhan/hadoop/full/ /opt/hadoop-3.1.3/logs/ [root@node3 ~]# rm -rf /var/itbaizhan/hadoop/full/ /opt/hadoop-3.1.3/logs/ [root@node4 ~]# rm -rf /var/itbaizhan/hadoop/full/ /opt/hadoop-3.1.3/logs/(3)格式化集群并启动。 [root@node1 ~]# hdfs namenode –format [root@node1 ~]# start-dfs.sh(4)查看结果 [root@node1 ~]# cd /var/itbaizhan/hadoop/full/dfs [root@node1 dfs]# ll 总用量 12 drwxrwxr-x. 3 root root 4096 10月 10 16:34 name1 drwxrwxr-x. 3 root root 4096 10月 10 16:34 name25.5 DataNode1.工作机制  一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。集群运行中可以安全加入和退出一些机器。 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。集群运行中可以安全加入和退出一些机器。2.存储结构 DataNode不需要显式地格式化;关键文件和目录结构如下:  1、HDFS块数据存储于blk_前缀的文件中,包含了被存储文件原始字节数据的一部分。 2、每个block文件都有一个.meta后缀的元数据文件关联。该文件包含了一个版本和类型信息的头部,后接该block中每个部分的校验和。 3、每个block属于一个block池,每个block池有自己的存储目录,该目录名称就是该池子的ID(跟NameNode的VERSION文件中记录的block池ID一样)。 当一个目录中的block达到64个(通过dfs.datanode.numblocks配置)的时候,DataNode会创建一个新的子目录来存放新的block和它们的元数据。这样即使当系统中有大量的block的时候,目录树也不会太深。同时也保证了在每个目录中文件的数量是可管理的,避免了多数操作系统都会碰到的单个目录中的文件个数限制(几十几百上千个)。 如果dfs.datanode.data.dir指定了位于在不同的硬盘驱动器上的多个不同的目录,则会通过轮询的方式向目录中写block数据。需要注意的是block的副本不会在同一个DataNode上复制,而是在不同的DataNode节点之间复制。 3.存储数据模型(重点)  1、文件线性切割成块(Block)(按字节切割) [root@node1 ~]# for i in `seq 100000`; do echo "hello gtjin $i" >> hello.txt; done [root@node1 ~]# cat hello.txt hello gtjin1 ..... hello gtjin100 ......2、Block分散存储在集群节点中 3、单一文件Block大小一致,文件与文件可以不一致 hdfs dfs -D dfs.blocksize=1048576 -D dfs.replication=2 -put hello.txt /4、Block可以设置副本数,副本分散在不同节点中 a) 副本数不要超过DataNode节点数量 b) 承担计算 c) 容错 5、文件上传可以设置Block大小和副本数 6、已上传的文件Block副本数可以调整,大小不变 7、只支持一次写入多次读取;对同一个文件,一个时刻只有一个写入者 8、可以append追加数据 4.优势(了解) 一个文件的大小可以大于网络中任意一个节点的磁盘容量 使用抽象块而非整个文件作为存储单元,大大简化存储子系统的设计 块非常适合用于数据备份进而提供数据容错能力和提高可用性 5.6 权限(了解)1、每个文件和目录都和一个拥有者和组相关联。 2、文件或者目录对与拥有者、同组用户和其他用户拥有独立的权限。 3、对于一个文件,r表示读取的权限,w表示写或者追加的权限。对于目录而言,r表示列出目录内容的权限,w表示创建或者删除文件和目录的权限,x表示访问该目录子项目的权限。 4、默认情况下hadoop运行时安全措施处于停用模式(hadoop2.6.5),启用模式3.1.3。一个客户端可以在远程系统上通过创建和任意一个合法用户同名的账号来进行访问。 5、安全措施可以防止用户或自动工具及程序意外修改或删除文件系统的重要部分。(dfs.permissions.enabled属性) 6、超级用户是namenode进程的标识。对于超级用户,系统不会执行任何权限检查。 六、Hadoop集群的安全模式6.1 工作流程(理解) 启动NameNode,NameNode加载fsimage到内存,对内存数据执行edits log日志中的事务操作。 文件系统元数据内存镜像加载完毕,进行fsimage和edits log日志的合并,并创建新的fsimage文件和一个空的edits log日志文件。 NameNode等待DataNode上传block列表信息,直到副本数满足最小副本条件。最小副本条件指整个文件系统中有99.9%的block达到了最小副本数(默认值是1,可设置) 当满足了最小副本条件,再过30秒,NameNode就会退出安全模式。在NameNode安全模式(safemode) 对文件系统元数据进行只读操作 当文件的所有block信息具备的情况下,对文件进行只读操作 不允许进行文件修改(写,删除或重命名文件) 6.2 注意事项 NameNode不会持久化block位置信息;DataNode保有各自存储的block列表信息。正常操作时,NameNode在内存中有一个blocks位置的映射信息(所有文件的所有文件块的位置映射信息)。 NameNode在安全模式,NameNode需要给DataNode时间来上传block列表信息到NameNode。如果NameNode不等待DataNode上传这些信息的话,则会在DataNode之间进行block的复制,而这在大多数情况下都是非必须的(因为只需要等待DataNode上传就行了),还会造成资源浪费。 在安全模式NameNode不会要求DataNode复制或删除block。 新格式化的HDFS不进入安全模式,因为DataNode压根就没有block。 6.3 配置信息在hdfs-site.xml位置中进行配置。 属性名称类型默认值描述dfs.namenode.replication.minint1写文件成功的最小副本数dfs.namenode.safemode.threshold-pctfloat0.999系统中block达到了最小副本数的比例,之后NameNode会退出安全模式。小于等于0表示不进入安全模式,大于1表示永不退出安全模式dfs.namenode.safemode.extensionint ms30000当副本数达到最小副本条件之后安全模式延续的时间。对于小的集群(几十个节点),可以设置为06.4 命令操作(了解)通过命令查看namenode是否处于安全模式: [root@node1 ~]# hdfs dfsadmin -safemode get Safe mode is ONHDFS的前端webUI页面也可以查看NameNode是否处于安全模式。 有时候我们希望等待安全模式退出,之后进行文件的读写操作,尤其是在脚本中,此时: [root@node1 ~]# hdfs dfsadmin -safemode wait # your read or write command goes here管理员有权在任何时间让namenode进入或退出安全模式。进入安全模式: [root@node1 ~]# hdfs dfsadmin -safemode enter Safe mode is ON这样做可以让namenode一直处于安全模式,也可以设置dfs.namenode.safemode.threshold-pct为1做到这一点。 离开安全模式: [root@node1 ~]# hdfs dfsadmin -safemode leave Safe mode is OFF七、HDFS之JavaAPI7.1 准备Hadoop的Windows开发环境 将 "软件\Windows依赖\hadoop-3.1.0"目录拷贝到D:\devsoft目录下 把hadoop-3.1.0\bin目录下的 hadoop.dll 和 winutils.exe 放到系统盘的 C:\Windows\System32 下 配置HADOOP_USER_NAME此电脑->右键 属性-> 高级系统设置->环境变量->新建系统变量  4.配置HADOOP_HOME  5.将hadoop3.1.0的bin目录放Path中,然后重启电脑。  7.2 项目搭建创建一个Maven工程HdfsClientAPI,并导入相应的依赖坐标
junit
junit
4.13
org.apache.hadoop
hadoop-client
3.1.3
org.apache.logging.log4j
log4j-slf4j-impl
2.12.0
日志配置 7.2 项目搭建创建一个Maven工程HdfsClientAPI,并导入相应的依赖坐标
junit
junit
4.13
org.apache.hadoop
hadoop-client
3.1.3
org.apache.logging.log4j
log4j-slf4j-impl
2.12.0
日志配置在项目的src/main/resources目录下,新建一个文件,名为“log4j2.xml”,在文件中填入一下内容 创建类com.itbaizhan.hdfs.HdfsApiDemo7.3 创建目录/**创建目录的API演示 */ @Test public void mkdirs() throws IOException { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.指定NameNode configuration.set("fs.defaultFS","hdfs://node1:9820"); //3.创建文件系统对象 FileSystem fileSystem = FileSystem.get(configuration); //4.调用创建目录的API方法 //boolean result = fileSystem.mkdirs(new Path("/api/show")); //存在的问题时result不准确 //System.out.println(result?"目录创建成功!":"目录创建失败!"); fileSystem.mkdirs(new Path("/api/show")); //5.勿忘我:关闭文件系统对象 fileSystem.close(); } @Test public void mkdirs2() throws IOException, URISyntaxException, InterruptedException { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.创建文件系统对象,指定URI,conf,userName FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"), configuration,"itbaizhan"); //3.调用创建目录的API方法 fileSystem.mkdirs(new Path("/hdfsapi/show")); //4.勿忘我:关闭文件系统对象 fileSystem.close(); }用户使用itbaizhan,出现异常提示:org.apache.hadoop.security.AccessControlException: Permission denied: user=itbaizhan, access=WRITE, inode="/":root:supergroup:drwxr-xr-x。将之改为root即可。 7.4 上传文件准备工作: #在node1通过脚本生成一个文本文件hh.txt [root@node1 ~]# for i in `seq 100000`; do echo "hello itbaizhan $i" >> hh.txt; done # 安装lrzsz包 [root@node1 ~]# yum install lrzsz -y #将生产的文件下载到F: [root@node1 ~]# sz hh.txt方式一:编写Java基础代码(选学): @Test public void uploadFile() throws Exception { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.创建文件系统对象,指定URI,conf,userName FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"), configuration,"root"); //3.创建本地输入流对象 FileInputStream fileInputStream = new FileInputStream("F:\\hh.txt"); //4.创建HDFS文件系统的输出流对象 FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/api/show/hh.txt")); //5.创建字节数组,临时存储中间缓存数据 byte[] data = new byte[1024]; int len = -1; while((len = fileInputStream.read(data))!=-1){ fsDataOutputStream.write(data,0,len); } //6.关闭输入流对象 fileInputStream.close(); //7.刷新输出流中的数据 fsDataOutputStream.flush(); //8.关闭输出流 fsDataOutputStream.close(); //9.断开和HDFS之间的连接 fileSystem.close(); }方式二:调用HDFS高级API //使用HDFS高级API @Test public void copyFromLocalFile() throws Exception { //1.创建文件系统对象 Configuration configuration = new Configuration(); //2.设置block大小为1MB,上传时候使用,仅对当前方法有效 configuration.set("dfs.blocksize","1048576"); //3.设置副本数 //configuration.set("dfs.replication","2"); //4.创建文件系统对象 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"), configuration, "root"); //5.上传文件 fileSystem.copyFromLocalFile(new Path("F:\\hh.txt"),new Path("/api/show/hh3.txt")); //6.关闭资源 fileSystem.close(); System.out.println("上传操作完成。。。"); }参数优先级总结: 参考原则是“就近一致”(约近优先级约高) 客户端代码中的参数设置的值 > 自定义配置文件中的参数的值 > 服务器默认xxx-default.xml 7.5 文件改名和移动@Test public void rename() throws Exception { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.生成文件系统对象 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"), configuration, "root"); //3.修改名称:相同路径下 //fileSystem.rename(new Path("/api/show/hh.txt"),new Path("/api/show/hh_new.txt")); //3.移动文件:不同路径下 fileSystem.rename(new Path("/api/show/hh_new.txt"),new Path("/api/hh_new.txt")); //4.关闭 fileSystem.close(); }7.6 下载文件@Test public void copyToLocalFile() throws Exception { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.生成文件系统对象 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"),configuration,"root"); /**3.调用下载API方法 * delSrc – whether to delete the src 是否原文件,false不删除,true表示删除原文件 * src – path:被下载文件的全路径名对应的Path类的对象 * dst – path:文件下载到的目标全路径名对应的Path类的对象 * useRawLocalFileSystem – 是否开启文件校验. */ fileSystem.copyToLocalFile(false,new Path("/api/hh_new.txt"), new Path("F:/hh_new.txt"),true); //4.关闭资源 fileSystem.close(); }7.7 文件和目录的删除@Test public void delete() throws Exception { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.获取文件系统对象 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"),configuration,"root"); /**3.调用删除方法 *Path f :被删除的文件或目录对应的Path类的对象 *boolean recursive: * false: 删除目录如果是一个非空的目录,抛出以下异常: * PathIsNotEmptyDirectoryException: ``/api is non empty': Directory is not empty * 删除时一个文件,或一个空目录,则直接删除。 * true:表示递归删除子文件或目录 */ //fileSystem.delete(new Path("/api"),false); //fileSystem.delete(new Path("/api/hh_new.txt"),false); //fileSystem.delete(new Path("/api"),true); fileSystem.delete(new Path("/hdfsapi/show"),false); //4.关闭资源 fileSystem.close(); }7.8 获取指定文件的详情@Test public void getFileInfo() throws Exception { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.获取文件系统对象 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"),configuration,"root"); //3.获取指定文件的详细信息的对象 FileStatus fileStatus = fileSystem.getFileStatus(new Path("/hello.txt")); //4.从fileStatus获取文件的信息 System.out.println("文件名称:"+fileStatus.getPath().getName()); System.out.println("文件所有者:"+fileStatus.getOwner()); System.out.println("文件所属用户组:"+fileStatus.getGroup()); System.out.println("文件块的大小:"+fileStatus.getBlockSize()); System.out.println("文件总大小:"+fileStatus.getLen()); System.out.println("文件的权限:"+fileStatus.getPermission()); System.out.println("副本数量:"+fileStatus.getReplication()); //5.关闭资源 fileSystem.close(); }运行后的结果如下: 文件名称:hello.txt 文件所有者:root 文件所属用户组:supergroup 文件块的大小:1048576 文件总大小:1788895 文件的权限:rw-r--r-- 副本数量:27.9 文件和目录的判断@Test public void fileOrDir() throws Exception { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.获取文件系统对象 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"),configuration,"root"); //3.获取指定目录下的子文件或子目录的信息 FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/")); //4.遍历数组 for(FileStatus fileStatus:fileStatuses){ if(fileStatus.isFile()){ System.out.println(fileStatus.getPath().getName()+" is file"); }else if(fileStatus.isDirectory()){ System.out.println(fileStatus.getPath().getName()+" is directory"); }else{ System.out.println(fileStatus.getPath().getName()+" is other.."); } } //5.关闭资源 fileSystem.close(); }运行程序结果如下: hdfsapi is directory hello.txt is file user is directory7.10 获取指定目录下文件详细@Test public void listFiles() throws Exception { //1.创建配置文件对象 Configuration configuration = new Configuration(); //2.获取文件系统对象 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9820"),configuration,"root"); /**3.获取指定目录下文件列表信息 *Path f:指定目录对应的Path类的对象 *boolean recursive: * true表示迭代“后代级别的文件“ * false表示仅仅获取指定目录下的文件 */ RemoteIterator listFiles = fileSystem.listFiles(new Path("/user"), true); //4.遍历迭代器 while(listFiles.hasNext()){ LocatedFileStatus fileStatus = listFiles.next(); System.out.println("文件名称:"+fileStatus.getPath().getName()); System.out.println("文件的长度:"+fileStatus.getLen()); System.out.println("文件所属用户:"+fileStatus.getOwner()); System.out.println("文件所属的用户组:"+fileStatus.getGroup()); System.out.println("文件的权限:"+fileStatus.getPermission()); //5.获取文件块s信息 //BlockLocation[] blockLocations = fileSystem.getFileBlockLocations(fileStatus, 0, fileStatus.getLen()); BlockLocation[] blockLocations = fileStatus.getBlockLocations(); //6.遍历文件块 for(BlockLocation blockLocation:blockLocations){ //获取 System.out.println("偏移量:"+blockLocation.getOffset()); String[] hosts = blockLocation.getHosts(); System.out.println("=============host start print=========="); for(String host:hosts){ System.out.println(host); } System.out.println("=============host end print=========="); String[] names = blockLocation.getNames(); System.out.println("names:"+names.toString()); } System.out.println("===================================="); } }八、读写流程(重点)8.1 HDFS写文件流程(重点)8.1.1 写文件流程剖析 三大角色:HDFS client、NameNode、DataNode。写文件过程中涉及到这三个角色之间联动。 调用客户端的对象DistributedFileSystem的create方法:create(new Path("/user/hh.txt")); DistributedFileSystem会发起对namenode的一个RPC连接,请求创建一个文件,不包含关于block块的请求。namenode会执行各种各样的检查,判断客户端是否拥有有创建文件的权限,如果检查通过,namenode会创建一个文件(在edits中,同时更新内存状态),否则创建失败,客户端抛异常IOException,流程结束。hadoop2.x版本中如果指定的文件在对应的路径下已经存在,则创建失败;不存在则创建成功。hadoop3.1.3版本中如果指定的文件在对应的路径下已经存在,则覆盖。 NN在文件(空文件)创建后,返回给HDFSClient可以开始上传文件块。 java FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/user/hh.txt")); DistributedFileSystem返回一个FSDataOutputStream对象给客户端用于写数据。FSDataOutputStream封装了一个DFSOutputStream对象负责客户端跟datanode以及namenode的通信。 DFSOutputStream对象向NameNode请求上传文件块(比如:0-128M),让NN返回DataNode节点列表。 NN根据网络距离的远近和资源的使用情况来选择DN节点,并返回最适合的“三个”节点。 DFSOutputStream对象收到DN列表后,按照一定规则请求建立一个通道DN1->DN2->DN3 DN开启应答DN3->DN2->DN1->DFSOutputStream对象,至此双工通道建立完成。 DFSOutputStream对象将数据切分为小的数据包(64kb,core-default.xml:file.client-write-packet-size默认值65536),并写入到一个内部队列(“数据队列”)。DataStreamer会读取其中内容,DataStreamer将数据包发送给管线中的DN1,DN1将接收到的数据发送给DN2,DN2发送给DN3 DFSOoutputStream维护着一个数据包的队列,这的数据包是需要写入到datanode中的,该队列称为确认队列。当一个数据包在管线中所有datanode中写入完成,就从ack队列中移除该数据包。 如果在数据写入期间datanode发生故障,则执行以下操作: a) 关闭管线,把确认队列中的所有包都添加回数据队列的最前端,以保证故障节点下游的datanode不会漏掉任何一个数据包。 b) 为存储在另一正常datanode的当前数据块指定一个新的标志,并将该标志传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块。 c) 从管线中删除故障数据节点并且把余下的数据块写入管线中另外两个正常的datanode。namenode在检测到副本数量不足时,会在另一个节点上创建新的副本。 d) 后续的数据块继续正常接受处理。 e) 在一个块被写入期间可能会有多个datanode同时发生故障,但非常少见。只要设置了dfs.replication.min的副本数(默认为1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标副本数(dfs.replication默认值为3)。 如果有多个block,则会反复从步骤3开始执行。 当客户端完成了所有的数据块的传输,调用数据流的close方法。该方法将数据队列中的剩余数据包写到DN的管线并等待管线的确认 客户端收到管线中所有正常DN的确认消息后,通知NN文件写完了。 namenode已经知道文件由哪些块组成,所以它在返回成功前只需要等待数据块进行最小量的复制。 8.1.2 节点距离的计算(理解) 如果在数据写入期间datanode发生故障,则执行以下操作: a) 关闭管线,把确认队列中的所有包都添加回数据队列的最前端,以保证故障节点下游的datanode不会漏掉任何一个数据包。 b) 为存储在另一正常datanode的当前数据块指定一个新的标志,并将该标志传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块。 c) 从管线中删除故障数据节点并且把余下的数据块写入管线中另外两个正常的datanode。namenode在检测到副本数量不足时,会在另一个节点上创建新的副本。 d) 后续的数据块继续正常接受处理。 e) 在一个块被写入期间可能会有多个datanode同时发生故障,但非常少见。只要设置了dfs.replication.min的副本数(默认为1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标副本数(dfs.replication默认值为3)。 如果有多个block,则会反复从步骤3开始执行。 当客户端完成了所有的数据块的传输,调用数据流的close方法。该方法将数据队列中的剩余数据包写到DN的管线并等待管线的确认 客户端收到管线中所有正常DN的确认消息后,通知NN文件写完了。 namenode已经知道文件由哪些块组成,所以它在返回成功前只需要等待数据块进行最小量的复制。 8.1.2 节点距离的计算(理解)在HDFS写数据的过程中,NameNode会选择距离HDFS Client最近的DataNode节点接收数据。那么这个最近距离如何计算? 节点距离:两个节点到达最近的共同父节点的距离和。  hadoop把网络看作是一棵树,两个节点间的距离是它们到最近共同祖先的距离和。通常可以设置等级: 同一个节点上的进程 同一机架上的不同节点 同一数据中心中不同机架上的节点 不同数据中心中的节点 8.1.3 数据块副本放置策略  Block的副本放置策略 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。 第二个副本:放置在于第一个副本不同的 机架的节点上。 第三个副本:与第二个副本相同机架的不同节点。 更多副本:随机节点 8.2 HDFS读文件流程(重点) 三大角色:HDFS Client、NameNode、DataNode。 客户端通过FileSystem对象的open方法打开希望下载的文件,DistributedFileSystem对象通过RPC调用namenode,以确保文件起始位置。对于每个block,namenode返回存有该副本的datanode地址。这些datanode根据它们与客户端的距离来排序。如果客户端本身就是一个datanode,并保存有相应block一个副本,会从本地读取这个block数据。 DistributedFileSystem返回一个FSDataInputStream对象给客户端读取数据。该类封装了DFSInputStream对象,该对象管理着datanode和namenode的I/O,用于给客户端使用。客户端对这个输入调用read方法,存储着文件起始几个block的datanode地址的DFSInputStream连接距离最近的datanode。通过对数据流反复调用read方法,可以将数据从datnaode传输到客户端。到达block的末端时,DFSInputSream关闭与该datanode的连接,然后寻找下一个block的最佳datanode。客户端只需要读取连续的流,并且对于客户端都是透明的。 客户端从流中读取数据时,block是按照打开DFSInputStream与datanode新建连接的顺序读取的。它也会根据需要询问namenode来检索下一批数据块的datanode的位置。一旦客户端完成读取,就close掉FSDataInputStream的输入流。 在读取数据的时候如果DFSInputStream在与datanode通信时遇到错误,会尝试从这个块的一个最近邻datanode读取数据。它也记住那个故障datanode,保证以后不会反复读取该节点上后续的block。DFSInputStream也会通过校验和确认从datanode发来的数据是否完整。如果发现有损坏的块,就在DFSInputStream试图从其他datanode读取其副本之前通知namenode。 Client下载完block后会验证DN中的MD5,保证块数据的完整性。总结:namenode告知客户端每个block中最佳的datanode,并让客户端直接连到datanode检索数据。由于数据流分散在集群中的所有datanode,这样可以使HDFS可扩展到大量的并发客户端。同时,namenode只需要响应block位置的请求,无需响应数据请求,否则namenode会成为瓶颈。 九、HDFS Federation联邦9.1 HDFS架构的局限性内存限制由于NameNode在内存中存储所有的元数据(metadata),因此单个NameNode所能存储的对象数目受到NameNode所在JVM的heap size的限制。随着数据的飞速增长,存储的需求也随之增长。内存将成为限制系统横向扩展的瓶颈。 隔离问题由于HDFS仅有一个NameNode,无法隔离各个程序,因此HDFS上的一个程序就很有可能影响整个HDFS上运行其它的程序。 性能的瓶颈由于是单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量。 9.2 HDFS Federation架构设计 不同应用可以使用不同NameNode进行数据管理,比如日志分析业务、图片业务、爬虫业务等,不同的业务模块使用不同的NameNode进行管理NameSpace。(隔离性)  9.3 Federation优点 通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使得namenode/namespace可以通过增加机器来进行水平扩展。 能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。 可以通过多个namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中。 十、HDFS NameNode HA10.1 NameNode HA概述 9.3 Federation优点 通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使得namenode/namespace可以通过增加机器来进行水平扩展。 能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。 可以通过多个namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中。 十、HDFS NameNode HA10.1 NameNode HA概述所谓HA(High Availablity [əˌveɪlə'bɪləti] ),即高可用(7*24小时服务不中断)。通过主备NameNode解决,如果主NameNode发生故障,则切换到备NameNode上,从而解决NameNode单点故障的问题。 实现高可用最关键的目的是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。Hadoop1.x在HDFS集群中NameNode存在单点故障;Hadoop2.0+可以通过NameNode HA解决单点故障的问题。Hadoop2.x中支持两个NameNode做HA,一个主,一个备。Hadoop3.x中支持两个或两个以上的NameNode做HA,一主一备,或一主多备。NameNode主要在以下两个方面影响HDFS集群NameNode机器发生意外,如宕机,集群将无法使用,直到管理员修复重启后。NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。10.2 手动NameNode HA概述 fsimage+edits log需要由StandbyNameNode做合并工作,fsimage推送的时机可以通过参数来调整: dfs.namenode.checkpoint.period 1小时 dfs.namenode.checkpoint.txns 100 0000事务 dfs.namenode.checkpoint.check.period 3s 一个NameNode进程处于Active状态,另1个NameNode进程处于Standby状态。Active的NameNode负责处理客户端的请求。 Active的NN修改了元数据之后,会在JNs的半数以上的节点上记录这个日志。Standby状态的NameNode会监视任何对JNs上edit log的更改。一旦edits log出现更改,Standby的NN就会根据edits log更改自己记录的元数据。 当发生故障转移时,Standby主机会确保已经读取了JNs上所有的更改来同步它本身记录的元数据,然后手动完成由Standby状态切换为Active状态。 为了确保在发生故障转移操作时拥有相同的数据块位置信息,DNs向所有NN发送数据块位置信息和心跳数据。 JNS只允许一台NameNode向JNs写edits log数据,这样就能保证不会发生“脑裂”。手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合10.3 自动NameNode HA概述 主备NameNode自动切换解决单点故障 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换 所有DataNode同时向两个NameNode汇报数据块信息(位置) JNN:集群(属性)同步edits log standby:备,完成了fsimage+edits.log文件的合并产生新的fsimage,推送回ANN 自动切换:基于Zookeeper自动切换方案 ZooKeeper Failover Controller:监控NameNode健康状态,并向Zookeeper注册NameNode。NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active 10.4 NameNode自动HA 集群搭建10.4.1 规划 关闭4台虚拟机(init 0),并拍摄快照"完全分布式over"  切换快照到 "初始化":确认防火墙保持关闭状态(Linux阶段)配置4台服务器彼此之间免密登录(Zookeeper阶段)4台服务器上安装JDK,并配置环境变量(Linux阶段)node2-4,安装Zookeeper(Zookeeper阶段)ssh时不提示信息的配置配置HDFS HA切换快照到“format_pre"(NN格式化之前):ssh时不提示信息的配置配置HDFS HA不切换快照,在当前位置:删除/var/itbaizhan/hadoop/full目录和/opt/hadoop3.1.3/logs目录下的全部内容ssh时不提示信息的配置配置HDFS HA10.4.2 ssh时不提示信息配置 切换快照到 "初始化":确认防火墙保持关闭状态(Linux阶段)配置4台服务器彼此之间免密登录(Zookeeper阶段)4台服务器上安装JDK,并配置环境变量(Linux阶段)node2-4,安装Zookeeper(Zookeeper阶段)ssh时不提示信息的配置配置HDFS HA切换快照到“format_pre"(NN格式化之前):ssh时不提示信息的配置配置HDFS HA不切换快照,在当前位置:删除/var/itbaizhan/hadoop/full目录和/opt/hadoop3.1.3/logs目录下的全部内容ssh时不提示信息的配置配置HDFS HA10.4.2 ssh时不提示信息配置后续需要编写HDFS HA集群的启动和关闭的Shell脚本,在Shell脚本中会涉及到 ssh nodeX 命令,将会出现提示fingerprint信息,比较烦人, 如何让ssh不提示fingerprint信息? /etc/ssh/ssh_config(客户端配置文件) 区别于sshd_config(服务端配置文件) [root@node1 ~]# vim /etc/ssh/ssh_config # StrictHostKeyChecking ask StrictHostKeyChecking no #将 修改后的文件拷贝到node2、node3、node4 [root@node1 ~]# vim /etc/ssh/ssh_config [root@node1 ~]# scp /etc/ssh/ssh_config node2:/etc/ssh/ ssh_config 100% 2301 894.3KB/s 00:00 [root@node1 ~]# scp /etc/ssh/ssh_config node3:/etc/ssh/ ssh_config 100% 2301 579.9KB/s 00:00 [root@node1 ~]# scp /etc/ssh/ssh_config node4:/etc/ssh/ ssh_config 100% 2301 298.3KB/s 00:00 10.4.3 HDFS配置 10.4.3 HDFS配置关闭hdfs集群后,删除四台节点上/var/itbaizhan/hadoop/full目录和/opt/hadoop3.1.3/logs目录下的全部内容 rm -rf /var/itbaizhan/hadoop/full rm -rf /opt/hadoop3.1.3/logs以下一律在node1上操作,做完后scp到node2、node3、node4 hadoop-env.sh配置JDK[root@node1 hadoop]# cd /opt/hadoop-3.1.3/etc/hadoop [root@node1 hadoop]# vim hadoop-env.sh export JAVA_HOME=/usr/java/default修改workers指定datanode的位置[root@node1 hadoop]# vim workers node2 node3 node4修改core-site.xml fs.defaultFS hdfs://mycluster hadoop.tmp.dir /var/itbaizhan/hadoop/ha ha.zookeeper.quorum node2:2181,node3:2181,node4:2181 hadoop.http.staticuser.user root hdfs-site.xml dfs.journalnode.edits.dir ${hadoop.tmp.dir}/dfs/journalnode/ dfs.nameservices mycluster dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 node1:9820 dfs.namenode.rpc-address.mycluster.nn2 node2:9820 dfs.namenode.http-address.mycluster.nn1 node1:9870 dfs.namenode.http-address.mycluster.nn2 node2:9870 dfs.namenode.shared.edits.dir qjournal://node1:8485;node2:8485;node3:8485/mycluster dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_dsa dfs.ha.automatic-failover.enabled true 先同步配置文件到node2、node3、node4#node1上执行: [root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml node2:`pwd` [root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml node3:`pwd` [root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml node4:`pwd`Hadoop环境变量配置参考完全分布式的环境变量配置。 10.4.4 首次启动HDFS HA集群a) 启动zookeeper集群, node2、node3、node4分别执行: zkServer.sh startb) 在node1\node2\node3上启动三台journalnode hdfs --daemon start journalnodec) 选择node1,格式化HDFS [root@node1 hadoop]# hdfs namenode -format #看到如下提示,表示格式化成功 2021-10-15 13:21:33,318 INFO common.Storage: Storage directory /var/itbaizhan/hadoop/ha/dfs/name has been successfully formatted./var/itbaizhan/hadoop/ha/dfs/name/current/目录下产生了fsimage文件 [root@node1 hadoop]# ll /var/itbaizhan/hadoop/ha/dfs/name/current/ 总用量 16 -rw-r--r-- 1 root root 391 10月 15 13:21 fsimage_0000000000000000000 -rw-r--r-- 1 root root 62 10月 15 13:21 fsimage_0000000000000000000.md5 -rw-r--r-- 1 root root 2 10月 15 13:21 seen_txid -rw-r--r-- 1 root root 218 10月 15 13:21 VERSION格式化后,启动namenode进程 [root@node1 hadoop]# hdfs --daemon start namenode [root@node1 hadoop]# jps 7347 JournalNode 7689 NameNode 7737 Jpsd) 在另一台node2上同步元数据,然后在该节点上启动NameNode。 [root@node2 ~]# hdfs namenode -bootstrapStandby #出现以下提示: 2021-10-15 13:26:36,101 INFO ha.BootstrapStandby: Found nn: nn1, ipc: node1/192.168.20.101:9820 ===================================================== About to bootstrap Standby ID nn2 from: Nameservice ID: mycluster Other Namenode ID: nn1 Other NN's HTTP address: http://node1:9870 Other NN's IPC address: node1/192.168.20.101:9820 Namespace ID: 1743499963 Block pool ID: BP-166908272-192.168.20.101-1634275293276 Cluster ID: CID-38fac5df-ed87-46c5-a4e0-f92ce7008c07 Layout version: -64 isUpgradeFinalized: true ===================================================== #启动NameNode [root@node2 ~]# hdfs --daemon start namenode [root@node2 ~]# jps 7249 QuorumPeerMain 8019 Jps 7466 JournalNode 7980 NameNode # 看到NameNode进程表示NameNode正常启动了。e) 初始化zookeeper上的内容 一定是在namenode节点(node1或node2)上。 执行格式命令之前在node2-node4任一节点上: [root@node4 hadoop]# zkCli.sh [zk: localhost:2181(CONNECTED) 1] ls / [itbaizhan, registry, wzyy, zk001, zookeeper]接下来在node1上执行: [root@node1 ~]# hdfs zkfc -formatZK 2021-10-15 13:30:20,048 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.然后在node4上接着执行: [zk: localhost:2181(CONNECTED) 1] ls / [zookeeper, hadoop-ha] [zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha [mycluster] [z: localhost:2181(CONNECTED) 3] ls /hadoop-ha/mycluster []执行到此处,还没有启动3个DataNode和2个ZKFC进程。 f) 启动hadoop集群,在node1执行 [root@node1 ~]# start-dfs.sh #出现如下错误提示 ERROR: Attempting to operate on hdfs journalnode as root ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation. Starting ZK Failover Controllers on NN hosts [node1 node2] ERROR: Attempting to operate on hdfs zkfc as root ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation. #解决办法:修改start-dfs.sh文件 [root@node1 ~]# vim /opt/hadoop-3.1.3/sbin/start-dfs.sh #添加 HDFS_JOURNALNODE_USER=root HDFS_ZKFC_USER=root #为了防止关闭时出现类似的错误提示,修改stop-dfs.sh [root@node1 ~]# vim /opt/hadoop-3.1.3/sbin/stop-dfs.sh #添加 HDFS_JOURNALNODE_USER=root HDFS_ZKFC_USER=root #再次启动 [root@node1 hadoop]# start-dfs.sh在启动zkCli.sh的节点node4上观察: [zk: localhost:2181(CONNECTED) 5] ls /hadoop-ha/mycluster [ActiveBreadCrumb, ActiveStandbyElectorLock] [zk: localhost:2181(CONNECTED) 6] get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock myclusternn1node1 �L(�> cZxid = 0x600000008 ctime = Fri Oct 15 13:40:10 CST 2021 mZxid = 0x600000008 mtime = Fri Oct 15 13:40:10 CST 2021 pZxid = 0x600000008 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x300006fd40a0002 dataLength = 29 numChildren = 0node1占用着锁,它的状态是active的。浏览器访问:http://node1:9870  node2为standby,浏览器地址栏输入:http://node2:9870  将Active NameNode对应节点node1上NameNode进程kill掉: [root@node1 hadoop]# jps 10337 Jps 7347 JournalNode 9701 DFSZKFailoverController 7689 NameNode [root@node1 hadoop]# kill -9 7689 #或者 [root@node1 hadoop]# hdfs --daemon stop namenode [root@node1 hadoop]# jps 7347 JournalNode 9701 DFSZKFailoverController 10381 Jpsnode4上继续查看: [zk: localhost:2181(CONNECTED) 12] get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock myclusternn2node2 �L(�> cZxid = 0x60000006c ......但是通过浏览器访问发现Active NameNode不能自动进行切换。这是因为缺少一个rpm包:psmisc。接下来在四台节点上安装psmisc包。 yum install -y psmiscnode1访问不了,node2 从Standby变为了Active。 node1上再次启动namenode: [root@node1 hadoop]# hdfs --daemon start namenodenode1变为standby,变为备机。 10.4.5 编写HDFS HA启动和关闭脚本 在node1的/root/bin目录下编写zk、hdfs启动脚本[root@node1 ~]# mkdir bin [root@node1 ~]# ls anaconda-ks.cfg bin hh.txt [root@node1 ~]# cd bin/ [root@node1 bin]# vim starthdfs.sh #!/bin/bash #启动zk集群 for node in node2 node3 node4 do ssh $node "source /etc/profile;zkServer.sh start" done #休眠1s sleep 1 #启动hdfs集群 start-dfs.sh #查看当前节点node1中的角色进程 echo "-----------node1 jps--------------" jps #查看其它三个节点中的角色进程 for nd in node2 node3 node4 do echo "-----------$node jps--------------" ssh $nd "source /etc/profile;jps" done # ESC->:wq [root@node1 bin]# chmod +x starthdfs.sh2.在node1的/root/bin目录下编写zk、hdfs关闭脚本 [root@node1 bin]# vim stophdfs.sh [root@node1 bin]# cat stophdfs.sh #!/bin/bash #关闭hdfs集群 stop-dfs.sh #休眠1s sleep 1 #关闭zk集群 for node in node2 node3 node4 do ssh $node "source /etc/profile;zkServer.sh stop" done #查看四个节点中角色进程 allJps.sh [root@node1 bin]# vim allJps.sh [root@node1 bin]# cat allJps.sh #!/bin/bash #查看当前节点的角色进程 echo "-----------node1 jps--------------" jps for node in node2 node3 node4 do echo "-----------$node jps--------------" ssh $node "source /etc/profile;jps" done [root@node1 bin]# chmod +x allJps.sh [root@node1 bin]# chmod +x stophdfs.sh3. 测试:stophdfs.sh进行关闭,starthdfs.sh进行启动 4.修改starthdfs.sh [root@node1 bin]# vim starthdfs.sh #!/bin/bash #启动zk集群 for node in node2 node3 node4 do ssh $node "source /etc/profile;zkServer.sh start" done #休眠1s sleep 1 #启动hdfs集群 start-dfs.sh #调用allJps.sh allJps.sh |
【本文地址】
今日新闻 |
推荐新闻 |