在 Ubuntu20.04 上快速搭建一个hadoop集群 |
您所在的位置:网站首页 › hadoop集群部署的目的 › 在 Ubuntu20.04 上快速搭建一个hadoop集群 |
在 Ubuntu20.04 上快速搭建一个hadoop集群
|
本文将从安装一台虚拟机开始,一步步的搭建一个hadoop集群。期间遇到了很多坑,我也把解决方案都写在文章中了,如果按照本文中的过程进行配置,还遇到了其他问题,欢迎各位提出~ 目录 1.单台虚拟机的配置1.1. 安装一台 ubuntu20.04 虚拟机1.2. 安装VMTools工具1.3.固定IP1.4.修改主机名与IP的映射1.5.安装配置必要工具1.5.1.SSH-Server1.5.2.安装JDK 1.6.对hadoop进行初步的配置1.6.1.安装hadoop-2.7.21.6.2.修改环境变量1.6.3.修改hadoop的配置文件: 1.7.编写两个脚本以便于之后文件的分发和命令的传输 2.配置分布式集群2.1.虚拟机的克隆2.2.修改主机名2.3.修改网络配置信息2.4.配置ssh免密登录2.5.测试xcall和xsync命令2.5.1.xcall2.5.2.xsync 2.6.设置non-login环境变量2.6.1.方式一2.6.2.方式二 3.hadoop的初次使用3.1.hadoop初始化3.2.开启HDFS3.3.开启YARN3.4.开启历史日志服务 注意1.集群分配2.java API 读写HDFS 1.单台虚拟机的配置 1.1. 安装一台 ubuntu20.04 虚拟机
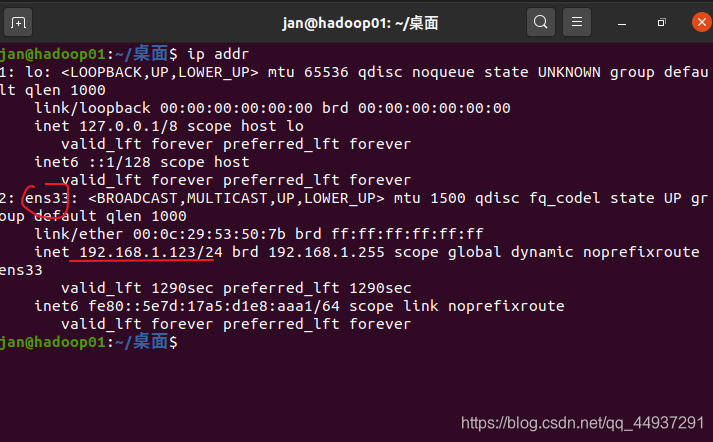
当然,这里的模式以后也可以重新选择。 安装完成,进入桌面。 为了可以向虚拟机内传输文件和调节虚拟机的窗口大小,需要安装VMTools。 打开一个终端,依次输入命令: sudo apt upgrade sudo apt install open-vm-tools-desktop -y sudo reboot 1.3.固定IP首先确认要修改的网卡号,在终端输入命令 ip addr我的虚拟机中显示如下: 新增一行,修改一行: 为用户增加权限的过程就完成了,下次sudo可以不用密码。 编辑网络配置信息文件 sudo gedit /etc/netplan/01-network-manager-all.yamlPS:其中01-network-manager-all.yaml文件是我机器上的配置信息,不同的机器可能不太一样,可以使用: cd /etc/netplan ls查看本机的文件: 在使用vi /etc/netplan/01-network-manager-all.yaml 命令后进入文件,需要把配置文件修改为以下内容: 假设IP地址修改为192.168.1.124,子网掩码24位即255.255.255.0,网关设置为192.168.1.2,DNS1:8.8.8.8。 dhcp4:no 代表不再动态分配IP。 network: ethernets: ens33: dhcp4: no addresses: [192.168.1.124/24] optional: true gateway4: 192.168.1.2 nameservers: addresses: [8.8.8.8,223.6.6.6] version: 2 renderer: NetworkManager应用新的网络配置 sudo netplan apply再次查看ip ip addr
我将搭建一个三台机器的集群,分配的ip如下: 主机名iphadoop01192.168.1.124hadoop01192.168.1.125hadoop01192.168.1.126在文件的最后加入: 192.168.1.124 hadoop01 192.168.1.125 hadoop02 192.168.1.126 hadoop03同时注释掉 #127.0.1.1 hadoop01 1.5.安装配置必要工具 1.5.1.SSH-Server安装ssh-server sudo apt-get install openssh-server修改 /etc/ssh/ssh_config 文件 gedit /etc/ssh/ssh_config将PermitRootLogin prohibit-password 改为 PermitRootLogin yes 后重启ssh服务 /etc/init.d/ssh restart 1.5.2.安装JDK在windows上下载一个8以上版本的JDK,直接拖到linux虚拟机桌面上。 创建一个environments文件夹,以后专门用来放各种环境的包,并把解压好的jdk移动到这个文件夹中 mkdir ~/environments mv jdk1.8.0_121 ~/environments/编辑本用户的配置文件 gedit ~/.profile在文件的最后加入 #Java export JAVA_HOME=/home/jan/environments/jdk1.8.0_121 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH在终端输入reboot重启,重启后验证是否生效。出现下面的提示则证明生效。 首先计划集群做一个功能的分配: hadoop01hadoop02hadoop03namenodedatanodedatanodedatanodesecondarynoderesourcemanagernodemanagernodemanagernodemanager 1.6.1.安装hadoop-2.7.2还是,下载一个linux版 hadoop tar 包拖进虚拟机 解压之后移动得到用户根目录下 tar -zvxf hadoop-2.7.2.tar.gz mv hadoop-2.7.2 ~/ 1.6.2.修改环境变量 gedit ~/.profile在文件末尾添加 # hadoop export HADOOP_HOME=/home/jan/hadoop-2.7.2 export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin 1.6.3.修改hadoop的配置文件:进入配置文件目录 cd /home/jan/hadoop-2.7.2/etc/hadoop/(其中jan是自己起的用户名) 修改以下4个文件 1.core-site.xml gedit core-site.xml fs.defaultFS hdfs://hadoop01:9000 hadoop.tmp.dir /opt/zhw/module/hadoop-2.7.2/data/tmp A base for other temporary directories.2.hdfs-site.xml gedit hdfs-site.xml dfs.namenode.secondary.http-address hadoop03:50090 The secondary namenode http server address and port.3.mapred-site.xml 复制一个 mapred-site.xml.template 文件 cp mapred-site.xml.template mapred-site.xml在mapred-site.xml中加入内容: gedit hdfs-site.xml mapreduce.framework.name yarn The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn. mapreduce.jobhistory.address 0.0.0.0:10020 MapReduce JobHistory Server IPC host:port mapreduce.jobhistory.webapp.address 0.0.0.0:19888 MapReduce JobHistory Server Web UI host:port4.yarn-site.xml gedit yarn-site.xml A comma separated list of services where service name should only contain a-zA-Z0-9_ and can not start with numbers yarn.nodemanager.aux-services mapreduce_shuffle The hostname of the RM. yarn.resourcemanager.hostname hadoop02 The http address of the RM web application. yarn.resourcemanager.webapp.address ${yarn.resourcemanager.hostname}:8088 yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 604800 1.7.编写两个脚本以便于之后文件的分发和命令的传输以下两个脚本源自尚硅谷的大数据课程,有兴趣去看看明白一下含义,这里我们仅仅说配置和用法。 1.xsync 新建一个文件 gedit xsync此脚本用于虚拟机之间通过scp传送文件 #!/bin/bash #校验参数是否合法 if(($#==0)) then echo 请输入要分发的文件! exit; fi #获取分发文件的绝对路径 dirpath=$(cd `dirname $1`; pwd -P) filename=`basename $1` echo 要分发的文件的路径是:$dirpath/$filename #循环执行rsync分发文件到集群的每条机器 for((i=1;i |

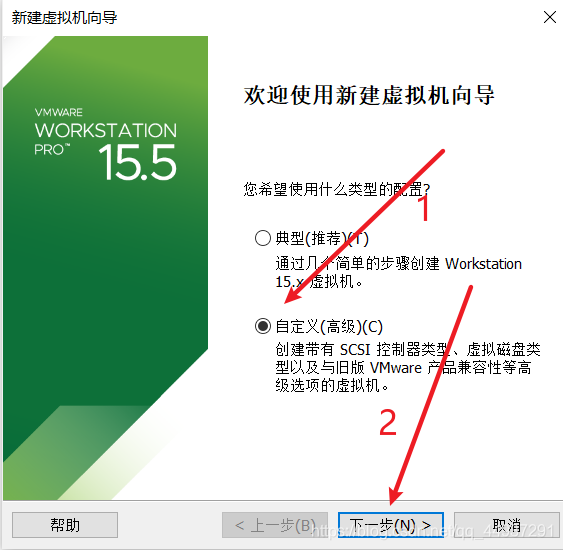
 上图中选择 15.X 是因为 Ubuntu20.04 是较新的版本,防止兼容性出问题。
上图中选择 15.X 是因为 Ubuntu20.04 是较新的版本,防止兼容性出问题。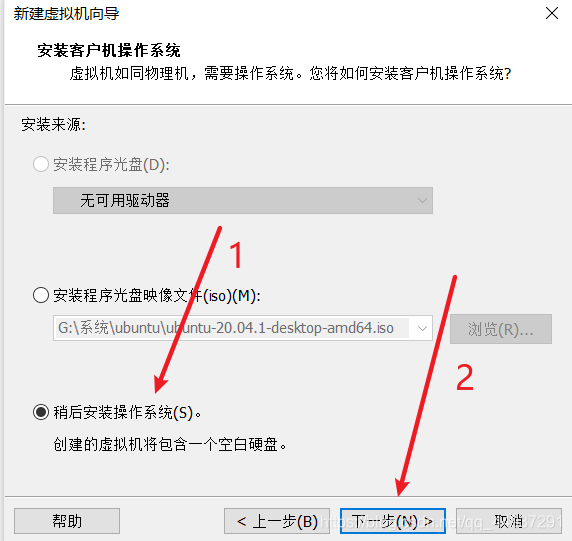
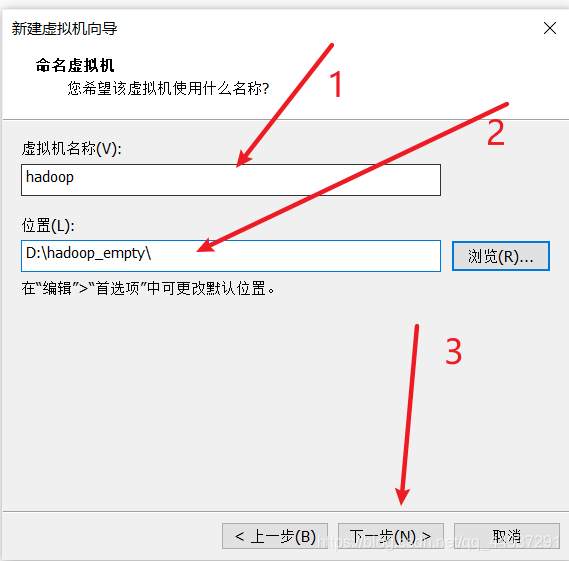 标号 1 处将为你在 VMware Workstation 中看到的虚拟机名字; 标号 2 处选择的位置最好是一个空文件夹,因为在创建虚拟机时不会产生一个包含所有文件的文件夹,位置处即为所有文件的根目录。
标号 1 处将为你在 VMware Workstation 中看到的虚拟机名字; 标号 2 处选择的位置最好是一个空文件夹,因为在创建虚拟机时不会产生一个包含所有文件的文件夹,位置处即为所有文件的根目录。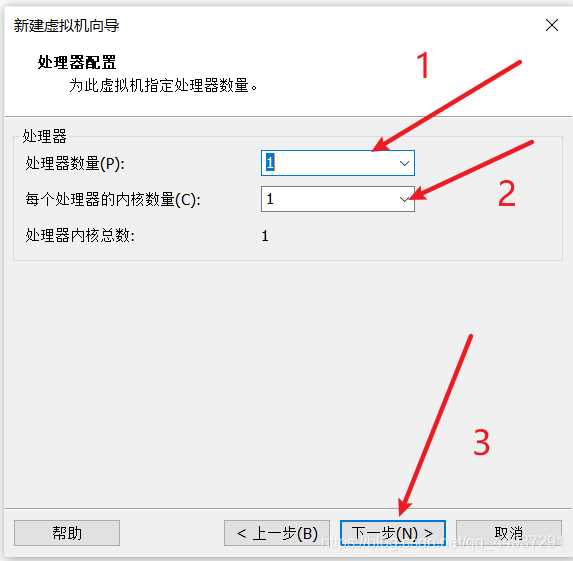
 这里的选择无所谓,以后还能调。
这里的选择无所谓,以后还能调。 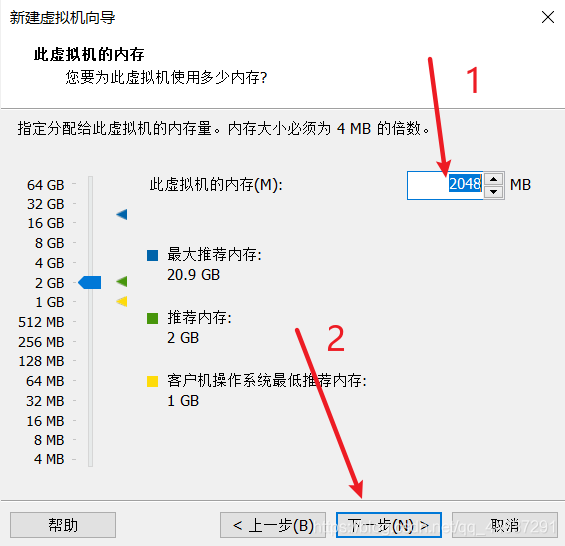 同样无所谓,可调。
同样无所谓,可调。 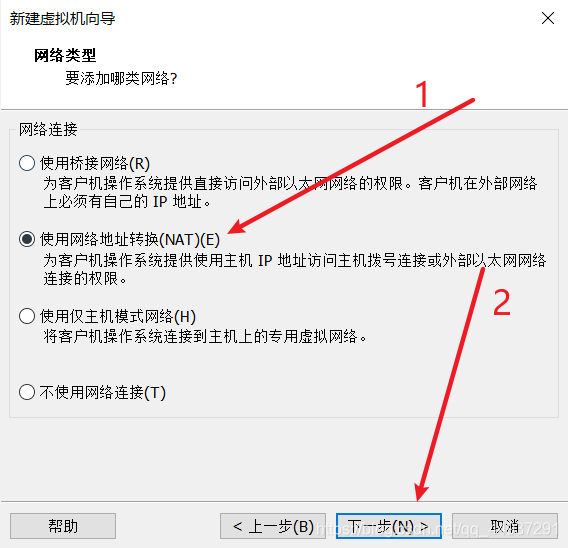 如果你的网络是学校的校园网,建议选NAT,如果是家庭局域网,那么NAT和桥接都可以。不要选主机模式网络!!!否则hadoop将无法使用。
如果你的网络是学校的校园网,建议选NAT,如果是家庭局域网,那么NAT和桥接都可以。不要选主机模式网络!!!否则hadoop将无法使用。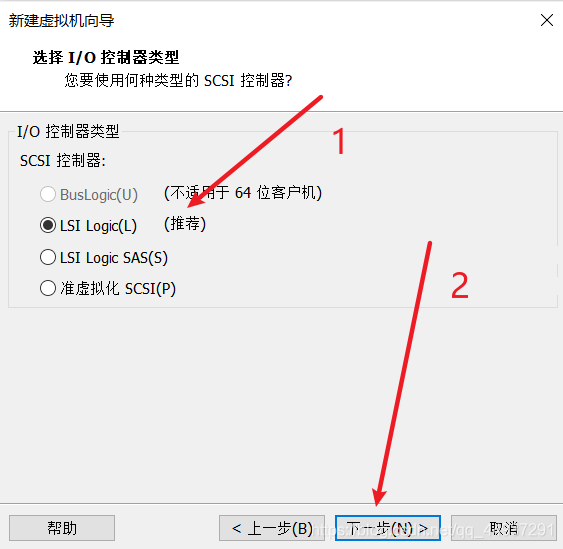
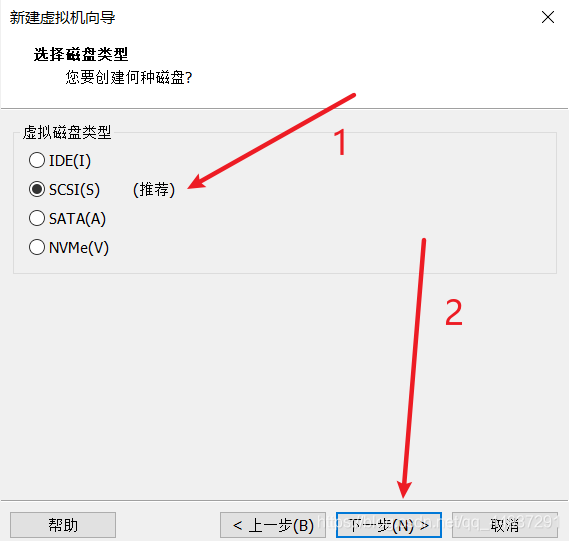
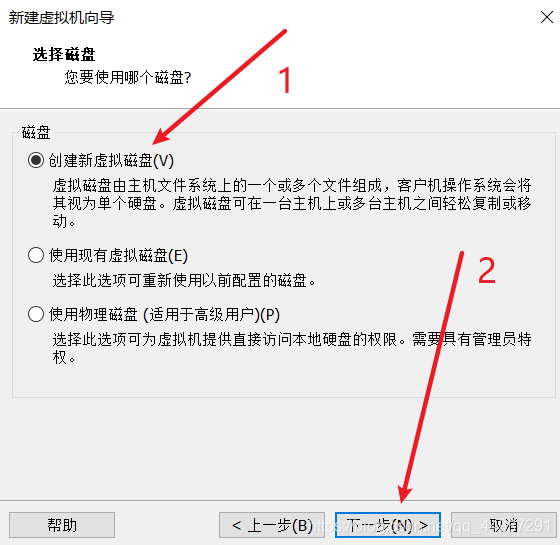
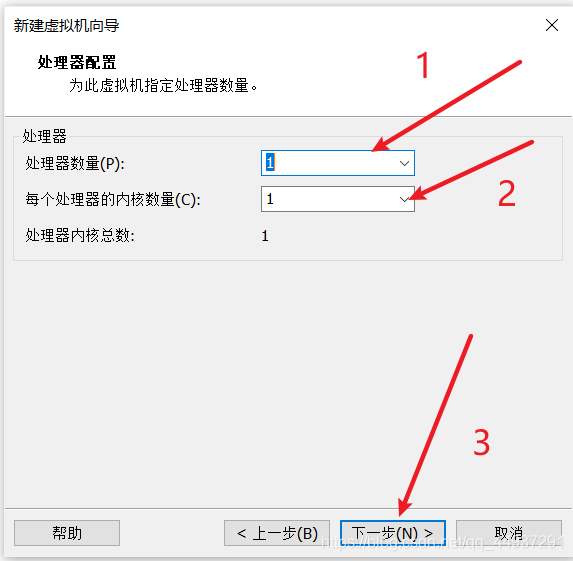
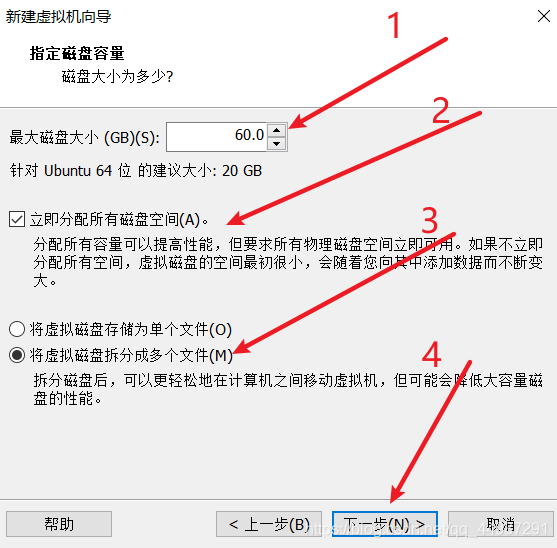 标号1、2处看你机器的具体情况。
标号1、2处看你机器的具体情况。 
 双击打开 CD/DVD(SATA)
双击打开 CD/DVD(SATA)  选择已经事先准备好的 Ubuntu20.04 的 ISO文件,下载地址:https://ubuntu.com/download/desktop/thank-you?version=20.04.1&architecture=amd64
选择已经事先准备好的 Ubuntu20.04 的 ISO文件,下载地址:https://ubuntu.com/download/desktop/thank-you?version=20.04.1&architecture=amd64  启动虚拟机,稍微等待一会儿。
启动虚拟机,稍微等待一会儿。  将左侧的导航条拉到底选择中文,并选择安装Ubuntu。
将左侧的导航条拉到底选择中文,并选择安装Ubuntu。 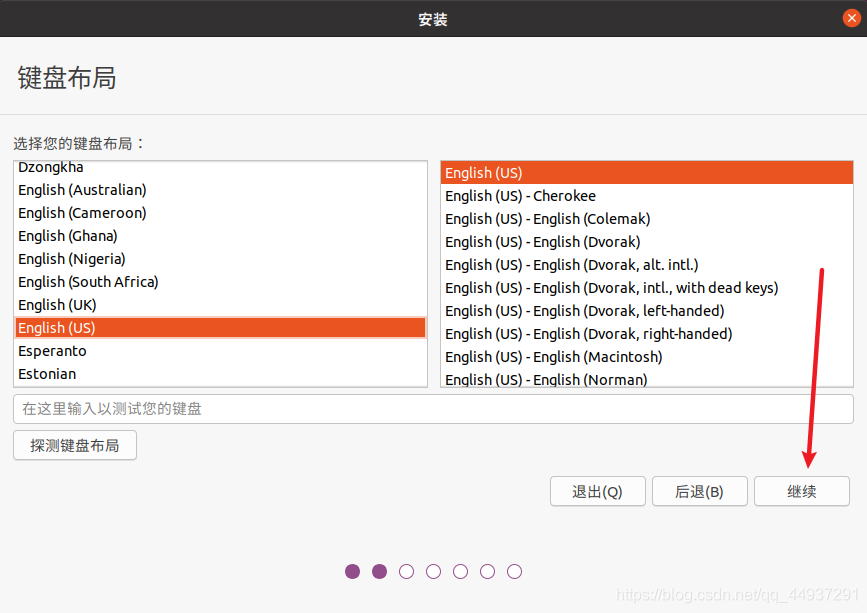
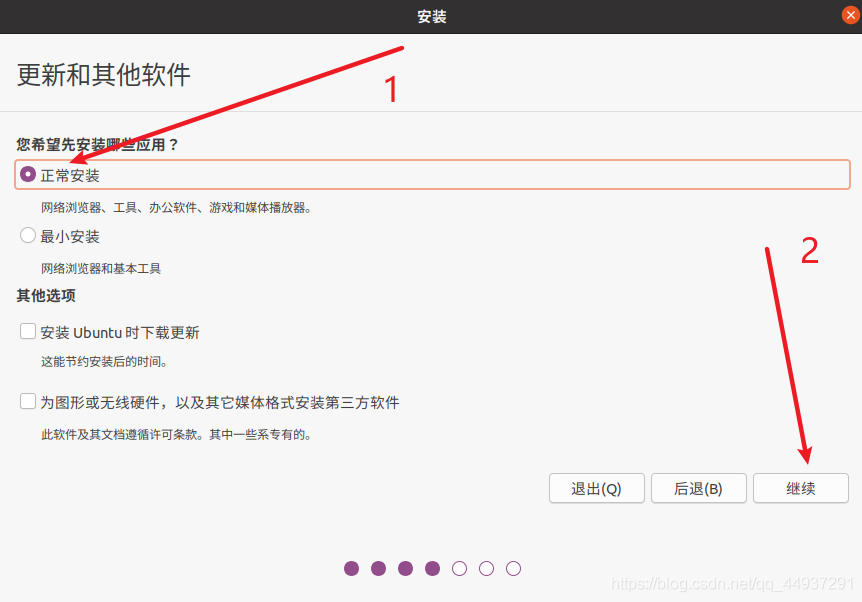
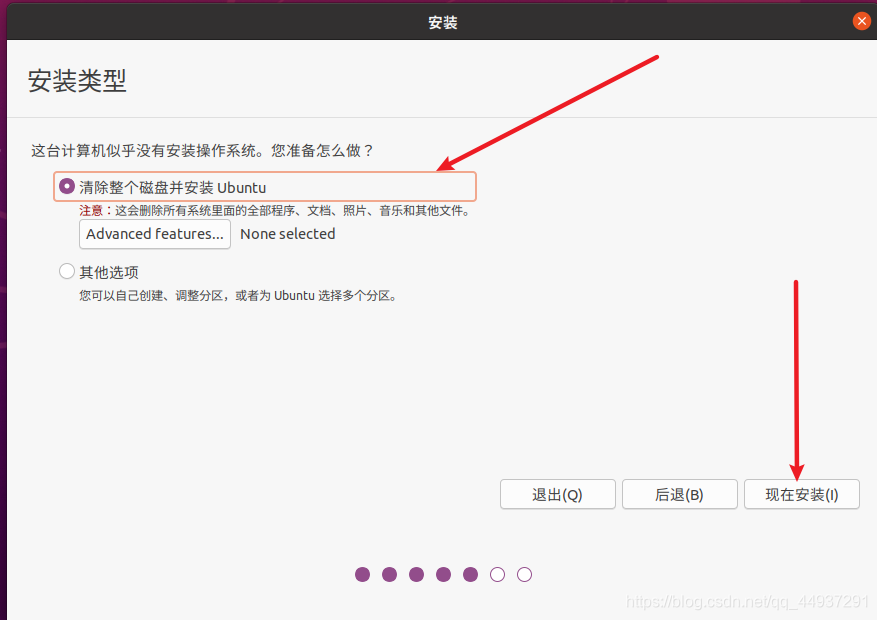 Linux 新手不建议自己分配分区,容易后期用着用着发现有坑。。
Linux 新手不建议自己分配分区,容易后期用着用着发现有坑。。 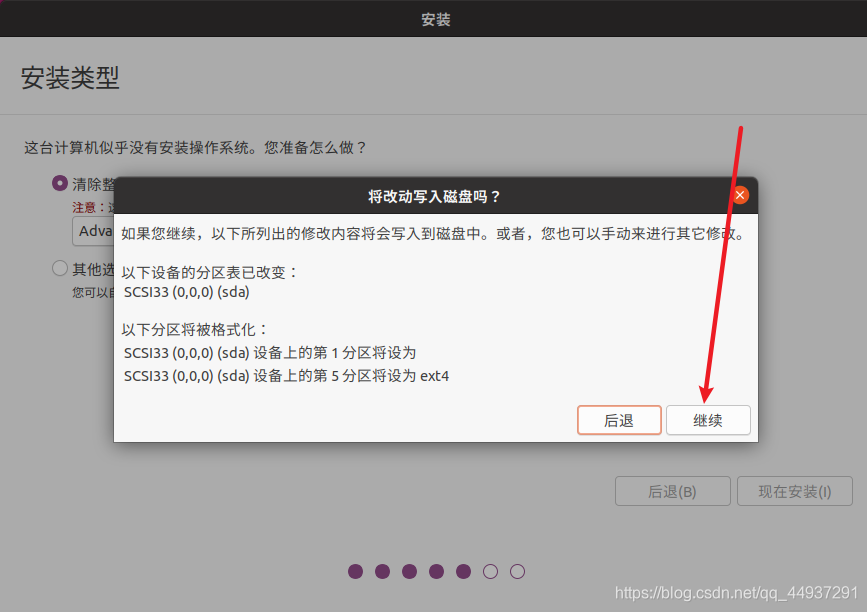
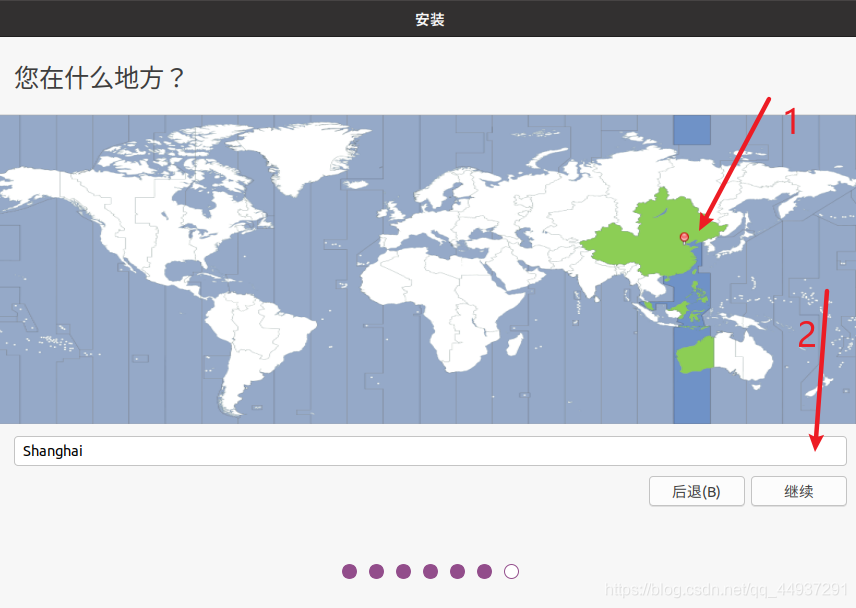 选择时区
选择时区 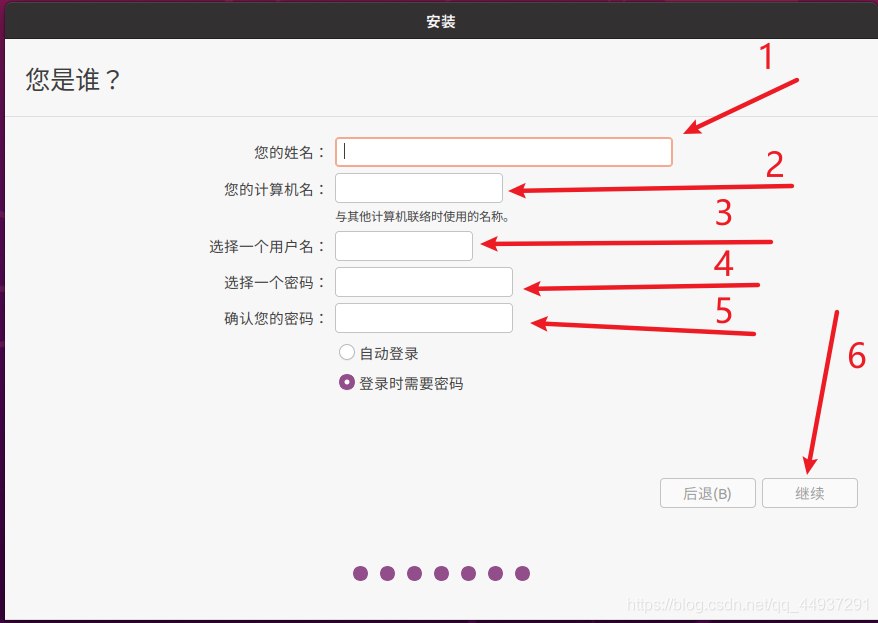 标号1,要设置的用户名 标号2,将要显示的计算机名 标号3-5,设置对应用户的用户名和密码
标号1,要设置的用户名 标号2,将要显示的计算机名 标号3-5,设置对应用户的用户名和密码
 接下来查看和修改网络配置信息。 我们创建的普通用户权限不足,不能修改网络配置信息,要先为普通用户赋予root权限,这需要切换到root用户下。首先为root用户设置一个密码并切换到root用户:
接下来查看和修改网络配置信息。 我们创建的普通用户权限不足,不能修改网络配置信息,要先为普通用户赋予root权限,这需要切换到root用户下。首先为root用户设置一个密码并切换到root用户: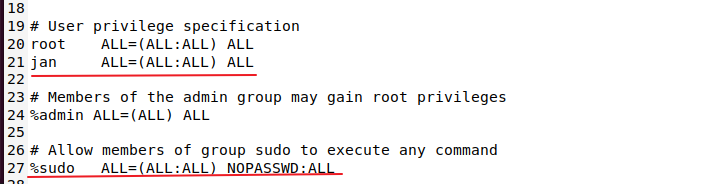

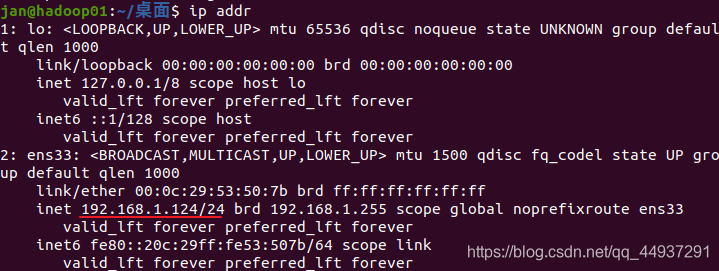 IP固定成功。
IP固定成功。 在桌面上打开一个终端,解压
在桌面上打开一个终端,解压 (这里有个小坑,按理说在修改配置文件之后重新开启一个终端配置文件应该就能生效,但是我测试的时候却没有,重启后才生效)
(这里有个小坑,按理说在修改配置文件之后重新开启一个终端配置文件应该就能生效,但是我测试的时候却没有,重启后才生效)【本文地址】
今日新闻 |
推荐新闻 |