解决Hadoop完全分布式集群中从节点jps没有datanode节点问题 |
您所在的位置:网站首页 › hadoop没有data文件 › 解决Hadoop完全分布式集群中从节点jps没有datanode节点问题 |
解决Hadoop完全分布式集群中从节点jps没有datanode节点问题
|
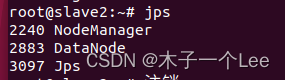
当用start-dfs.sh和start-yarn.sh后,在slave节点(从节点)中用jps命令查看进程 正常情况:
有时候可能发现没有Datanode,即只有两项(第一项和最后一项)。原因可能是重复格式化namenode后,导致datanode的clusterID和namenode的clusterID不一致。 解决方法: 在master节点(namenode): 找到你的hadoop安装目录(我的是/usr/local/hadoop)下的tmp文件:
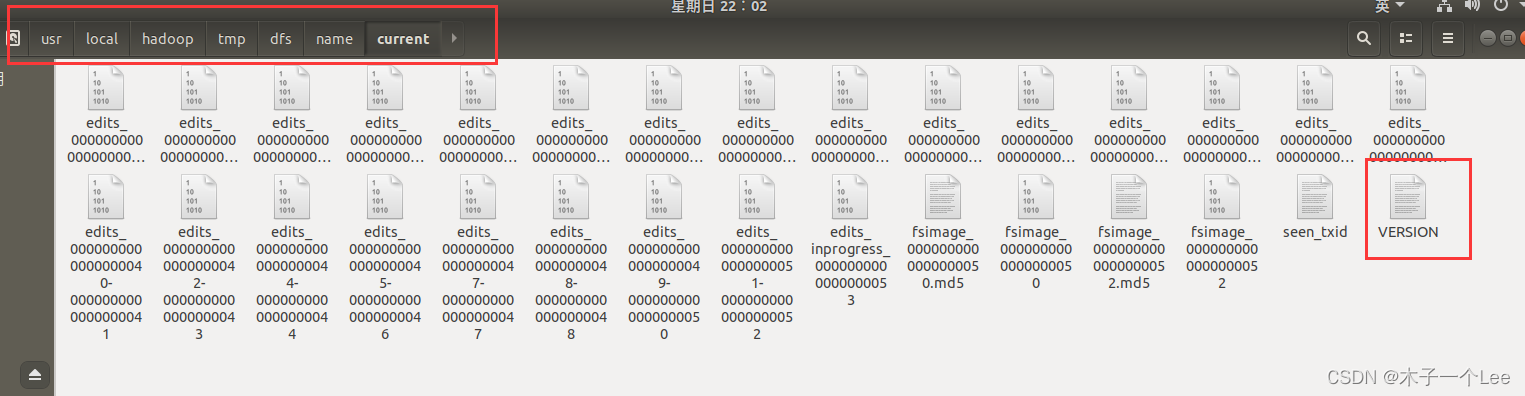
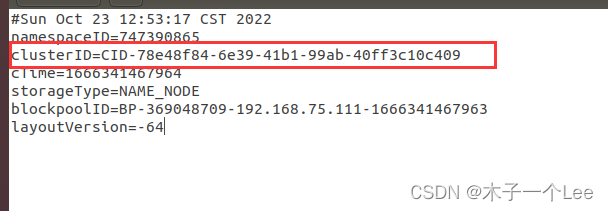
进入以下目录(/tmp/dfs/name/current),找到VERSION文件: 打开,记录namedode下的clusterID:
然后到你的从节点下(每个从节点都要改), 也是进入这个目录,只不过namenode中的name文件在datanode是变为了data文件,即/tmp/dfs/data/current 然后打开VERSION,把namenode的clusterID替换掉datanode的clusterID就可以了。 |

【本文地址】
今日新闻 |
推荐新闻 |