编写mapreduce程序实例 |
您所在的位置:网站首页 › hadoop对两个文件中的数据进行合并和去重 › 编写mapreduce程序实例 |
编写mapreduce程序实例
|
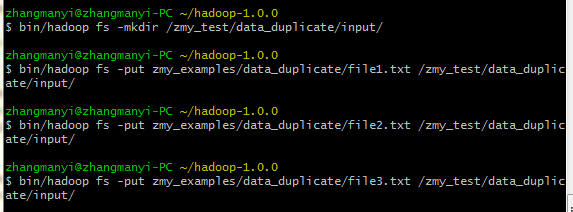
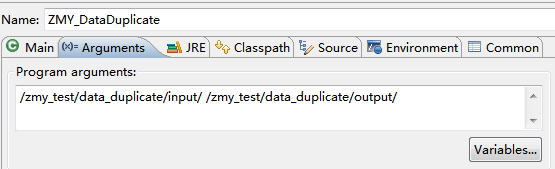
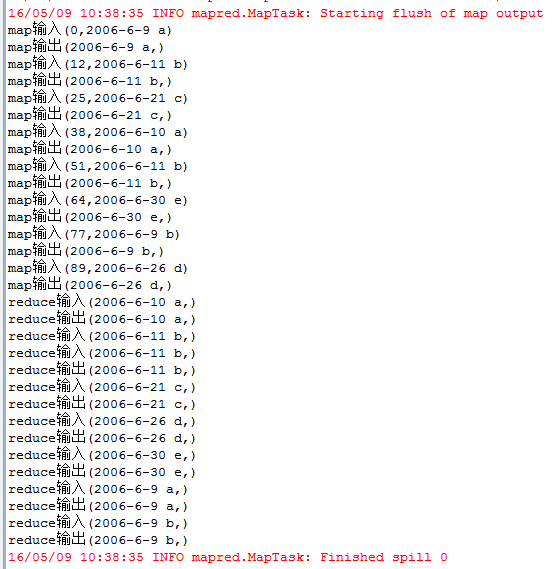
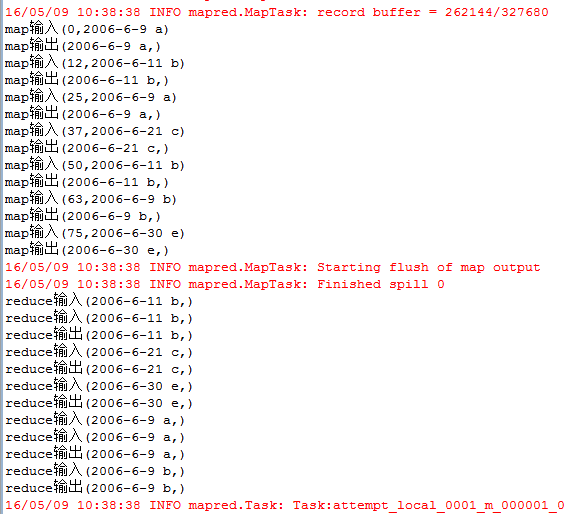
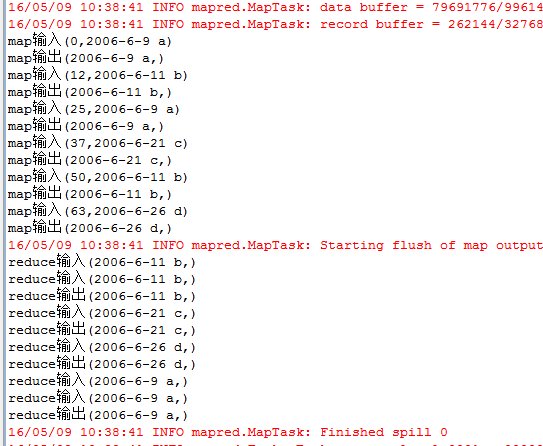
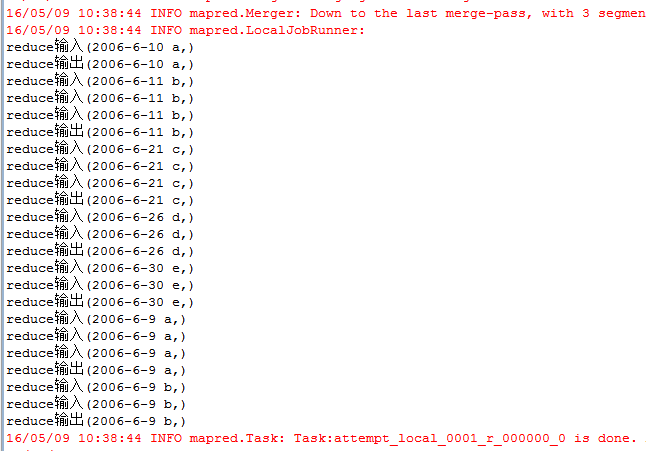
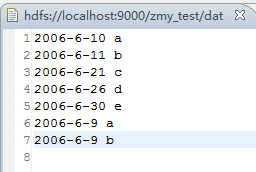
每一行为一个日期及一个人名字,分为3个文件,其中存在多行重复数据,需要进行去重。 输入文件: file1: 2006-6-9 a 2006-6-11 b 2006-6-21 c 2006-6-10 a 2006-6-11 b 2006-6-30 e 2006-6-9 a 2006-6-26 d file2: 2006-6-9 a 2006-6-11 b 2006-6-9 a 2006-6-21 c 2006-6-11 b 2006-6-9 a 2006-6-30 e file3: 2006-6-9 a 2006-6-11 b 2006-6-9 a 2006-6-21 c 2006-6-11 b 2006-6-26 d 期望输出: 2006-6-9 a 2006-6-10 a 2006-6-11 b 2006-6-21 c 2006-6-26 d 2006-6-30 e 编写代码: package zmy.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Mapper.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class ZMY_DataDuplicate_dedup { //定义log变量 public static final Log LOG = LogFactory.getLog(FileInputFormat.class); public static class TokenizerMapper extends Mapper{ private static Text line=new Text();//每行数据 //实现map函数 public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ System.out.println("map输入("+ key + "," + value + ")"); line=value; System.out.println("map输出("+ line + "," + new Text("") + ")"); context.write(line, new Text("")); } } public static class IntSumReducer extends Reducer{ //实现reduce函数 public void reduce(Text key,Iterable values,Context context) throws IOException,InterruptedException{ for (Text val : values) { System.out.println("reduce输入("+ key + "," + val.toString() + ")"); } System.out.println("reduce输出("+ key + "," + new Text("") + ")"); context.write(key, new Text("")); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //检查运行命令 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: data duplicate "); System.exit(2); } Job job = new Job(conf, "data duplicate"); job.setJarByClass(ZMY_DataDuplicate_dedup.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }运行过程: 1、单个文件的map输入输出与reduce输入输出过程: file1 file2 file3 注意这里reduce的输入的value其实是一个列表,是经过shuttle过程产生的,例如reduce输入(2006-6-11 b,) reduce输入(2006-6-11 b,) 其实应该是(2006-6-11 b,< , >) 2、再整合三个文件的reduce输出结果,又进行一次reduce过程: 思路: 1、map过程输入的值value即为一行数据,key为数据到文件头的偏移值,因此只需要value数据即可,因为是去重,所以不需要进行拆分。因此在map输出中将输入的value值定为输出的key值,value值置为空。 2、在map过程后会进行shuttle过程,这里是对每个文件都独立分开完成,完成shuttle过程后的输出即为reduce的输入,key值依然为一行数据,value值为相同key的value列表。 3、在reduce过程中对输入进行处理,key保留,对于value列表不需要进行处理,直接将value置为空,则只会输出一次。即达到了去重的目的。 4、将三个文件reduce后的去重结果,再进行一次shuttle和reduce过程,达到最终的结果。 5、这里没有自定义排序。按照默认排序。 输出结果: |
【本文地址】
今日新闻 |
推荐新闻 |