【Hadoop】大数据分析实战:Hadoop生态圈全家桶入门教程 |
您所在的位置:网站首页 › hadoop大数据处理实战 › 【Hadoop】大数据分析实战:Hadoop生态圈全家桶入门教程 |
【Hadoop】大数据分析实战:Hadoop生态圈全家桶入门教程
|
目录 1. 什么是大数据? 2. 什么是Hadoop生态圈? 3. Hadoop生态圈的组成 4. 大数据分析实战案例 5. 如何学习Hadoop生态圈 6. 总结  1. 什么是大数据?
1. 什么是大数据?
随着互联网的发展,数据量不断增加,大数据已经成为一种趋势。大数据指的是数据量非常大、类型繁多的数据集合。这些数据集合需要使用特定的技术和工具进行处理和分析。 2. 什么是Hadoop生态圈?Hadoop生态圈是由Apache基金会开发和维护的一系列开源软件组成的大数据处理框架。Hadoop生态圈包括HDFS、MapReduce、YARN、Hive、Pig、Spark等组件,提供了大规模数据存储、处理和分析等功能。 3. Hadoop生态圈的组成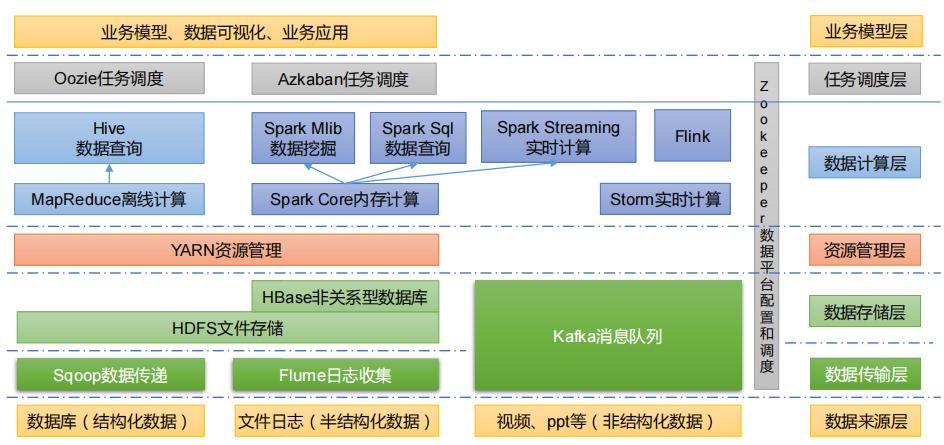
Hadoop生态圈由以下组件组成: HDFS:Hadoop分布式文件系统,用于存储大量的数据。 MapReduce:分布式计算框架,用于处理大规模数据集。 YARN:资源管理器,用于管理集群中的计算资源。 Hive:数据仓库,用于查询和分析数据。 Pig:数据流处理平台,用于处理非结构化数据。 Spark:分布式计算引擎,用于处理大规模数据集。 4. 大数据分析实战案例以下是几个常见的大数据分析实战案例: 电商网站用户行为分析:通过对用户浏览、搜索和购买等行为进行分析,提高销售效率和用户满意度。航空公司客户满意度分析:通过对乘客预订、登机、退票等行为进行分析,提高服务质量和客户满意度。金融风险管理分析:通过对金融市场、经济和企业等数据进行分析,识别潜在的风险和机会。 5. 如何学习Hadoop生态圈要学习Hadoop生态圈,需要具备编程基础和Linux操作系统知识。以下是一些学习资源和实践项目: 学习资源:可以通过官方文档(以下是Hadoop生态圈官方文档链接: Hadoop官方文档:https://hadoop.apache.org/docs/ HDFS官方文档:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html MapReduce官方文档:https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html YARN官方文档:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html Hive官方文档:https://cwiki.apache.org/confluence/display/Hive/Home Pig官方文档:https://pig.apache.org/docs/latest/ Spark官方文档:https://spark.apache.org/docs/latest/ )、在线课程和书籍等途径进行学习。实践项目:可以通过参与开源项目或者自己搭建实验环境进行实践。 6. 总结Hadoop生态圈是大数据处理领域的标准。学习Hadoop生态圈可以帮助我们掌握大数据存储、处理、分析和机器学习等技能。通过实践项目,我们可以深入了解Hadoop生态圈的应用和实践,提高自己的技术水平。同时,学习Hadoop生态圈需要具备一定的编程基础和Linux操作系统知识,建议在学习之前先掌握这些基础知识。总之,Hadoop生态圈是大数据处理领域的重要技术,对于从事大数据处理和分析工作的人员来说,学习Hadoop生态圈是非常有必要的。 |
【本文地址】
今日新闻 |
推荐新闻 |