BP神经网络的初步介绍 |
您所在的位置:网站首页 › greet模型简单介绍 › BP神经网络的初步介绍 |
BP神经网络的初步介绍
|
文章目录
前言:一、BP 神经网络概述二、神经网络的前馈过程三、逆向误差传播 (BP过程)四、模型的损失函数五、基于梯度下降的逆向传播过程 (关于损失函数的逆向求导)六、举例子直观了解BackPropagation七、BP反向传播的详细推导
前言:
上一篇博客,从感知机到人工神经网络大体的概括了人工神经网络,本篇博客旨在介绍BP神经网络,网上关于BP神经网络的相关知识以及数不胜数,本文在别人博客的基础上整理的知识点,便于自己理解,以后复习也可以常看看。 我们要训练多层网络的时候,最后关键的部分就是求梯度啦。纯数学方法几乎是不可能的,那么反向传播算法就是用来求梯度的,用了一个很巧妙的方法。 反向传播算法应该是神经网络最基本最需要弄懂的方法了,要是反向传播方法不懂,后面基本上进行不下去。 非常推荐的是How the backpropagation algorithm works 首先,需要记住两点: 1.反向传播算法告诉我们当我们改变权值(weights)和偏置(biases)的时候,损失函数改变的速度。2.反向传播也告诉我们如何改变权值和偏置以改变神经网络的整体表现。 一、BP 神经网络概述BP 神经网络是一类基于误差逆向传播 (BackPropagation, 简称 BP) 算法的多层前馈神经网络,BP算法是迄今最成功的神经网络学习算法。现实任务中使用神经网络时,大多是在使用 BP 算法进行训练。值得指出的是,BP算法不仅可用于多层前馈神经网络,还可以用于其他类型的神经网络,例如训练递归神经网络。但我们通常说 “BP 网络” 时,一般是指用 BP 算法训练的多层前馈神经网络。 二、神经网络的前馈过程假设我们构造一个经典的神经网络,如下图,该网络可接收输入数据 x x x,包含两个属性 x 1 , x 2 x_1,x_2 x1,x2,包含一个隐含层,隐含层的每个神经元首先通过 w [ 1 ] w^{[1]} w[1]和 b 1 b_1 b1(b 为偏置项) 将输入参数进行线性组合得到 z [ 1 ] z^{[1]} z[1],然后将 z [ 1 ] z^{[1]} z[1] 带入激活函数 (activation function) σ ( z ) σ(z) σ(z) ,得到隐含层的一组输出 a [ 1 ] a^{[1]} a[1] 。接下来,将这组 a [ 1 ] a^{[1]} a[1] 通过 w [ 2 ] w^{[2]} w[2]和 b 2 b_2 b2 进行第二次线性组合,得到 z [ 1 ] z^{[1]} z[1] ,再带入激活函数 σ ( z ) σ(z) σ(z) ,得到最终的输出值 a [ 2 ] a^{[2]} a[2] ,该值即为学习器 (广义上看,神经网络属于学习器的一种类型) 的推测结果 y h a t y^{hat} yhat。
上述过程,即为该神经网络的前馈 (forward propagation) 过程,前馈过程也非常容易理解,符合人正常的逻辑,具体的矩阵计算表达如下:
为了达到这个目标,这也就转换为了一个优化过程,对于任何优化问题,总是会有一个目标函数 (objective function),在机器学习的问题中,通常我们称此类函数为:损失函数 (loss function),具体来说,损失函数表达了推测值与真实值之间的误差。抽象来看,如果把模型的推测以函数形式表达为 那么在该问题中的损失函数是什么样的呢?抛开线性组合函数,我们先着眼于最终的激活函数,也就是 a [ 2 ] a^{[2]} a[2]的值,由于 sigmoid 函数具有很好的函数性质,其值域介于 0 到 1 之间,当自变量很大时,趋向于 1,很小时趋向于 0,因此,该模型的损失函数可以定义如下:
不难发现,由于是分类问题,真实值只有取 0 或 1 两种情况,当真实值为 1 时,输出值
a
a
a越接近 1,则 loss 越小;当真实值为 0 时,输出值越接近于 0,则 损失函数越小 (可自己手画一下
−
l
n
(
x
)
-ln(x)
−ln(x)函数的曲线)。因此,可将该分段函数整合为如下函数,也就是得到我们的交叉熵损失函数,对于这个概念不太了解的,可以查看交叉熵的理解: 该函数与上述分段函数等价。如果你了解 Logistic Regression 模型 的基本原理,那么损失函数这一部分与其完全是一致的,现在,我们已经确定了模型的损失函数关于输出量 [公式] 的函数形式,接下来的问题自然就是:如何根据该损失函数来优化模型的参数。 五、基于梯度下降的逆向传播过程 (关于损失函数的逆向求导)这里需要一些先修知识,主要是需要懂得 梯度下降 (gradient descent) 这一优化算法的原理,由于如果将神经网络的损失函数完全展开将会极为繁琐,这里我们先根据上面得到的关于输出量a 的损失函数来进行一步步的推导。
定义两层的神经网络,输入层(0层),隐藏层(1层),输出层(2层)。此处省略每个结点的偏置(有偏置的原理一样),激活函数为sigmoid函数(不同激活函数,求导不同)。 对应网络如下:
首先正向传播 下面我们看如何反向传播 根据公式,我们有: 同理有: 同理可得其他几个式子: 则最终的结果为: 在按照这个权重参数进行一遍正向传播得出来的Error为0.165 而这个值比原来的0.19要小,则继续迭代,不断修正权值,使得代价函数越来越小,预测值不断逼近0.5。我迭代了100次的结果,Error为5.92944818e-07(已经很小了,说明预测值与真实值非常接近了),最后的权值为: BP过程差不多就是这样了。 七、BP反向传播的详细推导请查看我的下一篇博客BP反向传播的详细推导 参考: [1] https://www.zhihu.com/question/27239198/answer/140093887 [2] https://www.zhihu.com/question/27239198/answer/140093887 [3] https://blog.csdn.net/u014303046/article/details/78200010 |



![[公式]](https://img-blog.csdnimg.cn/20190922095745471.png) (这里的函数字母使用 h 是源于“假设 hypothesis“ 这一单词),对于有个
m
m
m 训练样本的输入数据而言,其损失函数则可表达为:
(这里的函数字母使用 h 是源于“假设 hypothesis“ 这一单词),对于有个
m
m
m 训练样本的输入数据而言,其损失函数则可表达为: 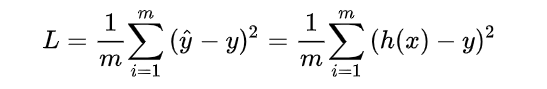
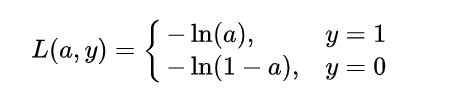
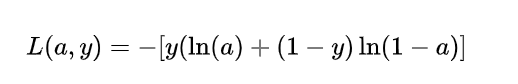


 至此,我们已经完成了整个逆向传播 BP 的过程。
至此,我们已经完成了整个逆向传播 BP 的过程。 对应矩阵如下:
对应矩阵如下: 
 则:
则:  同理可得:
同理可得:  最终的损失为:
最终的损失为: 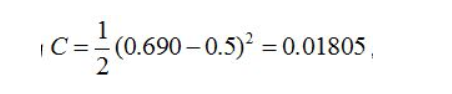 我们最终也就是希望损失越小越好,这就是我们为什要进行训练,调节参数,使损失最小,这就用到了我们的反向传播算法,实际上反向传播就是梯度下降算法中链式法则的使用。
我们最终也就是希望损失越小越好,这就是我们为什要进行训练,调节参数,使损失最小,这就用到了我们的反向传播算法,实际上反向传播就是梯度下降算法中链式法则的使用。 这个时候我们需要求出C对w的骗到,则根据链式法则有:
这个时候我们需要求出C对w的骗到,则根据链式法则有: 
 到此我们已经算出了最后一层的参数偏导了,我们继续往前面链式推导: 我们现在还需要求
到此我们已经算出了最后一层的参数偏导了,我们继续往前面链式推导: 我们现在还需要求 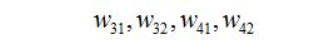 下面给出一个推导,其他全都类似:
下面给出一个推导,其他全都类似: 


【本文地址】
今日新闻 |
推荐新闻 |