C语言使用CUDA中cufft函数做GPU加速FFT运算,与调用fftw函数的FFT做运算速度对比 |
您所在的位置:网站首页 › gpu运算比cpu快多少 › C语言使用CUDA中cufft函数做GPU加速FFT运算,与调用fftw函数的FFT做运算速度对比 |
C语言使用CUDA中cufft函数做GPU加速FFT运算,与调用fftw函数的FFT做运算速度对比
|
目录
任务介绍环境所需相关软件下载与安装C语言:不调用库的GPU加速FFT代码C语言:调用fftw库的未使用GPU的FFT代码C语言:调用cufft库的GPU加速FFTgnuplot安装画图,maltab编写的FFT运算结果对比matlab测试信号和测试时的坑
任务介绍
时隔多年仍然逃不掉写C的命运……因为这个任务周期不短还踩了好多坑,必须记录一下了。 任务简单要求就是使用C语言编写一个GPU加速的快速傅里叶变换(FFT) 分为GPU加速的FFT代码改写、未使用GPU的FFT编写、运算速度对比、运算结果测试(与matlab结果对比),只要按照我文章写的顺序做就行 环境所需相关软件下载与安装Visual Studio 2010 要运行C语言代码就要先下载Microsoft Visual Studio 编辑器,我的电脑是Win10系统,但为了与项目环境和大家的使用习惯保持一致,使用的是Visual Studio 2010版本,网上有安装包的下载,这里提供一个我保存的中文版安装包 链接:https://pan.baidu.com/s/12Eyw5Woh11gtP6hyxbpUmQ 提取码:em9h 安装过程还挺顺利的,网上也有很多安装教程,就是安装时间挺久,我安装在D盘,最后应用图标在"D:\Visual Studio 2010\Common7\IDE\devenv.exe",安装在其他路径的只要找到IDE文件夹就能找到。 CUDA7.5 然后需要下载CUDA 来调用GPU。首先保证自己的电脑是有显卡GPU的(GPU和CUDA版本对应关系网上可以找到,这里插一个写挺好的文章链接CUDA和GPU版本对应),我的笔记本是双显卡,独立显卡是NVIDIA GeForce GTX 1660Ti,最高能用CUDA11.7版本的 集成显卡:为电脑基本显卡,在正常情况下电脑会一直使用集成显卡,以降低电脑运行负担,减少散热,提高笔记本使用寿命。 独立显卡:为电脑的高级显卡,多用来运行大型游戏以及部分软件。 要改为优先使用独立显卡的话,就打开NIVDIA控制面板,在左面管理3D设置中全局设置->首选图形处理器->下拉选择高性能NIVDIA处理器,就设置成功了 CUDA和Visual Studio 2010是有版本兼容关系的,在安装好Visual Studio 2010后安装CUDA需要选择对应版本,网上找到Visual Studio 2013是安装的CUDA7.5,但我想装一个能兼容的最高级版,就从9.0试到7.5 (CUDA历史版本下载链接),要是版本不兼容在安装CUDA的时候会出现不兼容的提示,就没办法继续安装,那个图我没保存,但安装的时候看到就能明白(安装教程简单,最好安装在默认路径,网上可找到教程),最终确定兼容版本是CUDA7.5+Visual Studio 2010 环境配置 软件安装完后配置环境,这里我基本是按照这篇文章教程配置的 windows+VS2013+CUDA7.5配置 只有在这篇文章中的第3步我创建项目的方式不太一样 我是打开VS2010创建一个空项目,在源文件中添加一个新建项,选择C++文件,这里注意:不加后缀名生成的源文件是.cpp后缀名的,这是C++代码文件后缀名,使用CUDA的C代码要命名为.cu的格式,不使用CUDA的C代码命名为.c格式 最后最好拿他给的测试代码试跑一下,能成功就算环境配置成功 C语言:不调用库的GPU加速FFT代码开始网上找到这篇文章CUDA实现FFT并行计算 在我简单调试更改后可以正常运行,很开心,我对代码加了些注释,这里把这个能正常运行的代码贴上,分为两个部分代码。 先是需要调用的函数Complex.cu文件,我跟主文件放在一起 #define PI 3.1415926 class Complex { public: double real; double imag; Complex() { } // Wn 获取n次单位复根中的主单位根 __device__ static Complex W(int n) { Complex res = Complex(cos(2.0 * PI / n), sin(2.0 * PI / n)); return res; } // Wn^k 获取n次单位复根中的第k个 __device__ static Complex W(int n, int k) { Complex res = Complex(cos(2.0 * PI * k / n), sin(2.0 * PI * k / n)); return res; } // 实例化并返回一个复数(只能在Host调用) static Complex GetComplex(double real, double imag) { Complex r; r.real = real; r.imag = imag; return r; } // 随机返回一个复数 static Complex GetRandomComplex() { Complex r; r.real = (double)rand() / rand(); r.imag = (double)rand() / rand(); return r; } // 随即返回一个实数 static Complex GetRandomReal() { Complex r; r.real = (double)rand() / rand(); r.imag = 0; return r; } // // 随即返回一个纯虚数 // static Complex GetRandomPureImag() //{ // Complex r; // r.real = 0; // r.imag = (double)rand() / rand(); // return r; // } // 构造函数(只能在Device上调用) __device__ Complex(double real, double imag) { this->real = real; this->imag = imag; } // 运算符重载 __device__ Complex operator+(const Complex &other) { Complex res(this->real + other.real, this->imag + other.imag); return res; } __device__ Complex operator-(const Complex &other) { Complex res(this->real - other.real, this->imag - other.imag); return res; } __device__ Complex operator*(const Complex &other) { Complex res(this->real * other.real - this->imag * other.imag, this->imag * other.real + this->real * other.imag); return res; } };然后是主文件 // 一维FFT #include "cuda_runtime.h" #include "device_launch_parameters.h" #include "Complex.cu" // 自定义的复数数据结构 #include #include #include #include #include #include #pragma comment(lib,"winmm.lib") using namespace std; // 根据数列长度n获取二进制位数 int GetBits(int n) { int bits = 0; while (n >>= 1) { bits++; } return bits; } // 在二进制位数为bits的前提下求数值i的二进制逆转 __device__ int BinaryReverse(int i, int bits) { int r = 0; do { r += i % 2 int tid = threadIdx.x + blockDim.x * blockIdx.x; //threadIdx,线程ID的索引 //blockDim:线程块的维度 //blockIdx,线程块ID的索引 if (tid >= n) return; for (int i = 2; i int k = i; if (n - tid printf("["); for (int i = 0; i if (imag > 0) printf("%.16f+%.16fi", real, imag); else printf("%.16f%.16fi", real, imag); } if (i != N - 1) printf(", "); } printf("]\n"); } int main() { //srand(time(0)); // 设置当前时刻为随机数种子 const int TPB = 1024; // 每个Block的线程数,即blockDim.x,每个块中的线程数量 printf("Error: %s\n", cudaGetErrorString(err)); } // 拷贝回结果 cudaMemcpy(nums, dResult, sizeof(Complex) * N, cudaMemcpyDeviceToHost); //设备到主机:cudaMemcpy(h_A,d_A,nBytes,cudaMemcpyDeviceToHost) // 计算用时 End = timeGetTime(); //printf("结束时间为: %d\n", End); /*printf("After FFT: \n"); printSequence(nums, N);*/ printf("变换用时: %dms\n", End - Start); // 释放内存 free(nums); cudaFree(dNums); cudaFree(dResult); }关于CUDA加速应用程序的教程这篇文章介绍的很详细,看一遍差不多就串起来了 CUDA C/C++ 教程一:加速应用程序 再贴一个看的时候记的一个草稿纸…… 我是看到前辈调用了fftw的库写FFT简直简便了好多,这个库分为32位的和64位的,网上可以下载,我还是贴一下我的下载链接fftw32位和64位库百度网盘下载 链接:https://pan.baidu.com/s/1kILG2Y10KUGh7g1iIOZOqw 提取码:bpgn 我的电脑是使用64位的库,安装教程参考这篇文章FFTW、Eigen库在VisualStudio中的导入和使用 文章里有fftw的详细导入教程,在打开开发人员命令提示符中,我的是下图(因为之前装过vs2015,但不影响,都能用) 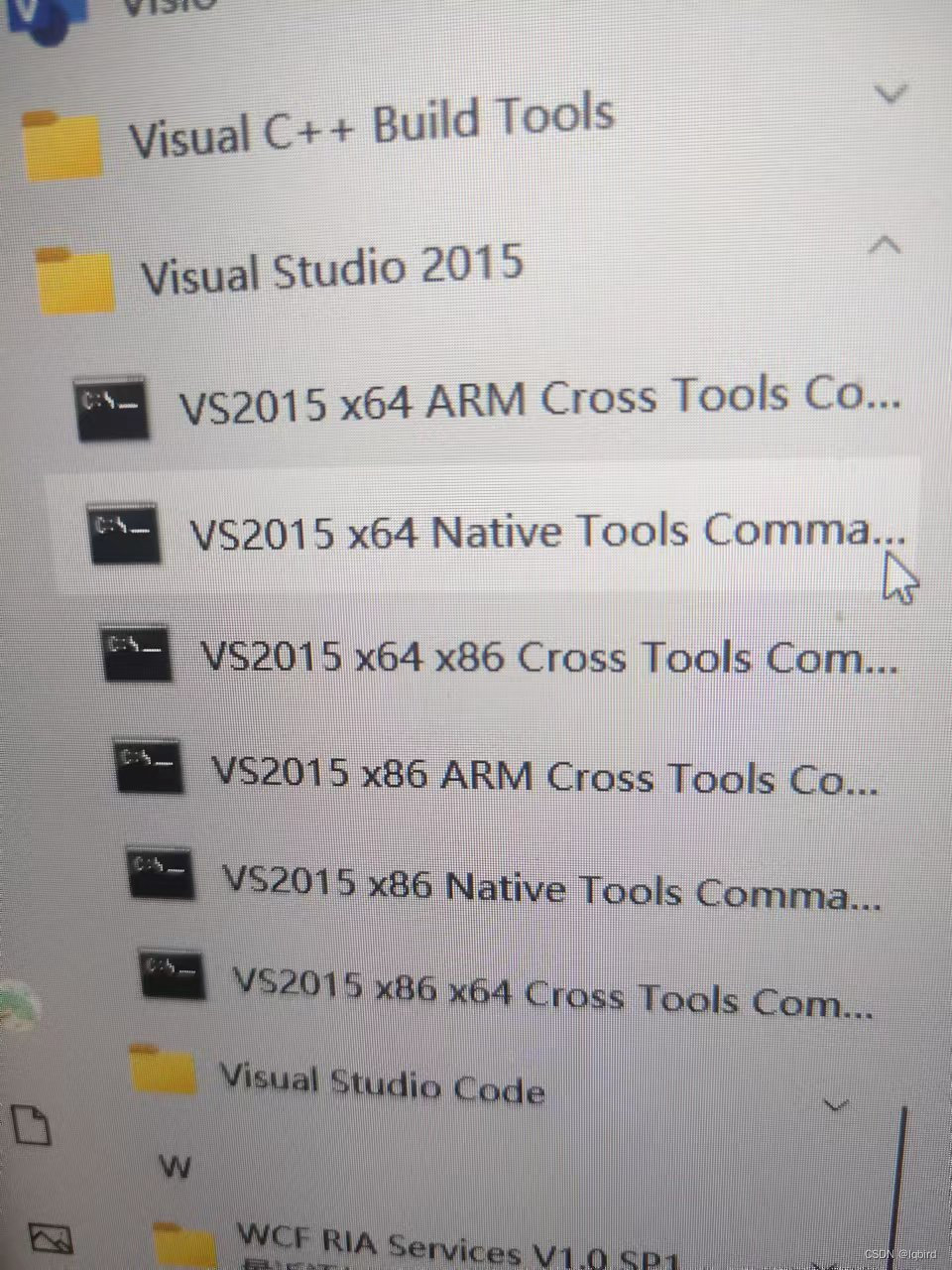
在最后一步放的位置就是下图 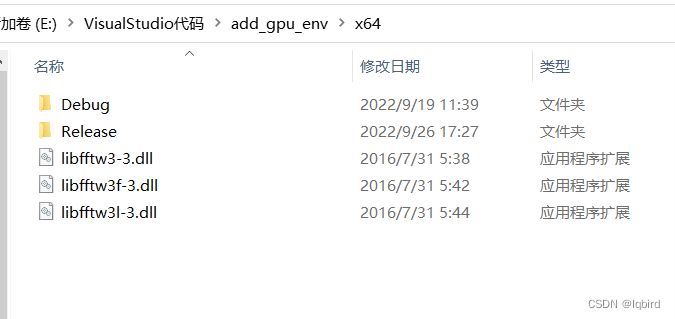
未调用GPU的FFT代码如下: #define _CRT_SECURE_NO_WARNINGS 1 #include "fftw3.h" #include #include #include #include #pragma comment(lib,"winmm.lib") #define N 4000000 void main() { int i; fftw_complex *din, *out; DWORD start, end; fftw_plan p; din = (fftw_complex*)fftw_malloc(sizeof(fftw_complex)*N); out = (fftw_complex*)fftw_malloc(sizeof(fftw_complex)*N); if(din == NULL || out == NULL) { printf("Error:insufficient avaliable memory\n"); } else { for(i=0; i // printf("%f,%fi\n", din[i][0], din[i][1]); //} //printf("\n"); //for(i=0; i\ if ((call) != cudaSuccess)\ {\ printf("Error: %s:%d, ", __FILE__, __LINE__);\ printf("code:%d, reason: %s\n", (call), cudaGetErrorString(cudaGetLastError()));\ exit(1);\ }\ } const double PI = 3.141592653; //void test_FFTW(); int main() { const int NX = 800; const int fs = 4000000; double T = 2e-6; const int BATCH = 1; //DWORD Start, End; int bei = fs/NX; double timebei = T/NX; double aaa = 1.0/NX; double Lk = 1/T; //printf("%f\n", aaa); //printf("%.20lf",timebei); cufftHandle plan; //创建句柄 cufftComplex *data; cufftComplex *data_cpu; double t[NX]; data_cpu = (cufftComplex *)malloc(sizeof(cufftComplex) * NX * BATCH); if (data_cpu == NULL) return -1; CHECK(cudaMalloc((void**)&data, sizeof(cufftComplex) * NX * BATCH)); CHECK(cufftPlan1d(&plan, NX, CUFFT_C2C, BATCH)); //对句柄进行配置,主要是配置句柄对应的信号长度,信号类型,在内存中的存储形式等信息。 //第一个参数就是要配置的 cuFFT 句柄; //第二个参数为要进行 fft 的信号的长度; //第三个CUFFT_C2C为要执行 fft 的信号输入类型及输出类型都为复数; //第四个参数BATCH表示要执行 fft 的信号的个数,新版的已经使用cufftPlanMany()来同时完成多个信号的 fft //Start = timeGetTime(); //输入数据 for (int i = 0; i // //printf("%f %f\n", data_cpu[i].x, data_cpu[i].y); // double mo = sqrt(data_cpu[i].x * data_cpu[i].x + data_cpu[i].y * data_cpu[i].y); // double time = i*timebei; // printf("%.15f %.20f\n", time, mo); //} //Start = timeGetTime(); //数据传输cpu->gpu CHECK(cudaMemcpy(data, data_cpu, sizeof(cufftComplex) * NX * BATCH, cudaMemcpyHostToDevice)); CHECK(cudaDeviceSynchronize()); CHECK(cufftExecC2C(plan, data, data, CUFFT_FORWARD)); //CHECK(cufftExecC2C(plan, data, data, CUFFT_INVERSE) != CUFFT_SUCCESS); //第一个参数就是配置好的 cuFFT 句柄; //第二个参数为输入信号的首地址; //第三个参数为输出信号的首地址; //第四个参数CUFFT_FORWARD表示执行的是 fft 正变换;CUFFT_INVERSE表示执行 fft 逆变换。 //!!!需要注意的是,执行完逆 fft 之后,要对信号中的每个值乘以 1/N //数据传输gpu->cpu CHECK(cudaMemcpy(data_cpu, data, sizeof(cufftComplex) * NX * BATCH, cudaMemcpyDeviceToHost)); CHECK(cudaDeviceSynchronize()); for (int i = 0; i |
 如果在这篇文章第3.f步的项类型里没有找到CUDA C++的话,就右键 【工程】-【生成自定义】-勾选上CUDA 7.5就行,如下图
如果在这篇文章第3.f步的项类型里没有找到CUDA C++的话,就右键 【工程】-【生成自定义】-勾选上CUDA 7.5就行,如下图 
 timeGetTime()计算时间精度比较高,我用了这个,最终计算4*10^6序列长度的数据,这个代码运算时间竟然要七秒多……要知道不用GPU的FFT才160ms左右(这个代码在下面会详细介绍),反正这个运算时间让我直接裂开,减没了输出内容,将配置从Debug改为Release,选用独立显卡运算试了好多都不顶用,又一行又一行看代码,也没看出哪里有毛病。 后来看到说调用GPU运算数据量太少,CPU传到GPU也要耗费时间,使用GPU要运算数据量大的才有优势,好嘛,我就加序列长度,没加到10^8就爆内存了,一看运算时间还是比不用GPU的FFT慢十倍多,我彻底萎掉了。
timeGetTime()计算时间精度比较高,我用了这个,最终计算4*10^6序列长度的数据,这个代码运算时间竟然要七秒多……要知道不用GPU的FFT才160ms左右(这个代码在下面会详细介绍),反正这个运算时间让我直接裂开,减没了输出内容,将配置从Debug改为Release,选用独立显卡运算试了好多都不顶用,又一行又一行看代码,也没看出哪里有毛病。 后来看到说调用GPU运算数据量太少,CPU传到GPU也要耗费时间,使用GPU要运算数据量大的才有优势,好嘛,我就加序列长度,没加到10^8就爆内存了,一看运算时间还是比不用GPU的FFT慢十倍多,我彻底萎掉了。【本文地址】
今日新闻 |
推荐新闻 |