图像版GPT3问世!打破语言与视觉界线,AI将更加聪明 |
您所在的位置:网站首页 › gpt3模型参数量 › 图像版GPT3问世!打破语言与视觉界线,AI将更加聪明 |
图像版GPT3问世!打破语言与视觉界线,AI将更加聪明
|
继 OpenAI 推出史上最强语言模型 GPT-3 后,这家旧金山 AI 研究公司又有新动作。 这次,他们一连推出两款强大的多模态模型 CLIP 和 DALL・E,CLIP 可以对图像进行理解、归类,而 DALL・E 则可以直接借助文本生成图像,简直就是 “图像版 GPT-3”。 OpenAI 在官博中介绍,DALL・E 是 GPT-3 的 120 亿参数版本,如此庞大的数据集,足以让它发挥 “想象力” 创造出那些不同寻常的图像。 你只用简单描述一下想要的图像特征,比如 “一个高质量的龟兔插图” “一只模仿乌龟的兔子” “一只乌龟做成的兔子”,DALL・E 就可以生成以下图像,堪称帮助设计师 “开脑洞” 的神器。  图|DALL・E 生成的 “乌龟 - 熊猫” 图和 “乌龟 - 兔子” 图 该模型一经发表,再次引燃 AI 圈。人工智能和机器学习领域的国际权威学者吴恩达,就用 DALL・E 模型生成了多张蓝色衬衫搭配黑色长裤的图像,并发推文对 OpenAI 表示祝贺,他认为这个成果很酷。 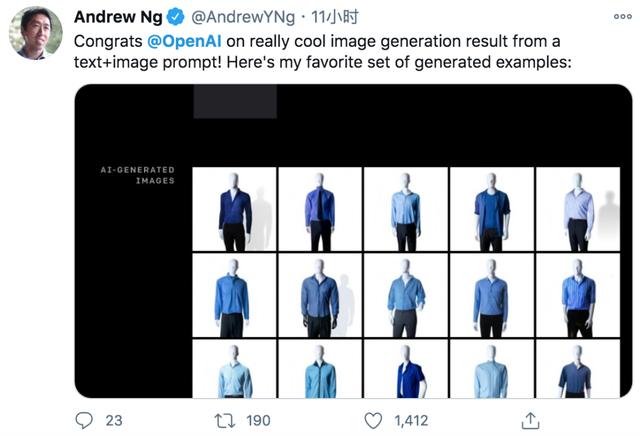 图|CLIP 可以对 DALL・E 中的样本进行重新排序 据悉,OpenAI 计划在下一篇论文中提供有关 DALL・E 架构和训练过程的详细信息。 DALL・E 和 CLIP 是从两个不同的方向来解决这个问题的。CLIP 是对搜集到的图片进行理解、分类,而 DALL・E 是根据文本生成图片,两个模型可以理解为互为逆过程。 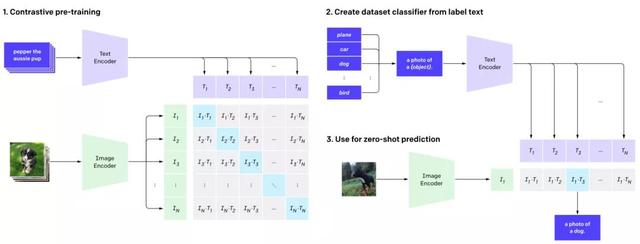 图|CLIP 的预训练过程 据了解,OpenAI 用高达 4 亿的数据集来训练 CLIP,它可以在各种各样的图像上进行训练,主打零样本学习,攻克了计算机视觉领域中数据集昂贵和狭窄的问题。 将语言建立在视觉理解上是让 AI 更加聪明的好方法OpenAI 这次推出的多模态模型成果惊人,但仍然不尽完美。比如 DALL・E 根据 “画着蓝色草莓的彩色玻璃窗” 这一文本创建的图像就有些让人迷惑,不仅掺杂着红色草莓,而且有些图像抽象到看不出是窗户或者草莓。  图|DALL・E 根据 “画着蓝色草莓的彩色玻璃窗” 这一文本创建的图像 再比如,OpenAI 工作人员 Aditya 认为以 “竖琴做成的蜗牛” 为文本生成的图像就很别扭,图像中蜗牛和竖琴以奇怪的方式结合在一起。  图|DALL・E 根据 “穿着芭蕾舞短裙遛狗的小白萝卜” 这一文本生成的图像 尽管如此,大部分 AI 研究人员仍然认为,将语言建立在视觉理解上是让 AI 更加聪明的好方法。 “未来的系统将由这样的模型组成,它们都是朝着那个系统迈进的一步。”OpenAI 首席科学家 Ilya Sutskever 说。 恭喜你,领取到一张面值 0 元的优惠券 只有购买全集内容 0.00 元,才可抵扣使用。 有效期截止于:2020-12-12 23:59 是否立即使用? |
【本文地址】