【Google最新成果】使用新的物理模拟引擎加速强化学习 |
您所在的位置:网站首页 › googleai平台 › 【Google最新成果】使用新的物理模拟引擎加速强化学习 |
【Google最新成果】使用新的物理模拟引擎加速强化学习
|
深度强化学习实验室 官网:http://www.neurondance.com/ 论坛:http://deeprl.neurondance.com/ 来源:GoogleAI Blog 上一篇文章我们介绍了Google AI 开放的【最新】如何降低深度强化学习研究的计算成本(Reducing the Computational Cost of DeepRL), 其通过对强化学习的计算成本进行考量,综合来提升强化学习的计算成本。本篇文章Google AI 再次带来《使用新的物理模拟引擎加速强化学习》,两者从降低成本,加速学习的模拟环境,其实早在2019年的时候伯克利Pieter Abbeel就曾经提出过《Accelerated Methods For Deep Reinforcement Learning》https://arxiv.org/pdf/1803.02811.pdf ,本文再一次将加速作为重点进行了研究,话不多少放内容: 强化学习(RL) 是一种流行的教学机器人导航和操纵物理世界的方法,其本身可以简化并表示为刚体之间的交互1(即,当对它们施加力时不会变形的固体物理对象)。为了便于在实际时间内收集训练数据,RL 通常利用模拟,其中任意数量的复杂对象的近似值由许多由关节连接并由执行器提供动力的刚体组成。但这带来了一个挑战:RL 智能体通常需要数百万到数十亿的模拟帧才能精通简单的任务,例如步行、使用工具或组装玩具积木。 虽然通过回收模拟帧在提高训练效率方面取得了进展,但一些 RL 工具通过将模拟帧的生成分布到许多模拟器来回避这个问题。这些分布式模拟平台产生了令人印象深刻的结果,训练速度非常快,但它们必须在具有数千个 CPU 或 GPU 的计算集群上运行,而大多数研究人员无法访问这些集群。 本文作者展示了一种新的物理仿真引擎“Brax”,它与仅具有单个 TPU 或 GPU 的大型计算集群的性能相匹配。该引擎旨在在单个加速器上高效运行数千个并行物理模拟以及机器学习 (ML) 算法,并在互连加速器的 pod 中无缝扩展数百万个模拟。我们已经开源了引擎以及参考 RL 算法和模拟环境,这些都可以通过Colab访问。使用这个新平台,我们展示了比传统工作站设置快 100-1000 倍的训练。
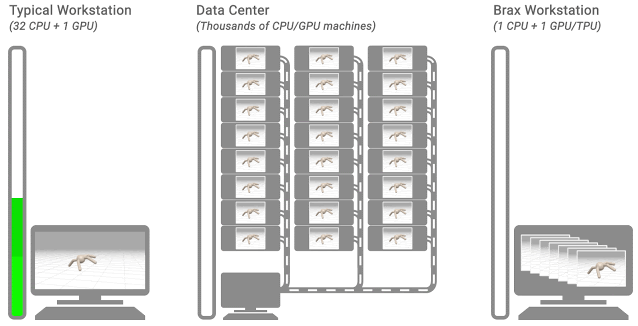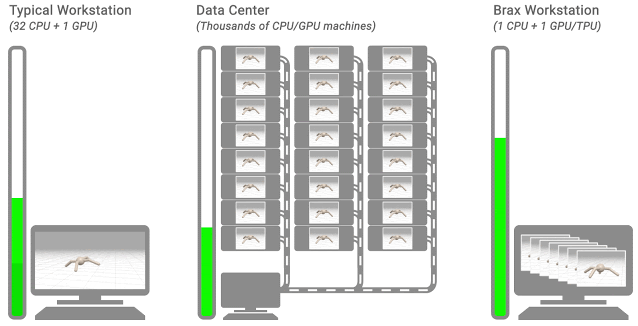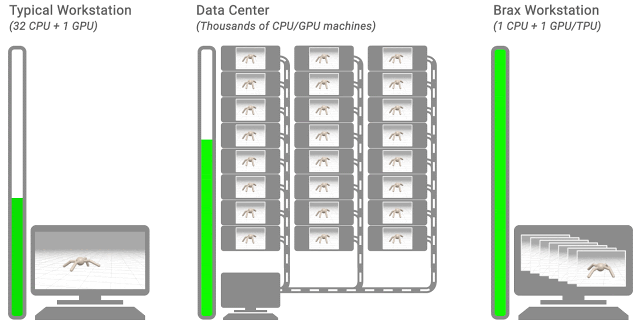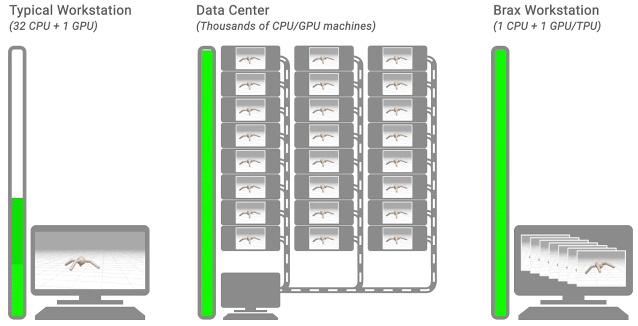
三个典型的 RL 工作流程。该留下显示了一个典型的工作站流程:一台机器上,对CPU的环境,训练需要数小时或数天。在中间显示了一个典型的分布式仿真流程:通过训练模拟耕出上千台机器只需要几分钟。的右示出了BRAX流动:学习和大批量模拟发生并排单个CPU / GPU芯片上。 物理仿真引擎设计机会刚体物理用于视频游戏、机器人、分子动力学、生物力学、图形和动画以及其他领域。为了对此类系统进行准确建模,模拟器集成了来自重力、电机驱动、关节约束、物体碰撞等的力,以模拟物理系统随时间的运动。
仔细研究当今大多数物理模拟引擎的设计方式,有一些提高效率的巨大机会。正如我们上面提到的,典型的机器人学习管道将单个学习器置于紧密反馈中,同时进行许多模拟,但在分析此架构后,人们发现: 这种布局带来了巨大的延迟瓶颈。由于数据必须通过数据中心内的网络传输,因此学习者必须等待 10,000 多纳秒才能从模拟器中获取经验。如果这种体验已经与学习者的神经网络在同一设备上,延迟将降至 |
【本文地址】
今日新闻 |
推荐新闻 |