网络拥塞成因与处理 |
您所在的位置:网站首页 › golangcpu过高原因及解决办法 › 网络拥塞成因与处理 |
网络拥塞成因与处理
|
网络拥塞成因与处理
引言
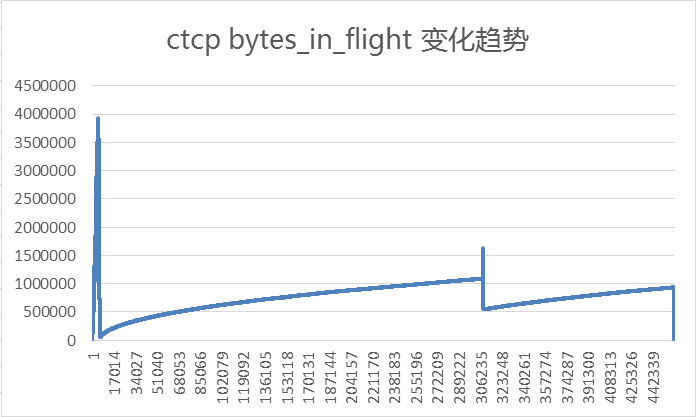
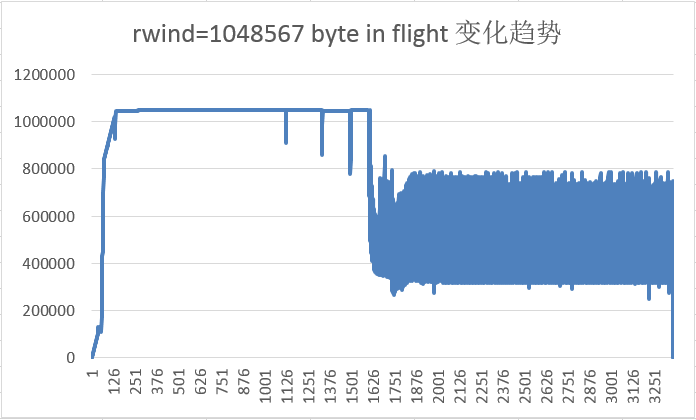
TCP 是最常用的传输层协议之一,为上层协议提供面向连接的、可靠的传输服务。为了尽可能的提供最大的吞吐量,TCP使用滑动窗口和拥塞窗口机制来控制某一时间点投放到网络中的数据量,已达到尽可能占满可用带宽,并且不产生拥塞的目的。网络中通常都会有一个瓶颈(bottleneck),数据包会在瓶颈处积压,甚至被丢弃。因此TCP流量控制的关键就是控制在瓶颈处数据包的积压程度,积压过快就会导致拥塞。拥塞是如何形成?哪些因素引起拥塞?发送方如何感知拥塞?如何缓解拥塞?本文将讨论这些问题。 Byte in flight在展开本文之前,先介绍一个概念——Byte in flight 一个比较形象的翻译“在途字节数”1,指的是已经发送,但尚未收到ACK确认的字节数,约等于当前在网络中传输与积压的数据包的字节数的总和。Byte in flight 的大小直接影响瓶颈处数据包的积压程度。根据滑动窗口的概念可以知道Byte in flight的大小受限于发送窗口2(Byte in flight byte_in_flight.txt 将得到的数组绘制成折线图如下: 上文仓库的例子中可以看到,当经理将搬运工人的数量(发送窗口)降到排队区大小100人时,不再会发生拥塞,100这个值,我们定义为是路径中粗略的拥塞点,也就是网络中发生拥塞时的在途字节数就是该时刻的拥塞点,此时发送方发送的数据填满路径的带宽管道。可以推测,只要发送方保证任何时刻发送的未确认的数据量小于该时刻的拥塞点,就不会产生拥塞。真实的TCP传输过程中,发送方不大可能预知拥塞点的大小,并且拥塞点还不断的变化,因此发送方只能相对保守的试探,如图4 当发送方将窗口缓慢增大到一定值时(第306235包左右),再次发生拥塞,如果横坐标足够长,我们可以看到每次发送方将窗口增大到一个值时,还会再次发生拥塞,我们会发现这些值可大致连成一个与横坐标平行的直线,这个直线与纵坐标相交的值,也就是平均发生拥塞时的byte in flight,可以粗略认为是拥塞点。 当然估算拥塞点不需要这么麻烦,相应的计算方法,本文就不介绍了。这里介绍一下利用估算拥塞点,消除拥塞。原理很简单,确保发送方的发送窗口永远不高于拥塞点的值,就可避免拥塞,可以通过修改接收窗口等方法限制发送窗口。下图5是修改接收窗口到拥塞点以下时,byte in flight的变化趋势,用图4同样方法导出的数据:
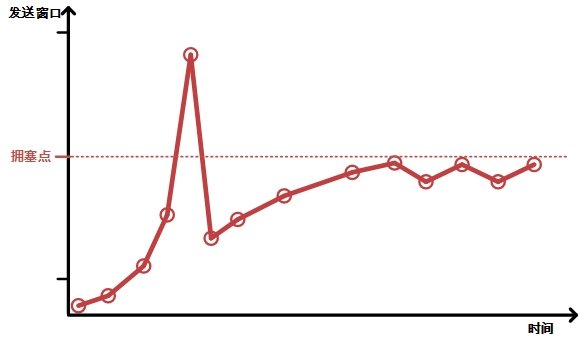
发送方感知到拥塞时,必须采取动作缓解拥塞,发送方如何感知拥塞的发生呢?一种方法就是根据丢包情况。像图2中一样,工人在桥边被挤下水,返回重新打包货物,此时经理便意识到发生拥塞了。可是网络传输过程中,数据包丢弃了不可能返回通知发送方,该如何发现丢包呢?TCP结合计时器和ACK机制来判断,简单来说TCP先预估发送方到接收方的往返时间,这个值称为SRTT(Smoothed Round Trip Time),根据预估往返时间计算出一个最大等待时间(RTO),当发送的数据在最大等待时间内未收到接收方确认(想想 搬运工人没有在规定的时间返回),就断定发生了丢包,必须重传,并且降低发送窗口,图4第一个谷底可以看到类似情景。关于RTO的计算方法很多,这里不详细介绍,请参照RFC-793、RFC-2988、RFC-6298等文献。 丢包发生就一定代表拥塞吗?考虑一下这种情况:如图2 假设所有货物都贴有编号,搬运工人按顺序搬运货物,一名搬运工人在过桥期间不小心掉下水,后续的工人正常将货物搬运到了仓库B,仓库B的经理入库货物时发现货物未按照顺序到达,便立即打电话通知仓库A经理,此时仓库A经理需要减少搬运工人吗?肯定是不需要的,因此为并没有发生拥塞。网络传输过程中也有类似现象,比如网线质量不好,导致一数据帧因为CRC校验错误被丢弃。接收方发现到达的数据乱序后,立即发送duplicate ack通知发送方数据包乱序了,当累积了三个duplicate ack 后发送方快速重传数据,不用等到超时重传。当然发送方为了保险,会主动减少发送窗口,但不会像发送超时重传那样大幅度减少,图4 第二个谷底可以看到类似情景。 超时重传对吞吐量的影响比较大,因为大量超时重传已明确表明网络瓶颈处发生了拥塞,发送方一般会将发送窗口降到一个相当低的值,重新缓慢增长发送窗口,以避免更严重的拥塞发生。高延迟的网络中发送窗口增长更加缓慢,少量的超时重传都会对吞吐量造成显著影响。因此多数TCP的拥塞避免算法会尽量避免超时重传,或减轻超时重传的影响。 基于延时(delay-besed)基于丢包的拥塞避免有一个弊端是只有当拥塞发生以后发送方才能感知,然后采取动作。有没有办法在拥塞发生之前就使发送方提前感知,然后采取动作,从而避免拥塞后发送窗口大幅下降造成的吞吐量下降呢? Brakmo和Peterson在1995年提出了一种使用RTT(Round Trip Time)预测拥塞的拥塞控制算法,称之为TCP Vegas。TCP vegas 里面的主要思想就是通过观察RTT的变化来判断当前网络是比较畅通还是比较拥堵,理由是持续增长的RTT被认为是发生拥塞的先兆。 怎么回事呢?回到图2,假设只有一名搬运工人搬运货物,这名工人在畅通的情况下将货物从仓库A搬运到仓库B,再从仓库B返回,往返时间(RTT)为5min,经理开始逐步增加工人,增加到一定程度后,工人就会在桥边排队,由于需要加上排队的时间,此时工人往返时间一定会大于5min,根据工人往返时间,经理就可以大致判断桥边等待队伍的长度,这里面引入几个值: 1)basertt:basertt 记录网络传输路径上的最小rtt,这里面就是5min; 2)srtt:平滑rtt,综合历史rtt和当前rtt计算出的值,计算公式这里不叙述了,为了简单,这里就理解为当前的rtt; 3)expected:网络理想状态下的吞吐量; 4)actual:当前真实的吞吐量; 当经理派出了100名工人,此时工人的往返时间增加到10min(srtt)。经理可以通过下面方法计算,桥边等待队伍的长度: expected(throughput)=wnd(发送窗口)/basertt=100/5=20 actual(throughput)=wnd/srtt=100/10=10 diff=(expected-actual)*basertt=(20-10)×5=50diff就是队列长度,即50人。 TCP vegas 采用相同的方法计算瓶颈路径前的队列长度。并规定diff的上限下限,作为判断当前网络状况的参考。当diff 大于上限时发送方主动减小发送窗口,当diff 小于下限时,发送方适当增加发送窗口。 基于延时的弊端根据前文的描述,理论上基于延时的拥塞避免算法可以真正的“避免”拥塞的发生,当发送窗口增长拥塞点附近时,RTT会增大,发送方会据此适当调整发送窗口,最终表现为发送窗口维持在拥塞点附近,在延时高的高速网络上吞吐量提升明显。可以估计基于延迟的TCP, 发送窗口与时间的变化关系会类似于下图: 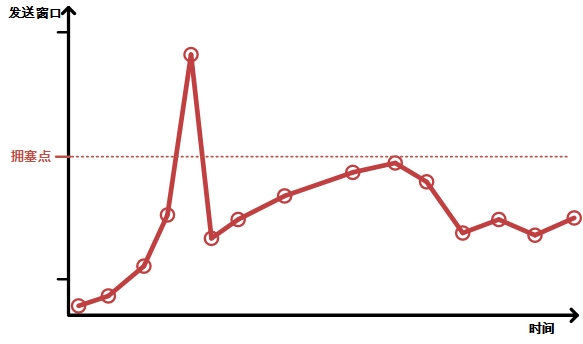 图7
折中方案
图7
折中方案
既然delay-besed 和loss-besed 拥塞避免机制都有缺点,能不能将二者结合在一起呢?实际上这种算法现在已经大规模应用了,从Windos 7 与 Windos Server 2008 开始,微软系统内核就默认采用一种全新的TCP——CTCP(Compound TCP),可在CMD使用命令 netsh interface tcp show global查看,CTCP的核心设计理念是在传统TCP的loss-based拥塞避免算法基础上添加一个可伸缩的delay-based 组件,以期既能实现delay-based的算法的优点,并且在同传统TCP竞争瓶颈带宽时保证公平性。CTCP的算法比较复杂,以后再详细阐述。 出自《Wireshark 网络协议分析的艺术》; ↩发送窗口,即TCP发送方维护的窗口,发送窗口=min[接收窗口,拥塞窗口],滑动窗口与拥塞窗口的算法本文不再详细介绍; ↩ |
【本文地址】
今日新闻 |
推荐新闻 |