数据挖掘之子图模式 |
您所在的位置:网站首页 › gSpan算法代码 › 数据挖掘之子图模式 |
数据挖掘之子图模式
|
文章目录
子图模式概述
图和子图
频繁子图
类Apriori算法
关联规则
置信度与支持度
类Apriori算法步骤
候选产生
顶点增长
边增长
候选剪枝
如何处理图同构
支持度计算
候选删除
类Apriori算法总结
gSpan算法
DFS编码
确定唯一DFS编码
gSpan最右路径扩展规则
gSpan算法步骤
gSpan算法示例
gSpan算法小结
子图模式概述
图和子图
图的结构很简单,就是由顶点V集和边E集构成,因此图可以表示成:G=(V,E)。 子图是一个图中的一部分,其可以表示为:
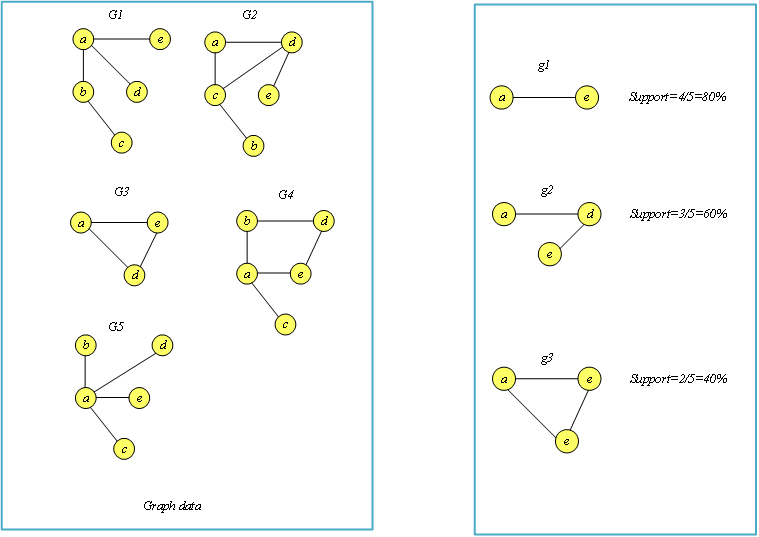
如何判断某子图是频繁子图? 支持度:给定图的集族ς, 子图g的支持度定义为包含它的所有图所占的百分比。 有了支持度的定义就可以计算某子图在图集中的占比,如此便可来规定频繁子图。
对频繁子图的搜索与查找也就称之为频繁子图挖掘。频繁子图挖掘(frequent subgraph mining) : 给定集合 ς 和支持度阈值 minsup,频繁子图挖掘的目标是找出使得所有 s(G) ≥ minsup 的子图G。 目前常用的两种频繁子图挖掘的算法为 Apriori 与 gSpan。接下来将分别介绍无向有权图的 Apriori 与 gSpan算法。 类Apriori算法Apriori algorithm是关联规则里一项基本算法。由Rakesh Agrawal 在 1994年提出的,详细的介绍来自于《Fast Algorithms for Mining Association Rules》。 关联规则关联规则形如“如果…那么…(If…Then…)”,前者为条件,后者为结果。 关联规则的目的在于在一个数据集中找出项之间的关系,也称之为购物篮分析 (market basketanalysis)。 例如,购买鞋的顾客,有10%的可能也会买袜子,60%的买面包的顾客,也会买牛奶。这其中最有名的例子就是"尿布和啤酒"的故事了。
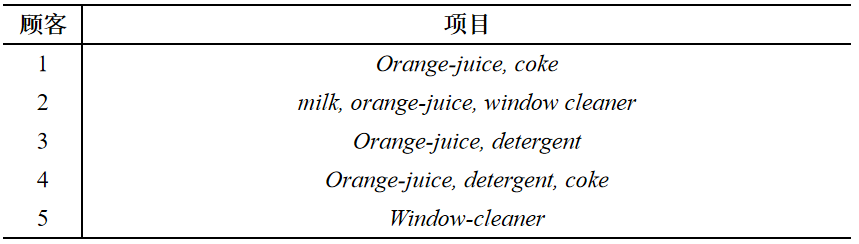
假设有如下表的购买记录
按照关联规则进行整理得到下表:
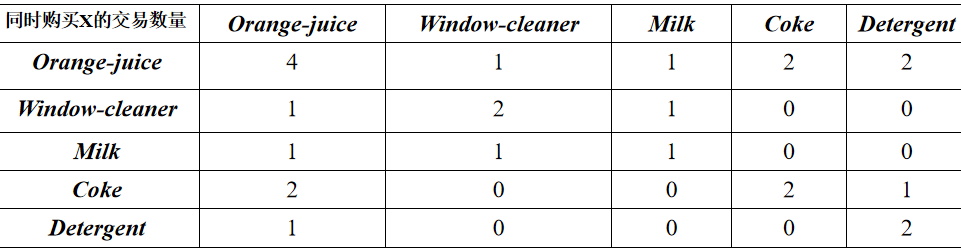
置信度:置信度表示了这条关联规则有多大程度上值得可信。 设条件的项的集合为A,结果的集合为B。 置信度计算在A中,同时也含有B的概率,即Confidence(A==>B)=P(B|A)。 例如计算“如果Orange-juice则Coke”的置信度。由于在含有Orange-juice的4条交易中,仅有2条交易含有Coke,其置信度为0.5。 支持度:支持度计算在所有的交易集中,既有A又有B的概率。 Support(A and B)=P(AB) 例如在5条记录中,既有Orange-juice又有Coke的记录有2条。则此条规则的支持度为2/5=0.4。 现在这条规则可表述为,如果一个顾客购买了Orange-juice,则有50%的可能购买Coke 。而这样的情况(即买了Orange-juice会再买Coke )会有40%的可能发生。 类Apriori算法步骤 候选产生:合并频繁(k-1)子图对,得到候选k-子图。 |



【本文地址】
今日新闻 |
推荐新闻 |