中文分词的原理、方法与工具 |
您所在的位置:网站首页 › fruitstudiomobile中文 › 中文分词的原理、方法与工具 |
中文分词的原理、方法与工具
|
海德格尔说“词语破碎处,无物可存在”。中文句子不像英文那样的词与词之间有显示空格边界,使得词和词组边界模糊。 为了让计算机更容易理解文本,通常中文信息处理的第一步是中文分词。中文分词是在中文句子中的词与词之间加上边界标记。 本文首先介绍词、词组、句子、语言模型等基本概念及基本原理,比如:短语结构语法(PSG)模型、n元语法模型( n-gram)、神经网络语言模型(NNLM)、Masked Language Model(MLM); 接着介绍主要中文分词方法,比如最短路径分词、n元语法分词、由字构词分词、循环神经网络分词、Transformer分词; 然后介绍当前主要使用的分词工具,比如jieba、HanLP、FoolNLTK; 最后抛出个人认为垂直领域如何中文分词及发展趋势。 文章目录如下: 一、中文分词原理1、中文分词2、词、词组、句子3、语言模型4、中文分词发展简史二、中文分词方法1、最短路径分词2、n元语法分词3、由字构词分词4、循环神经网络分词5、Transformer分词 三、中文分词工具1、jieba2、HanLP3、FoolNLTK 四、总结1、规则 VS 统计 VS 深度2、垂直领域中文分词3、中文分词发展趋势 直接上PPT  中文分词的原理、方法与工具 中文分词的原理、方法与工具为什么要中文分词?  为什么要中文分词?一、中文分词原理 为什么要中文分词?一、中文分词原理 中文分词原理的目录 中文分词原理的目录1、中文分词 什么是中文分词? 给出定义:中文分词是在中文句子中的词与词之间加上边界标记。  什么是中文分词? 什么是中文分词?中文分词总的来说就两种方法:一种是由句子到词;另一种是由字到词。  中文分词的基本概念、语言模型 中文分词的基本概念、语言模型中文分词本质:划分词的边界  中文分词本质:划分词的边界 中文分词本质:划分词的边界同时,中文分词也面临着分词规范、歧义切分、新词识别等挑战。  中文分词面临 中文分词面临2、词、词组、句子 什么是词?什么是词组?什么是句子? 搞懂这些基本概念,更容易处理它们。  什么是词?什么是词组?什么是句子? 什么是词?什么是词组?什么是句子?3、语言模型 什么是语言模型? 由语音、词汇、语法构成的交流模型。  语言模型 语言模型短语结构语法( Phrase Structure Grammar, PSG)  语言模型——PSG 语言模型——PSGn元语法模型( n-gram)  语言模型—— -gram 语言模型—— -gram常见的n元语法模型如下表所示:  常见的n元语法模型 常见的n元语法模型神经网络语言模型(NNLM)  神经网络语言模型(NNLM) 神经网络语言模型(NNLM)Masked Language Model(MLM)  Masked Language Model(MLM) Masked Language Model(MLM)4、中文分词发展简史  中文分词发展简史二、中文分词方法 中文分词发展简史二、中文分词方法中文分词代表方法有最短路径分词、n元语法分词、由字构词分词、循环神经网络分词、Transformer分词等。  中文分词方法的目录 中文分词方法的目录1、最短路径分词  最短路径分词 最短路径分词2、n元语法分词  n元语法分词 n元语法分词举一个n元语法分词的例子。  一个n元语法分词的例子 一个n元语法分词的例子3、由字构词分词  由字构词分词 由字构词分词常用的三类由字构词 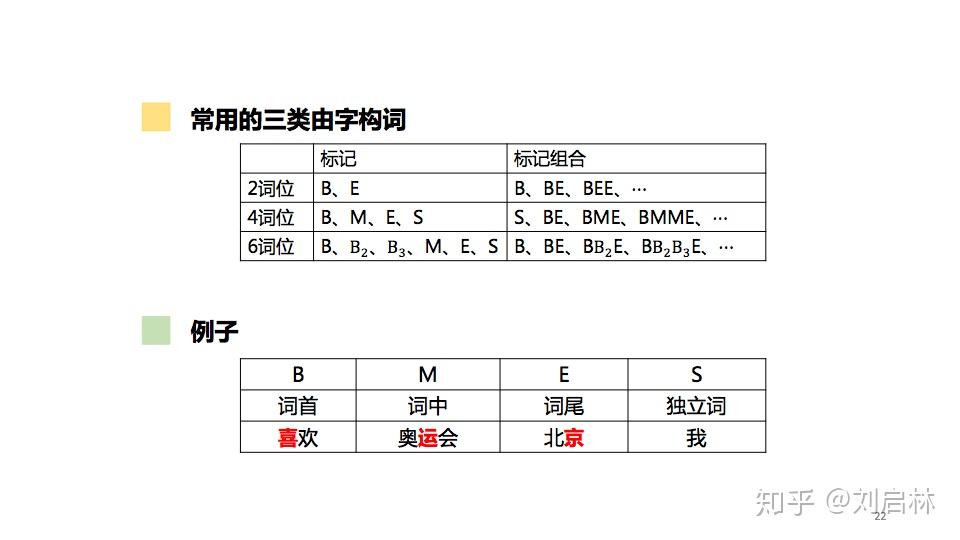 常用的三类由字构词 常用的三类由字构词4、循环神经网络分词  循环神经网络分词 循环神经网络分词循环神经网中文分词有:LSTM、LSTM+CRF、BiLSTM-CRF、LSTM-CNNs-CRF等。 循环神经网络中文分词的结构图如下:  循环神经网络中文分词的结构图 循环神经网络中文分词的结构图5、Transformer分词 2014年,Google在《Recurrent Models of Visual Attention》论文中提出Attention机制。 2017年,Google在《Attention is All You Need》论文中提出Transformer模型。  Transformer分词 Transformer分词2019年,邱锡鹏在《Multi-Criteria Chinese Word Segmentation with Transformer》论文中提出Transformer中文分词模型如下图所示: 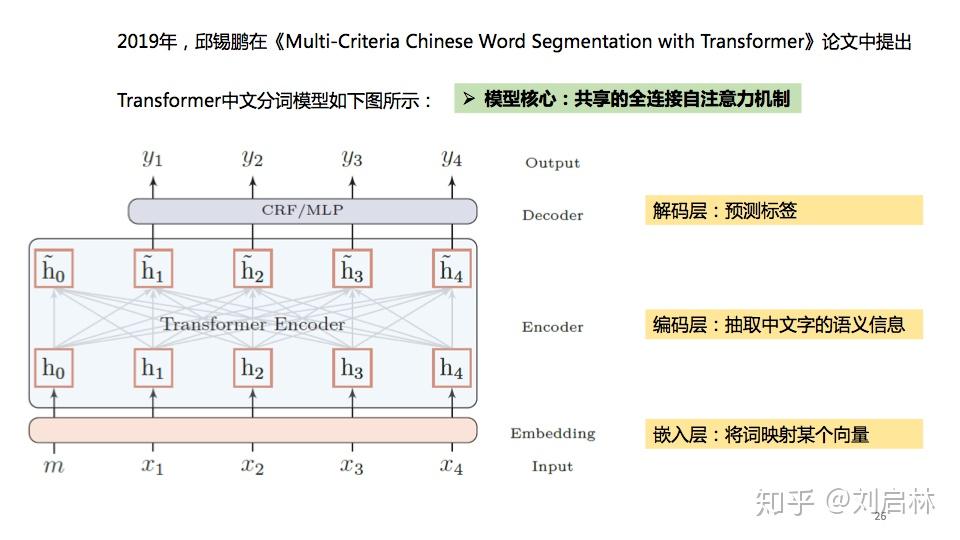 Transformer中文分词模型 Transformer中文分词模型Transformer中文分词学习结果如下图所示: 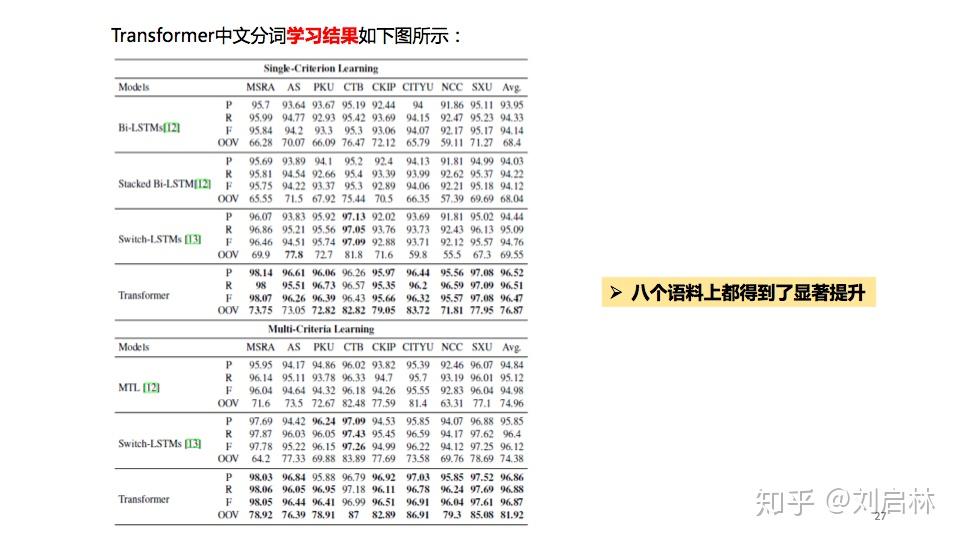 Transformer中文分词学习结果三、中文分词工具 Transformer中文分词学习结果三、中文分词工具中文分词工具工具很多,这里我们选择使用较多,关注度较高的jieba、HanLP、FoolNLTK等来介绍。  中文分词工具的目录 中文分词工具的目录jieba、HanLP、snownlp、FoolNLTK、LTP、THULAC等分词工具概览。 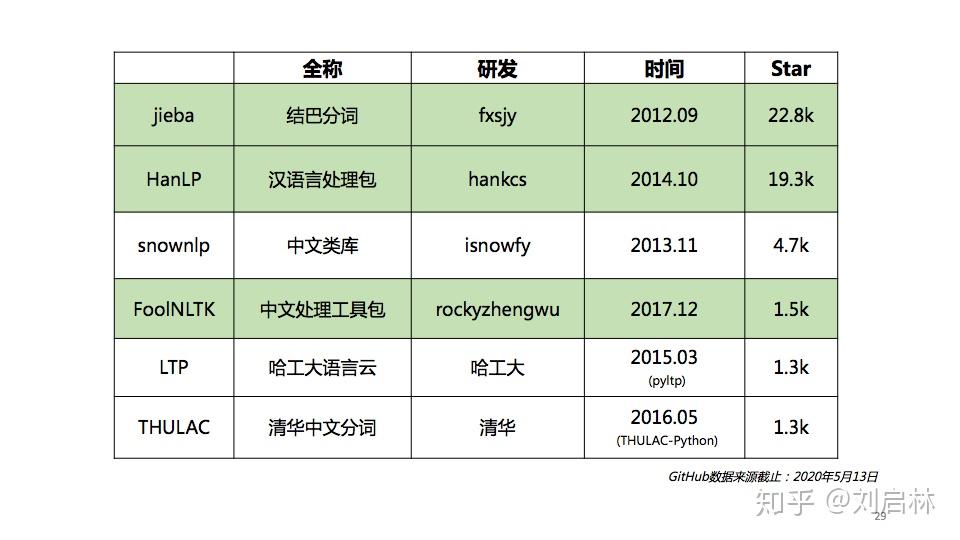 jieba、HanLP、snownlp、FoolNLTK、LTP、THULAC等分词工具概览 jieba、HanLP、snownlp、FoolNLTK、LTP、THULAC等分词工具概览1、jieba jieba概述  jieba概述 jieba概述jieba分词原理:HMM(隐马尔可夫模型)。更多HMM内容可参考:  HMM中文分词的图结构 HMM中文分词的图结构jieba中文分词代码实例如下: # jieba 0.42.1 import jieba string = '我喜欢北京冬奥会' print(",".join(jieba.cut(string)))2、HanLP HanLP概述 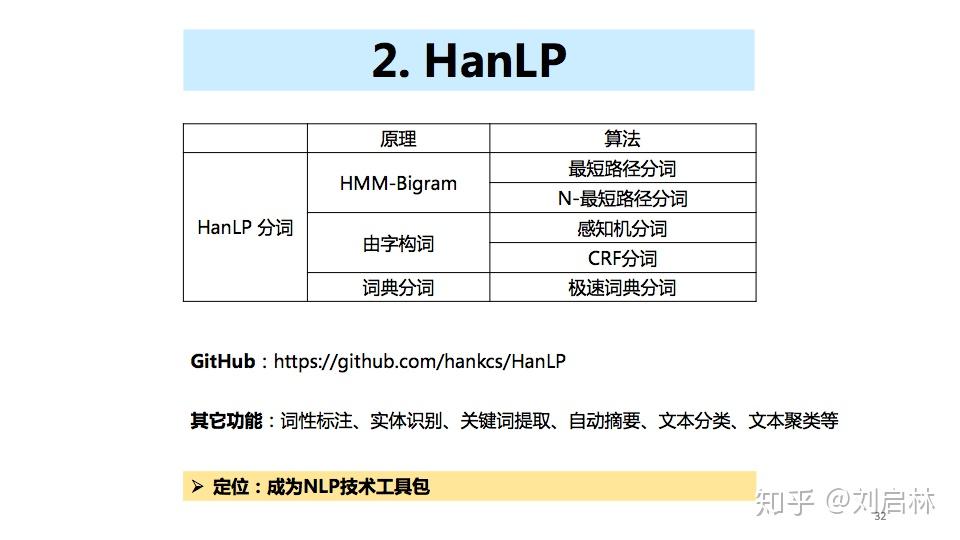 HanLP概述 HanLP概述HanLP实现的基于CRF分词原理如下: 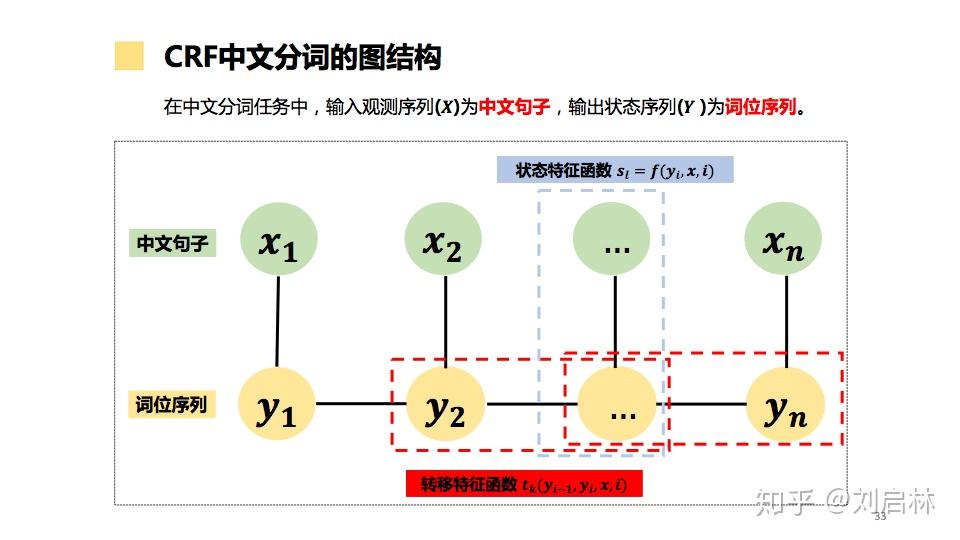 CRF中文分词的图结构 CRF中文分词的图结构HanLP中文分词代码实例如下: # HanLP1.7.7 from pyhanlp import * string = '我喜欢北京冬奥会' HanLP.Config.ShowTermNature = False print(HanLP.segment(string))3、FoolNLTK FoolNLTK概要  FoolNLTK概要 FoolNLTK概要FoolNLTK分词原理如下: BiLSTM-CRF模型架构 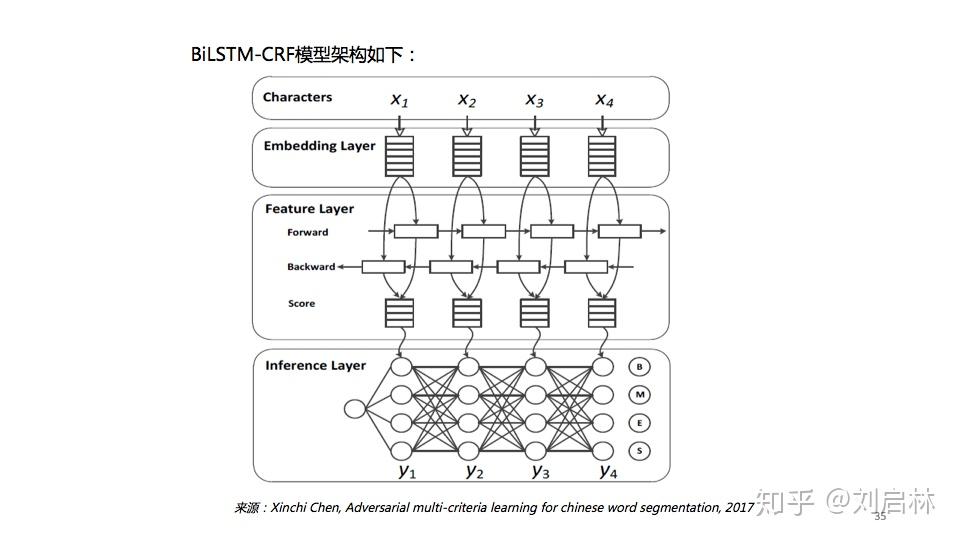 BiLSTM-CRF模型架构 BiLSTM-CRF模型架构各分词工具对比表如下:  分词工具对比表 分词工具对比表中文分词工具使用总结如下:  中文分词工具使用总结四、总结 中文分词工具使用总结四、总结 总结的目录 总结的目录1、规则 VS 统计 VS 深度 基于规则分词、基于统计分词与基于深度学习分词的对比。  基于规则分词、基于统计分词与基于深度学习分词的对比 基于规则分词、基于统计分词与基于深度学习分词的对比2、垂直领域中文分词 垂直领域的中文分词现状与挑战。  垂直领域中文分词 垂直领域中文分词3、中文分词发展趋势  中文分词发展趋势 中文分词发展趋势中文分词呈现两个发展趋势: 1、越来越多的Attention方法应用到中文分词上。 2、数据科学与语言科学融合,发挥彼此优势。 由于当前自己的能力和水平的限制,我的可能是错的,或者是片面,这里抛砖引玉,期待与您一起交流探讨。参考文献: 1、中国社会科学院语言研究所词典编辑室, 现代汉语词典(第7版), 商务印书馆[M], 2017.01 2、宗成庆, 统计自然语言处理(第2版), 清华大学出版社[M], 2013.08 3、黄昌宁, 赵海, 由字构词——中文分词新方法, 中国中文信息学会二十五周年学术会议[J], 2006 4、姜维, 文本分析与文本挖掘, 科学出版社[M], 2018.12 5、Xipeng Qiu等, Multi-Criteria Chinese Word Segmentation with Transformer, 2019.06 |
【本文地址】