c++安全编程指南 |
您所在的位置:网站首页 › free的用法归纳 › c++安全编程指南 |
c++安全编程指南
|
《c++安全编程指南》
前言
随着信息技术与相关产业的发展,人类的工作、学习与生活越来越依赖于计算机软件和网络,但与 此同时安全事件层出不穷,网络攻击造成的损失也与日俱增。比如国际上发生的臭名昭著的“棱镜门”事件。“信息战士”的工作使受害国家的安全都受到了威胁,更不用说窃取普通公民的网上交 易信息以及个人信息了。然而,这些信息与人们的生产、生活息息相关,信息的盗用给人们造成了财产 和无形的损失。这使人们比以往更加关注安全,逐渐意识到完善网络安全势在必行,各级政府以及各企 事业单位在安全方面的投入也在不断提高。在此情境下,撰写安全编码指南。 我曾经编写过C和C++代码,对这两门编程语言都深有感触。C和C++语言是实现许多操作系 统和服务器软件的开发语言,支撑着许多为数以万计的用户提供服务的重要应用程序,必须坚实可靠 才能持续不断地正常运行。特别是移动互联网的发展,大大增加了应用程序的种类和数量,不安全的 应用程序也会造成安全漏洞迅速地大面积传播。因为C和C++语言产生的年代较早并且设计为与底 层设备打交道,所以对效率要求很高,这使得这两种语言存在固有的安全问题,虽然语言标准的制定 者意识到了这个问题,并提出了许多更加安全的解决方案,但大量的遗留代码中仍然包含不安全的实 现和库函数调用,这些都会不时引发安全问题。许多安全检测工具可以帮助人们检查出代码的漏洞, 但却不能帮助他们把它们修改正确,而且对c语言中某些功能理解上的偏差往往会导致误用。总而言 之,编写安全代码完全是开发人员的责任,而开发人员若要具备这方面的技能,就得掌握相关的理论 并在实践中自觉加以运用。 本指南包含以下各章。 第1章:对为何C和C++程序中存在如此多的漏洞发表 看法。 第2章:描述C和C++中的字符串操作、常见的安全缺陷以及由此导致的漏洞 第3章:讨论整数安全问题(即与整数操作相关的安全主题),包括整数溢出、符号错误以及截 断错误等。 值得注意的是,这些是常见的,最容易犯的错误,我对他们进行了归纳总结,还有一些比如任意内存写(arbitrary memory write)漏洞、动态分配的缓冲区溢出、写入已释放内存,以及重复释放(double-free)漏洞、格式化输出函数的正确和错误的用法、并发和可能导致死锁、竞争条件和无效的内存访问序列的漏洞、文件I/O相关的常见漏洞等由于我的水平有限,就不在这说了。 第 1 章 1.1 安全概念计算机安全(computer security)指的是阻止攻击者通过未授权访问或未授权使用计算机 和网络达到目的。安全包含开发和配置两方面的元素。开发安全要求具有安全 的设计和无瑕疵的实现;配置安全则要求系统和网络被安全地予以部署以免遭攻击。两种安 全不分主次,属于鸡和蛋的问题,不过有一点是确定无疑的:二者缺一不可。原因在于,就 算能够开发岀极其安全的软件,最后仍然需要对其进行安全的部署和配置。如果部署阶段的 工作没有做好,即便设计为最安全的代码也会给攻击者以可乘之机。这种情形与最终用户要 求软件易使用、易配置、易维护同时价格低廉的目标是矛盾的。 程序是由软件组件(software component)和定制开发的源代码(source code)构建而成的。 软件组件是组成大型软件程序的元素[Wallnau 2002]o软件组件包括各种共享库,例如,动态 连接库(DLL)和ActiveX控件、EJB (Enterprise JavaBeans)以及其他一些组合单元。软件组 件在运行时可静态或动态链接到程序中。然而,软件组件并不是由最终用户直接执行的,它 只不过是一个大程序中的一个组成部分而已。因此,软件组件是不可以有漏洞的,因为它不 可能脱离程序的上下文而独立运行。源代码指的是程序指令集的原始形式。“源”这个词将代 码与它可能具有的其他任何形式(例如,目标代码和可执行代码)区分开。虽然有时也需要对 代码的“非源”形式(例如,当集成某些不包含源代码的第三方组件时)进行分析,但我们在 这里只关注“源”形式的代码,因为本指南的目标读者主要是软件开发人员。
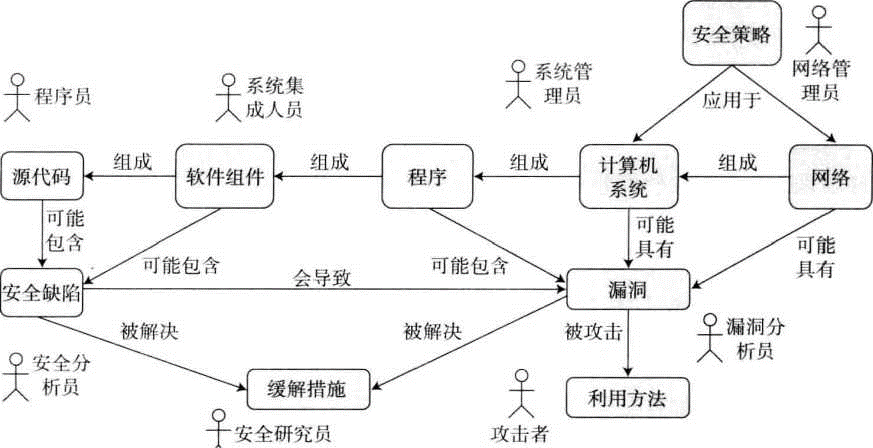
如图展示了这些安全概念之间的关系。 1.1.1安全策略安全策略,一套规则和操作,规定了系统或组织如何提供安全的服务以便保护其敏感和关键的系统 资源。 安全策略可以是显式的,也可以是隐式的。文档化的、众所周知的、显著的强制性安全 措施有助于规范预期的用户行为。当然了,一个组织缺乏明确的安全策略并不意味着会因为 没有策略可供违反而免受攻击。 1.1.2安全缺陷软件工程很早就关注软件瑕疵(software defect)的消除问题。软件瑕疵是人类思维错误 (包括疏忽)被编码到软件中的结果。功能缺陷可能在软件研发周期中的任何时刻产生。例如, 一个已部署的产品中的瑕疵可能源于讹传的需求或对需求的误解。并非所有软件瑕疵都有安全风险,只有那些确实有安全风险的软件瑕疵才称为安全缺陷。 如果我们认同安全缺陷就是软件瑕疵的说法,那我们也必须认同只要消除软件中的所有瑕疵, 就可以消除所有安全缺陷。这个前提是软件工程和安全程序设计之间关系的基础。伴随着软 件质量(可以用每千行代码中所包含的瑕疵的数量进行度量)的提高,软件的安全性也随之提 高。因此,很多设计用来消除软件瑕疵的工具、技术和过程也可以用来消除安全缺陷。 尽管如此,仍然有很多安全缺陷得不到检测,因为传统的软件开发方法很少假定攻击者 的存在。举个例子,软件测试通常仅验证对于合理范围内的用户输入应用程序是否有正确的 行为。遗憾的是,攻击者从来不按常理出牌,他们通常会花费大量的时间寻找能够危害系统 的输入条件。要想按照漏洞可能导致的风险对安全缺陷进行评估并将其按优先级排序,就必 须对现有的工具和方法进行扩展或补充,以假设攻击者的存在。 1.1.3漏洞指允许攻击者违反显式或隐式的安全策略的一组条件。并非所有的安全缺陷都会导致漏洞(vulnerability)。然而,如果一个安全缺陷会导致输入 数据(例如,命令行参数)越过安全界限进入到程序中,那该安全缺陷就会导致软件漏洞。当 包含安全缺陷的程序自身拥有比执行程序的用户更高的执行权限时,或者当程序被网络服务 所使用(输入数据通过网络连接传入)时,这种情况就可能会发生。 1.1.4漏洞利用软件中的漏洞是可以利用(exploitation)的。利用的形式多种多样,包括蠕虫、病毒和木 马等。 漏洞利用代码的存在让安全分析人员感到不安。因此,需要根据利用代码的目的对其进 行有效的区分。例如,验证性(proof-of・concept)的漏洞利用代码是为了验证某漏洞确实存在 而开发的。验证性的漏洞利用代码是必要的,因为有时软件产商会因怕造成不好的影响或者 不愿意负担提供补丁程序所带来的经济开销,而不愿承认软件漏洞的存在。此外,有时漏洞 很复杂,需要有验证性的利用代码向厂商证实该漏洞确实存在。 如果适当地加以管理,验证性的漏洞利用代码就是有益的。然而,我们也很容易发现, 一旦那些代码被心怀不轨的人所利用,它们将会迅速地变成蠕虫、病毒或者攻击者手中其他 的凶器。 虽然安全研究者喜欢区分不同类型的漏洞利用,可实际上,所有的利用代码都只不过是 经过编码了的知识,而知识就是力量。理解程序如何被利用是一个颇有价值的手段,它可以 帮助程序员开发安全的软件。然而,针对已知漏洞而传播的相应的利用代码会危害每个人的 利益。 1.1.5缓解措施缓解措施是指针对软件缺陷的解决方案,或者用于防止软件漏洞被利用的应急方案。在 源代码的层次,缓解措施可以是非常简单的操作,例如,使用一个带边界检查的字符串复制 函数取代不带边界检查的字符串复制函数。而在系统或网络的层次,一个缓解措施可能就是 关掉某个端口或者对流量进行过滤,使攻击者无法接触到漏洞。 消除安全缺陷的首选做法应该是找到并修正它。然而,在某些情况下,阻止恶意的输入 信息接触到漏洞所在地对于消除安全漏洞更划算。通常不推荐采用这种方法,因为这要求开 发人员首先理解攻击者所能采用的所有攻击手段,并有针对性地对代码中可能引发缺陷的所 有执行路径都进行识别和保护。 1.2 C 和 C++ 1.2.1C存在的问题C是一种灵活、可移植的高级编程语言,它已经广泛使用逾40年,但在安全社区中它却 是灾星。那么C的哪些特性使得用它编程易于犯错从而导致安全缺陷呢? C语言的目标是成为一种内存耗用微小的轻量级语言。C的这种特征使得当程序员误以 为某些事情会由c自动处理(而实际上并不会)时,就可能会导致漏洞的出现。如果程序员 熟悉某些表面看上去相似的语言,如Java、Pascal或者Ada,那他们更容易误以为C会为其 提供更多的保护。这些错误的假设导致程序员容易犯这样的一些错误:对数组的越界不加保 护,不处理整数操作的溢出和截断,以及用错误的实参数目调用函数等。 C语言标准的原章节包含一些指导原则。其中,第6点揭示了该语言中绝大多数安全问 题的根源: 要点6:保持C精神。C精神的一些方面,可以归纳为下列短语: (a) 信任程序员。 (b) 不要阻止程序员做他需要做的东西。 © 保持语言的小而简单。 (d) 对一种操作只提供一种方法。 (e) 即使不能保证可移植性,也要使它快速运行。 出于这些原因,C程序员的责任是开发杜绝未定义行为的代码,无论是否有编译器的帮助。 总之,虽然C语言包含了一些经常被误用,从而导致安全缺陷的因素,但C仍然是一种 广为流行的语言,在许多情况下是多种应用程序的首选语言。这些问题中的部分问题可以通 过对语言标准、编译器以及相关工具等的改进加以解决q短期来看,改善现状最有效的方式 就是通过让开发人员了解常见的安全缺陷以及相应的缓解策略,教他们如何进行安全的程序 设计。从长远来看,必须对C语言标准、兼容编译器及库做进一步的改进,使其继续作为开 发安全系统的可行语言。 1.3 开发平台软件漏洞可以从不同的抽象层次观察。在较高的抽象层,对于各种语言和各种操作系统环境,软件漏洞都广泛存在。本书主要关注通常的C和C++编程中容易产生的软件缺陷。漏 洞问题通常与其运行环境密切相关,如果不假设一个特定的操作系统则很难进行讨论。编译、 链接和执行过程中的不同也会造成显著不同的漏洞利用技术与缓解策略。 为了更好地描述漏洞、漏洞利用技术以及缓解措施,本书主要关注微软Windows和 Linux操作系统。选择这两个操作系统是因为它们的流行性,它们在关键的基础设施中广 泛采用,而且它们比较容易产生漏洞。操作系统软件漏洞的数量已经被科罗拉多州大学的 O.H.AIhazmi 和 Y.K.Malaiya 定量评估[Alhazmi 2005a]。 1.4 小结软件漏洞大都是由常见的软件瑕疵所引起的,这一事实早已不是秘密。对C和C++而言 更是如此。这些语言在设计时假设其用户具有一定水平的专业知识,可事实上并非如此。结果导致售出的产品中包含大量的瑕疵,其中一些可能导致软件漏洞。软件开发者需要对用户 发现的漏洞(其中一些是恶意的)作出反应,接着就开始发布补丁和安装补丁的循环周期。然 而,补丁的数量实在太多,导致系统管理员并不能及时完成打补丁的工作。甚至有时补丁程 序本身也包含安全缺陷。这种针对安全缺陷的反应式策略并不奏效,我们需要一种在早期进 行预防和消除安全缺陷的策略、 引起软件安全问题最主要的原因就是软件中的瑕疵,有瑕疵的软件随处可见。那些广泛 使用的操作系统平均每千行代码就有一两个瑕疵,而它们都是由几百万行代码所组成,因此 通常都会包含数千个瑕疵[Davis 2003]。应用软件的规模虽然没有操作系统那么庞大,但其每 千行代码包含的瑕疵数目差不多也是如此。虽然并非每个瑕疵都有安全问题,但是,就算它 们导致安全漏洞的比例只有1%或2%,风险也是相当大的。理解漏洞产生的原理和如何进行安全编程对于保护整个互联网以及我们自身免受攻击至 关重要。要想减少软件缺陷的数量,需要釆用一种以健全的设计原则和有效的质量管理实践 为基础的、严肃的工程方法。 第 2 章 2.1常见的字符串操作错误 2.1.1无界字符串复制无界字符串复制发生于从源数据复制数据到一个定长的字符数组时(例如,从标准输入 读取数据到一个定长的缓冲区中)。如例2.1所示,来自ISO/IEC TR 24731-2的附录A的一个 程序利用gets()函数把字符从标准输入读入一个定长的字符数组,直到读到一个换行符或 者遇到文件结束标志(EOF)为止。 #include #include void get_y_or_n(void) ( char response[8]: putsC'Continue? [y] n:"); gets(response); if (response[0] == 'n') exit(0); return; }如果在提示符下输入超过8个字符(包括空终结符),这个程序就会有不确定的行为。 gets()函数的主要问题是,它没有提供方法指定读入的字符数的限制。这种限制在此函数的 如下一致实现中是显而易见的: char *gets(char *dest) { int c = getchar(); char *p = dest; while (c != EOF && c != *\n') { *p++ = c; c = getchar(); } *p = '\0'; return dest; 10 }对于程序员而言,从无界数据源(例如Stdin)读入数据是一个有趣的问题。由于事先无 法得知用户将会输入多少个字符,因此不可能预先分配一个长度足够的数组。常见的解决方 案是静态分配一个认为长度远远大于所需的数组。在这个例子中,程序员仅仅期望用户输入 1个字符,因此假设不会超过8个字节的数组长度。对于友好的用户而言,这种方式可以很 好地工作。但对于那些恶意用户来说,很容易就超过一个定长字符数组的长度,从而导致发 生未定义行为。在《C安全编码标准》[Seacord 2008]的“ STR35-C,不要从一个无界源复制 数据到定长数组”中,禁止这种方法。 复制和连接字符串。复制和连接字符串时也容易出现错误,因为执行这个功能的许多标 准库调用,如strcpy()、strcat()和sprintf()函数,执行无界复制操作。 2.1.2差一错误空字符结尾的字符串的另一个常见问题是差一错误(off-by-one error)。差一错误与无界 字符串复制有相似之处,即都涉及对数组的越界写问题。这些错误中,很多都是新手易犯的错误,但经验丰富的程序员也可能犯同样的错误,很 容易开发岀并部署类似于这个例子的程序,因为它在大多数系统上都可以顺利通过编译并且 运行时也不报错。下列程序在微软Visual C++ 2010的 /W4警告级别上完全可以编译和链接,并且在Windows 7 ±运行时也不报错,但它包含了几 个差一错误。你能找出这个程序中所有的差一错误吗? #include #include #include int main(void) { char sl[] = "012345678"; char s2[] = ”0123456789"; char *dest; int i; strcpy_s(sl, sizeof(s2), s2); dest = (char *)malloc(strlen(sl)); for (i=l; i |
【本文地址】
今日新闻 |
推荐新闻 |