freemarker导出word、word转pdf,带附件、图片等比缩放 |
您所在的位置:网站首页 › freemarker生成docx文档 › freemarker导出word、word转pdf,带附件、图片等比缩放 |
freemarker导出word、word转pdf,带附件、图片等比缩放
|
目录
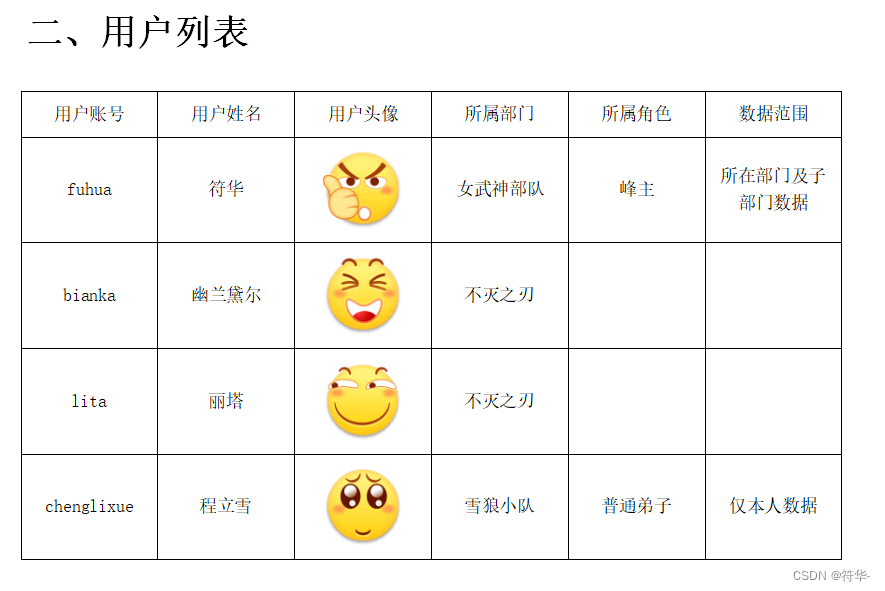
前言需求1、通过freemarker模板,导出word文档,同时可将word转为pdf。2、导出的word带图片,如果图片太大,可通过等比缩放解决图片尺寸变小后变形的问题。3、导出时,将文档里面的图片作为单独的附件一起下载下来;或者是还有其他文件需要和文档一起下载。(这一点也可以忽略😊)
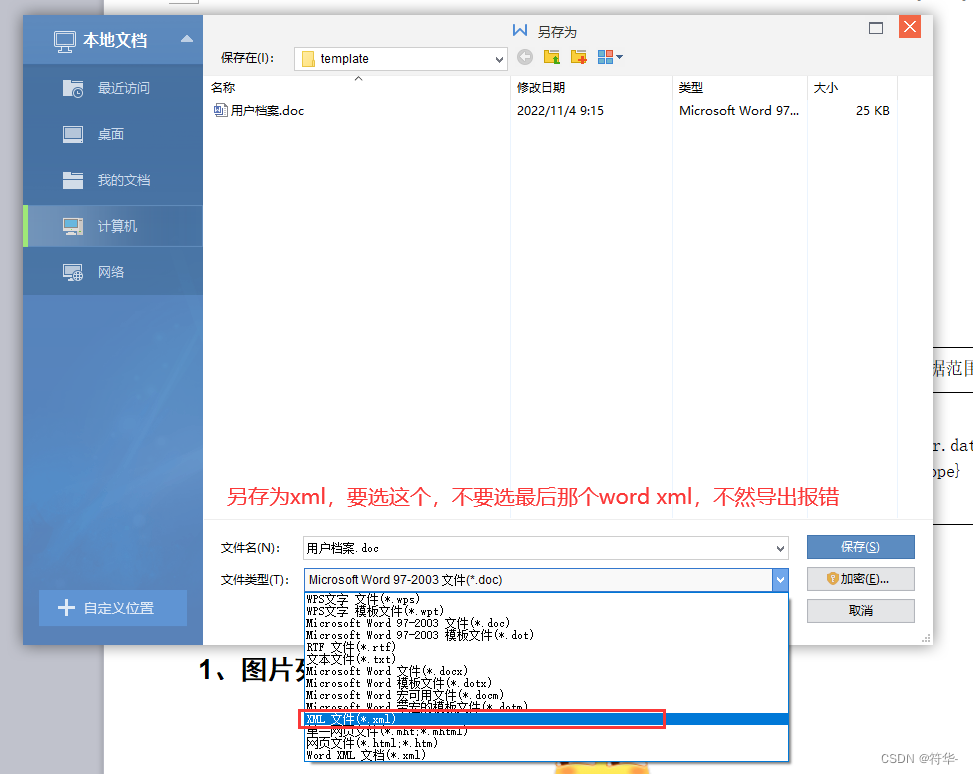
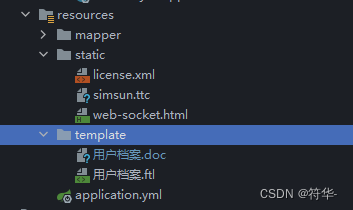
准备😁 1、aspose-words16.8.0.jar 包。😀 2、word转pdf需要的验证文件:license.xml(不验证转化出的pdf会有水印)。😋 3、simsun.ttc 字体文件(Linux要读取字体,否则pdf字体为方格)。🥰 4、word模板。😉 5、将word模板另存为xml文件,将后缀名改为 ftl。
效果😎1、我们先来看看模板是什么样的Ψ( ̄∀ ̄)Ψ2、再来看看导出效果 (。・∀・)ノ
实现😏源码jar包,提取码:3hwy
前言
以前写过一篇 freemarker导出word 的文章,然后在文章最后我说有空写个转pdf的,然后一直没写(其实我以为我写过了😂)。 好久都没用过 freemarker 了,用法都忘得差不多了,以前的那些模板代码也不知道什么时候被我给删掉了,现在重新写都是参考我之前的文章(这就是写博客的好处,不止是分享,还有记录😎)。 所以一些freemarker 的具体用法我这里就不再重复了,有兴趣的可以参考下我之前的文章: freemarker导出word,带表格和多张图片,解决图片重复和变形 freemarker合并单元格,if、else标签的使用,null、空字符串处理 因为word转pdf,需要一个叫 aspose-words 的包,mvn依赖仓库 中的是很旧的版本了,所以我在网上找了个 16.8.0 版本的。如果引入外部的第三方jar包,项目打包的时候,外部的第三方jar包没有一起打包进去,转pdf的时候无法加载,就会报错。那么如何将外部jar一起打包或者是将外部jar转成本地maven仓库依赖,可以参考下面这篇文章: springboot打包成jar运行无法访问resources下的资源,以及jar包运行时引用的第三方jar包也无法加载 需求 1、通过freemarker模板,导出word文档,同时可将word转为pdf。 2、导出的word带图片,如果图片太大,可通过等比缩放解决图片尺寸变小后变形的问题。 3、导出时,将文档里面的图片作为单独的附件一起下载下来;或者是还有其他文件需要和文档一起下载。(这一点也可以忽略😊) 准备 😁 1、aspose-words16.8.0.jar 包。 😀 2、word转pdf需要的验证文件:license.xml(不验证转化出的pdf会有水印)。 😋 3、simsun.ttc 字体文件(Linux要读取字体,否则pdf字体为方格)。 🥰 4、word模板。 😉 5、将word模板另存为xml文件,将后缀名改为 ftl。用到的这些我都放到文章结尾了(^∀^●)ノシ。 效果😎 1、我们先来看看模板是什么样的Ψ( ̄∀ ̄)Ψ
现在我们开始用代码实现,既然是用freemarker,那肯定得引入依赖: org.freemarker freemarker 2.3.31 org.xhtmlrenderer core-renderer R8 aspose words 16.8.0 org.assertj assertj-core然后我们把我上面说的要准备的几个文件分别放到resources目录下的static 和 template目录下:
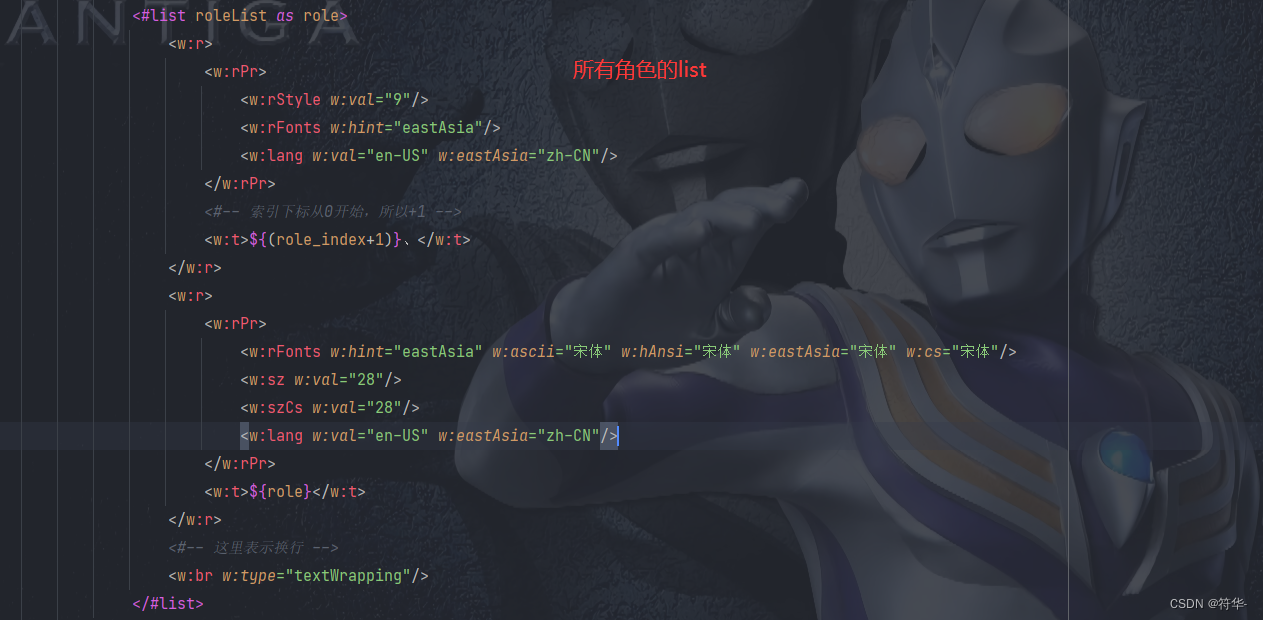
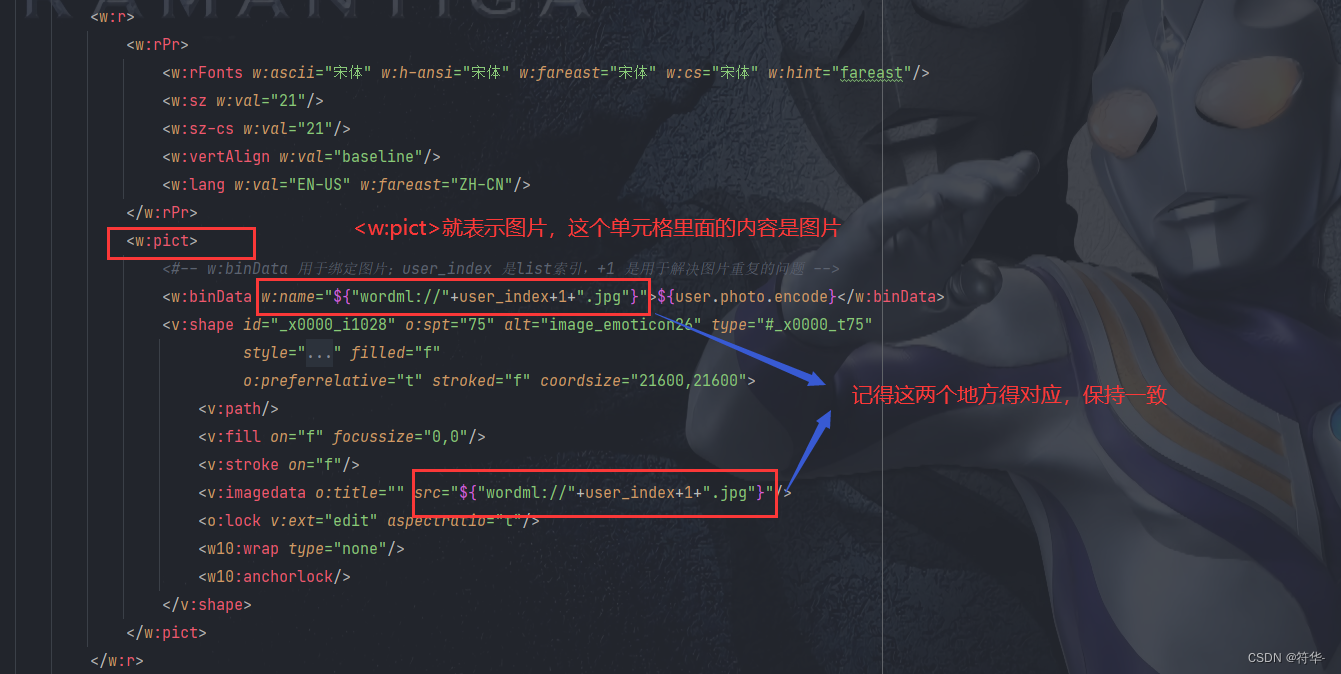
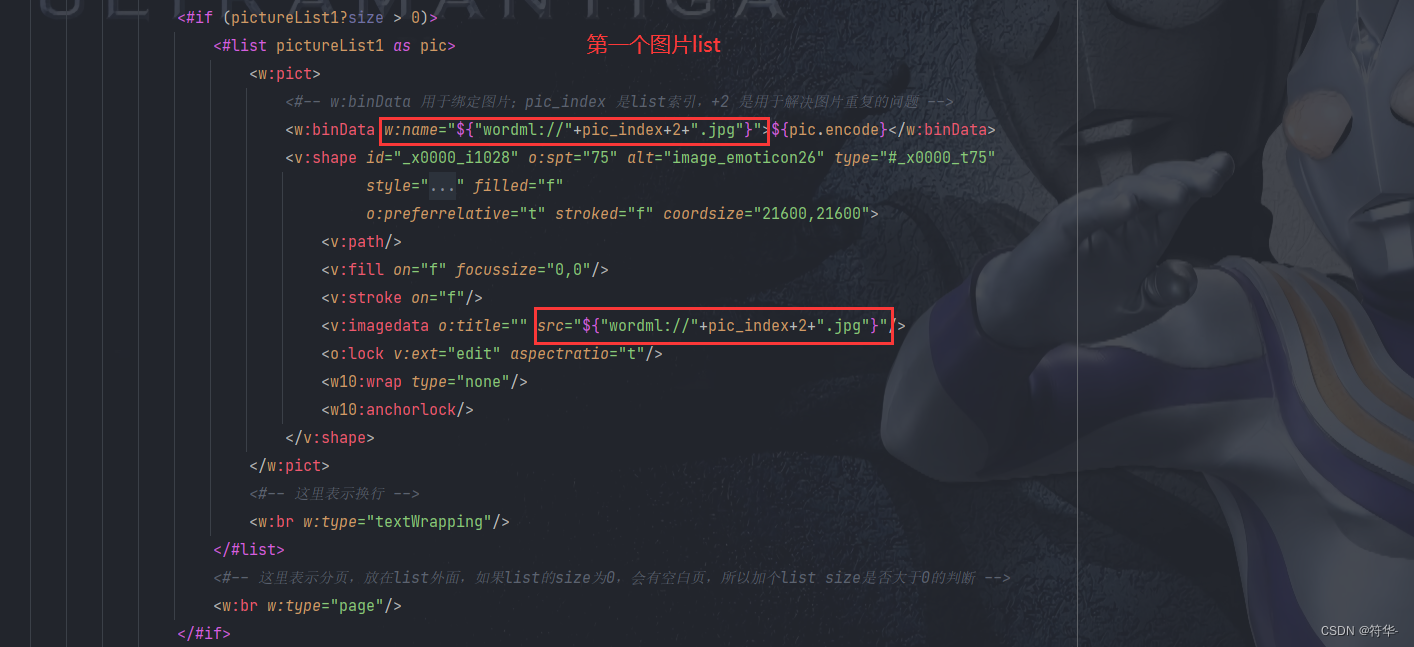
之后我们写个工具类,导出成word和word转pdf: import cn.hutool.system.OsInfo; import cn.hutool.system.SystemUtil; import com.aspose.words.Document; import com.aspose.words.FontSettings; import com.aspose.words.License; import com.aspose.words.SaveFormat; import com.lowagie.text.DocumentException; import com.lowagie.text.Image; import com.lowagie.text.pdf.*; import freemarker.template.Configuration; import freemarker.template.Template; import freemarker.template.Version; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.xhtmlrenderer.pdf.ITextFontResolver; import org.xhtmlrenderer.pdf.ITextRenderer; import java.io.*; import java.net.MalformedURLException; import java.util.Map; /** * word、pdf处理工具类 */ public class WordPDFUtil { protected static Logger logger = LoggerFactory.getLogger(WordPDFUtil.class); /** * 获取破解码文件内容 */ public static boolean getLicense() throws IOException { boolean result = false; InputStream is = null; try { // license.xml应放在..\WebRoot\WEB-INF\classes路径下 is = WordPDFUtil.class.getClassLoader().getResourceAsStream("static/license.xml"); License license = new License(); license.setLicense(is); result = true; } catch (Exception e) { e.printStackTrace(); } finally { if (null != is) is.close(); } return result; } /** * 通过模板导出word格式文件 * * @param dataMap 导出数据 * @param templateName 模板名称 * @param path 导出word的路径以及文件名称 */ public static void exportWord(Map dataMap, String templateName, String path) { try { // 验证License 若不验证则转化出的pdf文档会有水印产生 if (!getLicense()) { return; } //Configuration 用于读取ftl文件 Configuration configuration = new Configuration(new Version("2.3.0")); configuration.setDefaultEncoding("utf-8"); //指定路径(根据某个类的相对路径指定) configuration.setClassForTemplateLoading(WordPDFUtil.class, "/template"); //输出文档路径及名称 File outFile = new File(path); FileOutputStream os = new FileOutputStream(outFile); //以utf-8的编码读取ftl文件 Template template = configuration.getTemplate(templateName, "utf-8"); Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile), "utf-8"), 10240); template.process(dataMap, out); //导出成word时,\n换行替换成 标签,不起作用,无法换行,所以用Document保存word Document doc = new Document(path); doc.save(os, SaveFormat.DOC); out.close(); os.close(); } catch (Exception e) { e.printStackTrace(); } } /** * word转pdf文件 * * @param Address 原文件地址 * @param pdfAddress 保存的pdf文件地址 */ public static void wordConvertPdf(String Address, String pdfAddress) throws IOException { // 验证License 若不验证则转化出的pdf文档会有水印产生 if (!getLicense()) { return; } FileOutputStream os = null; //判断是否windows系统,Linux要读取字体,否则pdf字体为方格 OsInfo osInfo = SystemUtil.getOsInfo(); if (osInfo.isLinux()) { String path = WordPDFUtil.class.getClassLoader().getResource("static/simsun.ttc").getPath(); FontSettings.getDefaultInstance().setFontsFolder(path, true); } try { // 新建一个空白pdf文档 File file = new File(pdfAddress); os = new FileOutputStream(file); // Address是将要被转化的word文档 Document doc = new Document(Address); // 全面支持DOC, DOCX, OOXML, RTF HTML, OpenDocument, PDF, EPUB, XPS, SWF 相互转换 doc.save(os, SaveFormat.PDF); } catch (Exception e) { e.printStackTrace(); } finally { if (null != os) os.close(); } } /** * @param htmlString html字符串 * @param path 生成pdf文件存储路径 * @param chineseFontPath 中文字体存储路径 */ public static void htmlPDF(String htmlString, String path, String chineseFontPath) { OutputStream os = null; try { os = new FileOutputStream(path); ITextRenderer renderer = new ITextRenderer(); //html字符串转换模式 renderer.setDocumentFromString(htmlString); // 解决中文不显示问题 ITextFontResolver fontResolver = renderer.getFontResolver(); fontResolver.addFont(chineseFontPath, BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); renderer.layout(); renderer.createPDF(os); } catch (MalformedURLException e) { logger.warn(e.toString(), e); } catch (FileNotFoundException e) { logger.warn(e.toString(), e); } catch (DocumentException e) { logger.warn(e.toString(), e); } catch (IOException e) { logger.warn(e.toString(), e); } finally { if (os != null) { try { os.close(); } catch (IOException e) { logger.warn(e.toString(), e); } } } } /** * pdf文件添加图片水印 * * @param InPdfFile 要添加水印的pdf路径 * @param outPdfFile 添加水印完成的pdf输入路径 * @param markImagePath 添加图片水印的路径 * @param imgWidth 添加水印X坐标:文件的四个角,左下方的角坐标为(0,0) * @param imgHeight 添加水印的Y坐标 */ public static void addPDFLogo(String InPdfFile, String outPdfFile, String markImagePath, int imgWidth, int imgHeight) throws IOException, DocumentException { System.out.println("========开始生成水印========>>>>>>" + InPdfFile); PdfReader reader = new PdfReader(InPdfFile, "PDF".getBytes()); PdfStamper stamp = new PdfStamper(reader, new FileOutputStream(new File(outPdfFile))); PdfContentByte under; PdfGState gs1 = new PdfGState(); // 透明度设置 gs1.setFillOpacity(0.8f); // 插入图片水印 Image img = Image.getInstance(markImagePath); // 坐标 img.setAbsolutePosition(imgWidth, imgHeight); // 旋转 弧度 img.setRotation(0); // 旋转 角度 img.setRotationDegrees(0); // 自定义大小 img.scaleAbsolute(595, 842); //依照比例缩放 // img.scalePercent(50); // 原pdf文件的总页数 int pageSize = reader.getNumberOfPages(); for (int i = 1; i //......省略其他代码 /** * 将图片内容转换成Base64编码的字符串 * @param path 图片文件的全路径名称 * @return base64字符串和图片宽高 */ public static Map getImageBase64String(String path) { Map map = new HashMap(); if (StrUtil.isEmpty(path)) return null; File file = new File(path); if (!file.exists()) return null; InputStream is = null; InputStream is1 = null; byte[] data = null; try { is = new FileInputStream(file); is1 = new FileInputStream(file); data = new byte[is.available()]; is.read(data); //获取图片宽高 BufferedImage image = ImageIO.read(is1); //图片的原始宽高 map.put("height",Integer.toString(image.getHeight())); map.put("width",Integer.toString(image.getWidth())); is.close(); is1.close(); } catch (IOException e) { e.printStackTrace(); } BASE64Encoder encoder = new BASE64Encoder(); map.put("encode",encoder.encode(data)); return map; } /** * 将图片内容转换成Base64编码的字符串,并获得图片宽高,进行缩放 * @param path 图片文件的全路径名称 * @param flag 判断图片是否是用户头像 * @return base64字符串和图片宽高 */ public static Map getImageBase64String(String path,boolean flag) { Map map = new HashMap(); if (StrUtil.isEmpty(path)) return null; File file = new File(path); if (!file.exists()) return null; InputStream is = null; InputStream is1 = null; byte[] data = null; try { is = new FileInputStream(file); is1 = new FileInputStream(file); data = new byte[is.available()]; is.read(data); //获取图片宽高 BufferedImage image = ImageIO.read(is1); //图片的原始宽高 int height = image.getHeight(); int width = image.getWidth(); //如果图片是用户头像的话,按照50*50的标准来判断是否要缩小,否则的话按照500*500 if (flag){ //宽或高有一项大于50时,等比缩小 if (width > 50 || height > 50){ int cWidth = 50; int cHeight = 50; int showWidth = cWidth; int showHeight = cHeight; //原图宽高太大进行等比缩放(通过等比缩放,解决图片变形的问题) if(1.0 * width/height >= 1.0 * cWidth/cHeight){ //图片比较宽 showHeight = showWidth * height / width; }else { //图片比较长 showWidth = showHeight * width / height; } map.put("height",Integer.toString(showHeight)); map.put("width",Integer.toString(showWidth)); }else { //否则使用图片的原始大小 map.put("height",Integer.toString(height)); map.put("width",Integer.toString(width)); } }else { //宽或高大于500时,进行缩放 if (width > 500 || height > 500){ int cWidth = 500; int cHeight = 500; int showWidth = cWidth; int showHeight = cHeight; //原图宽高太大进行等比缩放 if(1.0 * width/height >= 1.0 * cWidth/cHeight){ //图片比较宽 showHeight = showWidth * height / width; }else { //图片比较长 showWidth = showHeight * width / height; } map.put("height",Integer.toString(showHeight)); map.put("width",Integer.toString(showWidth)); }else { map.put("height",Integer.toString(height)); map.put("width",Integer.toString(width)); } } is.close(); is1.close(); } catch (IOException e) { e.printStackTrace(); } BASE64Encoder encoder = new BASE64Encoder(); map.put("encode",encoder.encode(data)); return map; } }写完工具类,我们就可以处理数据,将数据导出了( ̄︶ ̄*)) /** * 导出word或pdf */ @GetMapping("/exportWordOrPdf") @SaCheckPermission("system:user:view") public ResultVo exportWordOrPdf(SysQuery query, boolean isPdf, HttpServletResponse response) { try { File zip = service.exportWordOrPdfZIP(query,"用户档案V1.1.0",isPdf); UpDownUtil.download(zip,response); // 将临时文件下载到浏览器 FileUtil.del(zip.getParentFile()); // 下载完之后将临时文件删除 }catch (Exception e){ e.printStackTrace(); return ResultUtil.error("导出失败"); } return ResultUtil.success(); } /** * 用户列表 * @param exportPath 导出为word/pdf时,头像单独作为附件一起导出的路径(不需要可以去掉这个参数) */ public List list(SysQuery queryVo,String exportPath) { Map map = sysParams(queryVo); String sqlStr = queryApplyScope("b.id","a.id", 1); if (StrUtil.isNotBlank(sqlStr)){ map.put("dataScope",sqlStr); } String path = System.getProperty("user.dir")+"/"; // 获取当前项目路径 List list = baseMapper.list(map); for (SysUserVo vo : list) { if (StrUtil.isNotBlank(vo.getDataScope())){ String dataScope = vo.getDataScope().replace("1","所有数据").replace("2","所在部门及子部门数据") .replace("3","所在部门数据").replace("4","仅本人数据").replace("5","自定义数据"); vo.setDataScope(dataScope); } if (StrUtil.isNotBlank(vo.getPicture())){ vo.setPicture(path+vo.getPicture()); // 获取头像的绝对路径 vo.setPhoto(UpDownUtil.getImageBase64String(vo.getPicture(),true)); // 设置头像的base64编码 FileUtil.copy(vo.getPicture(),exportPath,true); // 将源路径的图片复制到导出的路径中 } } return list; } /** * 导出word或pdf为压缩包 * 这里因为把word里面的图片页一起单独作为文件附件下载下来了,所以要打包成一个压缩包; * 如果不用把图片单独下载或没有其他附件,就不用打包成压缩包,而是直接下载单个word或pdf。 */ public File exportWordOrPdfZIP(SysQuery queryVo,String code,boolean isPdf) throws IOException { String path = System.getProperty("user.dir")+"/"; // 获取当前项目路径 File file = new File(path+"temp"+"/"+code); // 获取临时的根路径 if (!file.exists()) file.mkdirs(); // 判断文件路径是否存在 System.out.println("保存的路径=========>>>>>>>"+file.getPath()); String wordName = file.getPath()+"/"+ code +".doc"; // 设置导出的word的全路径名称 exportFormatWord(queryVo,file.getAbsolutePath(),code,wordName); // 生成word if (isPdf){ //生成pdf String pdfName = file.getPath()+"/"+ code +".pdf"; // 设置导出的pdf的全路径名称 WordPDFUtil.wordConvertPdf(wordName,pdfName); // 将word转成pdf FileUtil.del(wordName);// 将word文件删除 } File zip = ZipUtil.zip(file); // 压缩包 return zip; } /** * 生成word */ public void exportFormatWord(SysQuery query,String path,String code,String wordName){ //需要导出的模板的数据 Map dataMap = new HashMap(); // 角色列表按照自己的业务逻辑自行查询 List roleList = sysRoleService.list().stream().map(SysRole::getRoleName).collect(Collectors.toList()); dataMap.put("roleList",roleList); // 所有角色 dataMap.put("roleOther","角色对应数据范围,分别有:所有数据、所在部门及子部门数据、所在部门数据、仅本人数据、自定义数据)"); // 角色其他说明 dataMap.put("userList",list(query,path)); // 用户列表(按照自己的逻辑自行查询) //第一个图片list List pictureList1 = new ArrayList(); pictureList1.add(UpDownUtil.getImageBase64String("E:\\document\\图片\\剑网三\\儒风.jpg",false)); pictureList1.add(UpDownUtil.getImageBase64String("E:\\document\\图片\\剑网三\\雪河.jpg",false)); pictureList1.add(UpDownUtil.getImageBase64String("E:\\document\\图片\\剑网三\\破虏.jpg",false)); //第二个图片list List pictureList2 = new ArrayList(); pictureList2.add(UpDownUtil.getImageBase64String("E:\\document\\图片\\剑网三\\风雷.jpg",false)); pictureList2.add(UpDownUtil.getImageBase64String("E:\\document\\图片\\剑网三\\驰冥.jpg",false)); pictureList2.add(UpDownUtil.getImageBase64String("E:\\document\\图片\\剑网三\\破虏.jpg",false)); // pictureList1、pictureList2 这两个的图片没有像用户头像一样,单独作为附件下载。 // 如果有其他附件的话也像头像一样,直接用源文件复制到导出的路径就行,就可以一起打包成zip了。 //将处理好的数据,放到模板数据中 dataMap.put("pictureList1",pictureList1); dataMap.put("pictureList2",pictureList2); dataMap.put("code",code); // 设置页眉 //生成word文件到临时文件夹下 WordPDFUtil.exportWord(dataMap,"用户档案.ftl",wordName); }以上( •̀ .̫ •́ )✧我们就实现了导出word、word转pdf的功能啦(^∀^●)ノシ。同时解决了图片太大了要如何处理,图片重复是怎么回事。顺便还实现了下如果还有其他单独的文件附件要和文档一起下载要怎么做ヾ(•ω•`)o。最后我把源码还有用到的jar放到下面了,需要的自行查看/下载(除了jar包,其他资源都在源码里面)。 源码 jar包,提取码:3hwy如果你觉得文章写的还行或者对你有用的话,帮我点个赞呗~b( ̄▽ ̄)d |





【本文地址】
今日新闻 |
推荐新闻 |