Spark Streaming数据处理流程与工作机制 |
您所在的位置:网站首页 › flume的数据处理流程 › Spark Streaming数据处理流程与工作机制 |
Spark Streaming数据处理流程与工作机制
|
一、Spark Streaming处理的数据流程
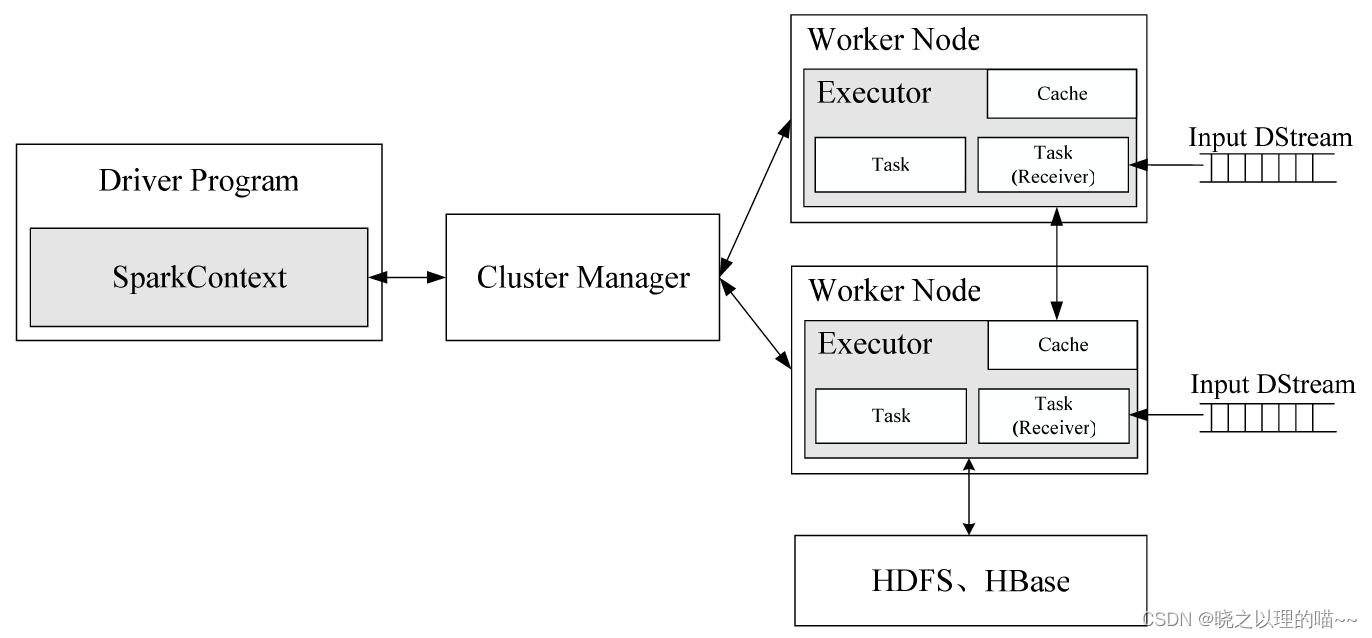
1、Spark Streaming接收Kafka、Flume、HDFS和Kinesis等各种来源的实时输入数据,进行处理后,处理结果保存在HDFS、Databases等各种地方。 在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的任务(Task)运行在一个Executor上,每个Receiver都会负责一个DStream输入流(如从文件中读取数据的文件流、套接字流或者从Kafka中读取的一个输入流等)。Receiver组件接收到数据源发来的数据后,会提交给Spark Streaming程序进行处理。处理后的结果,可以交给可视化组件进行可视化展示,也可以写入到HDFS、HBase中。 (1)通过创建输入DStream(Input Dstream)来定义输入源。流计算处理的数据对象是来自输入源的数据,这些输入源会源源不断产生数据,并发送给Spark Streaming,由Receiver组件接收到以后,交给用户自定义的Spark Streaming程序进行处理; (2)通过对DStream应用转换操作和输出操作来定义流计算。流计算过程通常是由用户自定义实现的,需要调用各种DStream操作实现用户处理逻辑; (3)调用StreamingContext对象的start()方法来开始接收数据和处理流程; (4)通过调用StreamingContext对象的awaitTermination()方法来等待流计算进程结束,或者可以通过调用StreamingContext对象的stop()方法来手动结束流计算进程。 3,创建StreamingContext对象在RDD编程中需要生成一个SparkContext对象,在Spark SQL编程中需要生成一个SparkSession对象,同理,如果要运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象,它是Spark Streaming程序的主入口。 (1)从一个SparkConf对象创建一个StreamingContext对象: scala> import org.apache.spark.streaming._ scala> val ssc = new StreamingContext(sc, Seconds(1))new StreamingContext(sc, Seconds(1))的两个参数中,sc表示SparkContext对象,Seconds(1)表示在对Spark Streaming的数据流进行分段时,每1秒切成一个分段。可以调整分段大小,比如使用Seconds(5)就表示每5秒切成一个分段,但是,无法实现毫秒级别的分段,因此,Spark Streaming无法实现毫秒级别的流计算。 (2)编写一个独立的Spark Streaming程序 import org.apache.spark._ import org.apache.spark.streaming._ val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]") val ssc = new StreamingContext(conf, Seconds(1))文章来源:《Spark技术内幕:深入解析Spark内核架构设计与实现原理》 作者:张安站 文章内容仅供学习交流,如有侵犯,联系删除哦! |
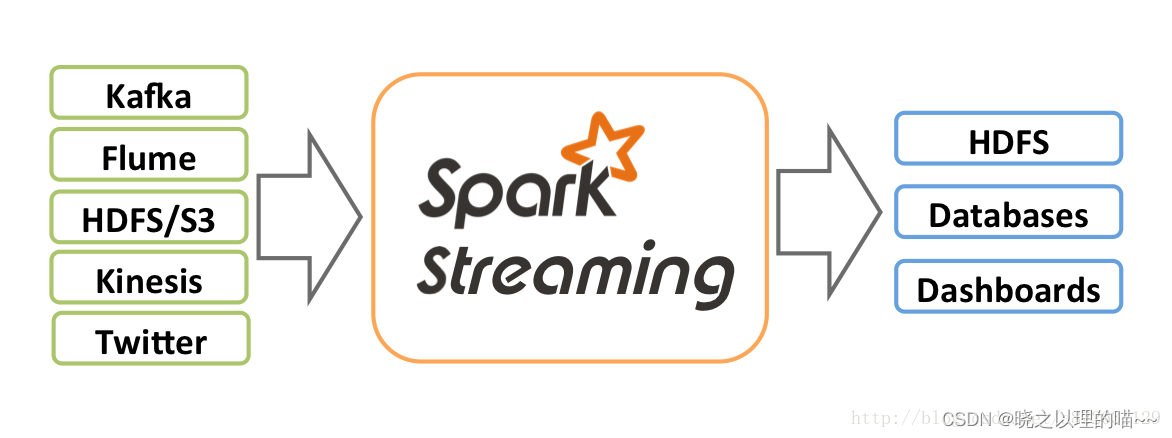 2、Spark Streaming接收这些实时输入数据流,会将它们按批次划分,然后交给Spark引擎处理,生成按照批次划分的结果流。
2、Spark Streaming接收这些实时输入数据流,会将它们按批次划分,然后交给Spark引擎处理,生成按照批次划分的结果流。 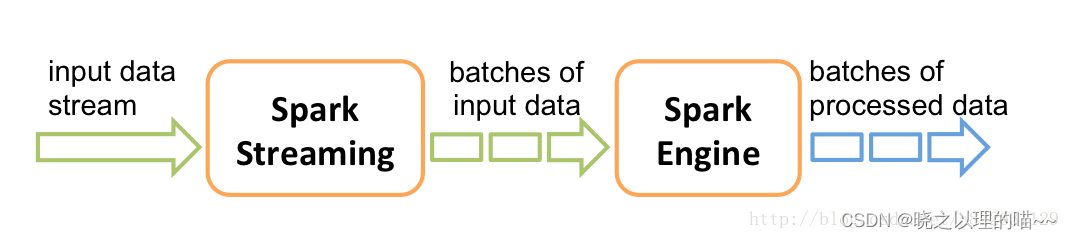 3、Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream。DStream本质上表示RDD的序列。任何对DStream的操作都会转变为对底层RDD的操作。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终被转变为对相应的RDD的操作。
3、Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream。DStream本质上表示RDD的序列。任何对DStream的操作都会转变为对底层RDD的操作。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终被转变为对相应的RDD的操作。 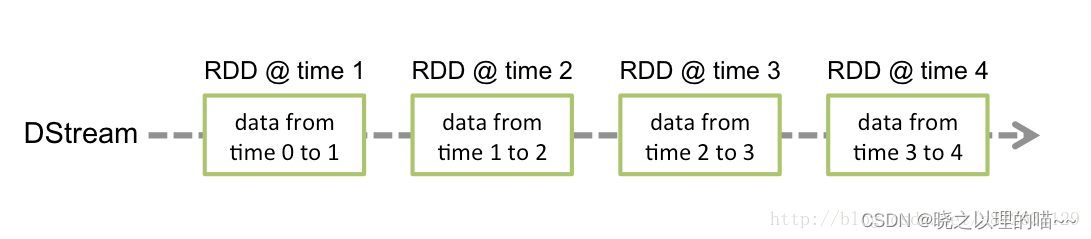 4、Spark Streaming使用数据源产生的数据流创建DStream,也可以在已有的DStream上使用一些操作来创建新的DStream。
4、Spark Streaming使用数据源产生的数据流创建DStream,也可以在已有的DStream上使用一些操作来创建新的DStream。 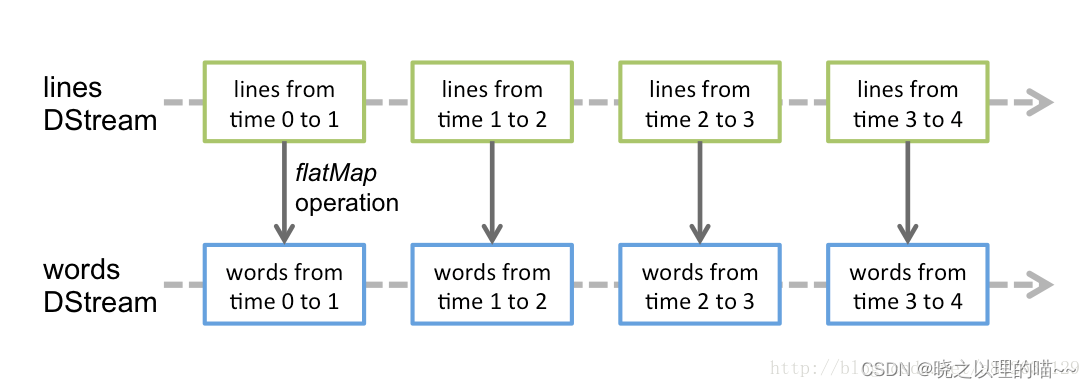
【本文地址】