Flink维表join与异步优化(一) |
您所在的位置:网站首页 › flink维度表join › Flink维表join与异步优化(一) |
Flink维表join与异步优化(一)
|
1. 业务背景
由于运营及产品需要,我们针对之前的离线画像来进行抽取,并将其转换成实时画像来提供给业务方进行接口查询服务。 数据来源为MySQL,维度数据来源于离线hive计算结果,针对本期是针对单用户的查询,所以我们会将具体的用户及相应的查询条件来组合,之后进行hbase单点查询,得到该用户的标签信息,而标签的写入通过flink写入hbase,目前有两个设想,一是将查询条件组合在rowkey上,通过不同的具体条件来查询;另一种则是建立二级索引,通过phoenix来查询,这种我们的rowkey只存储时间和用户信息,而其他信息走二级索引来查询。目前需要先调研下,具体的实现难度和查询效率来决定。 计算的逻辑是实时来,实时计算,之后覆盖写入到hbase中。而计算中两个问题在维度表的数据量对计算时长的影响,其次是计算的指标较多,针对一个用户共计得计算多达550个标签,这个时长需要测试,具体的写入hbase较为频繁,可以具体按照窗口来统计一批来计算,这个和业务方确认下具体的接受时长。 针对后期,如果有圈人的应用,用来发push的场景的话,会考虑后续引入elasticsearch,来存储具体的标签明细信息。具体的技术框架如下: 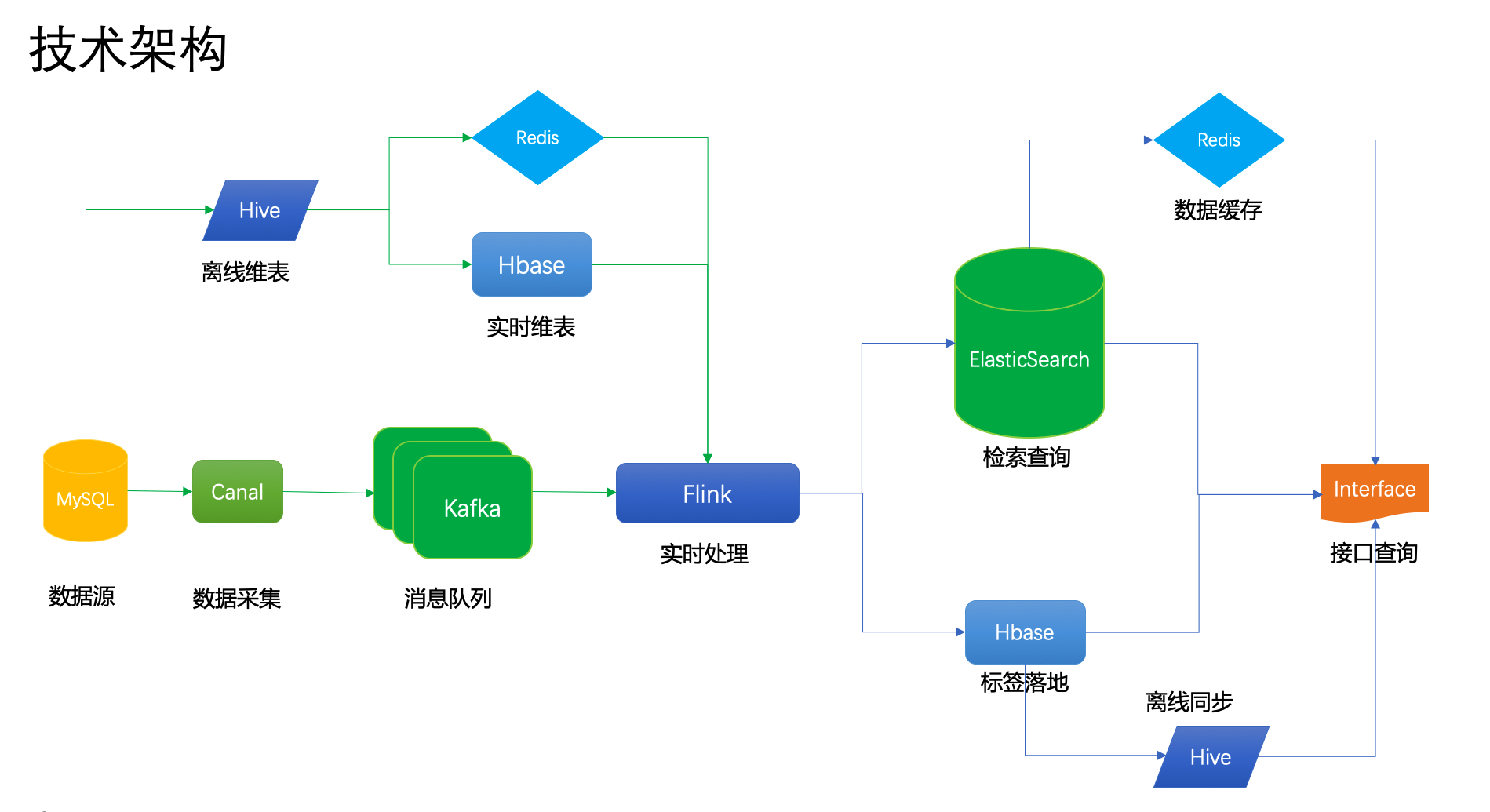 实时画像架构图
2. 维表join问题
实时画像架构图
2. 维表join问题
维度表这个概念,从数仓方面来看,是区别于事实表的,事实表是业务中真实存在的数据。而维度表通常用来表示业务属性信息,例如针对订单信息的商品属性,针对用户信息的地区属性等都可以称之为维度表。 flink流处理在进行实时画像,实时分析以及实时数仓建设时,同样需要使用维度表来完成一些数据过滤或字段补齐的操作。不过我们所需的维度信息通常是存储在Mysql/Redis/Hbase/Es这些外部数据库中,并且可能随时会发生变动,根据业务要求,数据的时效性需要根据不同程度的维表数据变化频率来决定,在实际使用中,常会有以下几种方案: 在维度表数据量较小且业务要求时效性不高的情况下,可以定时加载全量维表数据到内存中,直接从内存中查询维度数据; 在维度表数据量比较大且业务要求的时效性不高的情况下,这时候全量加载维表就会撑爆内存。所以可以考虑使用LRU的缓存策略,当缓存的维度数据达到一定大小,采用淘汰最近最少使用的数据,同时设置数据的过期时间; 业务要求数据时效性比较高时,那么就需要flink实时来查询外部存储,此时需要注意外部存储所能承受的QPS; 最后一种类似于近期发布的broadcaststate,可以直接将维度数据发送到kafka中,flink任务消费kafka的维度数据,然后使用广播方式将维度数据广播到每一个处理task中,该方式同样要求维表数据量比较小。 根据上述的几个方面,由于我们当前的离线维表存储在hive当中,且业务需要计算的字段较多,达到40余个,且数据量偏大,涉及用户的操作维表在千万左右。在跟业务方就具体处理的时效性达成一致的情况下,对维表的更新做到t+1即可。所以时效性上我们关注点不多,主要是考虑数据量的承载问题及访问的QPS问题。针对以上几点,综合考量后,计划将实时维度表存储在hbase当中,数据来源为hive离线维表每天进行同步,之后通过维表与事实流表关联计算得到需要的指标。 维表join上,目前阶段,我们所关心的问题无非是以下几个: 维表的加载查询速度问题,涉及这个问题,我们需要注意如何来增效提速?维表与事实表的关联问题,是否能够有效解决与事实表关联后的数据操作?维表加载与并发的关系,高并发下如何来支撑?加载维度表时如何来容错?针对以上四个问题,需要先理清楚在使用flink来处理事实表与维度表时,现阶段操作的方式方法及相关原理,那么下来,我们就上述的四个问题来一一解答。 3. 加载速度我们本身的情况看,针对千万的维度表做到毫秒级的查询,考验我们hbase表的设计的合理性以及我们集群本身的性能,当前使用的为五台阿里云hbase2.0的集群,根据测试报告看: 单台8c32G随机查询一条在18ms左右: 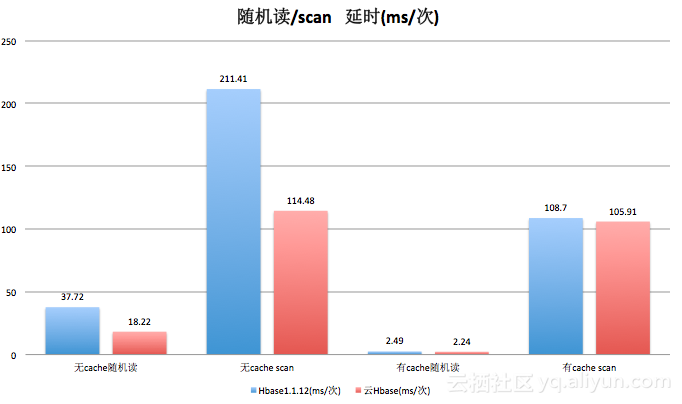 hbase读延时
hbase读延时
目前来看,集群方面,可以实现毫秒级加载,而使用方式则成为我们的一个要点,那么rowkey设计上,我们就要做到稀疏且易于查询,所以针对用户而言,这部分我们可以将uid倒序,也可以加盐或者hash散列等,为了方便我们及离线数仓的同学使用,这部分我们选择倒置uid; 再一个问题,是我们表结构的设计,由于我们涉及的画像字段诸多,那么,需要考虑是放置在一个列簇还是多个列簇中,由于目前我们字段数据一般,加上后续hbase region分裂时的一些特性,所以这块我们选择放置在一个列簇里; 所以表的family,qualiter,rowkey设计尽量短小具有代表性,这个优化后续对存储及查询有一定的提高。做完这些,加载速度这个问题就能跟上了吗?要是跟上了,写这篇就显得多余咯,所以还需要一些优化; 想问下大家,最快的查询是什么查询?其实,最快的查询,就是不做查询。此话怎讲,也就是说我们直接放到缓存里,当然,这个是有选择性的,不可能10000w数据我全放到缓存,那也不现实,对吧?所以唻,我们采取分批少量优先的方法来解决这个问题,那就是著名的Least Recently Used(最近最少使用缓存淘汰策略算法),即LRU。他认为最近访问过的数据在将来被访问的概率也比较大,当内存达到上限去淘汰那些最近访问较少的数据。 在Flink中做维表关联时,如果维表的数据比较大,无法一次性全部加载到内存中,而在业务上也允许一定数据的延时,那么就可以使用LRU策略加载维表数据。但是如果一条维表数据一直都被缓存命中,这条数据永远都不会被淘汰,这时维表的数据已经发生改变,那么将会在很长时间或者永远都无法更新这条改变,所以需要设置缓存超时时间--ttl,当缓存时间超过ttl,会强制性使其失效重新从外部加载进来。还有一种情况是,命中的缓存较少,大量的请求还是直接查hbase,这种,我们可以设置一个缓存的maxsize,如果还没到最大,那么也会将未命中的放进来。哈哈,上述几种讲完,接下来介绍两种比较常见的LRU使用: LinkedHashMapLinkedHashMap是双向链表+hash表的结构,普通的hash表访问是没有顺序的,通过加上元素之间的指向关系保证元素之间的顺序,默认是按照插入顺序的,插入是链表尾部,取数据是链表头部,也就是访问的顺序与插入的顺序是一致的。要想其具有LRU特性,那么就将其改为访问顺序,插入还是在链表尾部,但是数据访问会将其移动达到链表的尾部,那么最近插入或者访问的数据永远都在链表尾部,被访问较少的数据就在链表的头部,给 LinkedHashMap设置一个大小,当数据大小超过该值,就直接从链表头部移除数据。 LinkedHashMap本身不具有ttl功能,就是无法知晓数据是否过期,可以通过给数据封装一个时间字段insertTimestamp,表示数据加载到内存的时间,当这条记录被命中,首先判断当前时间currentTimestamp与insertTimestamp差值是否达到ttl, 如果达到了就重新从外部存储中查询加载到内存中。 其实我也想用这个来着,奈何涉及较多的数据结构更改,可能性能上自己写的也达不到要求,后来就作罢了,退而求其次,找个能用的类库吧,就发现了下面这个东东,呐,请看如下。 guava Cache本地缓存作用就是提高系统的运行速度,是一种空间换时间的取舍。它实质上是一个做key-value查询的字典,但是相对于我们常用HashMap它又有以下特点: 并发性:由于目前的应用大都是多线程的,所以缓存需要支持并发的写入;过期策略:在某些场景中,我们可能会希望缓存的数据有一定“保质期”,过期策略可以固定时间,例如缓存写入10分钟后过期。也可以是相对时间,例如10分钟内未访问则使缓存过期(类似于servlet中的session)。在java中甚至可以使用软引用,弱引用的过期策略;淘汰策略:由于本地缓存是存放在内存中,我们往往需要设置一个容量上限和淘汰策略来防止出现内存溢出的情况。Google Guava Cache是一种非常优秀本地缓存解决方案,提供了基于容量,时间和引用的缓存回收方式。基于容量的方式内部实现采用LRU算法,基于引用回收很好的利用了Java虚拟机的垃圾回收机制。其中的缓存构造器CacheBuilder采用构建者模式提供了设置好各种参数的缓存对象,它与ConcurrentMap很相似,但也不完全一样。最基本的区别是ConcurrentMap会一直保存所有添加的元素,直到显式地移除。相对地,Guava Cache为了限制内存占用,通常都设定为自动回收元素。在某些场景下,尽管LoadingCache 不回收元素,它也是很有用的,因为它会自动加载缓存。提供了Cache缓存模块,轻量级,适合做本地缓存,能够做到以下几点: 可配置本地缓存大小;可配置缓存过期时间;可配置淘汰策略。 //使用方式如下: Cache[String, String] cache = CacheBuilder.newBuilder() .maximumSize(1000) .expireAfterWrite(100, TimeUnit.MILLISECONDS) .build();使用google guava,也会有一些小问题,诸如: 需要消耗一些内存空间来提升速度;需要预料到某些键会被查询一次以上;缓存中存放的数据总量不会超出内存容量。结合我们一天一次的维表,第二点不会是问题,一和三设置好具体的缓存大小和过期时间后,显然也不足为患,那么下来,我们来接着讨论,维表关联操作的相关问题。 4. 关联操作我们在维度表和事实表关联时,会有关联后,数据的集成问题,比如集成两边的数据还是只取需要的维度数据,这个因人而异,比如是sql化操作,那么对于维度表join后,事实表的数据已经得到与之对应的维度数据,而我们的业务来看,事实表来源于三张,且有一定的关联关系,但是时效性上又大有不同,所以唻,可能得别出心裁,想点奇招,那么,就打算所有的实时数据也写入维表,然后直接关联用户后,拿到全量维表字段直接计算的招数。这个问题,我们慢慢细讲,且娓娓道来。 4.1 存在问题由于用户注册表和注销信息表以及相对应的消费信息表肯定不会百分百在同一时刻到达,那么针对这三个流无法同时到达的情况,需要调整下逻辑: 原来的三条流join,由于这个现实情况来看,无法达到,大多数会是两边会有join不上的情况,所以,这块,我们需要针对三条流分别统计出各自需要的字段,然后写入到针对单个用户的一条记录里,分别写入各自的字段中即可;维表join这部分,需要更换。因为我们首先拿到一个完整的用户信息记录以后,需要将这个记录与维表信息来关联,那么这里我们并不需要再去加载维表来计算,而是将我们的该条记录写入到实时维表中对应的用户这一条记录里即可。后续再做使用;后续的计算,由于我们把三条流的join和维表的加载解耦后,换成了另外一种方式来呈现,通过一张大宽表来放置不同的状态,而后,经过该表计算该用户的实时标签。这步处理的频率和时机是个问题,不能一直计算,也不能定时计算。所以这么做也行不通; 4.2 解决措施看似矛盾的流无法join以及计算环节放置在哪,这两个问题,要解决的话,先划清界限 一是三条流join 可以将未到达的无法join上的字段置为空,然后,通过主表与历史维度表join来获取更新前这个用户的状态,而后当有其他辅助流信息来之后,我们的维度表却没有这个主表实时信息,那还是关联不上,所以从这点看,在缺失主实时表的情况下,我们其他的辅助表关联的结果会不准确。所有理论讲需要一个能够容纳晚到以及辅助信息的宽表;二是何时计算在哪计算 有了这个宽表后,我们将历史以及实时的数据都会落到里面,之后进行实时更新写入或软删除即可,但这一点,同时又会引入另一个问题,什么时候去做计算处理,由哪一方来做? 从触发角度看,应该是调用方来做,但是由于涉及后续接口的并发和查询的统一性上,这个由数据方来处理,那么何时何地处理呢?有以下几种: 定时执行,按照分钟级的度来执行计算,但根据需要计算的指标看,需要一些时间,那么大体所需时长会在十几分钟左右; 定时局部执行,可能有很多是不需要计算的,然而我们只计算那部分状态改变的记录,根据uid来找该条记录,之后只计算该部分即可;困难点事如何找到这些记录?需要在state中来存储这部分uid,之后得到每个批次更新的uid后,再针对这部分已经存到实时宽表中的数据做维表join,之后得到记录后,便可以做计算了。这种方式来看,解决了上述的两个问题,一是如何来做无法一起到达数据的join,我们通过实时维度表来解决,二是何时何地来做计算,这个我们先计算一版离线的指标来入到接口查询的存储内,之后再根据我们每一个窗口内更新的用户信息来与实时维表做关联,得到全量信息后,再针对更新的这部分用户来做计算。 计算的频率,我们通过窗口来解决,根据需要先写入,再与维度表join,之后再计算的复杂逻辑,这部分的时间窗口我们可以设置为10-60s之间,尽可能批量的写入和异步查询。 目前计划通过该方式的调整,来达到实时写入与定时计算的统一,并且做到资源的有效利用和时间的尽可能缩短。 5. 并发加载单台8c32G随机读每秒QPS在1w左右: 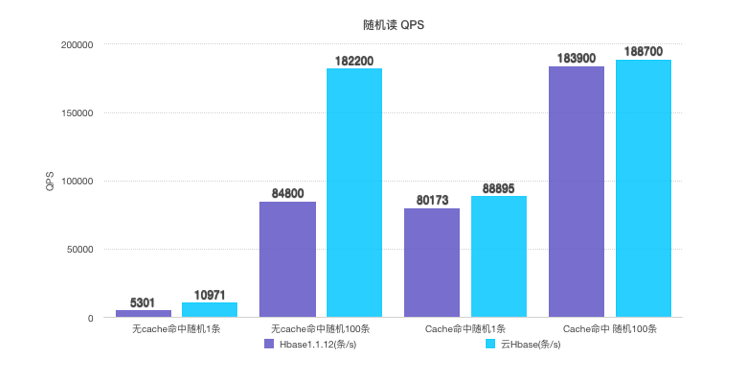 hbase并发
hbase并发
目前我们根据千万用户来看的话,集中在每天的使用4小时的具体时长下,我们的qps也不到1w/s,所以五台4c32G,目前这个并发问题不大。 而且针对维表加载,我们也做了一定的缓存策略,所以可以在一定程度上防止大批量查询hbase,所以对于实时数据的处理量上,我们可以做到实时的加载。 6. 容错容错有两个点,一是我们查询超时的请求如何处理,二是如果发生异常怎么来容错?针对这两个问题,首先,我们必须采用一个成熟可靠的方案来解决,其次,查询得快且准确,容错性高,那么目前结合社区及先进的实践经验看,有以下两种方式: Async I/O 异步加载维度表到flink;使用AsyncLookupTableSource来异步加载数据到flink;两种方式,各有优劣,下面两篇,我们结合实际的使用和采坑经验,给大家同步下具体使用中遇到的问题。 |
【本文地址】