Hadoop大数据平台数据迁移方案(跨集群) |
您所在的位置:网站首页 › fastdfs迁移到hdfs › Hadoop大数据平台数据迁移方案(跨集群) |
Hadoop大数据平台数据迁移方案(跨集群)
|
1、准备大数据平台迁移工作
由于公司项目业务需求,需要将两个项目的大数据平台进行迁移,业务数据进行跨平台平移。
前提(大数据平台之间网络互通)
①将Hive数据通过MR写到其他Linux文件夹中: hive> insert overwrite local directory '/usr/test' select * from test; 上述是通过MR任务计算!② 通过Linux原生SCP拷贝 将本机文件复制到远程服务器上 scp /home/test/* [email protected]:/usr/local/user/test/ 本地文件的绝对路径 new.txt 要复制到服务器上的本地文件 root 通过root用户登录到远程服务器(也可以使用其他拥有同等权限的用户) 192.168.1.1 远程服务器的ip地址(也可以使用域名或机器名) /usr/local 将本地文件复制到位于远程服务器上的路径(提供指定文件地址) 第二种方案 Hive外表远程引用(远程指向)[服务器2]创建Hive外表,其中外表的(location)地址远程指向迁移地址[服务器1]数据的(location)地址, 在我们的Hive中创建Hive外部引用表,将引用路径指向需要迁移的服务器地址 注意: [保证数据必须TextFile文件格式(Orc等压缩文件格无用),可以将压缩表数据插入非压缩表中insert ****** select ******] 第一步:拷贝服务器2host地址,粘贴在本地Host 做好映射 第一步:创建External外表 CREATE External TABLE TEST( id String, id1 String, id2 String )location 'hdfs://bigdata/test/data'; bigdata 为IP地址别名 必须为主节点 /test/data 数据存储地址
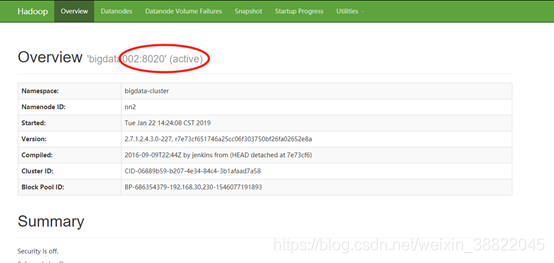
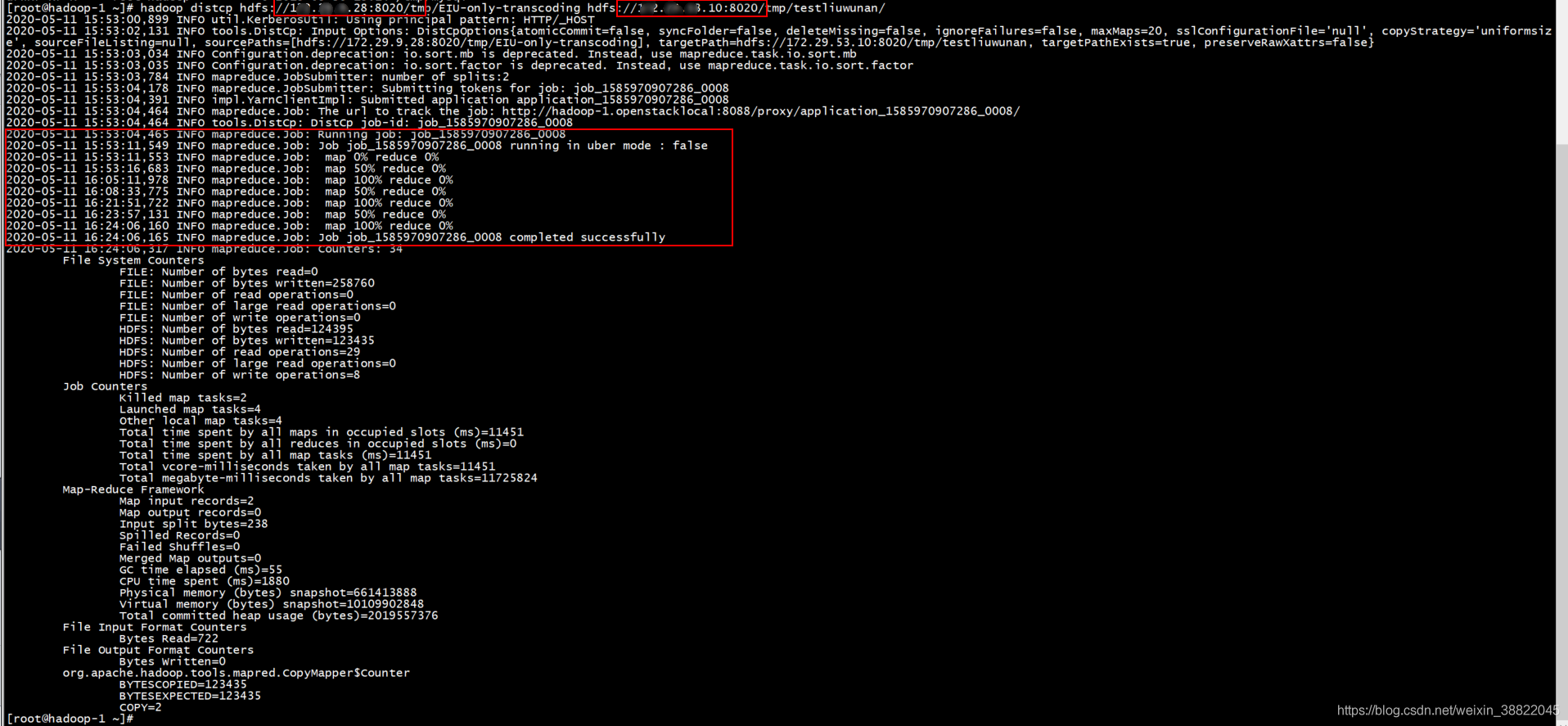
注意: 访问IP:50070端口 查看是否是主节点! 如果是备用节点就不支持,切记要切换 在本地建表,直接查询,即可查询远端数据 通过insert into My_test Select * from test; 将远端数据插入到本地! 在我们测试环境,亲测方案可行 方案要求:远程指向的IP必须为active模式,IP地址,端口都可以进行连接, 拥有权限,对两服务器之间网络要求高! 第三种方案:使用Hadoop集群叫远程拷贝Distcp命令Distcp最常用于在集群之间的拷贝: 实例: hadoop distcp hdfs://nn1:8020/source hdfs://nn2:8020/destination 注意: nn1:(服务器1活跃NM节点的IP) nn2:(服务器2活跃NM节点的IP) 上述命令会把nn1集群的/source目录下的所有文件或目录展开并存储到一个临时文件中,这些文件内容的拷贝工作被分配给多个map任务, 然后每个NodeManager分别执行从nn1到nn2的拷贝操作。【拷贝到的服务器不需要创建文件夹】 注意:DistCp使用绝对路径进行操作。 命令行中还可以指定多个源目录: hadoop distcp hdfs://nn1:8020/source/a hdfs://nn1:8020/source/b hdfs://nn2:8020/destination 方案要求:上述实现基于Hdoop 的MR任务实现,对端口,网络有要求,在本地测试环境亲测方案可行
|
【本文地址】
今日新闻 |
推荐新闻 |