ProtoBuf分析以及某方数据逆向 |
您所在的位置:网站首页 › f12查看返回数据 › ProtoBuf分析以及某方数据逆向 |
ProtoBuf分析以及某方数据逆向
|
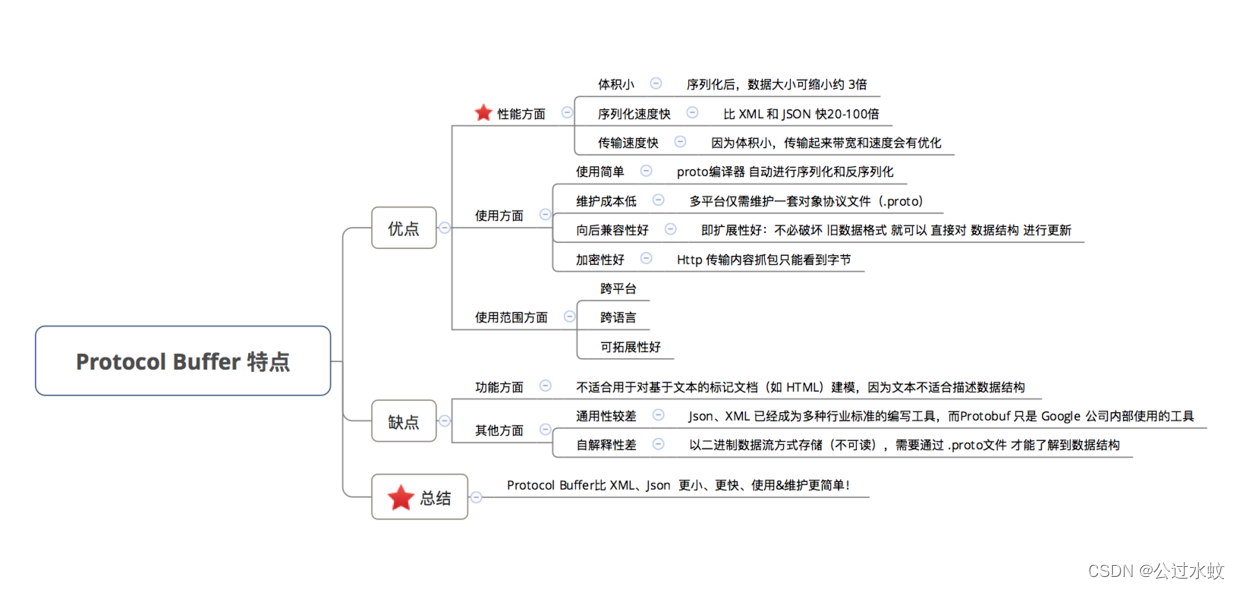
什么是protobuf
一拿到网站,F12查看是否有相关数据的请求接口 请求体是这样的
● application/json: JSON数据格式 ● application/octet-stream : 二进制流数据 ● application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式) ● multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式 通过查询知道这是protobuf 参考文章:https://blog.csdn.net/dideng7039/article/details/101869819 总结在图下了 开发者需要先编写proto文件,在proto文件中编写预期的数据类型、数据字段、默认值等 然后,通过编译器生成,编程语言对应的开发包!开发时调开发包中的对应方法进行序列化和反序列化。 所以请求的时候需要参数是序列化的字节序列,对接收到的返回值进行反序列化 而要实现序列化,就必须要有开发包,可是开发包是js版本的。而开发包是由proto编译而来,只要能拿到proto文件,就可以编译成任意编程的语言版本。 那就是需要通过编译好的包反编译出proto,再编译为python版本的 这里先写一个简单proto,在编译成js版本,看看里面大概的结构长什么样 下载编译器:https://github.com/protocolbuffers/protobuf/releases/ 解压后把bin目录路径添加到环境变量,就可以全局使用 注意,下载低于3.21.0 的proto版本,因为原项目已将它独立出来,下载最新版本的protoc,运行js_out会缺少插件 proto除了一些基础字段,还有一些特殊字段 英文中文备注enum枚举(数字从零开始) 作用是为字段指定某”预定义值序列”enum Type {DEFAULT = 0;success = 1; fail= -1;}message消息体message Student{}repeated数组/集合repeated Student student = 1import导入定义import “protos/other_protos.proto”//注释//用于注释extend扩展extend Student {}package包名相当于命名空间,用来防止不同消息类型的明明冲突现在写一个简单的proto文件 syntax = "proto3"; // 定义proto的版本 enum Gender{ boy=0; girl=1; } enum Score{ DEFAULT = 0; success = 1; // 及格 fail = -1; // 不及格 } message Student { string name = 1; // 姓名 int32 age = 2; // 年龄 Gender gender = 3; //性别 message Subject { string name = 1; // 学科名称 Score score = 2; // 分数 } repeated Subject subject = 4; // 学科 }编译为JS包 protoc --js_out=. .\test.proto3 protoc --js_out=import_style=commonjs,binary:. test.proto两条语句都可以,第一条会拆分成多个文件,第二条是合并成一个,推荐使用第二条 头部就能看到定义好的几个大的对象 可以大概看下代码,截一段比较重要的 /** * Serializes the given message to binary data (in protobuf wire * format), writing to the given BinaryWriter. * @param {!proto.Student} message * @param {!jspb.BinaryWriter} writer * @suppress {unusedLocalVariables} f is only used for nested messages */ proto.Student.serializeBinaryToWriter = function(message, writer) { var f = undefined; f = message.getName(); if (f.length > 0) { writer.writeString( 1, f ); } f = message.getAge(); if (f !== 0) { writer.writeInt32( 2, f ); } f = message.getGender(); if (f !== 0.0) { writer.writeEnum( 3, f ); } f = message.getSubjectList(); if (f.length > 0) { writer.writeRepeatedMessage( 4, f, proto.Student.Subject.serializeBinaryToWriter ); } };这一段序列化的代码中出现了如下的方法名: getName, writeString getAge, writeInt32 getGender, writeEnum getSubjectList, writeRepeatedMessage 这一整个判断,这意味 Student中定义了四个数据变量, 序号为1, 2,3,4,而数据类型和变量名可以根据其调用的方法推出 序号为1的数据类型为String,变量名为name 序号为2的数据类型为Int32,变量名为age 序号为3的数据类型为Enum, 变量名为gender 序号为4的数据类型为Message,变量名为subject,Repeated下面讲 字符串和整数型一看就明了,不做过多解释,下面了解Message和Enum Message是什么数据类型? 简单的理解,可以把message看作是一个类,在其中定义的变量就是类属性 在序号为4的subject判断中有这样一行代码 proto.Student.Subject.serializeBinaryToWriter再来看看Student的 proto.Student.serializeBinaryToWriter到这里可知,Subject定义在Student里面且类型是Message 在定义序号为4的数据时,数据类型就是Subject,并且是可重复的! 所以才会出现这样一个方法writeRepeatedMessage,并且严格来说,序号为4的数据是自定义的Message数据类型,且是可重复的 Message类型的Subject被repeated修饰,即Subject是一个包含多个Subject实例的数组 Enum是什么数据类型? 枚举类型,在值为限定的情况下,比如性别除了男就是女。可以理解为单选框,这里还有个注意的,枚举类型。必须要有为0的默认选项 总而言之呢,看见writeEnum就知道这个数据为Enum类型 repeated也可以修饰Enum,其对应的JS写操作的方法为writePackedEnum 被repeated修饰的enum类型,则好似的多选框,至少选择一个,可选择多个 小结一下: 被repeated修饰的message类型的数据,看作是一个包含任意个某message类型数据的数组被repeated修饰的enum类型的数据,看作是一个包含任意个整数类型数据的整型数组 调试JS反写proto目标网站:aHR0cHM6Ly9zLndhbmZhbmdkYXRhLmNvbS5jbi9wYXBlcj9xPXB5dGhvbg== 将接口的请求地址复制 /SearchService.SearchService/search ,打 XHR/fetch 断点 断住后查看堆栈,有SearchService跟进去打断点看看 看下这些方法的命名,序列化(serialize)、反序列化(deserialize),基本断定就在这个js文件里,但是这个js有几万行代码,不可能仔细去看也没必要。 看到明显的prototype字样,直接搜proto的特征 toObject 将获取到的数据转成结构化数据 deserializeBinary 二进制数据转换成数组结构(反序列化 | 获取到的数据需要Uint8Array转成二进制) deserializeBinaryFromReader 根据规则,将二进制数据转换成数组结构 serializeBinary 将数据转成二进制(序列化) serializeBinaryToWriter 根据规则,将数据转换成二进制数据(序列化)
可以肯定就是proto了 一步步跟进后,到序列化发包的位置 在这里,直接就可以看出其基本结构 message SearchService { message SearchRequest { } }继续调试。
关于变量名是什么,这个其实不重要 继续往下调试,进入到了CommonRequest 根据方法名,直接就可以反写出CommonRequest message SearchRequest { CommonRequest commonRequest = 1; // 任意变量名 InterfaceType interfaceType = 2; // 任意变量名 } message CommonRequest { string searchType = 1; string searchWord = 2; SearchSort searchSort = 3; repeated Second second = 4; int32 currentPage = 5; int32 pageSize = 6; SearchScope searchScope = 7; repeated SearchFilter searchFilter = 8; bool languageExpand = 9; bool topicExpand = 10; } message SearchSort { } message Second { } enum InterfaceType{ TypeDefault = 0; // 定义了什么不知道,但是enum必须有一个值就是0 } enum SearchScope{ ScopeDefault = 0; } enum SearchFilter { FilterDefault = 0; } }SearchSort和Second都是在SearchService定义的,Ctrl + F搜索 SearchService.SearchSort.serializeBinaryToWriter SearchService.Second.serializeBinaryToWriter 补齐字段,请求接口的proto文件就算写完了 在这里插入代码syntax = "proto3"; // 定义proto的版本 message SearchService { message SearchRequest { CommonRequest commonRequest = 1; // 任意变量名 InterfaceType interfaceType = 2; // 任意变量名 } message CommonRequest { string searchType = 1; string searchWord = 2; SearchSort searchSort = 3; repeated Second second = 4; int32 currentPage = 5; int32 pageSize = 6; SearchScope searchScope = 7; repeated SearchFilter searchFilter = 8; bool languageExpand = 9; bool topicExpand = 10; } message SearchSort { string field = 1; Order order = 2; enum Order { OrderDefault = 0; } } message Second { string field = 1; string value = 2; } enum InterfaceType{ TypeDefault = 0; // 定义了什么不知道,但是enum必须有一个值就是0 } enum SearchScope{ ScopeDefault = 0; } enum SearchFilter { FilterDefault = 0; } }对于所有的enum枚举类,至少填充一个默认值0,且变量名唯一 有的情况,枚举类含有哪些字段,可以在代码中直接看到,就照抄写进去。 看不到的,给个唯一变量名,默认值为0即可 现在还差一个源数据,即我们需要知道待编译的源数据是什么样子的? 使用fiddler进行抓包查看请求参数 抓到包后查看HexView,黑色部分就是请求体,里面也可以看到我们搜素的关键词python
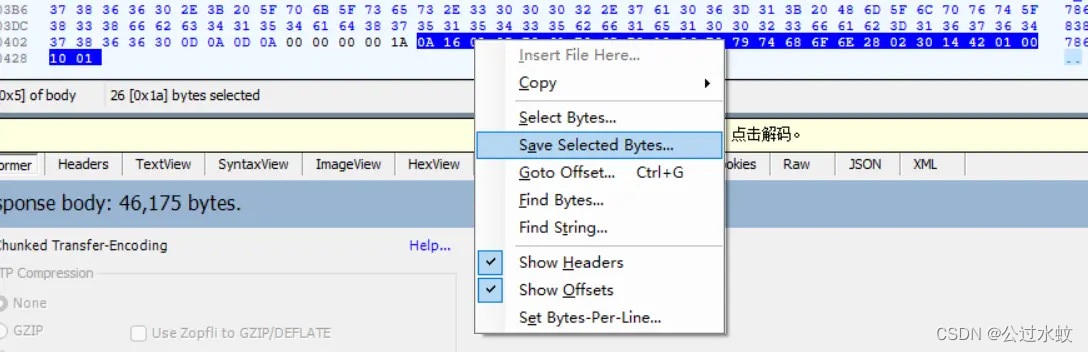
选中,右键保存为字节文件也就是bin后缀,这里要注意,前5个字节表示请求体的长度,从第6个字节开始到结束刚好就是0x1A
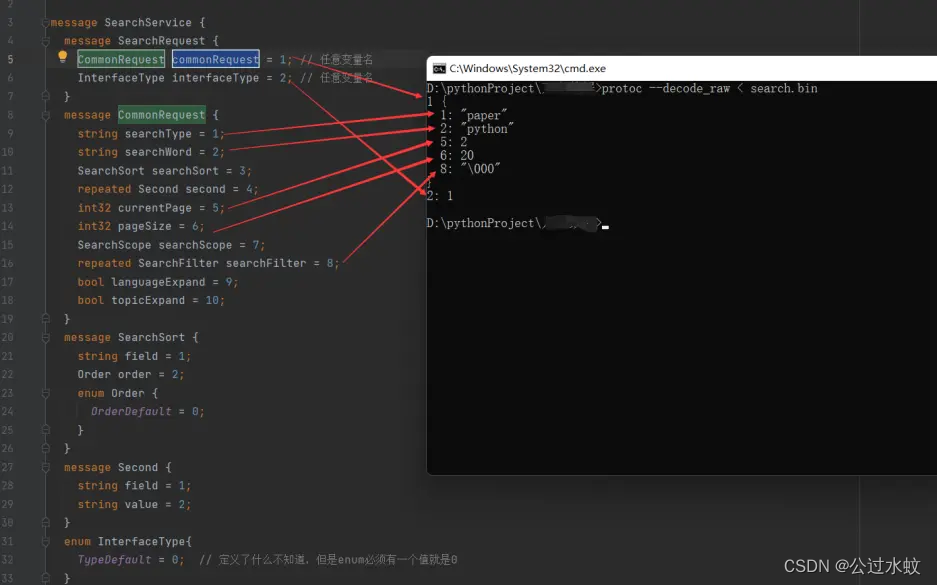
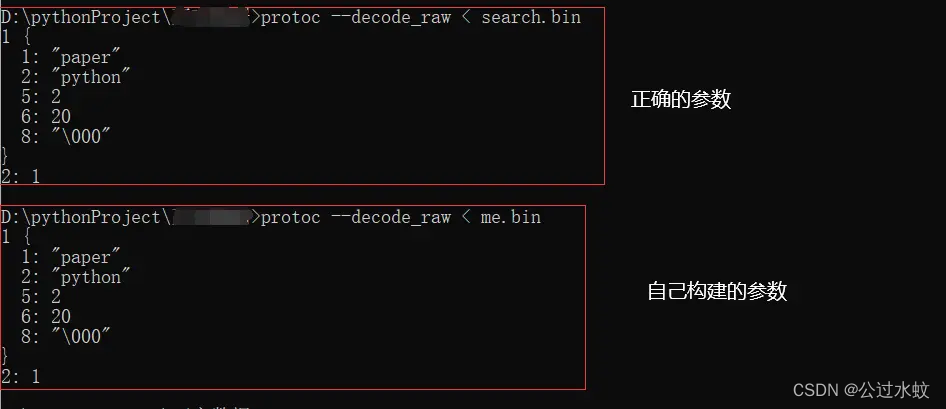
字节数据是可以通过protoc编译器解码出来的 >protoc --decode_raw < get_req.bin 1 { 1: "paper" 2: "python" 5: 2 6: 20 8: "\000" } 2: 1与上面编写好的proto文件进行对比
像有些没包含到的字段,是请求的时候页面没做一些条件筛选,就没触发到某些字段 实际传输时,简单的看,键就是proto中定义的序号,这就是之前提到的 变量名是什么根本不重要,变量名只是方便开发者开发时便于理解与调用。(传输一个数字远比传输一个字符串更有效率) 完全还原proto文件是不需要的,构造出这个请求参数,获取这个接口的响应内容就可以了 实现请求编译proto为python包,构建参数,序列化参数,发送请求 protoc --python_out=. ./search.proto目录下生成了search_pb2.py 拖入项目中,需要使用时就调用即可 import search_pb2 as pb # 导入包 search_request = pb.SearchService.SearchRequest() # 实例化对象 # 按上面解析数据,按照对应的属性设置值 # 字符串,数字型的都是直接赋值 search_request.commonRequest.searchType = 'paper' search_request.commonRequest.searchWord = 'python' search_request.commonRequest.currentPage = 2 search_request.commonRequest.pageSize = 20 # repeated修饰的messsage类型和enum类型,则需要稍微多几个步骤 search_request.commonRequest.searchFilter.append(0) search_request.interfaceType = 1 form_data = search_request.SerializeToString() print(form_data) # 保存数据玮bin文件供后续对比使用 with open('me.bin', mode="wb") as f: f.write(form_data) print(search_request.SerializeToString().decode())至此,请求参数的序列化已经是完成了
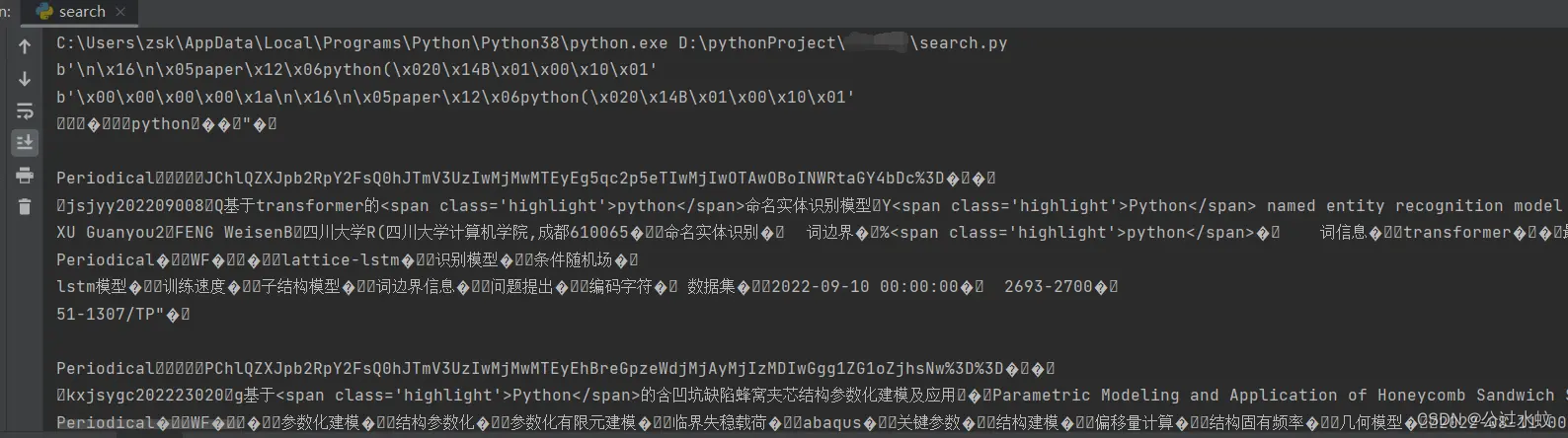
我们构造了请求的proto文件,并成功用python发包获得了数据,但是得到的数据和f12得到的数据是一样的乱码如下图
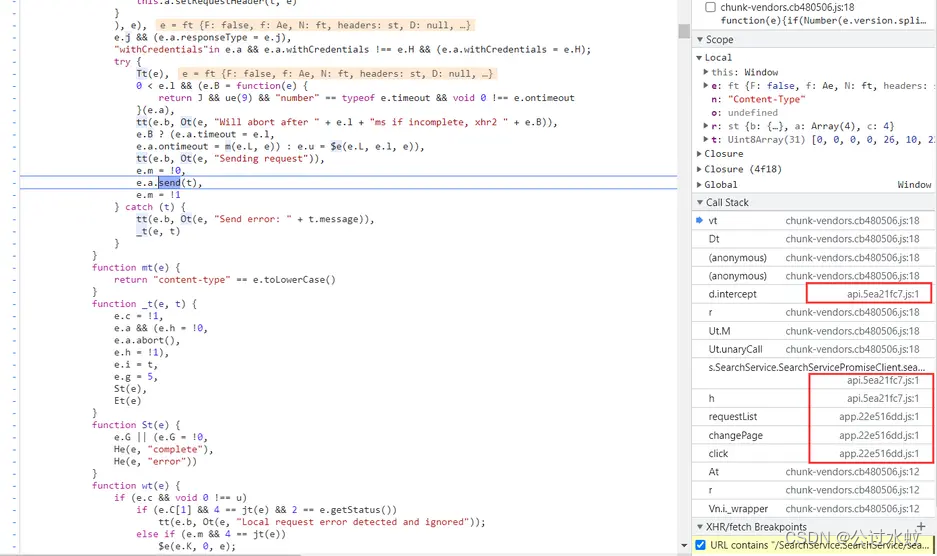
其实这个也是protobuf格式,发过去的是protobuf格式,收到的也是protobuf格式,只是它是以二进制序列化格式传输的,所以看上去像乱码. 接下来会带来两种方法:①直观但有点复杂,②便捷但不太直观 方法一写对应的响应的proto文件,和发包一样。当然可以和发包写在一起。 老规矩,还是打断点从堆栈进行分析,根据发包的堆栈主要看app开头的js,因为chunk开头的是基本库,很少在里面做手脚,一般都是在自写的js里面做加密或其他操作。
一步步调试后,
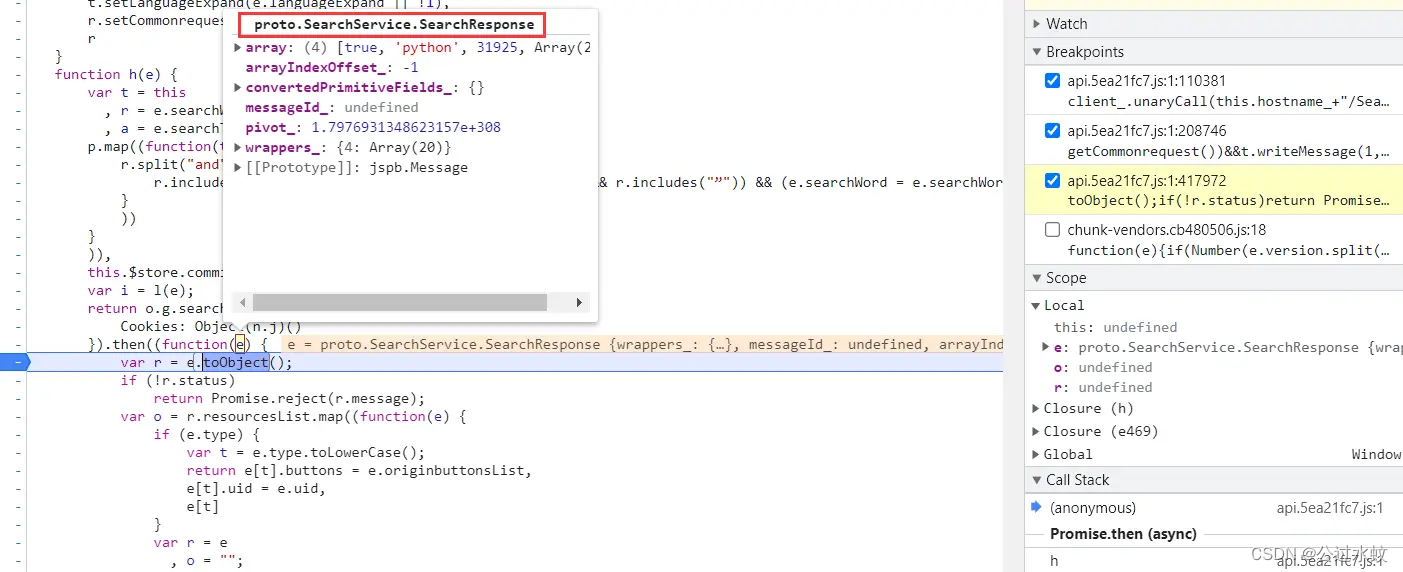
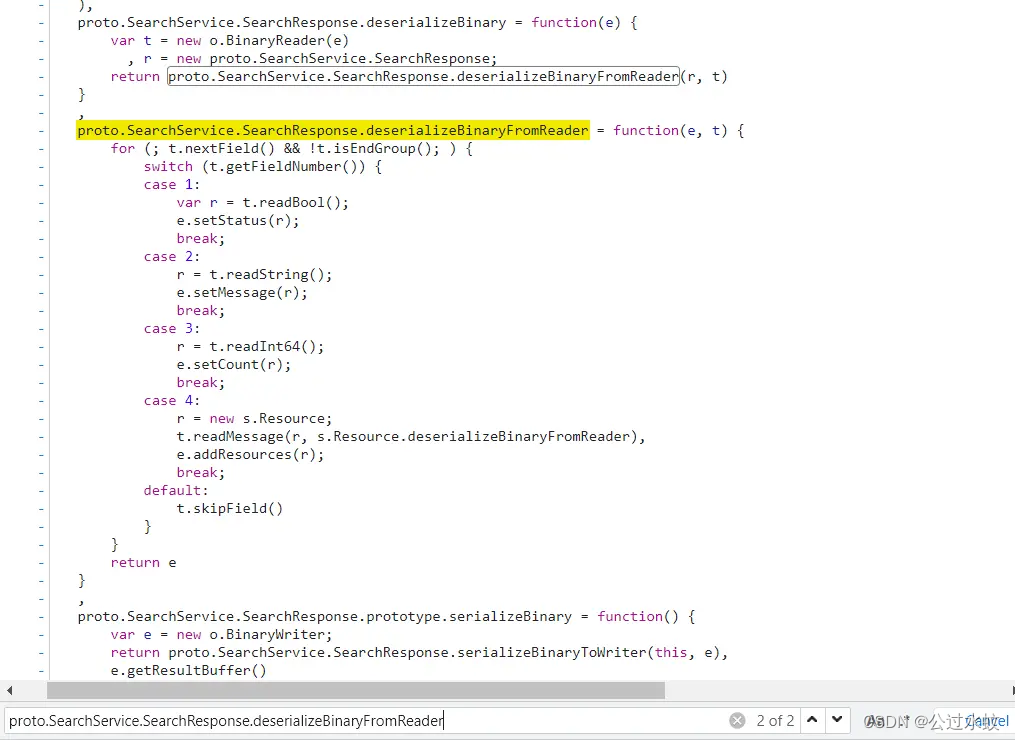
异步然后获得了值去.toObject,这个toObject就是proto文件转js的时候会产生的一个api函数接口,可以简单使用protoc去尝试转化成js看看。 这里不好跟进,直接全局搜索一下:proto.SearchService.SearchResponse 这里接受响应后需要把二进制数据进行反序列化,那么就会用到下面的api deserializeBinary------deserializeBinaryFromReader(重点核心) 完整的就是 proto.SearchService.SearchResponse.deserializeBinaryFromReader
一下子就定位到了,和请求的一样理解,只是他现在变成了case语句来表示序号位置,read后面的类型来表示类型。 序号4有个message,进去查看
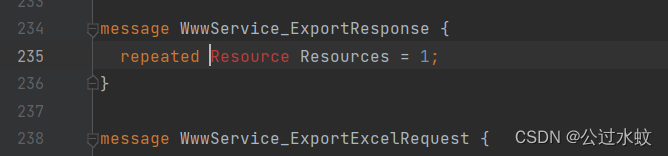
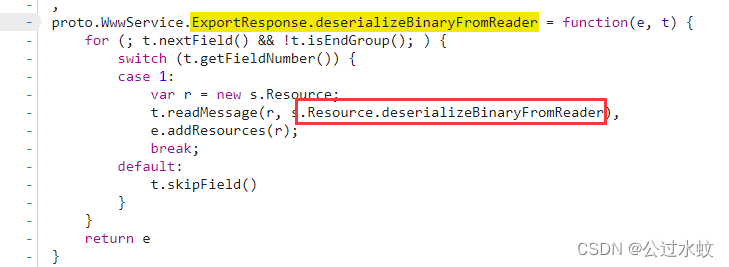
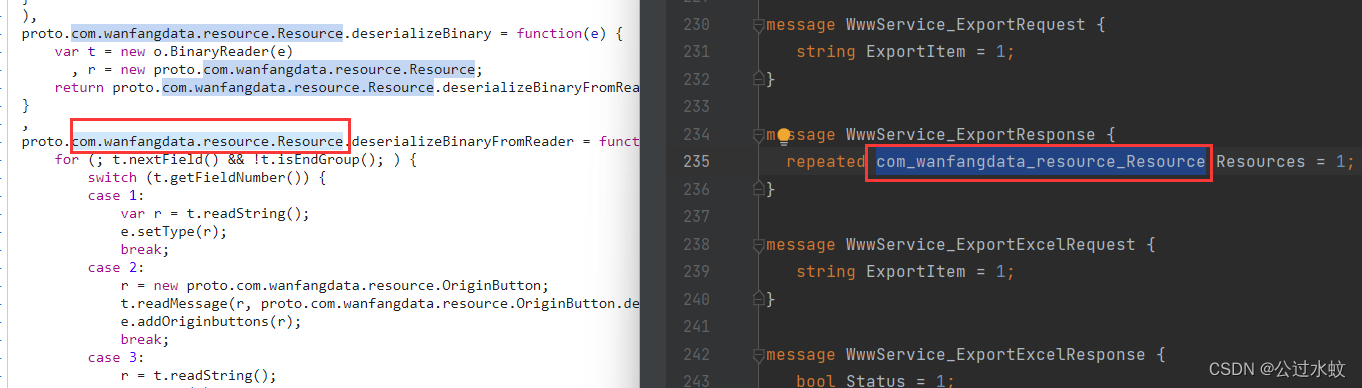
这个返回的数据量太大了,标号也特别的多,有没有什么更好的方法得到proto文件呢? 那就是自写ast,然后用ast来处理这种switch语句。这里直接使用渔歌写好的ats插件,文末附上链接,网站js有些小更新,之前的可能有些小报错,小小的修改了一下 这里把整个js复制出来命名为test.js,先安装babel解析库在当前目录下 npm install @babel/core --save-dev执行ast代码 const parser = require("@babel/parser"); // 为parser提供模板引擎 const template = require("@babel/template").default; // 遍历AST const traverse = require("@babel/traverse").default; // 操作节点,比如判断节点类型,生成新的节点等 const t = require("@babel/types"); // 将语法树转换为源代码 const generator = require("@babel/generator"); // 操作文件 const fs = require("fs"); //定义公共函数 function wtofile(path, flags, code) { var fd = fs.openSync(path,flags); fs.writeSync(fd, code); fs.closeSync(fd); } function dtofile(path) { fs.unlinkSync(path); } var file_path = 'test.js'; //你要处理的文件 var jscode = fs.readFileSync(file_path, { encoding: "utf-8" }); // 转换为AST语法树 let ast = parser.parse(jscode); let proto_text = `syntax = "proto3";\n\n// protoc --python_out=. app_proto2.proto\n\n`; traverse(ast, { MemberExpression(path){ if(path.node.property.type === 'Identifier' && path.node.property.name === 'deserializeBinaryFromReader' && path.parentPath.type === 'AssignmentExpression'){ let id_name = path.toString().split('.').slice(1, -1).join('_'); path.parentPath.traverse({ VariableDeclaration(path_2){ if(path_2.node.declarations.length === 1){ path_2.replaceWith(t.expressionStatement( t.assignmentExpression( "=", path_2.node.declarations[0].id, path_2.node.declarations[0].init ) )) } }, SwitchStatement(path_2){ for (let i = 0; i item.consequent = [ item2.consequent[0], t.expressionStatement( item2.consequent[1].expression.expressions[0] ), item2.consequent[2] ]; item2.consequent[1] = t.expressionStatement( item2.consequent[1].expression.expressions[1] ) }else if(item.consequent.length === 0){ item.consequent = item2.consequent }else if(item.consequent[1].expression.type === 'SequenceExpression'){ item.consequent[1] = t.expressionStatement( item.consequent[1].expression.expressions[1] ) } } } }); let id_text = 'message ' + id_name + ' {\n'; let let_id_list = []; try{ // console.log(path.parentPath.node.right.body.body[0].body.body[0].cases.length); for (let i = 0; i let id_number = item.test.value; let key = item.consequent[1].expression.callee.property.name; let id_st, id_type; if(key.startsWith("set")){ id_st = ""; }else if(key.startsWith("add")){ id_st = "repeated"; }else{ // map类型,因为案例中用不到,所以这里省略 continue } key = key.substring(3, key.length); id_type = item.consequent[0]; if(id_type.expression.right.type === 'NewExpression'){ id_type = generator.default(id_type.expression.right.callee).code.split('.').slice(1).join('_'); }else{ switch (id_type.expression.right.callee.property.name) { case "readString": id_type = "string"; break; case "readDouble": id_type = "double"; break; case "readInt32": id_type = "int32"; break; case "readInt64": id_type = "int64"; break; case "readFloat": id_type = "float"; break; case "readBool": id_type = "bool"; break; case "readPackedInt32": id_st = "repeated"; id_type = "int32"; break; case "readBytes": id_type = "bytes"; break; case "readEnum": id_type = "readEnum"; break; case "readPackedEnum": id_st = "repeated"; id_type = "readEnum"; break; } } if(id_type === 'readEnum'){ id_type = id_name + '_' + key + 'Enum'; if(let_id_list.indexOf(id_number) === -1){ id_text += '\tenum ' + id_type + ' {\n'; for (let j = 0; j if(let_id_list.indexOf(id_number) === -1){ id_text += '\t' + id_st + ' ' + id_type + ' ' + key + ' = ' + id_number + ';\n'; let_id_list.push(id_number) } } } } }catch(e){ } id_text += '}\n\n'; proto_text += id_text } } }); wtofile('app_proto3.proto', 'w', proto_text);这个ast代码单纯只是针对这个站点,其他站点也是类似分析。 运行后生成了app_proto3.proto文件,打开看一面有一些报错,如下图,渔歌文章也讲清楚了原因,因为对象调用deserializeBinaryFromReader方法的时候,ast代码处理对象无法确定,所以就没加载到。
我们在调试里面,搜索关键词ExportResponse.deserializeBinaryFromReader
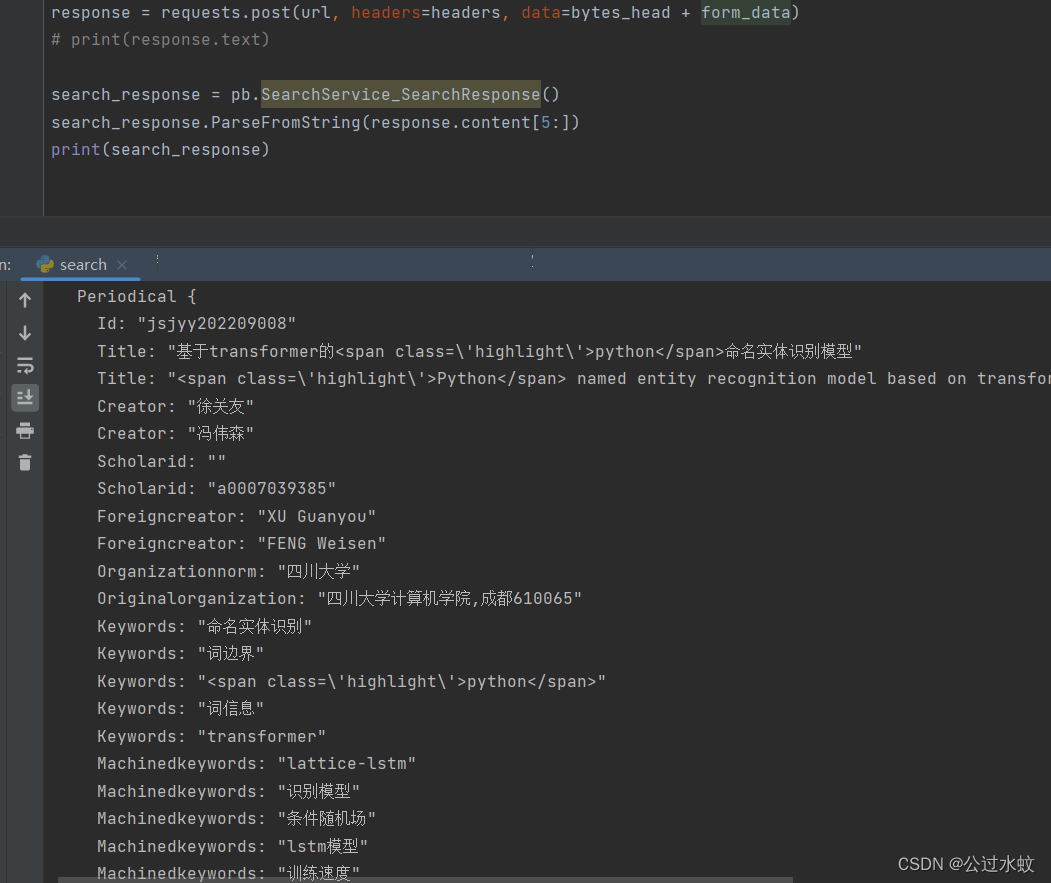
跟进去就能找到s对象是什么,补上就行,其他的报错也是这样的操作 得到了proto文件后进行编译成python protoc --python_out=. ./app_proto3.proto然后发个请求试一试 import app_proto3_pb2 as pb import requests search_request = pb.SearchService_SearchRequest() # 实例化对象 # 按上面解析数据,按照对应的属性设置值 # 字符串,数字型的都是直接赋值 search_request.Commonrequest.SearchType = 'paper' search_request.Commonrequest.SearchWord = 'python' search_request.Commonrequest.CurrentPage = 2 search_request.Commonrequest.PageSize = 20 # repeated修饰的messsage类型和enum类型,则需要稍微多几个步骤 search_request.Commonrequest.SearchFilterList.append(0) search_request.InterfaceType = 1 form_data = search_request.SerializeToString() print(form_data) # 保存数据玮bin文件供后续对比使用 # with open('me.bin', mode="wb") as f: # f.write(form_data) # print(search_request.SerializeToString().decode()) bytes_head = bytes([0, 0, 0, 0, len(form_data)]) print(bytes_head + form_data) headers = { "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.9", "Content-Type": "application/grpc-web+proto", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36", } url = "https://*********.com.cn/SearchService.SearchService/search" response = requests.post(url, headers=headers, data=bytes_head + form_data) # print(response.text) search_response = pb.SearchService_SearchResponse() search_response.ParseFromString(response.content[5:]) print(search_response)可以看到很直观,取值也方便。
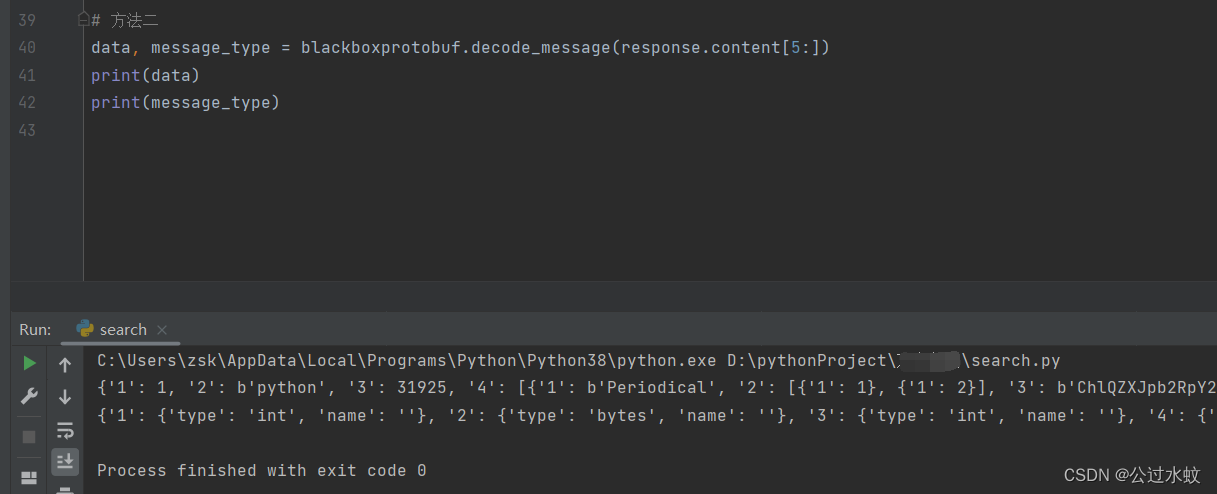
上面之所以从响应的第六位字节开启取,是跟上面发包一样的,前五个字节表示请求头的长度 下面是proto的核心,序列化和反序列化 serializeBinary------serializeBinaryFromReader(重点核心) deserializeBinary------deserializeBinaryFromReader(重点核心) 方法二使用python应对protobuf的第三方库:blackboxprotobuf 安装命令:pip install blackboxprotobuf 调用核心函数 :blackboxprotobuf.decode_message(Byte类型数据),进行解protobuf格式数据
上面是数据对应结构位置,下面是类型对应结构位置 虽然拿到了数据,只是位置序号加内容,我们其实要靠猜才能知道是什么,这种就不需要去写proto文件 两种方式都可以,喜欢哪种用哪种 相关资料参考https://blog.csdn.net/dideng7039/article/details/101869819 https://blog.csdn.net/qq_35491275/article/details/111721639 https://mp.weixin.qq.com/s/DzCz66_Szc7vfG6bpl956w https://blog.csdn.net/qq_56881388/article/details/128612717 |
 请求头的类型也非常见的
请求头的类型也非常见的 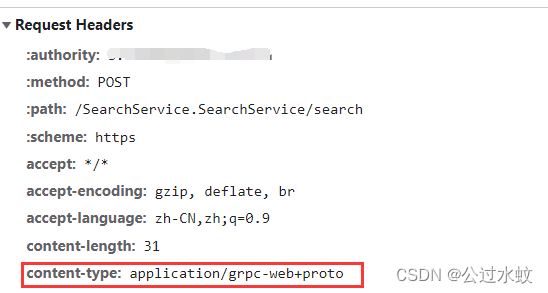

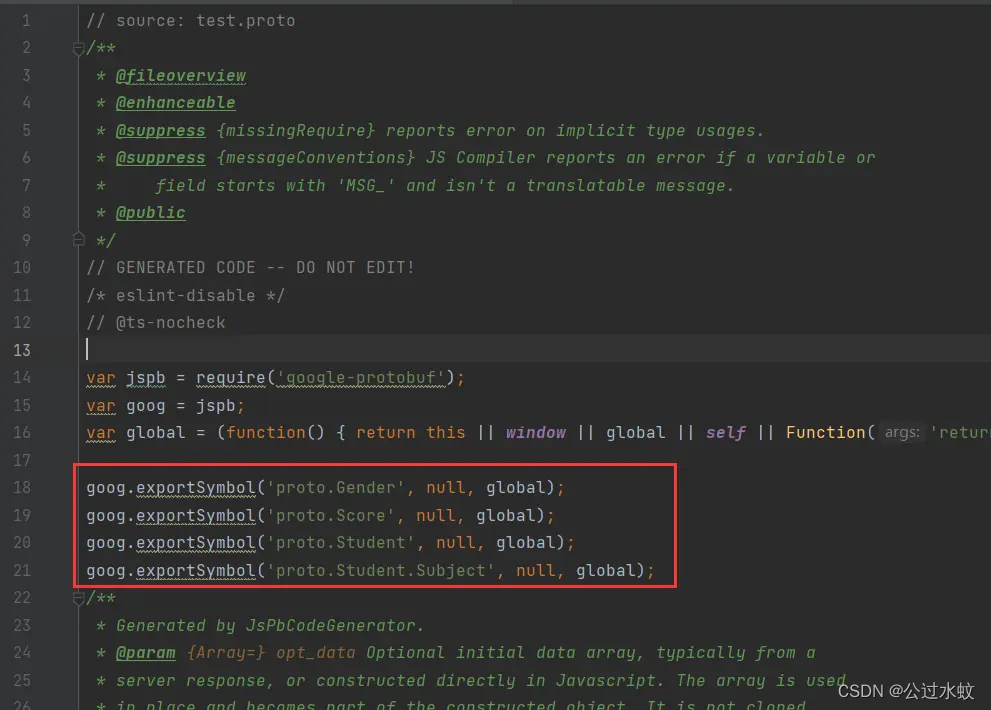
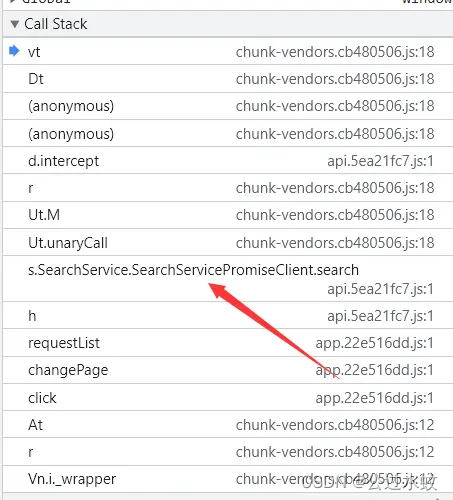
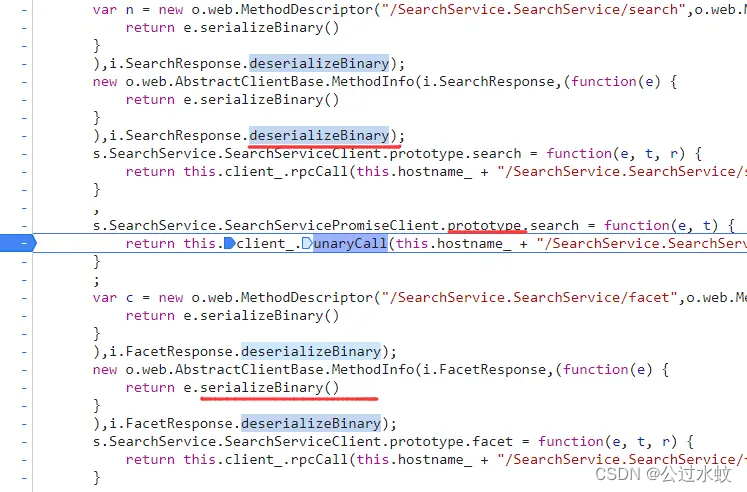
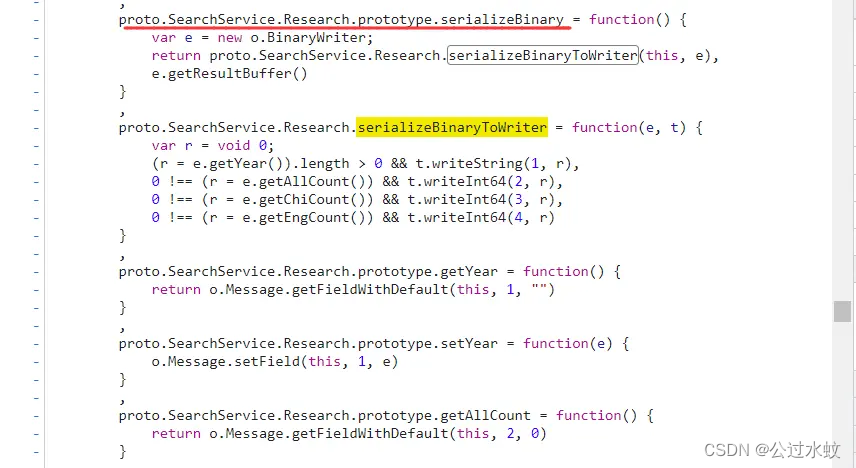
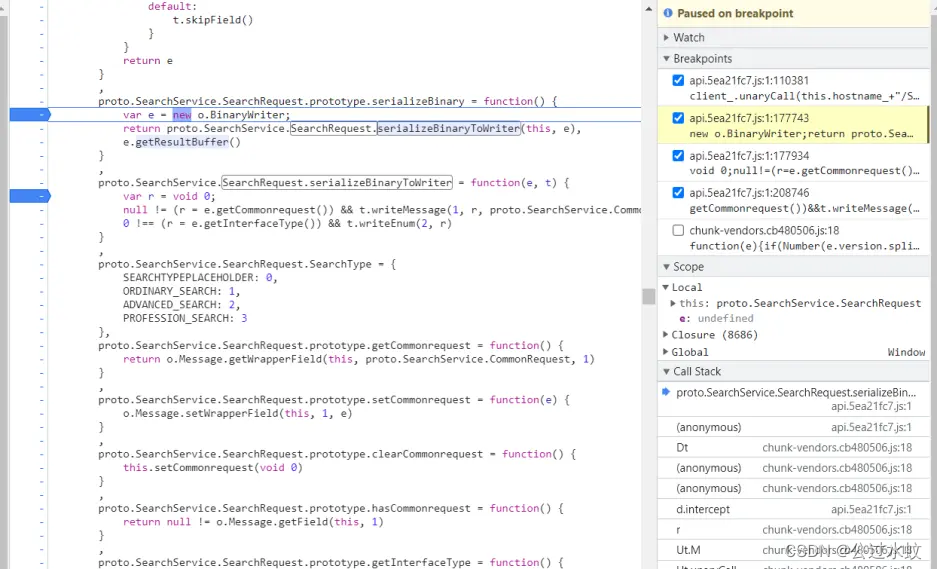
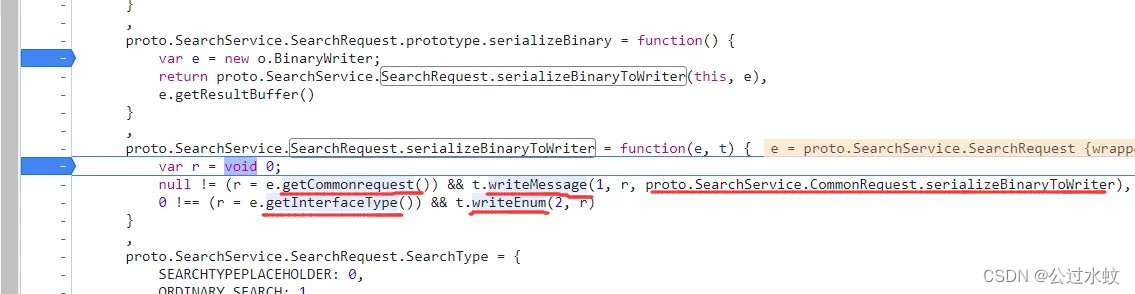 这里可以看出SearchRequest定义了两个变量,分别是序号为1的message类型的CommonRequest和序号为2的enum类型的InterfaceType。 根据SearchService.CommonRequest可知,CommonRequest定义在SearchService中 所以,proto文件现在是这样的:
这里可以看出SearchRequest定义了两个变量,分别是序号为1的message类型的CommonRequest和序号为2的enum类型的InterfaceType。 根据SearchService.CommonRequest可知,CommonRequest定义在SearchService中 所以,proto文件现在是这样的: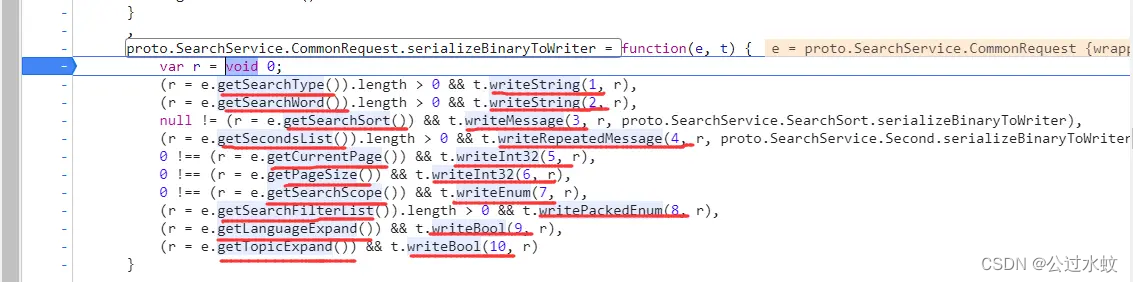




【本文地址】
今日新闻 |
推荐新闻 |