异步爬虫“该文章已下线” 、“mrd参数”解决方法 |
您所在的位置:网站首页 › e管家企业已经下线怎么办 › 异步爬虫“该文章已下线” 、“mrd参数”解决方法 |
异步爬虫“该文章已下线” 、“mrd参数”解决方法
|
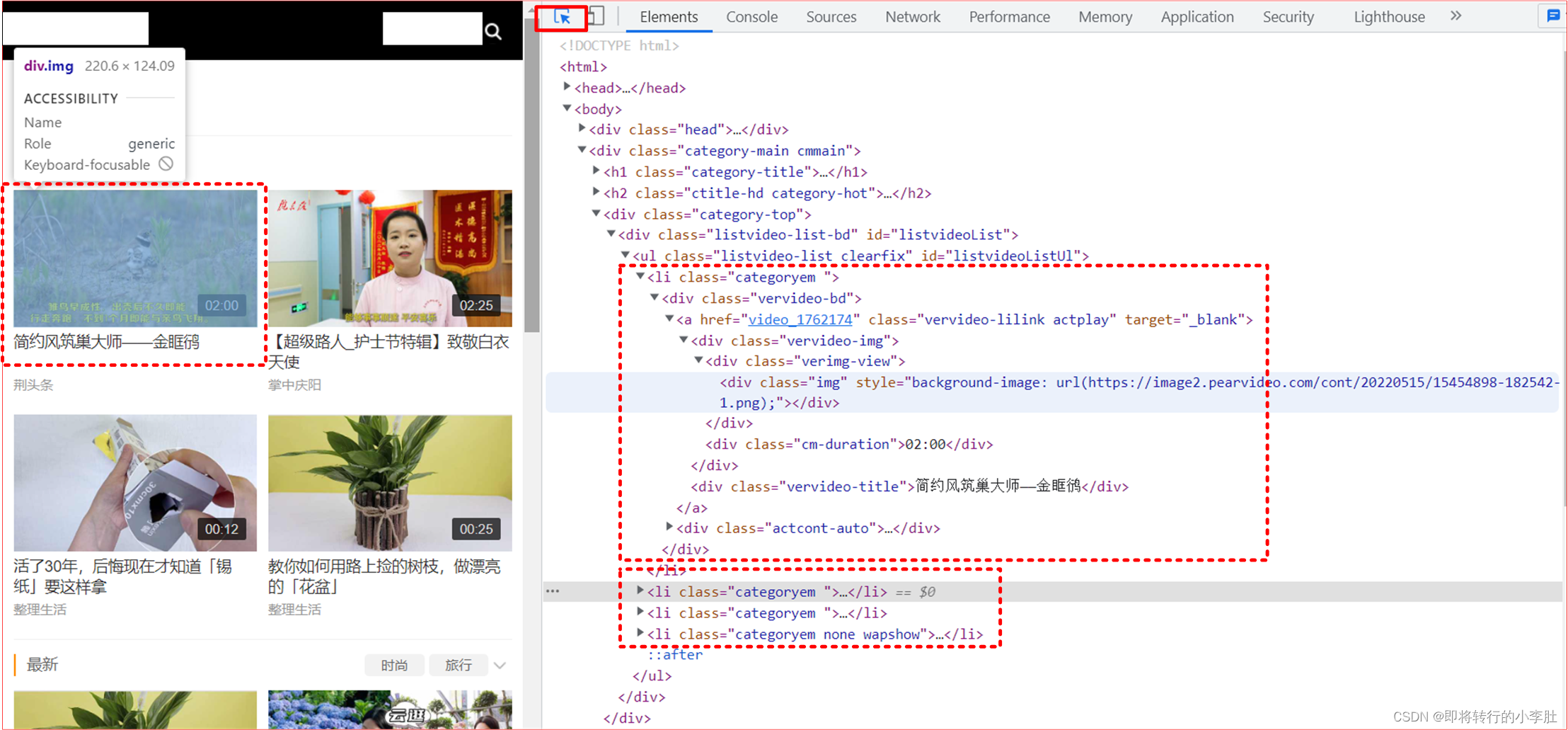
进入视频主页面: F12进入元素选择界面,随便点击一个视频略缩图,可以进入对应的标签,可以看到前四个视频应该都在 ul 标签的 li 标签下 从这个页面可以获取视频的详情页 URL 地址(需要进入详情页进一步获取下载地址)和视频名称 通过 xpath 定位到属性 id=“listvideoListUl” 的 ul 标签,然后定位到 li 标签 li_list=tree.xpath("//ul[@id='listvideoListUl']/li")此时获取到的是一个 li 列表,遍历所有 li 标签,获取 a 标签下的属性 herf 和第二个 div 标签的文本内容(视频名称) name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'拼接获取详情页 URL: detal_url='...www.pearvideo.com/'+li.xpath('./div/a/@href')[0]这个地址还不是视频的直接地址
在 Headers 里有实际请求的实际 URL 地址,带有视频的 id 和一个 mrd 随机数(在请求时,mrd 可以使用 random() 生成一个随机数替代,然后用 params 传递参数) 实际上式无法访问的 而是要将 1652797150836 替换成 cont-+视频 id (具体原理不懂,欢迎大家探讨) ...video.pearvideo.com/mp4/third/20220513/cont-1762013-15192550-111602-hd.mp4将全部的 Response 列出方便观察取出地址,其实就是一个嵌套的 dict: { "resultCode":"1", "resultMsg":"success", "reqId":"f3461e8c-2e60-4c22-8f16-0f5d6aaeba1b", "systemTime": "1652797150836", "videoInfo":{"playSta":"1","video_image":"https://image1.pearvideo.com/cont/20220513/15192550-112403-1.png","videos":{"hdUrl":"","hdflvUrl":"","sdUrl":"","sdflvUrl":"","srcUrl":"...video.pearvideo.com/mp4/third/20220513/1652797150836-15192550-111602-hd.mp4"}} }可以看到需要替换的那一部分的值其实就是参数 systemTime,对这一项使用正则很容易实现替换: video_url=page_dict["videoInfo"]["videos"]["srcUrl"]#从 dict 里取出URL video_systemTime_dict=page_dict['systemTime']#从 dict 里取出 systemTime使用正则替换获得视频真实存储 URL : # 需要替换一部分字符 'cont-'+id_ download_url=re.sub(video_systemTime_dict, 'cont-'+id_, video_url)定义一个视频下载函数: def get_video(urls_): url_=urls_['url'] print('正在下载'+urls_['name']+'!!!') video_data=requests.get(url=url_,headers=headers).content #持续化存储 with open (urls_['name'],'wb') as fp: fp.write(video_data) print(urls_['name']+"下载完成!!!")创建 pool 对象,下载完后关闭线程池 pool=Pool(4) pool.map(get_video,urls) pool.close() pool.join() from lxml import etree import re import random import requests from multiprocessing.dummy import Pool #需求:爬取视频数据 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36' } # 原则:线程池处理的是阻塞且耗时的操作 # 对下述 URL 发请求 解析出视频详情页的url和视频名称 url='...www.pearvideo.com/category_5' page_text=requests.get(url=url,headers=headers).text tree=etree.HTML(page_text) # // 表示查询所有子孙节点 / 表示查询某个节点下的下一个节点,只查询子一辈 . 表示选取当前节点 li_list=tree.xpath("//ul[@id='listvideoListUl']/li") urls=[] for li in li_list: # 获取不到正确的视频解析地址 detal_url='...www.pearvideo.com/'+li.xpath('./div/a/@href')[0] # /@ 表示取当前标签里的属性值 name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4' print(detal_url,name) # 对视频详情页发请求 id_=(li.xpath('./div/a/@href')[0]).split('_')[1] # 重新定义url、headers ajax_url='...www.pearvideo.com/videoStatus.jsp?' ajax_headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36', 'Referer':'...www.pearvideo.com/video_'+id_ } params={ 'contId':id_, 'mrd':str(random.random()) } page_dict=requests.get(url=ajax_url,params=params,headers=ajax_headers).json() # 从详情页中解析出视频的url # ? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 video_url=page_dict["videoInfo"]["videos"]["srcUrl"] video_systemTime_dict=page_dict['systemTime'] # 实际视频地址:...video.pearvideo.com/mp4/third/20220513/cont-1762013-15192550-111602-hd.mp4 # 伪地址: ...video.pearvideo.com/mp4/third/20220513/1652778780046-15192550-111602-hd.mp4 # 需要替换一部分字符 'cont-'+id_ download_url=re.sub(video_systemTime_dict, 'cont-'+id_, video_url) video_dict={ 'name': name, 'url': download_url } urls.append(video_dict) print(urls) def get_video(urls_): url_=urls_['url'] print('正在下载'+urls_['name']+'!!!') video_data=requests.get(url=url_,headers=headers).content with open (urls_['name'],'wb') as fp: fp.write(video_data) print(urls_['name']+"下载完成!!!") pool=Pool(4) pool.map(get_video,urls) pool.close() pool.join()家人们突然发现原来视频真实地址可以直接点击视频详情页播放后,再按 F12 元素选择就会直接出现: |
 进入详情页后,按F12后,点击 network 刷新, 按 Ctrl+f 进入搜索,输入后缀名 .mp4 寻找疑似的视频地址,在 XHR 里找到一个 videoStatus.jsp?contId=1762013&mrd=0.32865430503405535 下的 Response 有类似视频地址
进入详情页后,按F12后,点击 network 刷新, 按 Ctrl+f 进入搜索,输入后缀名 .mp4 寻找疑似的视频地址,在 XHR 里找到一个 videoStatus.jsp?contId=1762013&mrd=0.32865430503405535 下的 Response 有类似视频地址 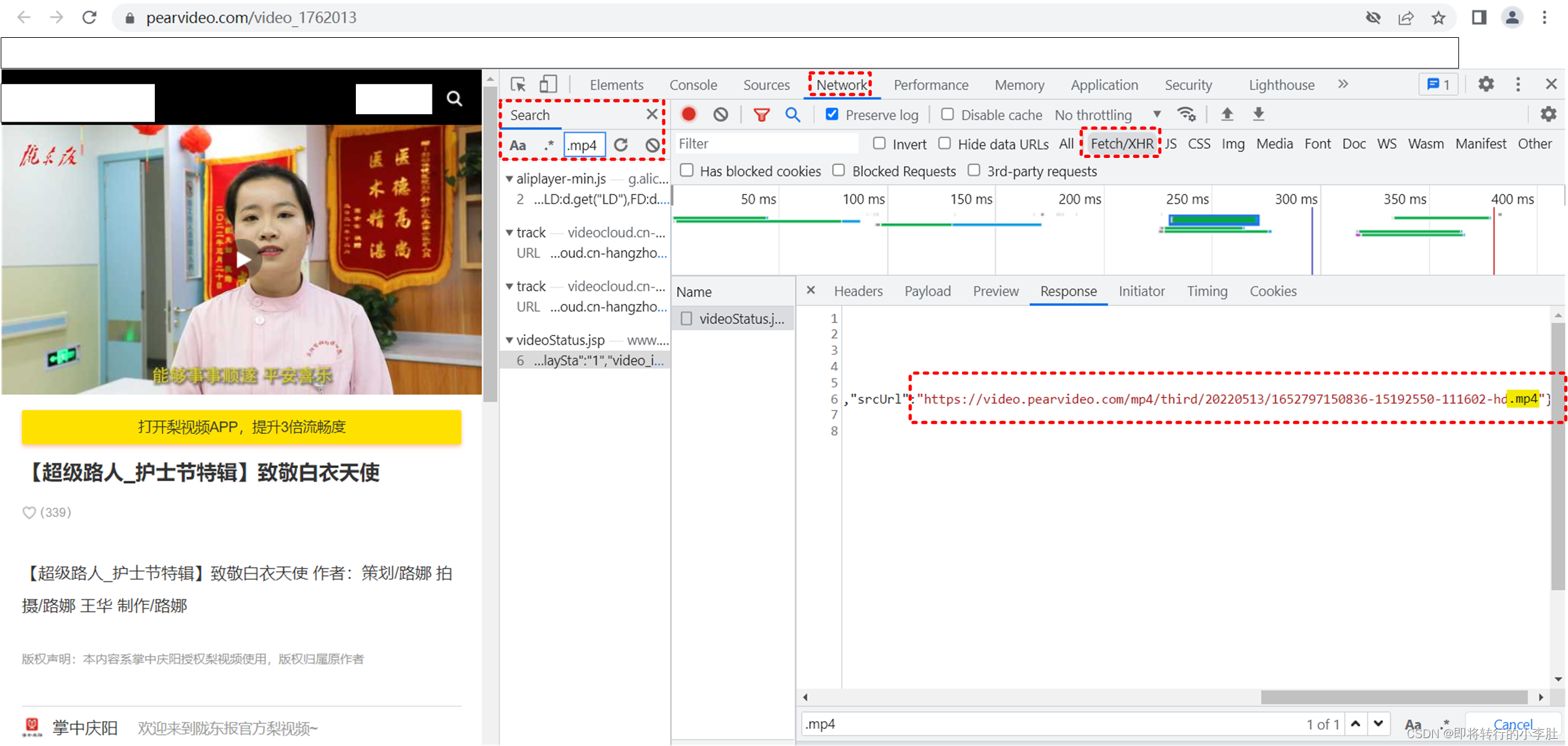
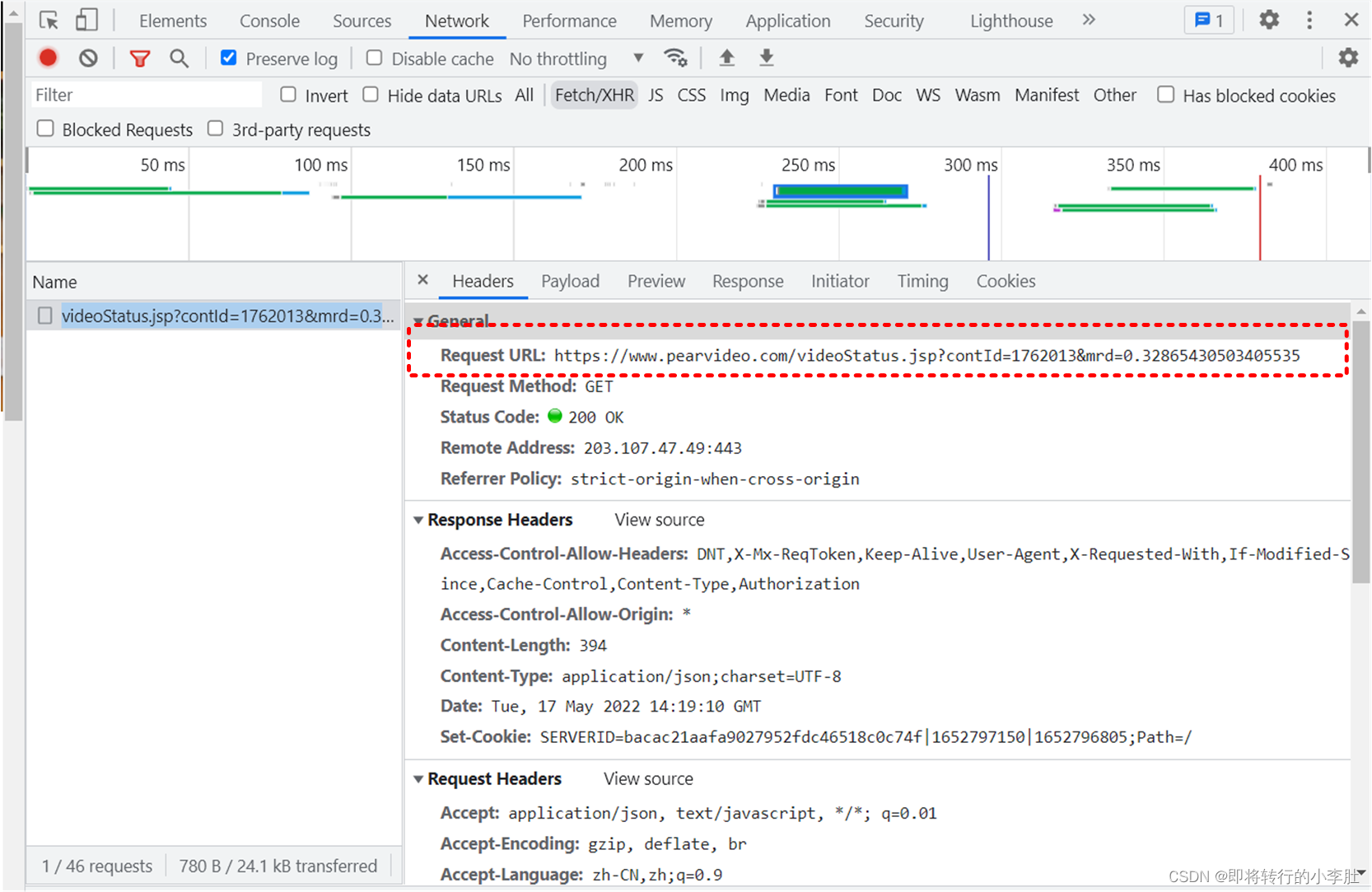 可以上面的实际请求的 URL 后的响应即 Response 得到视频对应的存储地址,如果直接使用 Response 里的键值:
可以上面的实际请求的 URL 后的响应即 Response 得到视频对应的存储地址,如果直接使用 Response 里的键值: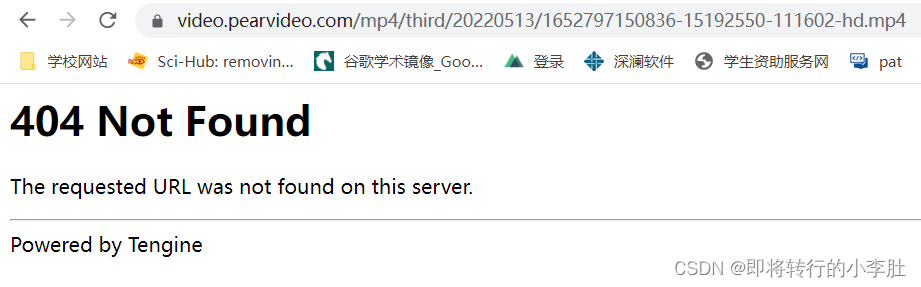 受到一个大佬的指点发现地址并不是:
受到一个大佬的指点发现地址并不是: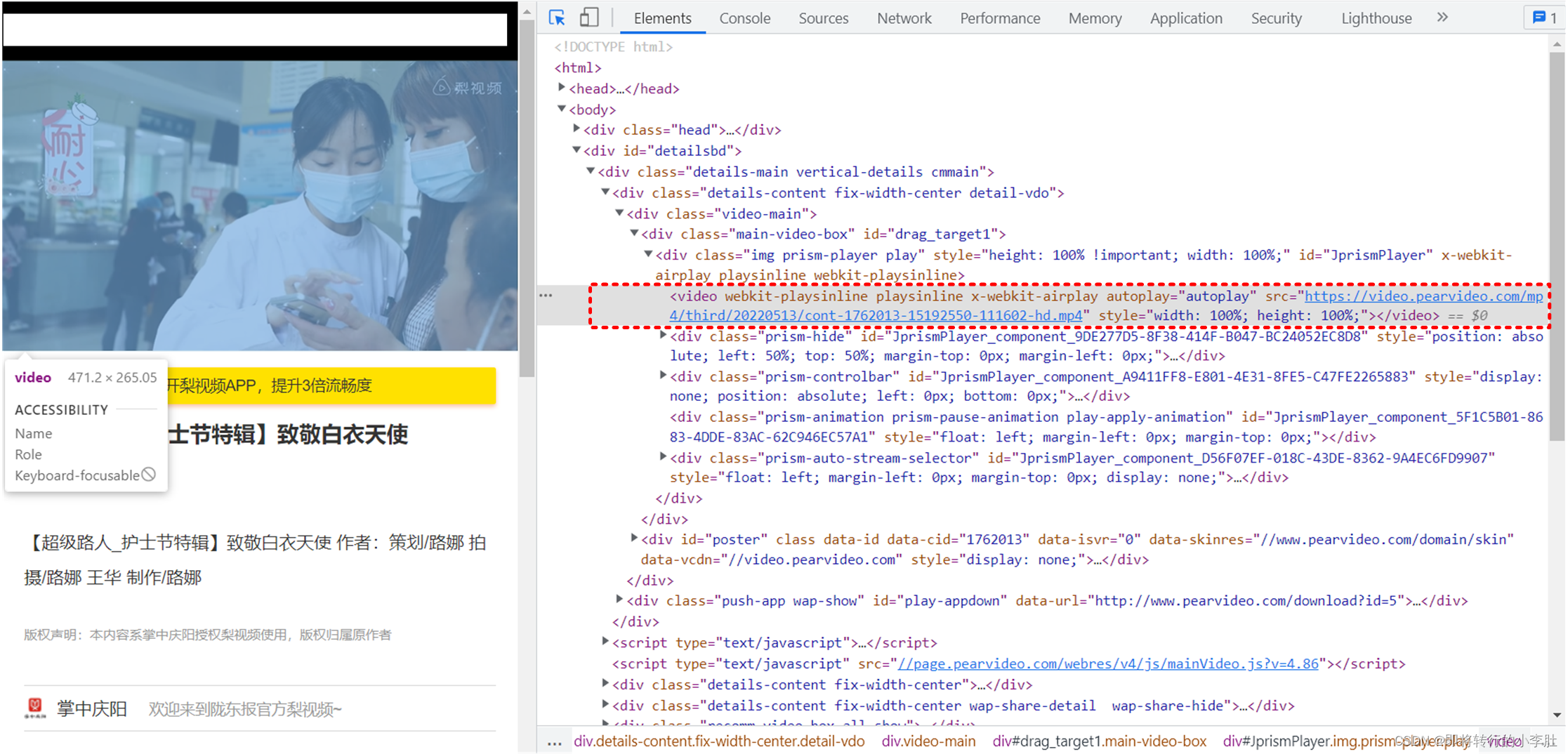
【本文地址】
今日新闻 |
推荐新闻 |