Python3 Request+Redis 爬取BILIBILI番剧列表 |
您所在的位置:网站首页 › e站动漫番剧 › Python3 Request+Redis 爬取BILIBILI番剧列表 |
Python3 Request+Redis 爬取BILIBILI番剧列表
|
该项目是结合Redis与Python爬虫爬取哔哩哔哩番剧索引中的所有番剧,目标网站链接如下: 番剧索引 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
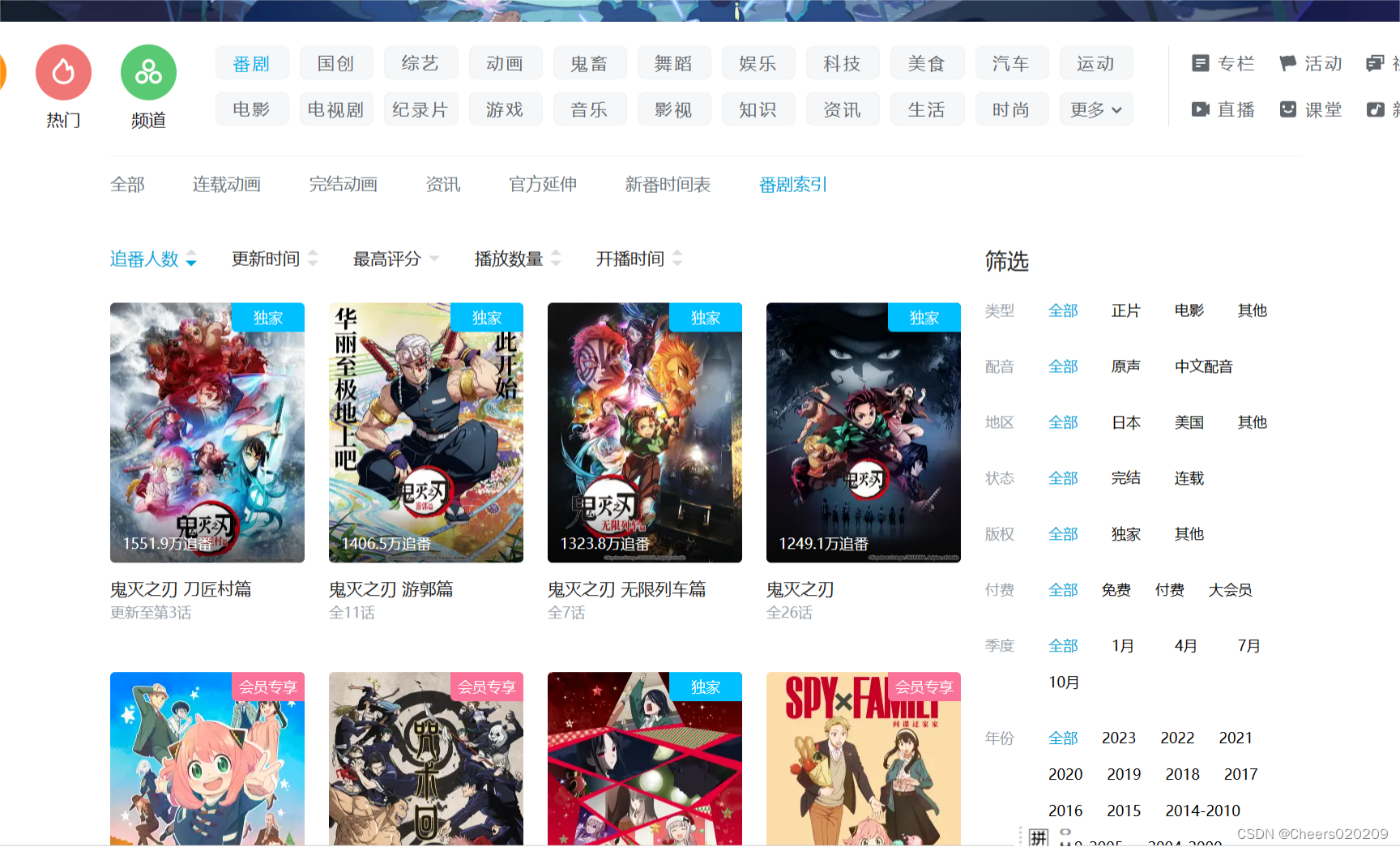
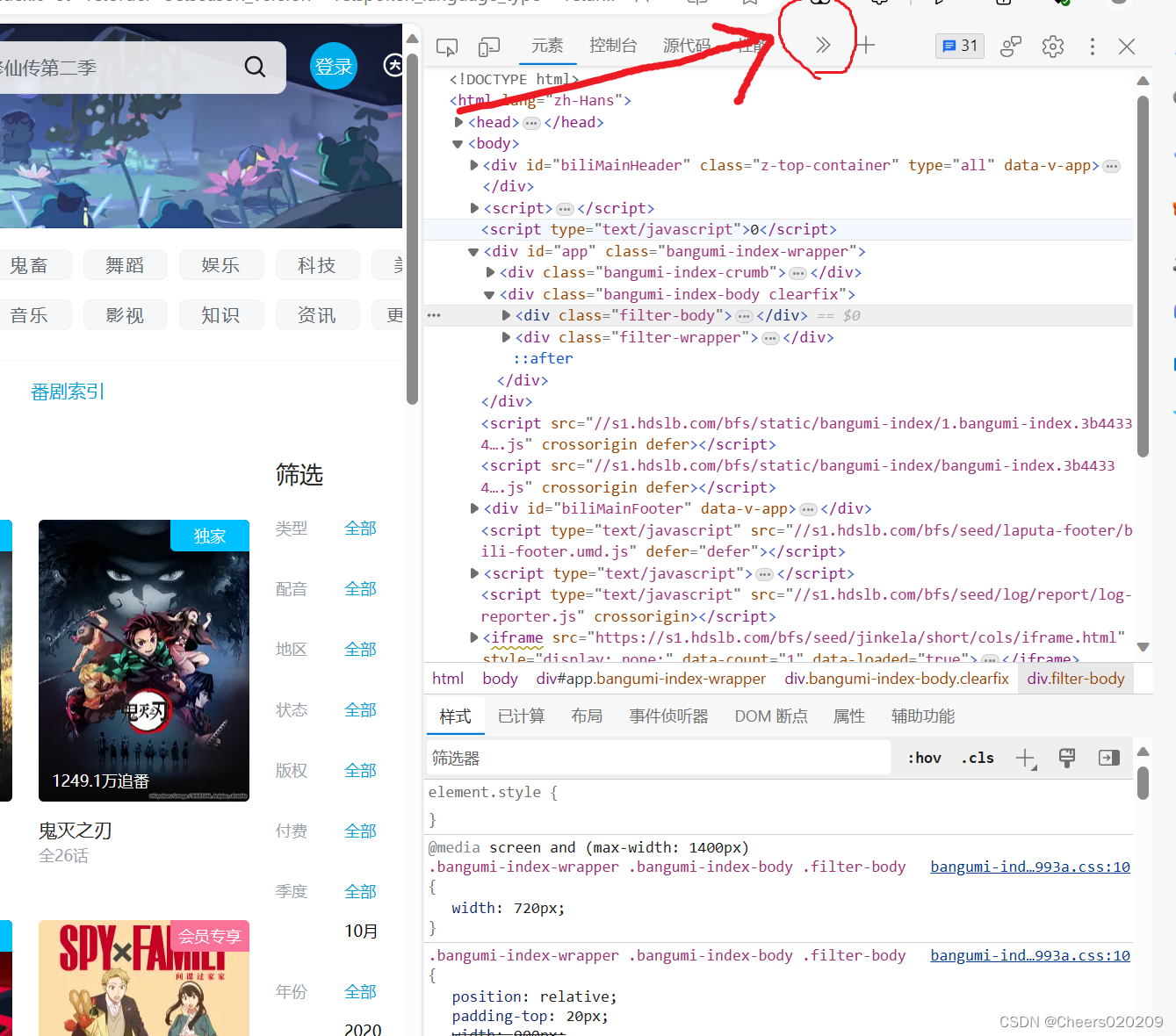
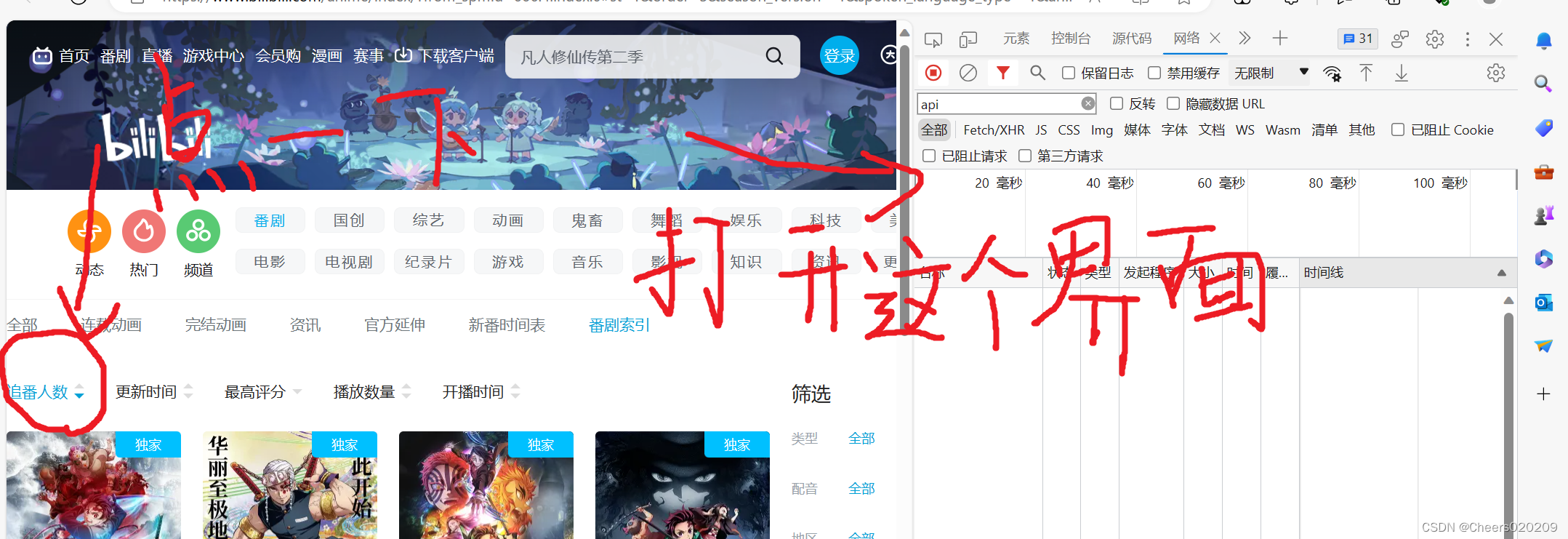
前情提要 该项目需要提前下载并配置好Windows版本Redis并下载Python Requests库和Redis库 一.找到b站番剧索引api在b站番剧索引页面按键盘f12打开浏览器开发者工具,或者鼠标右键点击页面选择“检查”选项
随后点击网络栏目,将网络栏目打开后,再点击一次“追番人数”
在右边就会出现api请求,(这里我点击了两下,选择最下面的请求,这样番剧的排序就会从比较新的开始排序)
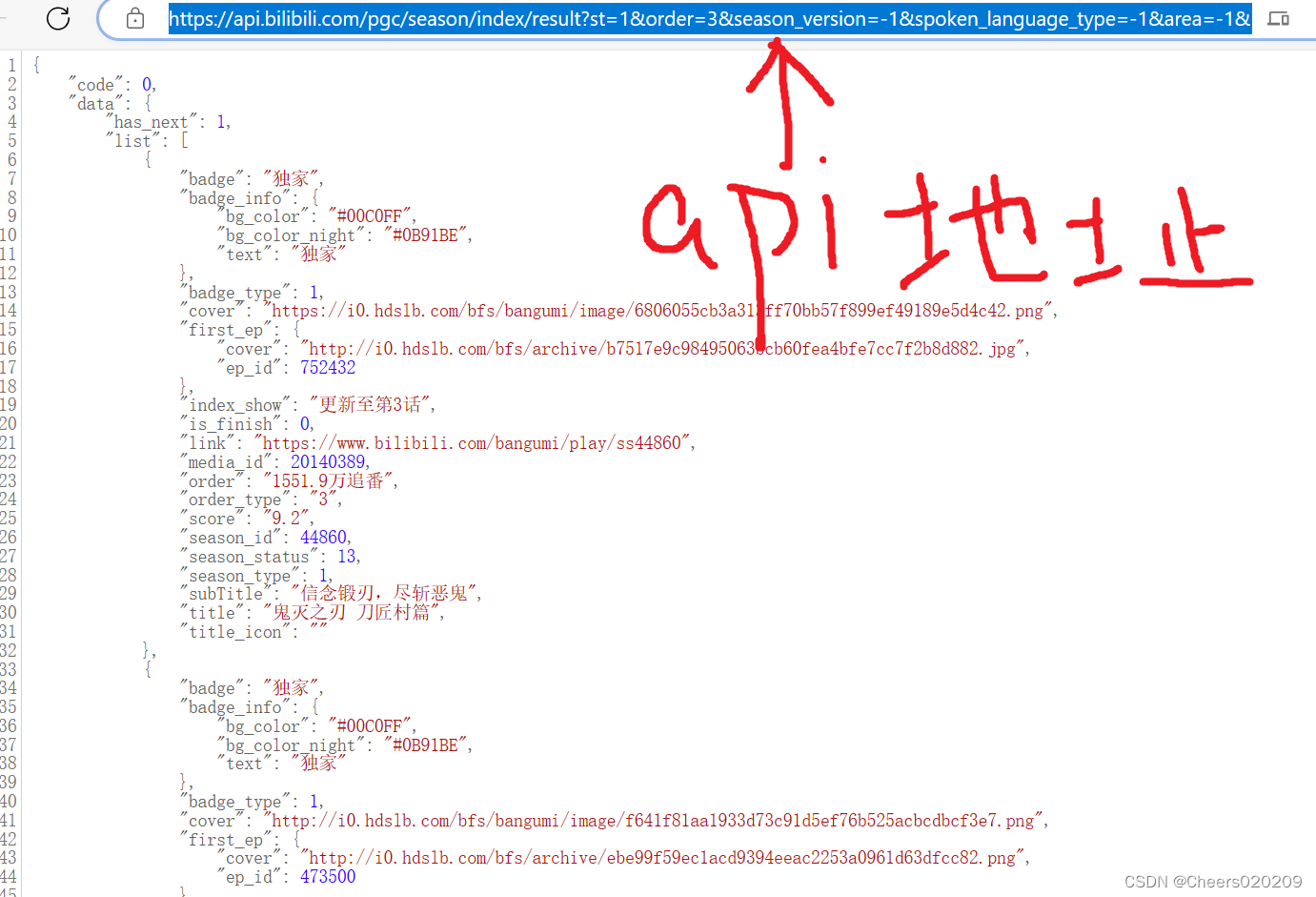
打开以后网址栏就是本次要使用的api地址,网页下方显示api请求的内容
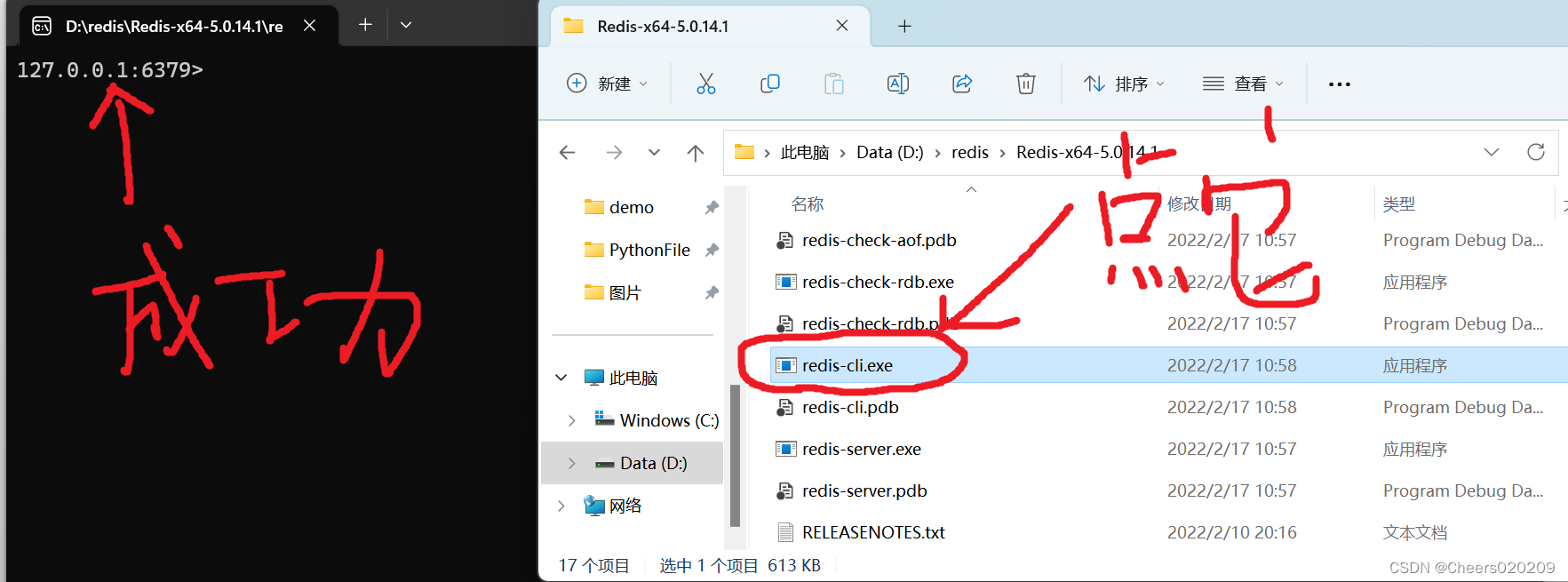
将这里的api地址保存下来,后面要用到。 (不确定b站以后会不会更新api地址,我先把我这里的显示的贴出来) api.bilibili.com/pgc/season/index/result?st=1&order=3&season_version=-1&spoken_language_type=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&sort=0&page=1&season_type=1&pagesize=20&type=1 可以看到地址中有一个参数page是处理请求的页码,我在番剧索引第一页找到的api,自然可以知道page=1,而pagesize是一个页面可以显示的番剧个数,很明显是20个,剩下一些参数是对番剧类型的一些筛选,无关紧要。 二.打开Redis记得把Redis打开方便调试代码,点击Redis目录下的redis-cli.exe,控制台出现端口号即为打开成功。
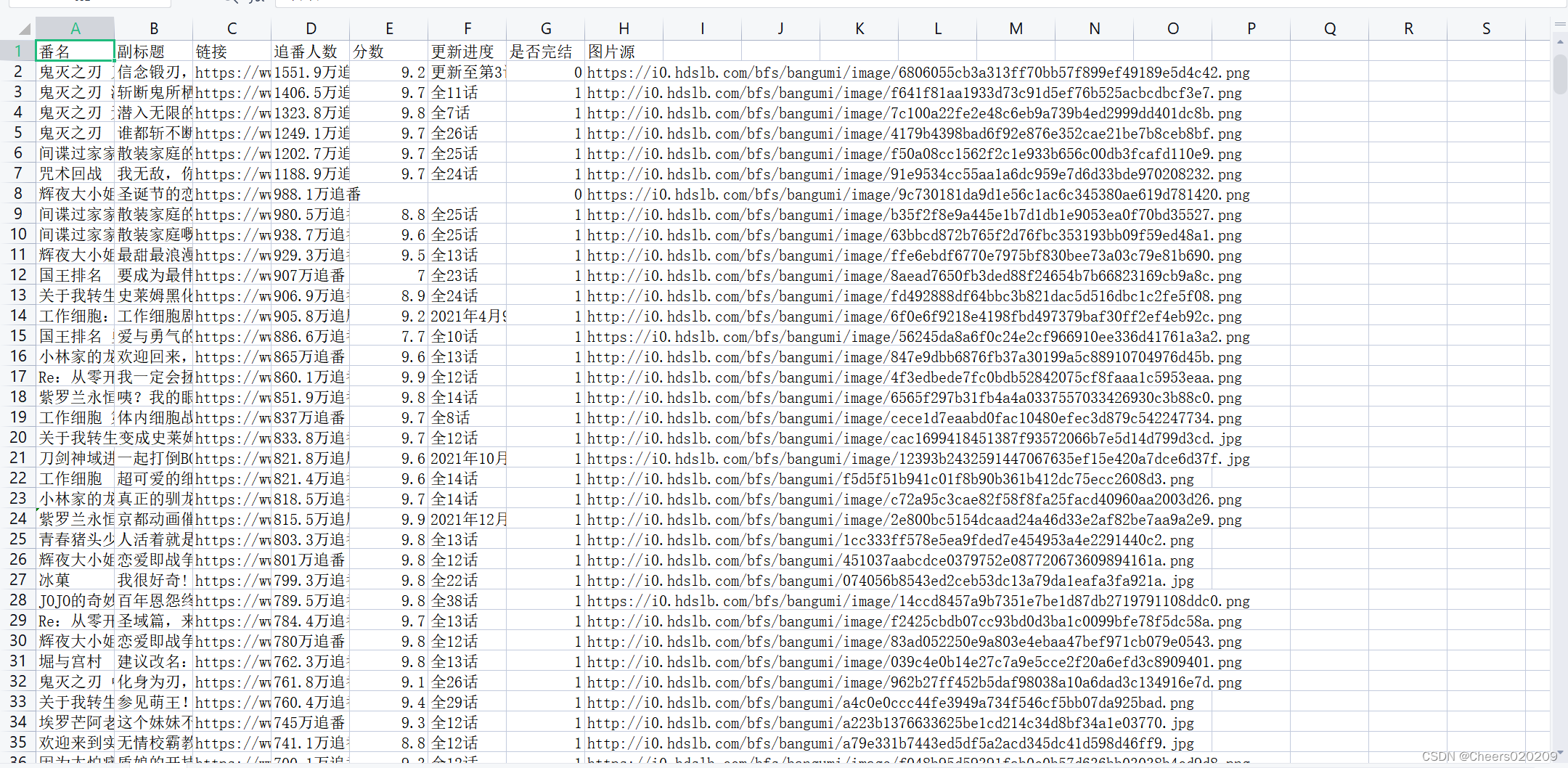
1.首先引入我们需要的库,这里把数据存放到csv文件里了 import requests import redis import json import csv2.建立Redis连接和工作序列 # 建立Redis链接 r = redis.Redis(host='127.0.0.1', port=6379) # 工作队列 Work = "WorkingSequence"3.顺手再定义一个计数器,计数我们爬过多少页面 # 爬取页面计数 pa = 04.将所有待爬取的页面url放到工作序列中,页码从1到172页,这里添加的顺序是从比较新的番剧开始的,如果像要倒序可以将api请求参数中sort值改为0,其余排序方式也可更改,order对应不同的排序方式 # sort=1为正序sort=0为倒序 # order=3为追番人数排序0为更新时间排序4为评分排序2为播放数量排序5为开播时间排序 for page in range(1, 172): # 将待爬页面加入工作序列 r.lpush(Work,"https://api.bilibili.com/pgc/season/index/result?season_version=-1&spoken_language_type=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&order=3&st=1&sort=0&page=" + str(page) + "&season_type=1&pagesize=20&type=1")5.建立csv,定义请求头 with open("test.csv", "w", newline='', encoding='utf-8') as csvfile: writer = csv.writer(csvfile) # csv第一行 writer.writerow(['番名', '副标题', '链接', '追番人数', '分数', '更新进度', '是否完结', '图片源']) # 请求头 Headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \ Chrome/84.0.4147.135 Safari/537.36"}6.写入csv,具体思想是每次从工作序列中弹出一个url,之后对这个url进行爬取,爬取出来的数据转换为json格式以便Python对其进行字典操作,代码运行完毕后,工作序列刚好清空。(api请求内容转化为json格式后还需要进行转化,因为在关键字‘list’后面有个中括号,没办法直接操作,这里我多转换了两次把json转换为字符串又把字符串转换为了json) # 工作序列不清空循环会一直持续 while r.llen(Work) != 0: # 从工作序列中弹出url url = str(r.rpop(Work), encoding="utf-8") # 爬取该url category = requests.get(url, headers=Headers) # 将爬取信息转化为json格式 data = json.loads(category.text) for text in data['data']['list']: # 下两步来回转化去掉list后的“[]” DataString = json.dumps(text, ensure_ascii=False) Datajson = json.loads(DataString) # 写入csv writer.writerow([eval(json.dumps(Datajson["title"], ensure_ascii=False)), eval(json.dumps(Datajson["subTitle"], ensure_ascii=False)), eval(json.dumps(Datajson["link"], ensure_ascii=False)), eval(json.dumps(Datajson["order"], ensure_ascii=False)), eval(json.dumps(Datajson["score"], ensure_ascii=False)), eval(json.dumps(Datajson["index_show"], ensure_ascii=False)), eval(json.dumps(Datajson["is_finish"], ensure_ascii=False)), eval(json.dumps(Datajson["cover"], ensure_ascii=False)), ]) pa += 1 print("完成第" + str(pa) + "页")7.养成好习惯最后把csv文件关闭 csvfile.close() 四.运行运行完成后打开test.csv文件看到成果
总共有三千四百多番剧 |

【本文地址】