案例分享:使用 Python 批量处理统计年鉴数据(上) |
您所在的位置:网站首页 › excel表格看不到子表 › 案例分享:使用 Python 批量处理统计年鉴数据(上) |
案例分享:使用 Python 批量处理统计年鉴数据(上)
|
目录一、引言二、案例背景三、处理过程 1. 解决数据不可读问题 2. 提取行业名称,生成对照字典 3. 检查是否存在多Sheet表 4. 合并所有年鉴表到一个表格中 5. 转换数据类型,验证是否存在异常数据四、总结五、Python教学系列内容本文共10208个字,阅读大约需要26分钟,欢迎指正!Part1 引言 作为政府机构出版的官方统计数据,统计年鉴中数据的研究价值不必多说,但处理这些数据却不是一件容易事。不同类型的统计年鉴来源于不同机构,即使是相同机构不同年份出版的年鉴格式也不完全一样,有的是网页,有的是Excel 表,有的是 PDF。好在知网已经对这些统计年鉴进行了收集整理,将其全部处理为 Excel 表并提供给用户下载。尽管如此,在使用或处理这些数据时仍会遇到各种各样的问题,常见的问题有: 知网提供的年鉴是加密的 Excel 表,无法使用 Stata 等软件进行读取变幻莫测的续表,时有时无的 Sheet 表统计口径不一致、指标内容不一致……抛开数据口径和内容问题不谈,年鉴表本身的处理就已经难倒了很多人,不少学者无奈选择手动整理数据。我们认为,处理统计年鉴表虽难,但并非毫无办法,本期文章我们就以一个实际案例为背景,向大家介绍如何使用 Python 批量整理统计年鉴数据,并提供一套完整的处理思路。  更多详情可点击原文链接查看: Part2 案例背景为研究近几年不同地区不同行业(本次分析44个行业)主要经济指标的变化规律,需要将不同年份的统计年鉴表整理合并在一张表中,数据已经事先采集完毕并按照内容命名,原始数据(2021年)如下图所示。  上图所示统计年鉴表的数据格式均如下图所示(每个年鉴表都有一个主表,一个续表)。  最后需要整理为如下图所示面板表格(没有截全,实际包含了上图中两张子表的全部指标)。  Part3 处理过程 Part3 处理过程本文只演示案例中处理 2021 年 44 个行业的统计年鉴数据的流程。这 44 个统计年鉴表的原始文件存放在同一个文件夹下:D:\统计年鉴\2021原始xls文件。 1 解决数据不可读问题一般来说,处理数据的第一步是读取数据。但使用 Python 的 Pandas 库读取知网下载的统计年鉴时,被提示工作表是受保护的,故无法读取。尝试使用 Stata 软件导入数据也遇到了类似问题。最后经过测试,使用 Excel 软件或 WPS 软件将原始的.xls类型的统计年鉴另存为.xlsx文件,然后再使用 Python 或 Stata 就可以导入了。所以用Python处理统计年鉴数据的第一步就是先将的.xls类型的年鉴表转为.xlsx类型。 为什么加密的.xls文件另存为.xlsx文件后就可读了呢?这是因为两种类型文件的加密范围是不一样的。.xls 文件加密的是表中的数据值,导致程序读取数据时受到阻挠;而.xlsx加密的是整个工作表,这不妨碍文件的可读性。虽然另存为.xlsx文件后,表格还是加密的,都不允许用户修改表中的数据值,但后者却可以被正常地读取了。 .xls文件是二进制文件,所以我们不可以像对待文本文件那样,通过修改文件后缀名来改变文件类型。如果真的这样操作,不仅不会达到目的,还有可能损坏文件。正确的做法是使用 Excel 软件或 WPS 软件打开.xls工作表,然后在【文件】选项中选择将表另存为.xlsx类型的表。 如果要处理的统计年鉴表不多,那么手动将表格另存为可以读取的.xlsx文件当然无可厚非。不过当有非常多的统计年鉴表需要转为.xlsx文件时,使用 Python 批量转换是一个更高效的方法。使用 Python 第三方库Win32com可以操作本地计算机(Windows系统)中的 Excel 软件帮助完成另存操作,速度要比人工处理快得多,完成批量另存的代码如下。 import os import win32com.client as win32 # 定义将一个文件夹下所有 xls 文件全部另存为 xlsx 文件,并保存到指定文件夹下的方法 def Transform_excel(input_path, output_path): ''' input_path: 存放 xls 文件的文件夹的路径, 最好是绝对路径 output_path: 存放另存后的文件所在文件夹的路径, 最好是绝对路径, 建议是空文件夹 ''' # input_path 文件夹下面所有的 .xls 文件的名称 fileList = [path for path in os.listdir(input_path) if path.endswith('.xls')] for i in range(len(fileList)): # 文件和格式分开 file_name = os.path.splitext(fileList[i]) if file_name[1] == '.xls': # 要转换的 excel 的路径 transfile1 = os.path.join(input_path, fileList[i]) # 转换后的 excel 存放的路径 transfile2 = os.path.join(output_path, file_name[0]) # 调用 excel 软件 excel=win32.gencache.EnsureDispatch('excel.application') # 设置 excel 后台运行,桌面不可见 excel.Visible = False # 打开要转换的 xls 文件 XLS=excel.Workbooks.Open(transfile1) # 另存为xlsx格式 XLS.SaveAs(transfile2 + ".xlsx", FileFormat=51) # 51 表示另存为 xlsx 格式,6 则是 csv 格式 # 关闭文件 XLS.Close() excel.Application.Quit() excel.Quit() # 下面是调用上述方法的代码 XLS_folder = r'D:\统计年鉴\2021原始xls文件' XLSX_folder = r'D:\统计年鉴\2021转换后xlsx文件' # 需要实现创建好存放另存后xlsx文件的文件夹 Transform_excel(XLS_folder, XLSX_folder) # 调用上述方法完成操作如果存放.xls格式的统计年鉴表存放在不同的文件夹下,那么我们可以先获取所有存放原始年鉴表的文件夹,然后循环调用上述自定义方法,就可以一次性将所有不可读取的统计年鉴表转为可读的统计年鉴表了。 此外,如果你安装的是 WPS,而不是 Excel,那么不用担心,经过实测,使用上述代码(无需修改)也可以调用本地安装的 WPS 软件完成另存操作。不过使用完毕后,最好在任务管理器中强制结束 WPS 后台进程,否则下次使用 WPS 打开文件时会卡住。最后,在使用上述代码之前,记得关闭 Excel 或 WPS 软件。 2 提取行业名称,生成对照字典根据目标,最终整理完成的数据中,还需要添加五个字段,分别是年份、行业名称、行业代码、省份名称、省份代码。其中省份名称就是年鉴表中已经存在的地区字段,年份可以从存放统计年鉴表的文件夹名称中提取,行业名称字段可以从统计年鉴表文件名称中提取,而行业代码和省份代码两个字段则分别需要根据行业名称和省份名称来得到。这一步就是要事先生成行业名称与行业代码的对照,以及省份名称与省份代码的对照。 根据下图所示的统计年鉴表文件名可以发现,文件命名规则为 序号 + “按地区分组的” + 行业名称 +“主要经济指标.xls”那么我们可以使用 Python 正则表达式提取文件名中的行业名称,代码如下。 import os, re # 导入操作系统库和正则表达式库 XLS_folder = r'D:\统计年鉴\2021原始xls文件' # 存放原始年鉴的文件夹路径 # 读取 XLS_folder 下所有的 .xls 文件的文件名 File_names = [f for f in os.listdir(XLS_folder ) if f.endswith('.xls')] # 去除文件名称前后不需要的文字,留下的就是行业名称,得到的是行业名称列表 Idustry_names = [re.sub('^.*?分组的|主要经济指标.*?xls$', '', name) for name in File_names] # 生成一个行业名称字典,键是行业名称,值是空字符 INDUSTRY_CODE_DICT = {Key:'' for Key in Idustry_names} INDUSTRY_CODE_DICT上述代码得到如下图所示对照字典。  下面将得到的字典复制出来,并根据《2017 国民经济行业分类》手动填充对应的行业代码,最后将填充完毕的对照字典写入 json 文件,以便下次使用。写入 json 文件的 Python 代码如下。 import json # 使用 open() 函数创建目标文件,采用可显示中文的编码 with open("Industry_dict.json", mode='w', encoding='utf-8-sig') as File: # 使用 json 库将字典写入 json 文件。(实际上 json 文件也是一种文本文件) # 变量 INDUSTRY_CODE_DICT 是填充后的行业代码对照字典 json.dump(INDUSTRY_CODE_DICT, File, ensure_ascii=False, indent=4)随后根据年鉴数据表中的省份名称,生成省份名称与省份代码的对照字典,这一步手动整理即可,然后再将整理好的字典以同样的方式写入 json 文件。写入后的 json 文件内容如下图所示。   3 检查是否存在多 Sheet 表 3 检查是否存在多 Sheet 表不同年份、类型的统计年鉴表的数据分布方式可能会有不同,有的是将所有表格存放在一个 Sheet 中,如果有多个表,就以续表的形式排布;有的则是将续表存放在多个 Sheet 表中,如下图所示。   虽然我们要处理的统计年鉴表属于同一类,几乎不太可能出现形式不统一的情况,不过为了保险起见,我们还是要验证一下是否存在含多个 Sheet 表的年鉴表,以免遗漏数据。下面是使用 Python 获取一个文件夹下所有统计年鉴表中 Sheet 表数量的代码(注意这里读取的是另存后的.xlsx文件,因为无法读取原始的.xls文件)。 import os from tqdm import tqdm # 循环进度条 from openpyxl import load_workbook # 导入读取 sheet 的函数 def Get_sheet_num(dir_path): '''获取文件夹中每个 excel 表的 sheet 数量''' Target_dict = {} # 获取所有 .xlsx 文件的名称 File_list = [os.path.join(dir_path, f) for f in os.listdir(dir_path) if f.endswith('.xlsx')] for path in tqdm(File_list): # 循环验证输出文件夹下的所有 excel 表 wb = load_workbook(path) # 加载 excel 表 Allnames = wb.sheetnames # 获取一张 excel 表的所有 sheet 名称 while 'CNKI' in Allnames: # 知网下载的年鉴中都有一个名为“CNKI”的sheet, 其中存放的内容与年鉴数据无关,这里删除掉它 Allnames.remove('CNKI') # 获取 sheet 表的数量 Target_dict[os.path.basename(path)] = len(Allnames) return Target_dict Sheet_num= Get_sheet_num(r'D:\统计年鉴\2021转换后xlsx文件') if len(set(Sheet_num.values())) == 1 and list(Sheet_num.values())[0] == 1: # 如果所有统计年鉴的 sheet 数量都一样,都等于 1,那么就输出下面这句话 print('所有表格都只有 1 个 Sheet 表')上述代码中,变量Sheet_num就是统计 sheet 表数量的结果,其内容如下图字典所示。字典的键是年鉴表文件名称,值是该年鉴表文件中 sheet 的数量。最后经过分析,所有统计年鉴表都只有一个 sheet 表,所以后续处理过程只读取统计年鉴表的第一个 sheet 即可。  4 合并所有年鉴表到一个表格中 4 合并所有年鉴表到一个表格中合并年鉴的准备工作已经完毕,下面开始将所有表格合并保存到一个面板数据中。这里我们使用 Python 中最常用的数据处理分析库 Pandas 进行处理。这一步需要解决的麻烦有不少,以 2021 年 44 个行业的统计年鉴表举例,每个表中都存在续表,而且由于年鉴表数据的表头处经常使用合并单元格,导致表头的处理相当麻烦。如下图所示,看起来整洁干净的表格,用 Python 读取后却变得混乱不堪。 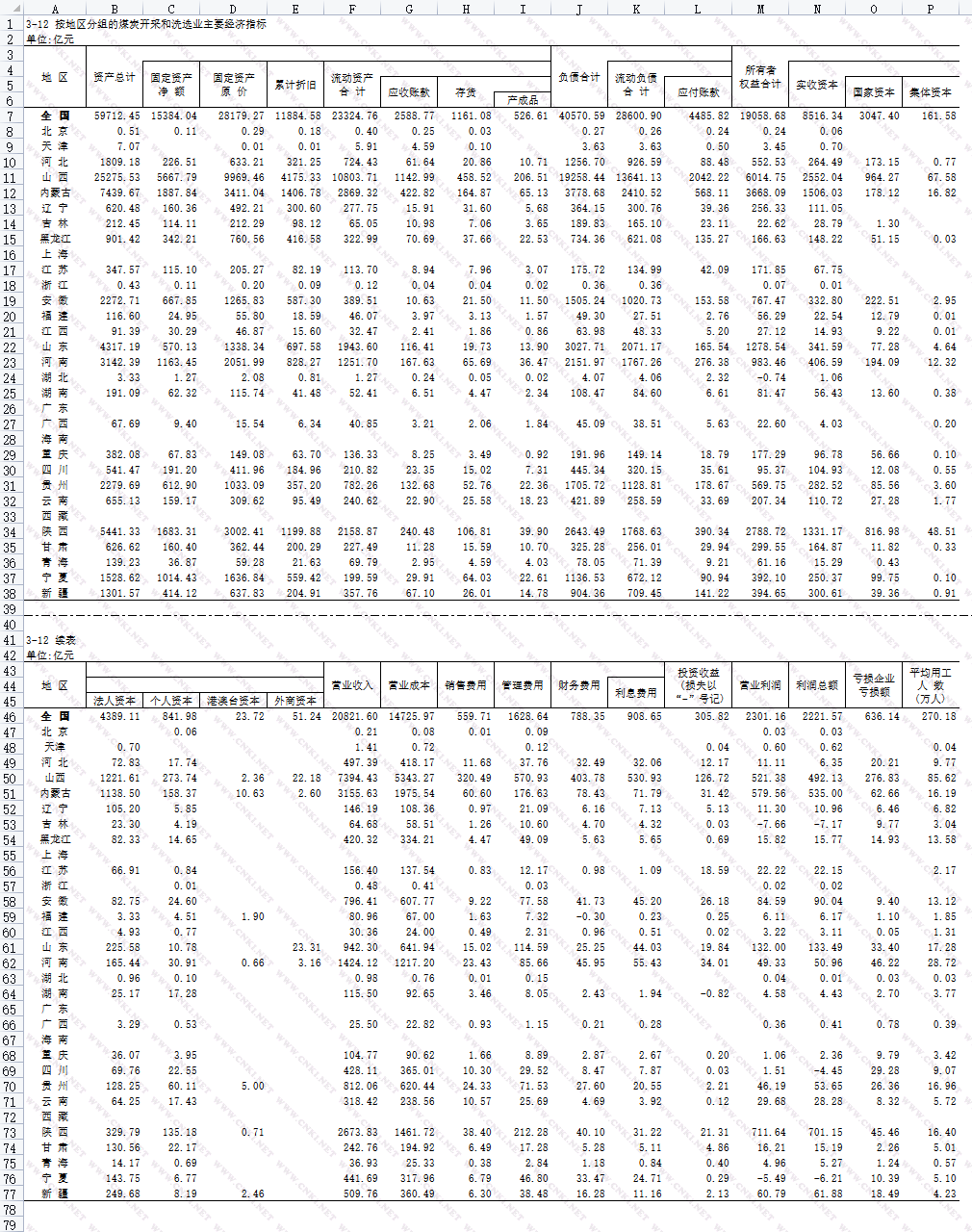  单从 Python 读取后的表格来看,表头(字段名)的处理确实麻烦,不过就事论事的话,处理这批统计年鉴表的表头其实并不难。由于所有统计年鉴表的格式都是一样的,他们统计的都是相同的指标,所以只需要事先人工记录好表头,最后再像扣帽子一样把记录好的表头扣在数据头上即可。那么接下来只需要合并表中的续表即可。从年鉴数据表的内容来看,两张续表实际上是需要横向拼接在一起的。下面我们使用 Python 将一份年鉴表中的两张表合并为一张表,再将所有年鉴表合并后的表纵向拼接在一起即可,将两张表合并为一张表的主要思路是根据表中的关键字“续表”将整张表纵向一分为二,然后再根据两张表中共有的地区字段将他们匹配为一张表。下面是完整的处理代码。 import os,re,glob,json from tqdm import tqdm # 进度条模块 import pandas as pd import numpy as np # 事先记录的字段名 Col1 = ['地区', '资产总计', '固定资产净额', '固定资产原价', '累计折旧', '流动资产合计', '应收账款', '存货', '产成品', '负债合计', '流动负债合计', '应付账款', '所有者权益合计', '实收资本', '国家资本', '集体资本'] Col2 = ['地区', '法人资本', '个人资本', '港澳台资本', '外商资本', '营业收入', '营业成本', '销售费用', '管理费用', '财务费用', '利息费用', '投资收益', '营业利润', '利润总额', '亏损企业亏损额', '平均用工人数'] # 定义处理一个子表(续表)的函数,该函数为了后面的函数服务 def Get_useful_info(df): ''' 删除表格前面(上面)不需要的行 ''' df = df.applymap(str) # 表中所有内容转为字符型 for ind, row in df.iterrows(): row_info = ' '.join(row) # 将一行数据拼接在一起 if bool(re.search('全\s*?国', row.values[0])) or bool(re.search('\d+\.\d+', row_info)): # 如果在一行数据中,首列内容是“全国”,或者在这一行中找到了数字,那么这一行就是指标的第一行,前面的行统统舍弃 ind_num = ind break # 选取需要的数据行 df_res = df.iloc[ind_num:, :] # 返回的时候重置列索引 return df_res.reset_index(drop=True) def Merge_continued_table(df, Col1=Col1, Col2=Col2): ''' 合并一张表中的两张表(含续表),返回合并后的表 此代码只能处理含有一张续表的文件 ''' split_line = 0 for ind, val in enumerate(df.iloc[:, 0]): if bool(re.search('续\s*?表', val)): # 找到关键字【续表】,从这里将原表纵向一分为二,注意“续表”二字中可能还有空格 split_line = ind break assert split_line>0, '没有找到续表' # 验证是否找到续表 df1 = pd.DataFrame(df.iloc[:split_line, :].values, columns=Col1) # 上半部分表格, 删除空行 df2 = pd.DataFrame(df.iloc[split_line+1:, :].values, columns=Col2) # 下半部分表格, 删除空行 # 去除表上方没有用的行 df1 = Get_useful_info(df1) df2 = Get_useful_info(df2) # 删除全空的行 df1, df2 = df1.replace('', np.nan), df2.replace('', np.nan) df1 = df1.dropna(how='all').fillna('').reset_index(drop=True) df2 = df2.dropna(how='all').fillna('').reset_index(drop=True) # 根据 “地区” 字段将两张表合二为一 # 先预处理地区字段,去除该字段中的空格、换行符等,防止匹配过程出错 df1['地区'] = df1['地区'].apply(lambda x: re.sub('\s+', '', x)) df2['地区'] = df2['地区'].apply(lambda x: re.sub('\s+', '', x)) # 根据地区字段匹配两张表 df_processer = pd.merge(left=df1, right=df2, how='left', on=['地区']) # 修改字段名为需要的字段名 df_processer.rename(columns={'地区':'省份名称'}, inplace=True) return df_processer #################### 上面是用于合并处理一份年鉴的自定义函数 #################### ################## 下面是循环处理所有年鉴并合并为一张表的代码 ################## # 创建存放 2021 年全部统计年鉴数据的总表 DATA = pd.DataFrame() # 暂时是空表,后续逐一将处理后的表放入其中 # 读取第二步中处理好的 json 对照文件,用于添加行业代码和省份代码两个字段 with open('./Industry_dict.json', 'r', encoding='utf-8-sig') as F: INDUSTRUY_CODE = json.load(F) with open('./Province_dict.json', 'r', encoding='utf-8-sig') as F: PROVINCE_CODE = json.load(F) # 获取所有待处理统计年鉴的路径, 注意要处理的是另存后的 .xlsx 文件 All_files = glob.glob(r'D:\统计年鉴\2021转换后xlsx文件\*.xlsx') for PATH in tqdm(All_files): ''' 循环处理所有年鉴,每次循环处理一份年鉴,并添加到目标表中 ''' # 1. 从文件路径中获取年份 ABSpath = os.path.abspath(PATH) # 获取统计年鉴的绝对路径 DIR = os.path.dirname(ABSpath) # 获取统计年鉴所在的文件夹的路径 Folder = os.path.basename(DIR) # 获取统计年鉴所在的文件夹的名称 YEAR = re.findall('\d{4}', Folder)[0] # 从统计年鉴所在的文件夹的名称中提取年份 # 2. 获取行业名称和行业代码 Filename = os.path.basename(ABSpath) # 获取统计年鉴的文件名 Industry_name = re.sub('^.*?分组的|主要经济指标.*?xlsx$', '', Filename) # 从文件名中提取行业名称 Industry_code = INDUSTRUY_CODE[Industry_name] # 根据行业名称,得到行业代码 # 3. 读取数据表,将两张子表合并为一张大表 data = pd.read_excel(ABSpath).fillna('') # 读取一个统计年鉴表,并使用空字符填充缺失值 data = Merge_continued_table(data) # 使用上面定义的合并续表的方法去处理一份年鉴 # 4. 在表格的最前面添加需要的字段 data.insert(0, '年份', YEAR) data.insert(1, '行业名称', Industry_name) data.insert(2, '行业代码', Industry_code) data.insert(3, '省份代码', '') data['省份代码'] = data['省份名称'].map(PROVINCE_CODE) # 根据省份名称,映射省份代码,“全国”没有代码,映射后省份代码为空 ## 一张表的处理结束, 将一张表的结果添加到大表中去 DATA = pd.concat([DATA, data]).reset_index(drop=True) # 循环结束后,输出查看得到的面板数据 DATA上述代码执行完毕后,得到了2021转换后xlsx文件这一文件夹下所有统计年鉴表合并后的数据,如下图所示。  5 转换数据类型,验证是否存在异常数据 5 转换数据类型,验证是否存在异常数据知网整理提供的年鉴表中,所有数字的类型都是字符型,这是不利于分析计算的,所以我们需要将数字全部转为数字型。此外,由于一部分年份较早的统计年鉴表是使用 OCR 技术整理的,可能会存在一些识别出错的地方,例如数字3.15经过识别后变成了3·15,这种“伪数字”也是影响数据质量的一个因素,所以处理的最后一步就是要将面板数据中的字符型数字转为真正的数字,顺便还能检查是否存在“伪数字”,如果有,则需要手动改正。转换数字类型的代码如下。 # 获取所有的指标字段 ALL_COLS = Col1 + Col2 while '地区' in ALL_COLS: ALL_COLS.remove('地区') for col in ALL_COLS: try: # 使用 eval() 函数将字符型数字转为真正的数字,每次转一个字段 DATA[col] = DATA[col].apply(lambda x: eval(x) if x not in {'', '-'} and isinstance(x, str) else x) except Exception as e: # 如果遇到异常值,就输出出现异常值的字段名,并报告异常 print(col) raise e # 转换数值类型,并确认没有异常值后,将最终的面板数据保存为 Excel 表。 DATA.to_excel(r'D:\统计年鉴\2021分地区工业统计年鉴.xlsx', index=False)以上就是本文要分享的批量处理统计年鉴表的全部流程,如果你对处理年鉴有需求,或者有兴趣,可以点击原文查看。 统计年鉴表的形式有很多种,如何提取续表,如何清洗续表,这是两个较难处理的点。在本文案例中,由于我们要处理的几十份统计年鉴都是统一的格式,即所有统计年鉴都有一个主表和一个续表,主表和续表都是纵向分布的,并且所有的年鉴的指标都是一样的,所以在处理过程中,处理年鉴的代码非常具有针对性,还做了一些投机取巧的操作,例如提前写好字段名,这样做的目的其实就是节省精力,节省时间。不过当我们需要处理格式不一致的统计年鉴时,就不得不编写普适性更强的代码了,例如无论当一份年鉴中是否包含续表,包含多少个续表,无论表头多么散乱,我们都可以用一份代码将这些表格提取、清洗出来。 我们将在下期文章中向大家演示如何实现这个需求,届时笔者还会将全部代码和测试用的统计年鉴表全部免费赠送给大家。敬请期待! Part4 总结统计年鉴的数据样式有太多太多种,处理过程中面临的问题也不少。不过在本文清洗统计年鉴的案例中,已经向大家提供了解决基本问题的参考答案,希望对大家有所帮助。下期文章,我们将向大家演示如何处理更加复杂的统计年鉴表。 Part5 Python 教学系列内容学习 Python 第一步——环境安装与配置Python 基本数据类型Python 字符串操作(上)Python 字符串操作(下)Python 变量与基本运算组合数据类型-列表组合数据类型-集合(内含实例)组合数据类型 - 字典&元组Python 中的分支结构(判断语句)Python 中的循环结构(上)Python 中的循环结构(下)Python 函数的定义与调用Python 内置函数持续更新中......这里是大数据、分析技术与学术研究的三叉路口 |
【本文地址】
今日新闻 |
推荐新闻 |