利用Pandas拆分Excel的单元格为多行并保留其他行的数据 |
您所在的位置:网站首页 › excel表格怎样拆分单元格成2行 › 利用Pandas拆分Excel的单元格为多行并保留其他行的数据 |
利用Pandas拆分Excel的单元格为多行并保留其他行的数据
|
利用Pandas拆分Excel的单元格为多行并保留其他行的数据
1. 需求2. Pandas解决需求2.1 准备工作2.2 Python程序执行
3. Pandas实现需求过程详解3.1 碎碎念,可忽略3.2 解决需求过程3.2.1 Pandas读取、写入Excel3.2.2 Pandas拆分单元格为多行
4. 心得总结5. 参考文献
1. 需求
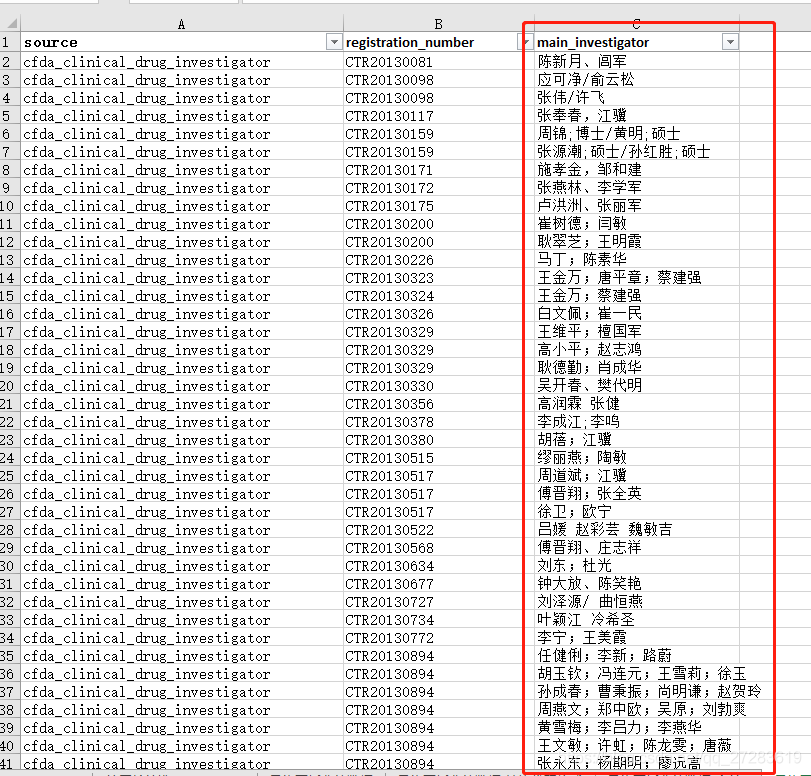
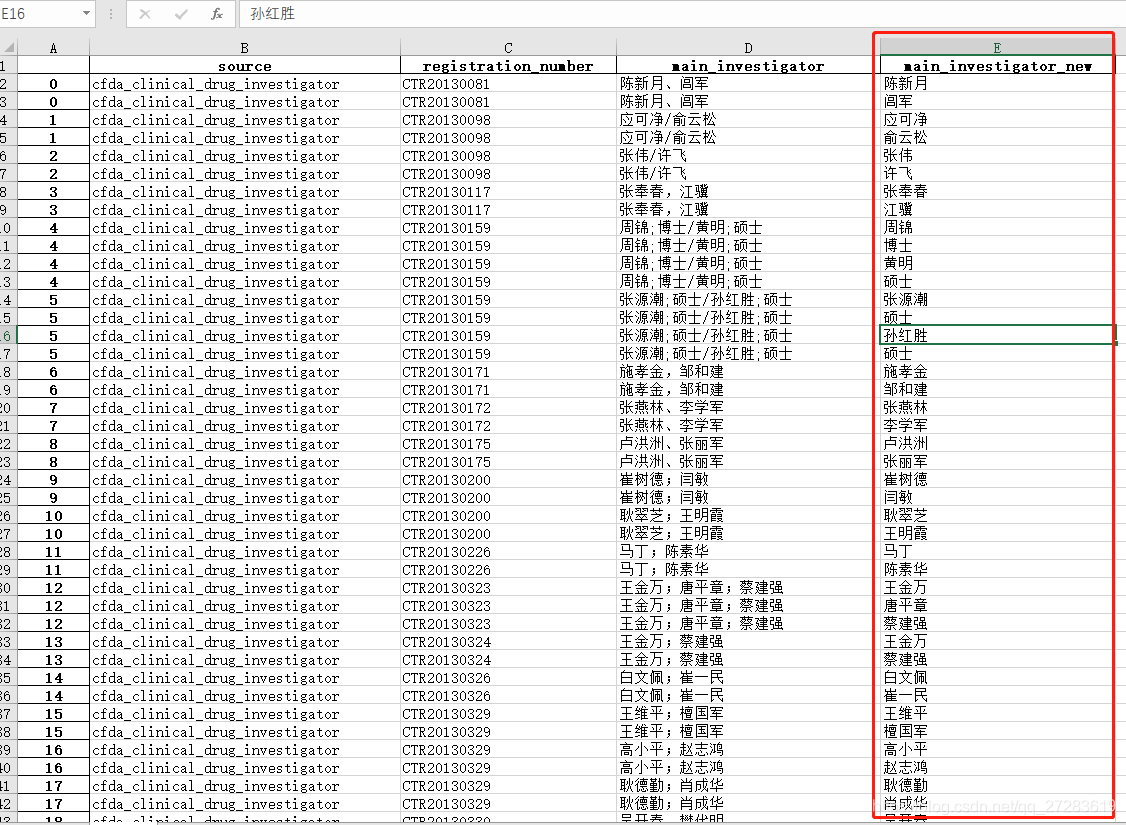
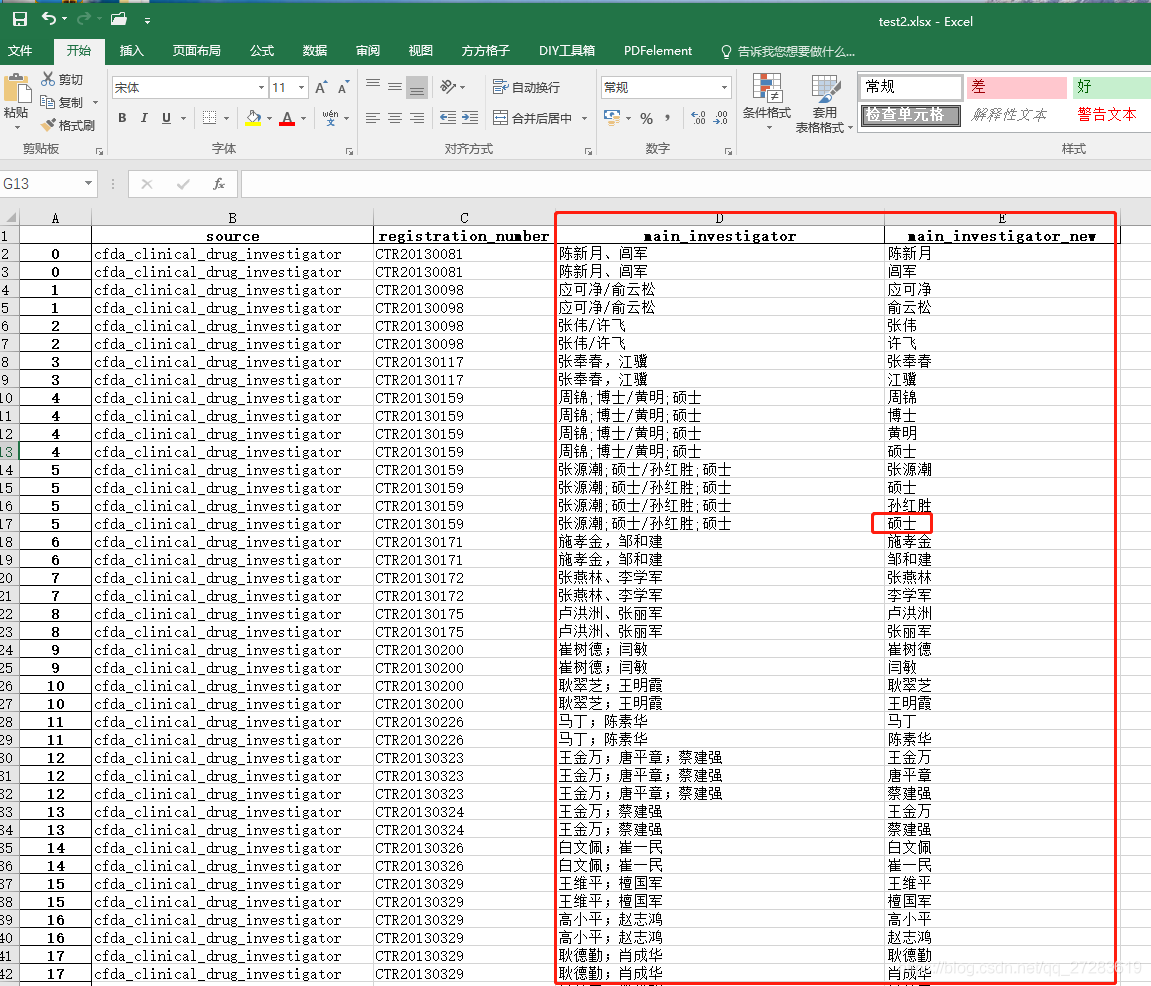
需求:对Excel中的C列(标红)所有单元格的内容进行拆分,同时保证其他行不变。如果着急完成任务,直接看第二部分,copy代码,简单修改,跑程序。 处理前:
处理后 整体代码如下: import pandas as pd # 读取Excel # 直接复制路径,Win下会有Bug,编码问题。所以Win下一定要手敲路径 df = pd.read_excel(r'C:\Users\admin\Desktop\test.xlsx') # 拆分单元格 df = df.drop(['main_investigator_1'], axis=1).join(df['main_investigator_1'].str.split(',', expand=True).stack().reset_index(level=1, drop=True).rename('main_investigator_new')) # 写入新的Excel writer = pd.ExcelWriter(r'C:\Users\admin\Desktop\test2.xlsx') df.to_excel(writer,'Sheet1') writer.save()执行结果: 刚开始我拿到这个任务的时候,一共有54994条数据,需要先筛选出研究者是两个或者两个以上的进行拆分。筛选出来之后,发现还剩下745条要进行拆分,如果纯人工,一个个去复制粘贴,那么非常地幔且繁琐。 所以果断度娘,发现网上大部分都是Excel中如何一个单元格变成几列,关于把Excel中一个的单元格变成几行,其他行不变的教程非常少。最后找到了两个利用VBA编程的方法来实现的,不过自己没有尝试过,主要是装的office没法打开VBA编程的界面,提示内存溢出,重装office费时太久,就考虑换方法了,后面参考文献会放出来,日后可以尝试。因为自己有Python的基础,同时之前也看过一些数据分析的书,大致了解Pandas和Numpy这些库。所以Google Python实现拆分Excel单元格为几行的方法,比较了一圈xlwings、openpyxl、pandas、xlutils等。最后发现还是Pandas的教程更多,在拆分单元格变为多行上应用很广。果断才用了。 3.2 解决需求过程因为当初学完Pandas就没再用过,基本都忘完了,所以我把Pandas解决需求分为了三个部分:1)Pandas读取Excel文件;2)Pandas写入Excel文件;3)Pandas拆分单元格,三个主要的功能模块。 解决1)和3)部分非常简单,这也是Pandas这方面做得很好。我直接拿python3 pandas读写excel这篇教程代码改一下,测试顺利通过。 接下来就是解决最核心的部分——拆分单元格。这个我看的是这篇教程pandas某一列中每一行拆分成多行的方法 下面我基本上照搬两篇教程的知识了。 3.2.1 Pandas读取、写入ExcelPandas读取Excel pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, parse_cols=None, parse_dates=False, date_parser=None, na_values=None, thousands=None, convert_float=True, has_index_names=None, converters=None, dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds) ''' 该函数主要的参数为io、sheetname、header、names、encoding。 io:excel文件,可以是文件路径、文件网址、file-like对象、xlrd workbook; sheetname:返回指定的sheet,参数可以是字符串(sheet名)、整型(sheet索引)、list(元素为字符串和整型,返回字典{'key':'sheet'})、none(返回字典,全部sheet); header:指定数据表的表头,参数可以是int、list of ints,即为索引行数为表头; names:返回指定name的列,参数为array-like对象。 encoding:关键字参数,指定以何种编码读取。 该函数返回pandas中的DataFrame或dict of DataFrame对象,利用DataFrame的相关操作即可读取相应的数据。 ''' # 代码示例: import pandas as pd # 读取Excel # 直接复制路径,Win下会有Bug,编码问题。所以Win下一定要手敲路径 df = pd.read_excel(r'C:\Users\admin\Desktop\test.xlsx') print(df)Pandas写入Excel DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None) ''' 该函数主要参数为:excel_writer。 excel_writer:写入的目标excel文件,可以是文件路径、ExcelWriter对象; sheet_name:被写入的sheet名称,string类型,默认为'sheet1'; na_rep:缺失值表示,string类型; header:是否写表头信息,布尔或list of string类型,默认为True; index:是否写行号,布尔类型,默认为True; encoding:指定写入编码,string类型。 ''' import pandas as pd # 写入新的Excel writer = pd.ExcelWriter(r'C:\Users\admin\Desktop\test2.xlsx') df.to_excel(writer,'Sheet1') writer.save() 3.2.2 Pandas拆分单元格为多行核心代码:df.drop(['main_investigator_1'], axis=1).join(df['main_investigator_1'].str.split(',', expand=True).stack().reset_index(level=1, drop=True).rename('main_investigator_new')) 具体解释: 将需要拆分的数据使用split拆分工具拆分,并使用expand功能拆分成多列将拆分后的多列数据进行列转行操作(stack),合并成一列将生成的复合索引重新进行reset保留原始的索引,并命名将上面处理后的DataFrame和原始DataFrame进行join操作,默认使用的是索引进行连接。 import pandas as pd # 读入Excel df = pd.read_excel(r'C:\Users\admin\Desktop\test.xlsx') print(df['main_investigator_1']) # 第一步:拆分,生成多列 print('第一步:拆分,生成多列') df_1 = df['main_investigator_1'].str.split(',', expand=True) print(df_1) # 第二步:行转列 df_1 = df_1.stack() print('第二步:行转列') print(df_1) # 第三步:重置索引,并命名(并删除多于的索引),同时命名字段 df_1 = df_1.reset_index(level=1, drop=True).rename('main_investigator_new') print('第三步:重置索引,并命名(并删除多于的索引)') print(df_1) # 第四步:和原始数据合并 df_new = df.drop(['main_investigator_1'], axis=1).join(df_1) print('第四步:和原始数据合并') print(df_new) print('拆分前数据') print(df)核心一句代码解决df.drop(['main_investigator_1'], axis=1).join(df['main_investigator_1'].str.split(',', expand=True).stack().reset_index(level=1, drop=True).rename('main_investigator_new'))。根据自己需要替换掉里面的split(',')中的逗号,比如用空格、;、/;等。 4. 心得总结 数据的处理一定要追求准确,严格控制自己的数据输入和输出。数据处理一定要有不同的方法,去校验自己的数据是否存在不符合标准的值,这个通常跟处理过程密切相关。数据的处理过程一定要有所记录,最好是详细记录,因为一旦数据出现问题,自己也可以回过头进行排查,定位到数据出错的步骤。数据出问题了,一定要先冷静思考,分析出错的原因,不要动不动就重头开始重新处理。这样往往会耗费大量的时间。前期可以适当多花时梳理于业务处理流程,保证数据处理流程没有问题,同时把一些需要注意的点做好标记。任务完成后,及时总结反思,对于方法进一步优惠,方便以后复用。 最后附上,我本次数据处理的流程图(图形的使用的不太规范,下次规范起来):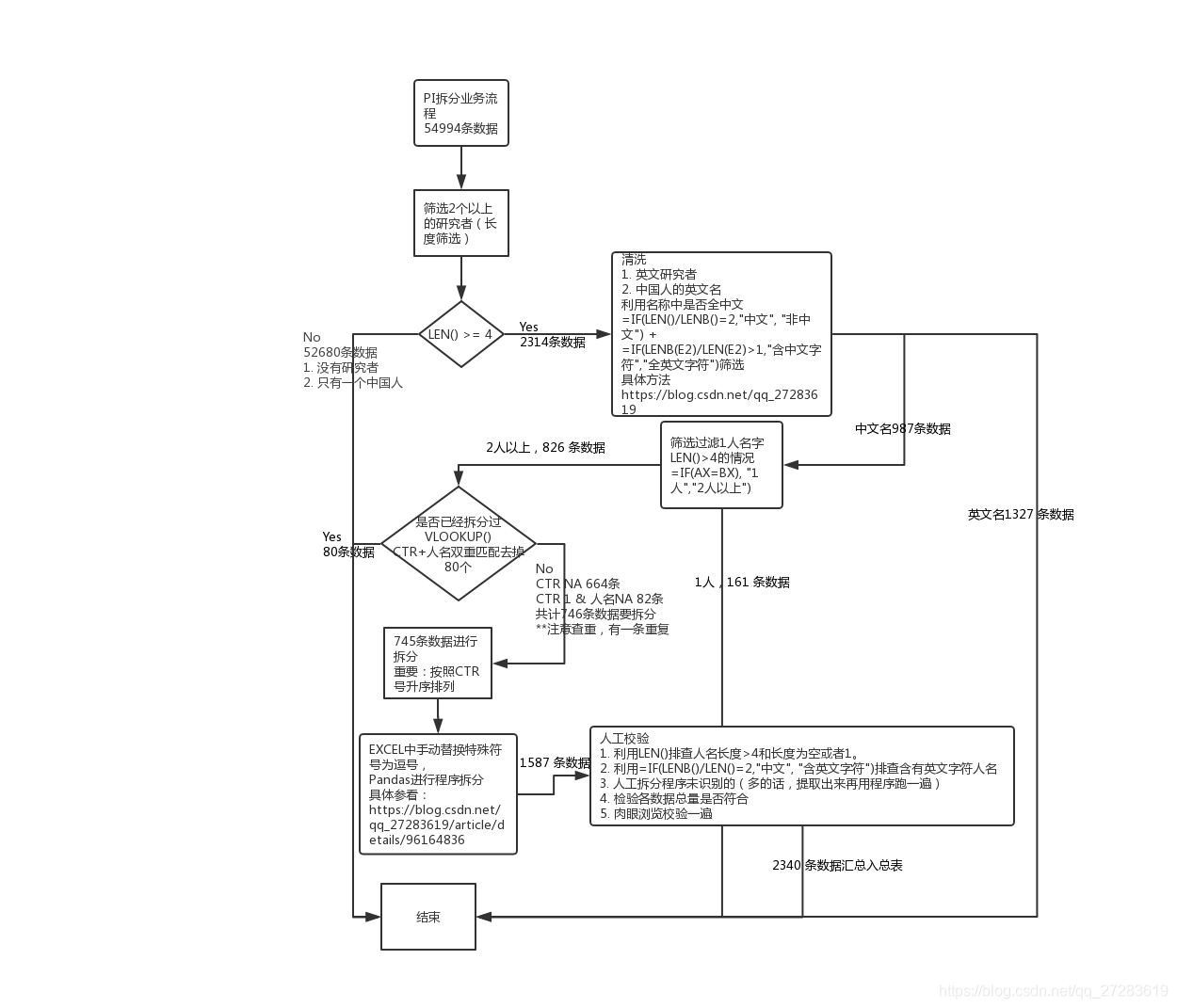 5. 参考文献
python3 pandas读写excelpandas某一列中每一行拆分成多行的方法Python3 读取和写入excel xlsx文件 使用openpyxlexcel – VBA:将单元格值拆分为多行并保留其他数据如何将单元格中的数据拆分多行,谢谢!
5. 参考文献
python3 pandas读写excelpandas某一列中每一行拆分成多行的方法Python3 读取和写入excel xlsx文件 使用openpyxlexcel – VBA:将单元格值拆分为多行并保留其他数据如何将单元格中的数据拆分多行,谢谢!
后记: 我从本硕药学零基础转行计算机,自学路上,走过很多弯路,也庆幸自己喜欢记笔记,把知识点进行总结,帮助自己成功实现转行。 2020下半年进入职场,深感自己的不足,所以2021年给自己定了个计划,每日学一技,日积月累,厚积薄发。 如果你想和我一起交流学习,欢迎大家关注我的微信公众号每日学一技,扫描下方二维码或者搜索每日学一技关注。 这个公众号主要是分享和记录自己每日的技术学习,不定期整理子类分享,主要涉及 C – > Python – > Java,计算机基础知识,机器学习,职场技能等,简单说就是一句话,成长的见证! |
 如果数据不够干净,后面还需要增加筛选排查机制,同时人工干预,保证数据的准确性。
如果数据不够干净,后面还需要增加筛选排查机制,同时人工干预,保证数据的准确性。
【本文地址】
今日新闻 |
推荐新闻 |