python 用 xlwings 处理 Excel 中的重复数据 |
您所在的位置:网站首页 › excel自动去重复数据 › python 用 xlwings 处理 Excel 中的重复数据 |
python 用 xlwings 处理 Excel 中的重复数据
|
xlwings 简介
xlwings 是一个 Python 库。简化了 Python 和 Excel 通信。 xlwings - 让Excel跑得飞快! 本文写作背景 & 需求 & 方案因前几个月帮在医院工作的朋友现学现卖用VBA写了段程序,处理2个excel文档的数据到第3个Excel文档上,有模板数据,有图表,怕数据出错,反复测试,折腾了有2天才弄出来。在摸索怎么用VBA开发的过程中发现,VBA开发太痛苦了。 前几天我无意间看到了一篇文章的标题 叫做 插上翅膀,让Excel飞起来——xlwings ,我被标题吸引住了,看到了有这么个东西。 更巧的是昨天朋友又让我帮她处理个Excel问题,这次的需求非常简单,为: 1. 只有一张只有3列的表 2. 如果表中存在两行或多行数据,它们的第2列和第3列数据都相同,第1列数据是否相同不考虑 3. 那么就只保留任意一行数据即可。 即:删除表中后两列数据相同的多余的行 于是乎想到了xlwings这个东西,想试一试,看看怎么玩(我还不会python的HelloWorld) 效果图如下: 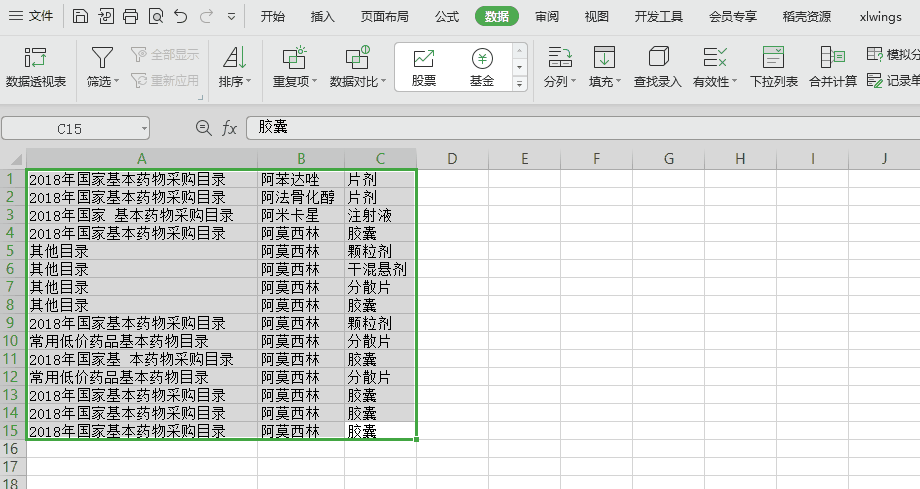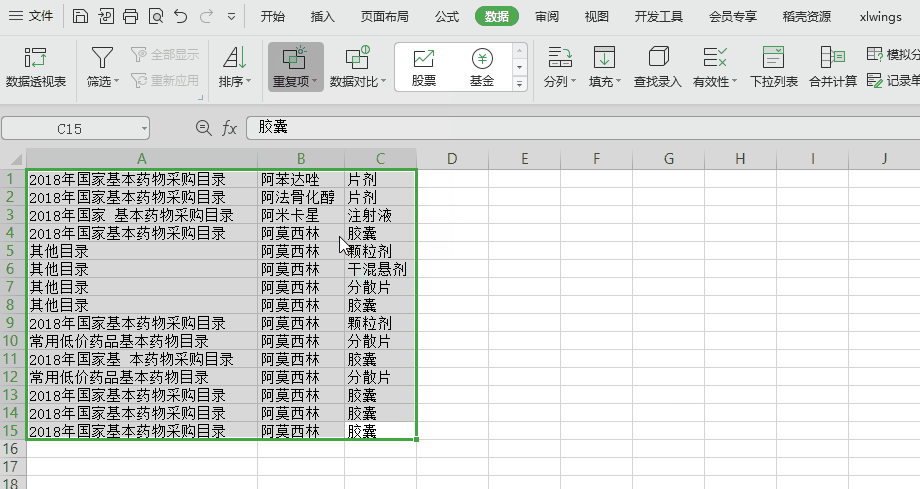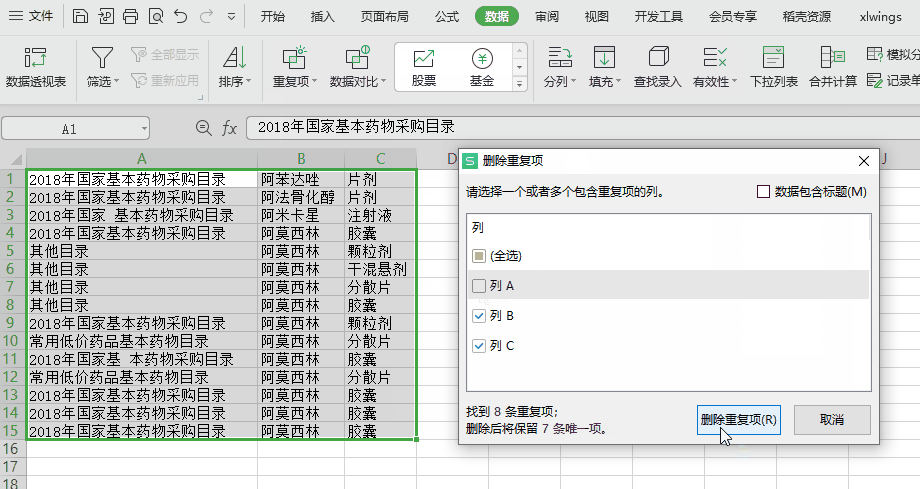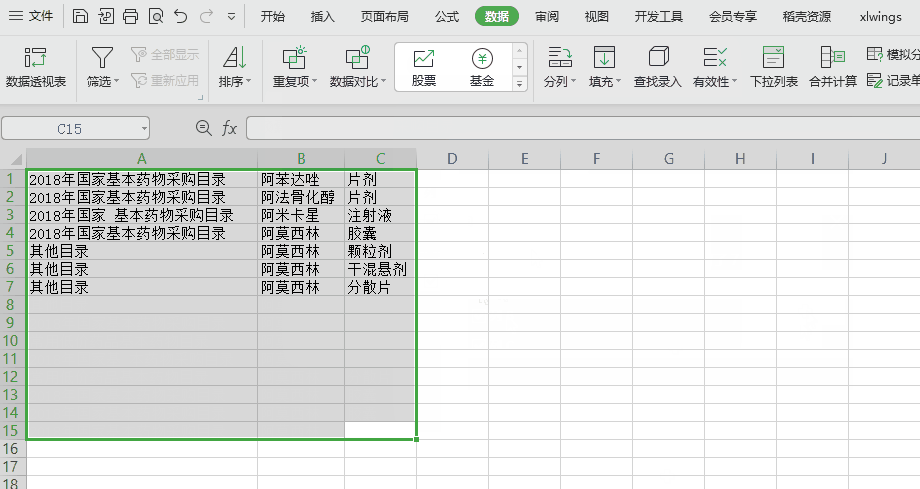 环境准备
环境准备
推荐使用 anaconda 解决环境问题,具体用法自行百度 Python3 安装注意:安装时提供管理员权限,否则容易出错。 库安装pip install 库名[=版本号] xlwings pip install xlwings 其他库(看需安装) NumPy NumPy Matplotlibpandas Python 语法基础 >>> def fib(n): >>> a, b = 0, 1 >>> while a >> print(a, end=' ') >>> a, b = b, a+b >>> print() >>> fib(1000) 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 中文报错需要首行加入 #coding=utf-8 或 # -*- coding: UTF-8 -*- 内置函数https://docs.python.org/zh-cn/3.7/library/functions.html type() 用于检测一个数据的数据类型,非常有用。效果如: str() 转为字符串int() 转为intlen() 获取序列或集合对象长度max() 返回可迭代对象中最大值,等等其他数学函数round(num, n) 四舍五入保留n位小数的函数input("请输入:") 等待接收用户输入数据并将接收数据返回 严格代码对齐因为没有大括号,必须要严格代码对齐,否则语义可能不同甚至报错! 序列类型 — list, tuple, range列表list 是可变序列 class list([iterable])¶ 使用一对方括号来表示空列表: [] 使用方括号,其中的项以逗号分隔: [a], [a, b, c] 使用列表推导式: [x for x in iterable] 使用类型的构造器: list() 或 list(iterable) 元组tuple是不可变序列,通常用于储存异构数据的多项集 class tuple([iterable]) 使用一对圆括号来表示空元组: () 使用一个后缀的逗号来表示单元组: a, 或 (a,) 使用以逗号分隔的多个项: a, b, c or (a, b, c) 使用内置的 tuple(): tuple() 或 tuple(iterable) tuple(‘abc’) 返回 (‘a’, ‘b’, ‘c’) 而 tuple( [1, 2, 3] ) 返回 (1, 2, 3)。 如果没有给出参数,构造器将创建一个空元组 () 范围range 类型表示不可变的数字序列,通常用于在 for 循环中循环指定的次数。 class range(stop) class range(start, stop[, step]) 举例 >>> 3,0,-1 (3, 0, -1) >>> (3,0,-1) # 同上,为元组,括号大多可省,不建议省 (3, 0, -1) >>> range(3,0,-1) # range ,表示开始为3,结束为1,步长为-1的整数范围 range(3, 0, -1) >>> for i in range(3,0,-1): ... print(i) ... 3 2 1 集合/字典集合可用多种方式来创建: 使用花括号内以逗号分隔元素的方式: {‘jack’, ‘sjoerd’} 使用集合推导式: {c for c in ‘abracadabra’ if c not in ‘abc’} 使用类型构造器: set(), set(‘foobar’), set([‘a’, ‘b’, ‘foo’]) 字典可用多种方式来创建: 使用花括号内以逗号分隔 键: 值 对的方式: {‘jack’: 4098, ‘sjoerd’: 4127} or {4098: ‘jack’, 4127: ‘sjoerd’} 使用字典推导式: {}, {x: x ** 2 for x in range(10)} 使用类型构造器: dict(), dict([(‘foo’, 100), (‘bar’, 200)]), dict(foo=100, bar=200) for 循环,和其他语言还真不一样语法格式只有 for-in 这一种格式 "for" target_list "in" expression_list ":" suite ["else" ":" suite]`因此,如果想动态修改循环次数,可使用while替换 r = 3 for i in range(r): print(i) # 下面的修改对for循环没有用,因为i的值会被下次循环覆盖,i的值在range范围内 i-=1 r-=2 # 输出: # 0 # 1 # 2 字符串拼接加号用于字符串拼接时,需要注意非字符串需要str()函数处理才可以,如:"你好" + str(123) ;或 print("你好%s"%123) 或更简单的print(a, b, c...) 或 format()方法拼接: "你好{1}{0}{2}".format(1,2,3) # ‘你好213’ "你好{}{}{}".format(1,2,3) # ‘你好123’ 等 冒号if / for 等语句中,分割代码作用 >>> if x >> x [1, 3, 5, 8, 9] >>> x[1:3] # 索引范围 [3, 5] >>> x[:] # 全部 [1, 3, 5, 8, 9]包含3个子列表的一维列表 X=array( [[1,2,3,4], [5,6,7,8], [9,10,11,12]] ) X[:, 0] 就是取矩阵X的所有行的第0列的元素,X[:,1] 就是取所有行的第1列的元素 X[:, m:n] 即取矩阵X的所有行中的的第m到n-1列数据,含左不含右 双冒号 推荐:官方文档在Range处的解释(点击查看) a[x:y:z] x表示切片起点,y表示切片终点,z表示步长,步长z默认为1; 如果z为正数,则默认x、y分别为列表的开始和结束索引,内容的公式为 a[i] = start + step*i 其中 i >= 0 且 r[i] < stop; 如果z为负数,表示倒序,内容的公式仍然为 a[i] = start + step*i,但限制条件改为 i >= 0 且 a[i] > z.; 如果 a[0] 不符合值的限制条件,则该 a 对象为空。 a 对象确实支持负索引(最后一个元素的索引是-1,倒数第二个元素索引为-2),但是会将其解读为从正索引所确定的序列的末尾开始索引; 如果z为0,则报错。 如下: >>> a = [1,3,5,8] >>> a[::] [1, 3, 5, 8] >>> a[1:3:] [3, 5] >>> a[::2] [1, 5] >>> a[::-1] [8, 5, 3, 1] >>> a[::-2] [8, 3] >>> a[1::-2] [3] >>> a[0:3:-1] [] >>> a[3:0:-1] [8, 5, 3] >>> a[3:0:-2] [8, 3] >>> a[1:3:0] Traceback (most recent call last): File "", line 1, in ValueError: slice step cannot be zerorange(10)[::2] 表示范围 [0, 10) 步长为2的切片 >>> range(10)[::2] range(0, 10, 2)切片完全指南(语法篇) [xx for xx in yy] 链表推导式 for 循环 遍历列表的四种方法
https://www.runoob.com/python3/python3-class.html class people: #定义基本属性 name = '' age = 0 #定义私有属性,私有属性在类外部无法直接进行访问 __weight = 0 #定义构造方法 def __init__(self,n,a,w): self.name = n self.age = a self.__weight = w def speak(self): print("%s 说: 我 %d 岁。" %(self.name,self.age)) # 实例化类 p = people('runoob',10,30) p.speak() 模块和包https://www.runoob.com/python3/python3-module.html 模块,是一个python文件。包,是一个包含若干模块的文件夹。模块导入方式 import 模块名 [as 别名]from 模块名 import 或 from 包名 import * 使用方式 有别名的使用别名,导入成员的可直接使用成员,否则使用 模块名.成员包导入方式类似,包中必须包含文件__init__.py ,__all__ python 标准库python 标准库 常用标准库——菜鸟教程 sys print(sys.argv) # 程序执行参数 print(sys.platform) # 系统平台 sys.exit() sys.exit(“崩了”)pprint pprint.pprint(sys.modules) # 模块字典 print(sys.path) # 模块搜索路径os pprint.pprint(os.environ) # 格式化打印系统环境变量 print(os.environ[“path”]) # 打印path os.system(“ls”) # 执行系统命令 print(os.getcwd()) # 当前的工作目录字符串正则匹配数学日期和时间数据压缩访问互联网 零散知识点 __name__ 属性,主程序的该属性值为 __main__dir() 函数,可以找到模块内定义的所有名称 编码 本需求方案代码 1 (不推荐)该代码虽然能得到正确的结果,但是 for i in range(rows-1): 语句内部虽然有对 rows 值的修改,但是i 在下次循环时又会被重新赋值,i 在下次循环的取值依然不会因循环体内部对 rows 的改变而改变。i 始终会将所有的 [0, rows-1) 内的整数值取完。可参见官方 for 语句解释 #coding=utf-8 # 首行作用:防止中文乱码 import xlwings as xw import operator # 打开Excel程序,默认设置为程序可见,只打开不新建 app = xw.App(visible=True,add_book=False) wb = xw.Book('test.xls') sht = wb.sheets[0] rng = sht.range('A1').expand('table') rows = rng.rows.count cols = rng.columns.count print(str(rows)+", "+ str(cols)) # 将表中数据转为二维数组格式 all = sht.range((1,1),(rows,cols)).value for i in range(rows-1): print("--"+str(i)+"---") print(range(rows-1,i,-1)) for j in range(rows-1,i,-1): # print(str(i)+", "+str(j)) # 先用strip()去除单元格数据中首尾空白,防止数据因空白影响结果 if operator.eq(all[i][1].strip(),all[j][1].strip()) and operator.eq(all[i][2].strip(),all[j][2].strip()): # print(all[j]) # print(str(j)) rng.rows[j].api.EntireRow.Delete() del all[j] rows-=1 wb.save() wb.close() app.quit() 方案代码2 (推荐)(2023/01/08更新:不再推荐这种自写算法方案方式) #coding=utf-8 import xlwings as xw # app = xw.App(visible=True, add_book=False) wb = xw.Book('ok.xls') # wb = app.books.open(r'D:/cuncaojin/desktop/ok.xls') # wb = xw.Book(r'D:/cuncaojin/desktop/ok.xls') sht = wb.sheets[0] # myList = [['2018年国家基本药物采购目录', '阿苯达唑', '片剂'], ['2018年国家基本药物采购目录', '阿法骨化醇', '片剂'], ['2018年国家 基本药物采购目录', '阿米卡星', '注射液'], ['2018年国家基本药物采购目录', '阿莫西林', '胶囊'], ['其他目录', '阿莫西林', '颗粒剂'], ['其他目录', '阿莫西林', '干混悬剂'], ['其他目录', '阿莫西林', '分散片'], ['其他目录', '阿莫西林', '胶囊'], ['2018年国家基本药物采购目录', '阿莫西林', '颗粒剂'], ['常用低价药品基本药物目录', '阿莫西林', '分散片2'], ['2018年国家基 本药物采购目录', '阿莫西林', '胶囊'], ['常用低价药品基本药物目录', '阿莫西林', '分散片'], ['2018年国家基本药物采购目录', '阿莫西林3', '胶囊'], ['2018年国家基本药物采购目录', '阿莫西林', '胶囊'], ['2018年国家基本药物采购目录', '阿莫西林', ' 胶囊']] myList = sht[0,0].current_region.value # print(len(myList),"\n", myList) i = 0 while i |


【本文地址】
今日新闻 |
推荐新闻 |