【Python】处理Excel中数据1(单元格中的数据拆分,拆分后数据作为新列追加) |
您所在的位置:网站首页 › excel提取单元格中的数字内容 › 【Python】处理Excel中数据1(单元格中的数据拆分,拆分后数据作为新列追加) |
【Python】处理Excel中数据1(单元格中的数据拆分,拆分后数据作为新列追加)
|
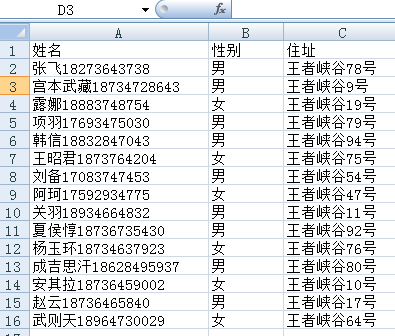
一,把不规则数据按照正则匹配提取拆分 需求: 1.原文件中的内容呈现. 把姓名中的电话号码提取出来生成新的列追加
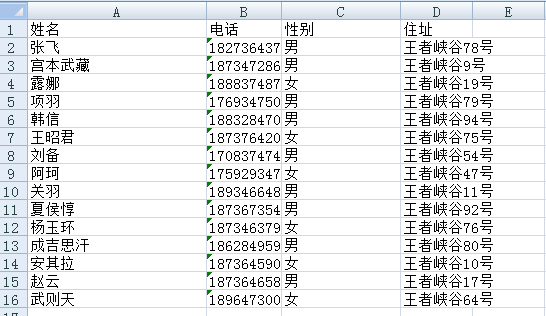
2. 生成结果的内容呈现
二, 代码的呈现 思路: 1. 加载excel类便于读取Excel中的数据内容 2. 通过正则表达式来获取到数字及数字以外的字符串.这样做就可以对于excel中的第一列内容进行拆分把数字跟字符区分开来 3. 为了文件不被覆盖。把编辑后的文件重新保存到新的excel中 三,代码的呈现 1 # -*- coding:utf-8 2 3 import openpyxl 4 import re 5 # 1. 数据指向excel中的第一个sheet 6 file_path = R"C:\Users\Administrator\python处理Excel数据\20200113\student_list.xlsx" 7 workbook = openpyxl.load_workbook(file_path) 8 sheet_names = workbook.sheetnames 9 sheet1 = workbook[sheet_names[0]] 10 11 # 2. 读取Excel sheet1中的所有数据 12 sheet1_allDatas = [] 13 for row in sheet1.rows: 14 line = [cell.value for cell in row] 15 sheet1_allDatas.append(line) 16 #print(sheet1_allDatas) 17 18 # 3. 处理数据中姓名这个元素把字符串跟数字区分出来 19 # [1] 第一正则表达式 20 parrten1 = re.compile("[\d]+") #获取第一个元素的所有数字 21 parrten2 = re.compile("[^\d]+")#获取第一个元素的所有除数字以外的字符 22 # [2] 通过正则把元素的数字跟字符分离出来,并把处理好的数据添加到新的集合中 23 new_data = [] 24 flg = 0 25 for strs in sheet1_allDatas: 26 flg += 1 27 for i in range(len(strs)): 28 file_data1 = parrten1.findall(strs[0]) 29 file_data2 = parrten2.findall(strs[0]) 30 strs[0] = "".join(file_data2) 31 strs.insert(1, "".join(file_data1)) 32 new_data.append(strs) 33 print(new_data) 34 print("====================================================") 35 # [3] 给title加电话标签 36 new_data[0].insert(3,"电话") 37 print(new_data) 38 # [4] 除去空格 39 last_Data = [] 40 for lines in new_data: 41 flg +=1 42 for i in range(len(lines)): 43 new_list =[x.strip() for x in lines if x.strip() != ''] 44 last_Data.append(new_list) 45 print(last_Data) 46 47 # [5] 创建新的Excel把结果写入到Excel中 48 wb = openpyxl.Workbook() 49 ws = workbook.active 50 ws.title = "sheet1" 51 flg = 0 52 for lines in last_Data: 53 flg +=1 54 for i in range(len(lines)): 55 ws.cell(flg,i+1,lines[i]) 56 workbook.save("C:\\Users\\Administrator\\python处理Excel数据\\20200113\\student_list2.xlsx") 57 print("文件保存成功!")四,重点解释 1. print(sheet1_allDatas)打印出来的结果如下。到这里只是原封不动的获取了Excel中原来数据的信息。[['姓名', '性别', '住址'], ['张飞18273643738', '男', '王者峡谷78号'], ['宫本武藏18734728643', '男', '王者峡谷9号'], ....等 2. 下面这段代码中的strs代表获取到sheet1_allDatas中的每一条元素。而file_data1 = parrten1.findall(strs[0])是通过正则表达式查找每一条元素中的第一个元素中的内容进行匹配。file_data1中匹配的是所有数字相反file_data2是file_data1取反数字以外的所有的意思。strs[0] = "".join(file_data2) 和 strs.insert(1, "".join(file_data1))这两句比较关键。第一条把两个list中的数据合并。第二条是 for strs in sheet1_allDatas: flg += 1 for i in range(len(strs)): file_data1 = parrten1.findall(strs[0]) file_data2 = parrten2.findall(strs[0]) strs[0] = "".join(file_data2) strs.insert(1, "".join(file_data1)) new_data.append(strs)print(new_data) 结果:[['姓名', '', '', '', '性别', '住址'], ['张飞', '', '', '18273643738', '男', '王者峡谷78号'], ['宫本武藏', '', '', '18734728643', '男', '王者峡谷9号'], ['露娜', '', '', '18883748754', '女', '王者峡谷19号'], ['项羽', '', '', '17693475030', '男', '王者峡谷79号'], ['韩信', '', '', '18832847043', '男', '王者峡谷94号'], ['王昭君', '', '', '1873764204', '女', '王者峡谷75号'], ['刘备', '', '', '17083747453', '男', '王者峡谷54号'], ['阿珂', '', '', '17592934775', '女', '王者峡谷47号'], ['关羽', '', '', '18934664832', '男', '王者峡谷11号'], ['夏侯惇', '', '', '18736735430', '男', '王者峡谷92号'], ['杨玉环', '', '', '18734637923', '女', '王者峡谷76号'], ['成吉思汗', '', '', '18628495937', '男', '王者峡谷80号'], ['安其拉', '', '', '18736459002', '女', '王者峡谷10号'], ['赵云', '', '', '18736465840', '男', '王者峡谷17号'], ['武则天', '', '', '18964730029', '女', '王者峡谷64号']] 可以看出至少出现两到三个' ', ' '这种空格。第一段元素为头部姓名后有3处空格,二内容元素中间有2处空格 |
【本文地址】
今日新闻 |
推荐新闻 |