干预研究前期如何确定样本量和进行抽样及分组? |
您所在的位置:网站首页 › excel如何随机分组样本量大 › 干预研究前期如何确定样本量和进行抽样及分组? |
干预研究前期如何确定样本量和进行抽样及分组?
|
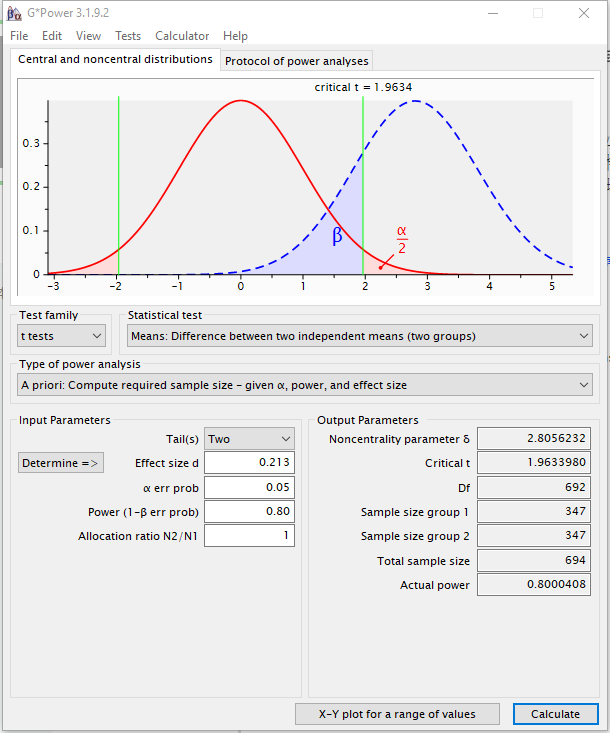
“让我们做朋友-陕西”抽样方法简介 郭申阳 有关“让我们做朋友-陕西”项目的新闻发布后,很多读者来信,希望了解更多有关抽样方法的信息。抽样方法是本项目随机实验的重要组成部分,我们将在项目评估的研究论文中详细阐述。这里,为满足读者需要,仅做简单介绍。 1.干预前:如何确定样本 首先,统计力度分析(Statistical Power Analysis)显示,为达到0.80的统计力度和较小效应规模(small effect size;d=.20)的要求,项目需要的样本量为实验组350人,控制组350人。根据泾阳县小学的平均规模,我们确定需要抽取14所实验小学及14所控制小学。 开展干预研究,很重要的一步就是在做研究设计时,进行统计力度分析,因为Effect Size,alpha, power,和样本量这四个值只需要知道其中三个,就可以通过G*Power算出另外一个值。一般干预研究需要在给定预期的ES, Alpha, and power来算出所需的样本量(包括干预组和对照组;可以假设两组人数相同,也可以设置两组样本不同进行比例计算)。 如何做统计力度分析,请下载免费软件G*Power并参考使用指南(简单易懂,可以自学):http://www.gpower.hhu.de/ 以下是G*Power 的参数设置(各位也可以参考以下标红的参数自己练习一下): t tests - Means: Difference between two independent means (two groups) Analysis:A priori: Compute required sample size Input:Tail(s)=Two Effect size d=0.213 (注:small ES:d 约等于.20; medium ES: d约等于.50; large ES: d约等于.80) α err prob=0.05 (注:α 指显著度水平,拒绝原假设区间) Power (1-β err prob)=0.80 (注:Power 指统计力度,可以根据以往的研究,或实际情况,设定一个合理的power,一般来讲0.8以上都可) Allocation ratio N2/N1=1 (注:这个指两组人数比例,若相同,则为1;否则可以根据实际情况,根据两组人数的预计调整比值) Output:Noncentrality parameter δ=2.8056232 Critical t=1.9633980 Df=692 Sample size group 1=347 (注:347是最少应有的样本量,越多下面的actual power会越大) Sample size group 2=347 Total sample size=694 Actual power=0.8000408
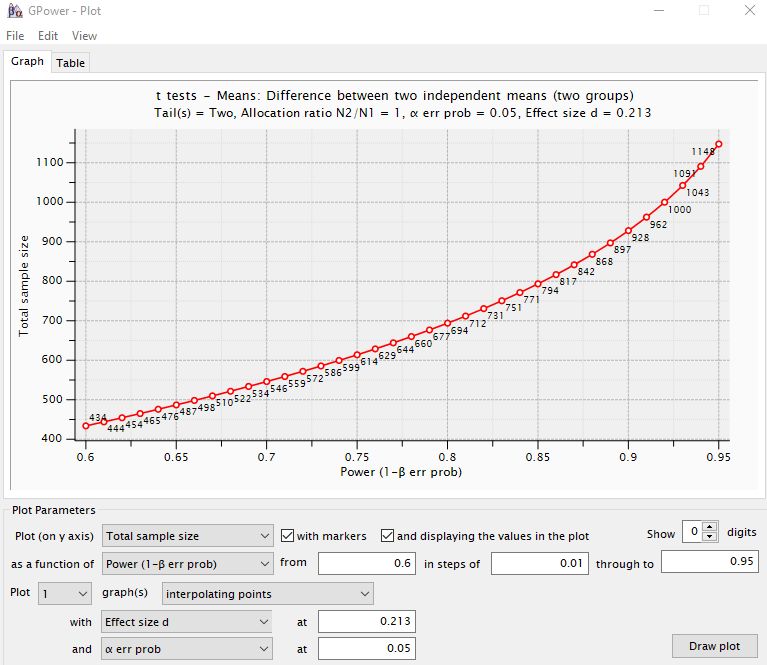
(各位也可以点击“calculate”左边的“X-Y plot for a range of values",获取不同power对应所需的样本表,这样大家可以根据自己的实际样本量可知该干预研究的power(这个power当然越大越好,这也就是为什么越多样本越好,当然,样本越多,花费越大,故研究者要综合考虑),如下图)
开展干预研究,很重要的一步就是在做研究设计时,进行统计力度分析,因为Effect Size,alpha, power,和样本量这四个值只需要知道其中三个,就可以通过G*Power算出另外一个值。一般干预研究需要在给定预期的ES, Alpha, and power来算出所需的样本量(包括干预组和对照组;可以假设两组人数相同,也可以设置两组样本不同进行比例计算)。 如何做统计力度分析,请下载免费软件G*Power并参考使用指南(简单易懂,可以自学):http://www.gpower.hhu.de/ 以下是G*Power 的参数设置(各位也可以参考以下标红的参数自己练习一下): t tests - Means: Difference between two independent means (two groups) Analysis:A priori: Compute required sample size Input:Tail(s)=Two Effect size d=0.213 (注:small ES:d 约等于.20; medium ES: d约等于.50; large ES: d约等于.80) α err prob=0.05 (注:α 指显著度水平,拒绝原假设区间) Power (1-β err prob)=0.80 (注:Power 指统计力度,可以根据以往的研究,或实际情况,设定一个合理的power,一般来讲0.8以上都可) Allocation ratio N2/N1=1 (注:这个指两组人数比例,若相同,则为1;否则可以根据实际情况,根据两组人数的预计调整比值) Output:Noncentrality parameter δ=2.8056232 Critical t=1.9633980 Df=692 Sample size group 1=347 (注:347是最少应有的样本量,越多下面的actual power会越大) Sample size group 2=347 Total sample size=694 Actual power=0.8000408
(各位也可以点击“calculate”左边的“X-Y plot for a range of values",获取不同power对应所需的样本表,这样大家可以根据自己的实际样本量可知该干预研究的power(这个power当然越大越好,这也就是为什么越多样本越好,当然,样本越多,花费越大,故研究者要综合考虑),如下图)
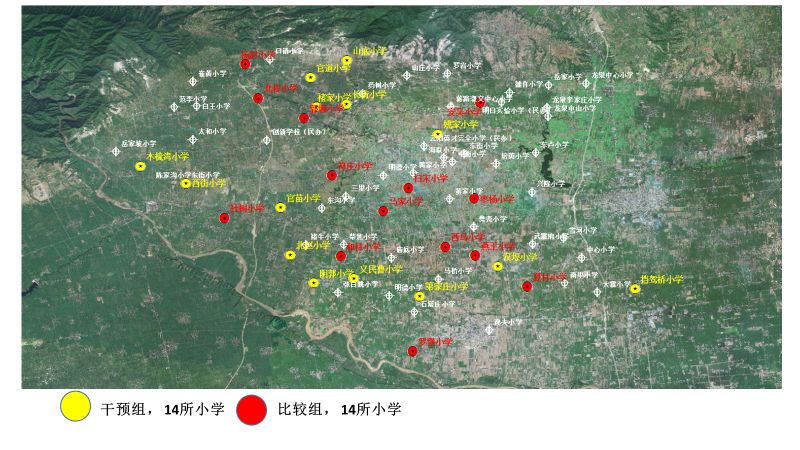
2018年6月全县一共有73所小学,其中城区小学1所,新建民办小学8所。这9所学校不符合项目在泾阳县典型公办农村小学做干预的要求,予以剔出。这样,符合抽样要求的一共有64所小学。 2.进行随机分组 然后,我们运用群组随机(Cluster Randomization)的方法,在这64所小学中随机抽取了14所小学组成实验组。群组随机,即在学校层面做纯随机抽样,保证了项目接受干预的小学生与不接受干预的控制组学生没有沟通,避免了干预的“溢出效应”(spill-over effect)。如果项目在小学生层面作随机抽样,有可能在同一所小学出现部分学生接受干预、部分学生不接受干预的现象。如此,两类学生的交流会造成结果数据的“污染”—即控制组学生的结果也会受到干预的影响,俗称“溢出效应”。 为保证控制组学校与实验组学校高度相似,我们随后又运用向量模方法(vector norm),也称“马氏距离匹配法”(Mahalanobis metric matching),运用学校层面的八个变量,对每一所选定的实验学校找到它所对应的控制组学校。这样,控制组学校至少在我们已知的变量上与实验组高度相似,保证了在做项目评估时,我们可以比较放心地将两组学生在结果变量上的差异归因于实验组学生接受干预而控制组学生没有接受干预这一基本事实。用于匹配的八个变量是:(A)学生总人数,(B)留守儿童百分比,(C)每百学生拥有电脑台数,(D)生均拥有图书数,(E)师生比,(F)专任教师大专及以上学历的比例、(G)中级以上专业技术职务教师比例, (H)高级专业技术职务或县级以上骨干教师比例。 最终选定的14对实验与控制学校如下表所示: 配对编号 向量模分 实验组小学 控制组小学 1 0.6378 YMC小学 LB小学 2 1.4759 MSW小学 BC小学 3 1.5103 YG小学 XC小学 4 1.8050 DJQ小学 YW小学 5 1.2374 GDZX小学 SS小学 6 0.2083 YJ小学 AW小学 7 2.3631 CJ小学 GY小学 8 2.0982 GM小学 HC小学 9 1.0931 CJ小学 XN小学 10 2.1912 BZZX小学 YZ小学 11 1.3744 DJZ小学 SS小学 12 2.6644 HD小学 ZY小学 13 1.3126 XJ小学 MJ小学 14 1.5865 SD小学 FZ小学 这28所学校的地理分布如下图所示:
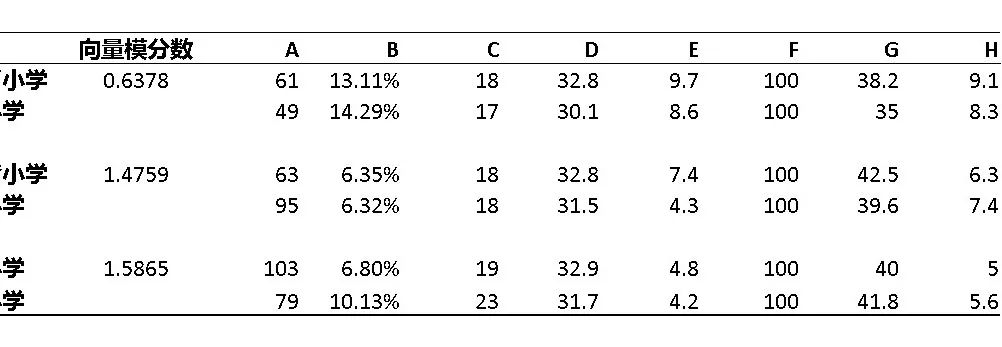
运用向量模匹配方法,每对学校在八个变量上高度相似。下表用三对学校的数据做示例,说明匹配的成功性:
抽样完成以后,有两所抽中的实验组学校,由于体制调整而合并,所以最终是13所实验组小学共354名学生接受了14次系统干预和两次数据测试,14所控制组小学共390名学生只提供两次数据测试而没有接受干预。 本项目的抽样方法,学术名称为“纯随机控制实验+ 向量模匹配”(Randomized Controlled Trial + Vector Norm Matching),它是“完全分块随机”(fully blocked randomization)方法的一种,是在现有教育系统能够提供的数据条件下,实施随机实验有可能达到最好结果的一种方法。返回搜狐,查看更多 责任编辑: |
【本文地址】
今日新闻 |
推荐新闻 |