超简单的方法完整保留原有所有样式拆分Excel表 |
您所在的位置:网站首页 › excel如何把一列数据拆分为多个合计一万以内 › 超简单的方法完整保留原有所有样式拆分Excel表 |
超简单的方法完整保留原有所有样式拆分Excel表
|
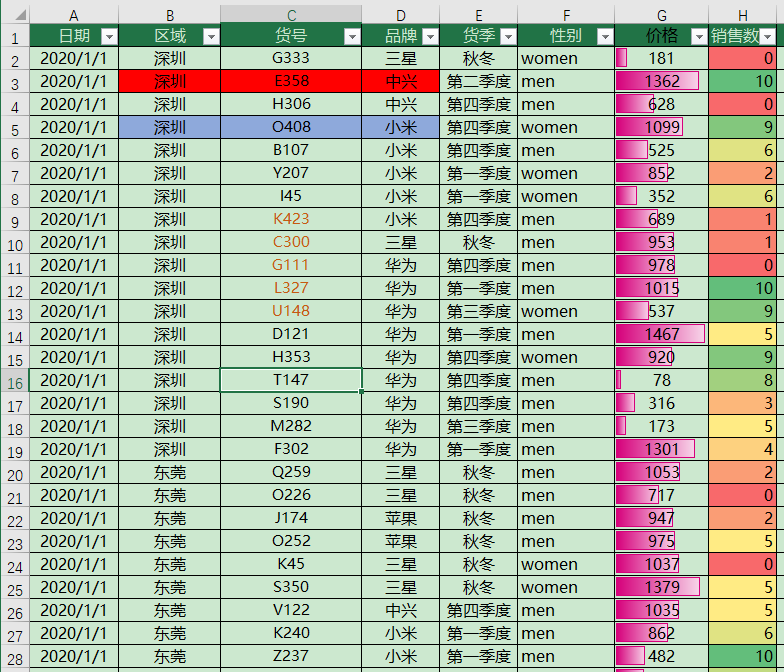
本文作为一篇原始雏形已经过时,新版本的文章请移步到: 深度剖析Excel表拆分的三项技术(已实现纯Openpyxl保留全部样式拆分,自适应单文件和多文件拆分等):https://blog.csdn.net/as604049322/article/details/118655016 本文目录: 文章目录 需求描述实现过程纯VBA实现升级:能指定起始行的带格式拆分VBA代码翻译成Python调用示例使用Pandas实现Excel拆分使用openpyxl保留表头样式拆分Excel表总结 透过本文你能够学到: 通过VBA复制粘贴全部样式进行单文件表拆分纯Pandas拆分表,无样式保留openpyxl模板法拆分表保留表头样式作者:小小明,高阶数据处理玩家,帮助各行数据从业者解决各类数据处理难题。 需求描述有一个Excel表格:
我们希望将其按照指定的字段拆分为多个表格。如果直接用pandas,代码很简单却只能保留数据;如果使用openpyxl,也无法直接设置原有的样式,需要逐个设置会非常麻烦。下面我将使用Excel自带的筛选功能,筛选出指定的值,然后复制粘贴到一张新的工作表中。唯一值不多的时候我们人工操作也可以,但数据量大唯一值多的时候,人工操作就耗时很久了。 如何使用Python实现这个自动化操作呢?那就是通过pywin32调用VBA。 下面我们开始操作吧: 实现过程首先,用pywin32打开目标文件: import win32com.client as win32 # 导入模块 import os excel_app = win32.gencache.EnsureDispatch('Excel.Application') filename = "数据源.xlsx" filename = os.path.abspath(filename) wb = excel_app.Workbooks.Open(filename) sheet = wb.ActiveSheet max_rows = sheet.UsedRange.Rows.Count max_cols = sheet.UsedRange.Columns.Count max_rows, max_cols (3216, 9)可以看到源数据有3216行,9列。 获取数据范围,并设置自动列宽调整: rng = sheet.Range(sheet.Cells(1, 1), sheet.Cells(max_rows, max_cols)) # 设置自动列宽 rng.EntireColumn.AutoFit()设置后的效果:
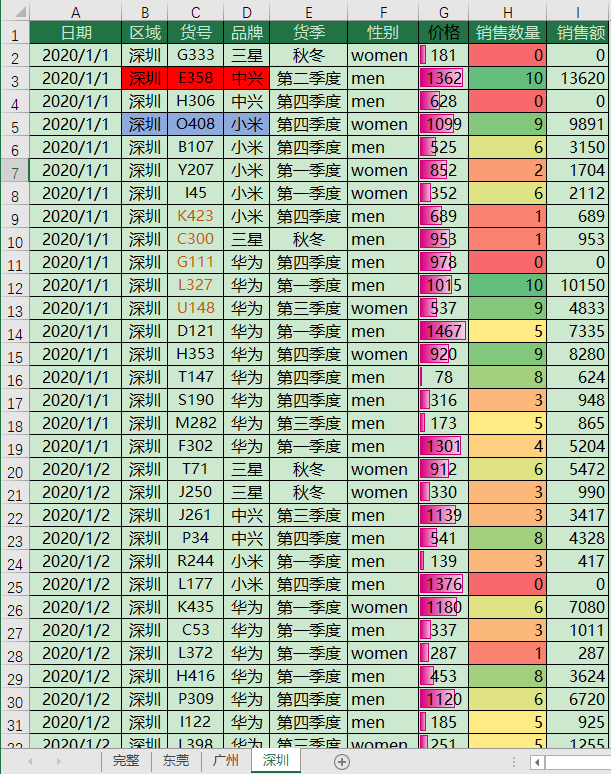
构建一个拆分函数: def split_excel(num): """num示被拆分的列号""" names = set(sheet.Range(sheet.Cells(2, num), sheet.Cells(max_rows, num)).Value) # 禁用自动更新加快执行速度 excel_app.ScreenUpdating = False for name, in names: sheet.Activate() rng.AutoFilter(Field=num, Criteria1=name) rng.Select() excel_app.Selection.Copy() new_sheet = excel_app.Sheets.Add(After=wb.Worksheets(wb.Worksheets.Count)) new_sheet.Name = name new_sheet.Range("A1").Activate() new_sheet.Paste() new_sheet.Range(new_sheet.Cells(1, 1), new_sheet.Cells(1, max_cols)).EntireColumn.AutoFit() # 恢复自动更新 excel_app.ScreenUpdating = True该函数涉及的方法很多,需要反复查询VBA文档并测试才能写出,不过前人栽树后人乘凉,我已经为大家写出来啦,可以直接使用。当然也欢迎VBA大佬对本方法进行升级改造。 一些重点的API: Range 对象:https://docs.microsoft.com/zh-cn/office/vba/api/excel.range(object) Range.AutoFilter:https://docs.microsoft.com/zh-cn/office/vba/api/excel.range.autofilter Sheets.Add :https://docs.microsoft.com/zh-cn/office/vba/api/excel.sheets.add Worksheet.Name 属性:https://docs.microsoft.com/zh-cn/office/vba/api/excel.worksheet.name Application.ScreenUpdating:https://docs.microsoft.com/zh-cn/office/vba/api/excel.application.screenupdating 其他需要注意的点: 在Excel本身的VBA环境,获取唯一值,我们往往需要使用高级筛选或字典对象。VBA的字典对象使用起来较为麻烦,文档地址:https://docs.microsoft.com/zh-cn/office/vba/language/reference/user-interface-help/dictionary-object 但我们再Python环境中使用VBA,则无需使用VBA的数组或字典对象,使用python本身的对象操作即可。 下面我们对区域列(第2列)进行拆分: split_excel(2)
可以看到拆分的结果,完全保留了原有的样式。 最后我们保存文件即可: wb.SaveAs(os.path.abspath("result.xlsx"))直接修改原有文件直接调用wb.Save()即可,上述命令表示另存为。 可以关闭工作簿: wb.Close()还可以关闭Excel软件: excel_app.Quit() 纯VBA实现为了没有安装python的童鞋使用方便,将以上过程封装成纯vba代码,可以直接在Excel软件中使用: Sub 带格式分列() Application.ScreenUpdating = False Set Sh = ActiveSheet max_rows = Sh.UsedRange.Rows.Count max_cols = Sh.UsedRange.Columns.Count Set Rng = Sh.Range(Sh.Cells(1, 1), Sh.Cells(max_rows, max_cols)) Rng.EntireColumn.AutoFit 'Col为要手动输入要拆分的列序数 Col = CInt(InputBox("输入用于分组的列序号!")) Range(Cells(2, Col), Cells(max_rows, Col)).AdvancedFilter Action:=xlFilterCopy, CopyToRange:=Cells(1, max_cols + 2), Unique:=True LastRow = Cells(1, max_cols + 2).End(xlDown).Row Range(Cells(1, max_cols + 2), Cells(LastRow, max_cols + 2)).RemoveDuplicates Columns:=1, Header:=xlNo LastRow = Cells(1, max_cols + 2).End(xlDown).Row For i = 1 To LastRow Name = CStr(Sh.Cells(i, max_cols + 2)) Sh.Activate Rng.AutoFilter Field:=Col, Criteria1:=Name Rng.Copy Set new_sheet = Sheets.Add(After:=Sheets(Sheets.Count)) new_sheet.Name = Name new_sheet.Range("A1").Activate new_sheet.Paste new_sheet.Range(new_sheet.Cells(1, 1), new_sheet.Cells(1, max_cols)).EntireColumn.AutoFit Next Sh.Activate Columns(max_cols + 2).Delete Shift:=xlToLeft Selection.AutoFilter Application.ScreenUpdating = True End Sub 升级:能指定起始行的带格式拆分后面碰过了起始行不在开头的需求:
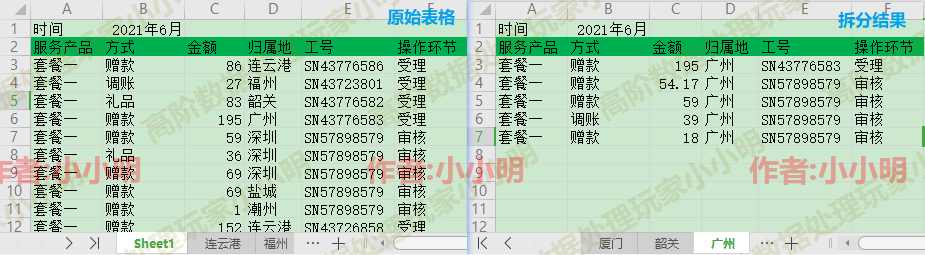
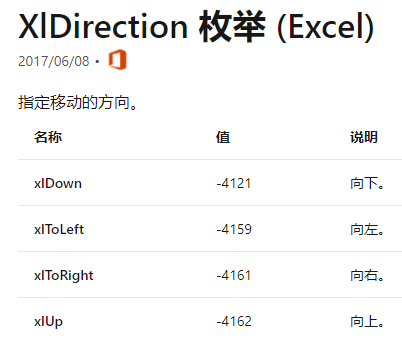
对于这类需求会增加复制非筛选区域的操作,我已经完整封装了全部过程到一个方法。 完整代码如下: import win32com.client as win32 # 导入模块 import os excel_app = win32.gencache.EnsureDispatch('Excel.Application') def split_excel(filename, save_name, num, title_row=1): """作者小小明的csdn:https://blog.csdn.net/as604049322""" wb = excel_app.Workbooks.Open(os.path.abspath(filename)) try: sheet = wb.ActiveSheet max_rows = sheet.UsedRange.Rows.Count max_cols = sheet.UsedRange.Columns.Count if title_row > 1: start = sheet.Range(sheet.Cells( 1, 1), sheet.Cells(title_row-1, max_cols)) rng = sheet.Range(sheet.Cells(title_row, 1), sheet.Cells(max_rows, max_cols)) # 设置自动列宽 rng.EntireColumn.AutoFit() names = set(sheet.Range(sheet.Cells(title_row+1, num), sheet.Cells(max_rows, num)).Value) for name, in names: if not name: continue new_sheet = excel_app.Sheets.Add( After=wb.Worksheets(wb.Worksheets.Count)) new_sheet.Name = name if title_row > 1: sheet.Activate() start.Copy() new_sheet.Activate() new_sheet.Range("A1").Activate() new_sheet.Paste() sheet.Activate() rng.AutoFilter(Field=num, Criteria1=name) rng.Copy() new_sheet.Activate() new_sheet.Range(f"A{title_row}").Activate() new_sheet.Paste() new_sheet.Range(new_sheet.Cells(1, 1), new_sheet.Cells( 1, max_cols)).EntireColumn.AutoFit() wb.SaveAs(os.path.abspath(save_name)) finally: wb.Close() split_excel("工单.xlsx", '拆分结果.xlsx', 4, 2) #这步会关闭你正在使用的Excel软件,视具体情况决定是否要注释掉 excel_app.Quit() VBA代码翻译成Python调用示例前面我演示了Python带格式拆分Excel表,可能大家对使用python来调用vba还比较生疏,下面我将演示将一段vba代码翻译为python调用。 下面这段拆分Excel表的vba代码来自才哥的文章《Python对比VBA实现excel表格合并与拆分》,作者是“两百斤的老涛”,一起看看吧: Sub 表格拆分() '屏幕刷新=false Application.ScreenUpdating = False Dim LastRow, LastCol As Long Dim Sh, Sht As Worksheet 'Sh指代当前活动页 Set Sh = ActiveSheet '当前活动页的最后一行 LastRow = Sh.Cells(Rows.Count, 1).End(xlUp).Row '当前活动页的最后一列 LastCol = Sh.Cells(1, Columns.Count).End(xlToLeft).Column '定义D为字典 Dim D As Object Set D = CreateObject("Scripting.Dictionary") Dim Col As Integer 'Col为要手动输入要拆分的列序数 Col = InputBox("输入用于分组的列序号!") '从第2行找到最后一行 For i = 2 To LastRow '查找这个要拆分行,看它在不在字典里 TempStr = CStr(Sh.Cells(i, Col)) '如果在字典里 If D.exists(TempStr) Then '将数据放到对应的页里 Set Sht = Worksheets(TempStr) '字典key值对应的项目值记录该页当前内容添加的行数,每次+1 D(TempStr) = D(TempStr) + 1 '下面一行可以注释掉了跟下面的重复了…… 'Sht.Cells(D(TempStr), 1) = Sh.Cells(i, 1) For j = 1 To LastCol Sht.Cells(D(TempStr), j) = Sh.Cells(i, j) Next Else '如果不在字典里,就添加一个新key D.Add TempStr, 1 'i = i - 1是让该行一会儿重新检索一遍就能进到if里了 i = i - 1 '在最后一页新加一页,页名就是TempStr Sheets.Add After:=Sheets(Sheets.Count) Sheets(Sheets.Count).Name = TempStr '下面一行也是可以注释掉的 'Sheets(Sheets.Count).Cells(1, 1) = Sh.Cells(1, 1) '把第一行标题行弄过去 For j = 1 To LastCol Sheets(Sheets.Count).Cells(1, j) = Sh.Cells(1, j) Next End If Next '激活初始页,视觉上保持不变 Sh.Activate 'RT,GDCDSZ MsgBox ("完成!") End Sub下面我们将其转换为python代码来调用: 建立在已经打开Excel文件的前提下: import win32com.client as win32 # 导入模块 import os excel_app = win32.gencache.EnsureDispatch('Excel.Application') filename = "数据源.xlsx" filename = os.path.abspath(filename) wb = excel_app.Workbooks.Open(filename)Set Sh = ActiveSheet等价于: Sh = wb.ActiveSheet对于下面这两行代码: '当前活动页的最后一行 LastRow = Sh.Cells(Rows.Count, 1).End(xlUp).Row '当前活动页的最后一列 LastCol = Sh.Cells(1, Columns.Count).End(xlToLeft).Column首先对于Rows和Columns可以通过顶级的’Excel.Application’对象来引用,而xlUp和xlToLeft两个常量值,我目前采用的方案是通过文档进行查阅,首先定位到vba文档的Range.End 属性,然后再点击 Direction 参数的数据类型:https://docs.microsoft.com/zh-cn/office/vba/api/excel.xldirection
于是我们翻译为: LastRow = Sh.Cells(excel_app.Rows.Count, 1).End(-4162).Row LastCol = Sh.Cells(1, excel_app.Columns.Count).End(-4159).Column专业的vba程序员都习惯用上面的方法获取数据的行数和列数,但一般情况下用我前面的UsedRange的方法就够了。 由于数据都直接读取到python环境中,我们直接使用python的字典,继续翻译剩下的循环部分: D = {} Col = 2 excel_app.ScreenUpdating = False for i in range(2, LastRow+1): TempStr = Sh.Cells(i, Col).Value if TempStr in D: Sht = wb.Sheets(TempStr) D[TempStr] += 1 for j in range(1, LastCol+1): Sht.Cells(D[TempStr], j).Value = Sh.Cells(i, j).Value else: D[TempStr] = 1 excel_app.Sheets.Add(After=wb.Sheets(wb.Sheets.Count)) wb.Sheets(wb.Sheets.Count).Name = TempStr for j in range(1, LastCol+1): wb.Sheets(wb.Sheets.Count).Cells(1, j).Value = Sh.Cells(1, j).Value Sh.Activate() excel_app.ScreenUpdating = True我再按照个人的习惯重新编写一下: rows_dict = {} Col = 2 excel_app.ScreenUpdating = False for i in range(2, LastRow+1): k = Sh.Cells(i, Col).Value if k not in rows_dict: Sht = excel_app.Sheets.Add(After=wb.Sheets(wb.Sheets.Count)) Sht.Name = k Sht.Range(Sht.Cells(1, 1), Sht.Cells(1, LastCol)).Value = Sh.Range( Sh.Cells(1, 1), Sh.Cells(1, LastCol)).Value rows_dict[k] = 1 else: Sht = wb.Sheets(k) rows_dict[k] += 1 Sht.Range(Sht.Cells(rows_dict[k], 1), Sht.Cells( rows_dict[k], LastCol)).Value = Sh.Range(Sh.Cells(i, 1), Sh.Cells(i, LastCol)).Value Sh.Activate() excel_app.ScreenUpdating = True最终完整代码: import win32com.client as win32 # 导入模块 import os excel_app = win32.gencache.EnsureDispatch('Excel.Application') filename = "数据源.xlsx" filename = os.path.abspath(filename) wb = excel_app.Workbooks.Open(filename) Sh = wb.ActiveSheet LastRow = Sh.Cells(excel_app.Rows.Count, 1).End(-4162).Row LastCol = Sh.Cells(1, excel_app.Columns.Count).End(-4159).Column rows_dict = {} Col = 2 excel_app.ScreenUpdating = False for i in range(2, LastRow+1): k = Sh.Cells(i, Col).Value if k not in rows_dict: Sht = excel_app.Sheets.Add(After=wb.Sheets(wb.Sheets.Count)) Sht.Name = k Sht.Range(Sht.Cells(1, 1), Sht.Cells(1, LastCol)).Value = Sh.Range( Sh.Cells(1, 1), Sh.Cells(1, LastCol)).Value rows_dict[k] = 1 else: Sht = wb.Sheets(k) rows_dict[k] += 1 Sht.Range(Sht.Cells(rows_dict[k], 1), Sht.Cells( rows_dict[k], LastCol)).Value = Sh.Range(Sh.Cells(i, 1), Sh.Cells(i, LastCol)).Value Sh.Activate() excel_app.ScreenUpdating = True wb.SaveAs(os.path.abspath("result.xlsx")) wb.Close() excel_app.Quit()经测试,原始vba代码在Excel环境中 运行耗时1秒以内,但运行以上python代码,耗时接近30秒。 这是因为,python通过vba读取Excel数据时,存在很频繁的交互,同时也说明并不是任何vba代码都适合用python来调用。对于大部分数据读写操作,用python自带的库会便捷很多,速度也会比vba快。对于样式复杂粘贴使用vba则极度方便。 使用Pandas实现Excel拆分上述vba代码实际上仅仅只是实现不带样式的拆分,对于这样的需求,其实用Pandas会非常简单: from openpyxl import load_workbook import pandas as pd df = pd.read_excel("数据源.xlsx") with pd.ExcelWriter('result.xlsx', engine='openpyxl') as writer: writer.book = load_workbook("数据源.xlsx") for area, df_split in df.groupby("区域"): df_split.to_excel(writer, area, index=False)缺点是日期没有保留原有的文本格式:
不过我们可以指定日期的格式: from openpyxl import load_workbook import pandas as pd df = pd.read_excel("数据源.xlsx") with pd.ExcelWriter('result.xlsx', engine='openpyxl', datetime_format='YYYY/MM/DD') as writer: writer.book = load_workbook("数据源.xlsx") for area, df_split in df.groupby("区域"): df_split.to_excel(writer, area, index=False)
使用了openpyxl还可以逐个单元格copy样式信息,相对来说会麻烦一些,也并不是所有样式都能复制。 不过但如果我们只需要保留表头样式拆分Excel表,可以通过openpyxl制作模板并加载模板,下面看看具体实现: 使用openpyxl保留表头样式拆分Excel表我们的实现目标依然是:
其实这种需求,除了表头样式以外并不需要关心下面的数据的样式。这时使用openpyxl才是最简单的,下面我们看看操作流程。 首先,我们读取数据并分组: from openpyxl import load_workbook num = 4 title_row = 2 filename = "工单.xlsx" book = load_workbook(filename) sheet = book.active # 读取并分组相应的数据 data = {} for row in sheet.iter_rows(min_row=title_row+1): row = [cell.value for cell in row] data_split = data.setdefault(row[num-1], []) data_split.append(row)然后遍历每组创建模板后写入对应数据: for name, data_split in data.items(): new_sheet = book.copy_worksheet(sheet) new_sheet.title = name # 删除标题行以外的数据作为模板 new_sheet.delete_rows(title_row+1, sheet.max_row) for row in data_split: new_sheet.append(row) book.save("拆分结果.xlsx")是不是非常简单?下面我们可以封装起来: from openpyxl import load_workbook def split_excel(filename, save_name, num, title_row=1): """小小明的CSDN:https://blog.csdn.net/as604049322""" book = load_workbook(filename) sheet = book.active # 读取并分组相应的数据 data = {} for row in sheet.iter_rows(min_row=title_row+1): row = [cell.value for cell in row] data_split = data.setdefault(row[num-1], []) data_split.append(row) for name, data_split in data.items(): new_sheet = book.copy_worksheet(sheet) new_sheet.title = name # 删除标题行以外的数据作为模板 new_sheet.delete_rows(title_row+1, sheet.max_row) for row in data_split: new_sheet.append(row) book.save(save_name) split_excel("工单.xlsx", '拆分结果.xlsx', 4, 2)但是使用openpyxl拆分也有较大缺陷,例如数据中存在日期格式时: split_excel("数据源.xlsx", '拆分结果2.xlsx', 2, 1)
日期格式自定义起来会比较麻烦,难以通用化,列宽需要手工自适应(这个我在《Pandas指定样式保存excel数据的N种姿势》一文中已经实现了pandas自适应调整)。 总结本文演示了通过复制粘贴筛选结果实现保留格式拆分表格的方法,并分别通过python调用和纯vba实现。作为一种一种抛砖引玉的做法并不能应对所有的需求,对于表头涉及多行合并单元格的需求还需各位童鞋发挥自己的脑洞,针对性解决相应的问题。 通过上述代码的样式详细大家都能看到,对于样式拷贝,使用vba很简单;对于数据处理,使用Pandas很简单;仅仅只拷贝表头样式,使用openpyxl最简单,但对于日期和列宽需要特殊处理。 |

【本文地址】
今日新闻 |
推荐新闻 |