Python pandas将excel的数据按月份分组求平均 |
您所在的位置:网站首页 › excel中平均值的计算 › Python pandas将excel的数据按月份分组求平均 |
Python pandas将excel的数据按月份分组求平均
|
先观察一下要处理的数据是怎样的,原始文件是有五组分隔开的数据,第一行是表示组名,第二行是列标签,第三行开始才是真正的数据。很容易就会想到使用pandas来处理这个文件了。 查看df的内容,可以看到列标签很多都是Unamed,是因为本来文件表格就是空的,因此也读取不到内容。而后面使用mean()求平均时,要使用标签Year和Month来进行分组,因此,要先将这个dataframe里面的第一行数据转换成列标签,再将这一行删除。 替换后的dataframe内容就是这样子的 但程序立马就报错了,通过查找发现原来是在使用groupby()函数的时候,是按照先对于Year标签分组,再根据Month标签分组,而我的数据里面,有不止一组Year和Month,也就是有重复的列,因此无法判断该按哪一组进行分组。 所以现在需要将除了一组Year和Month保留,其他的都要去掉。如果直接使用drop()函数,会把所有的Year和Month都删除,我也没找到能按索引来删除列的方法。那只能从根源入手了,在读取文件的时候,就把那些不需要的列排除在外。 数据data就会变成这样 我替换成求总和sum()试了一下,发现是可以计算的。那么就是mean()函数的问题了。 aver = data.groupby(['Year', 'Month']).sum()
我又去查,为什么我的mean()函数用不了。看到一个说法就是, 有可能是这个dataframe的列dtypes为object,而sum()函数可以对非数值进行计算,只要这个计算对这个数据类型有意义;但mean()函数不行,只能对数值进行计算。然后我查看了下data的dtypes,还真的全是object类型。  我又想起列名重复的问题,我统计了一下,重复的列名有5种共16列,每一种的个数平方再加上不重复的数量刚好就是62!这就说明,凡是重复的列都进行了重复的转换,也就是平方。(重复的问题真的太麻烦了)所以我把那个label列表用unique()函数筛选了一下,将重复的标签都删除了。 ```python unique_label = np.unique(label) a = data[unique_label].astype('float') ``` 最后再尝试一下mean()函数求平均
aver = data.groupby(['Year', 'Month']).mean() 我又想起列名重复的问题,我统计了一下,重复的列名有5种共16列,每一种的个数平方再加上不重复的数量刚好就是62!这就说明,凡是重复的列都进行了重复的转换,也就是平方。(重复的问题真的太麻烦了)所以我把那个label列表用unique()函数筛选了一下,将重复的标签都删除了。 ```python unique_label = np.unique(label) a = data[unique_label].astype('float') ``` 最后再尝试一下mean()函数求平均
aver = data.groupby(['Year', 'Month']).mean()
终于没有问题了 最终的代码 import pandas as pd import numpy as np read_num = [] for i in range(41): read_num.append(i) drop_list = [2, 7, 8, 9, 10, 16, 17, 18, 19, 25, 26, 27, 28, 33, 34, 35, 36] # 不需要读取的excel列号 read_num = np.delete(read_num, drop_list) df = pd.read_excel(io='use_nofillvalue(1).xlsx', usecols=read_num) label = list(df.iloc[0]) data = df.drop([0]) data.columns = label unique_label = np.unique(label) a = data[unique_label].astype('float') aver = a.groupby(['Year', 'Month']).mean() |
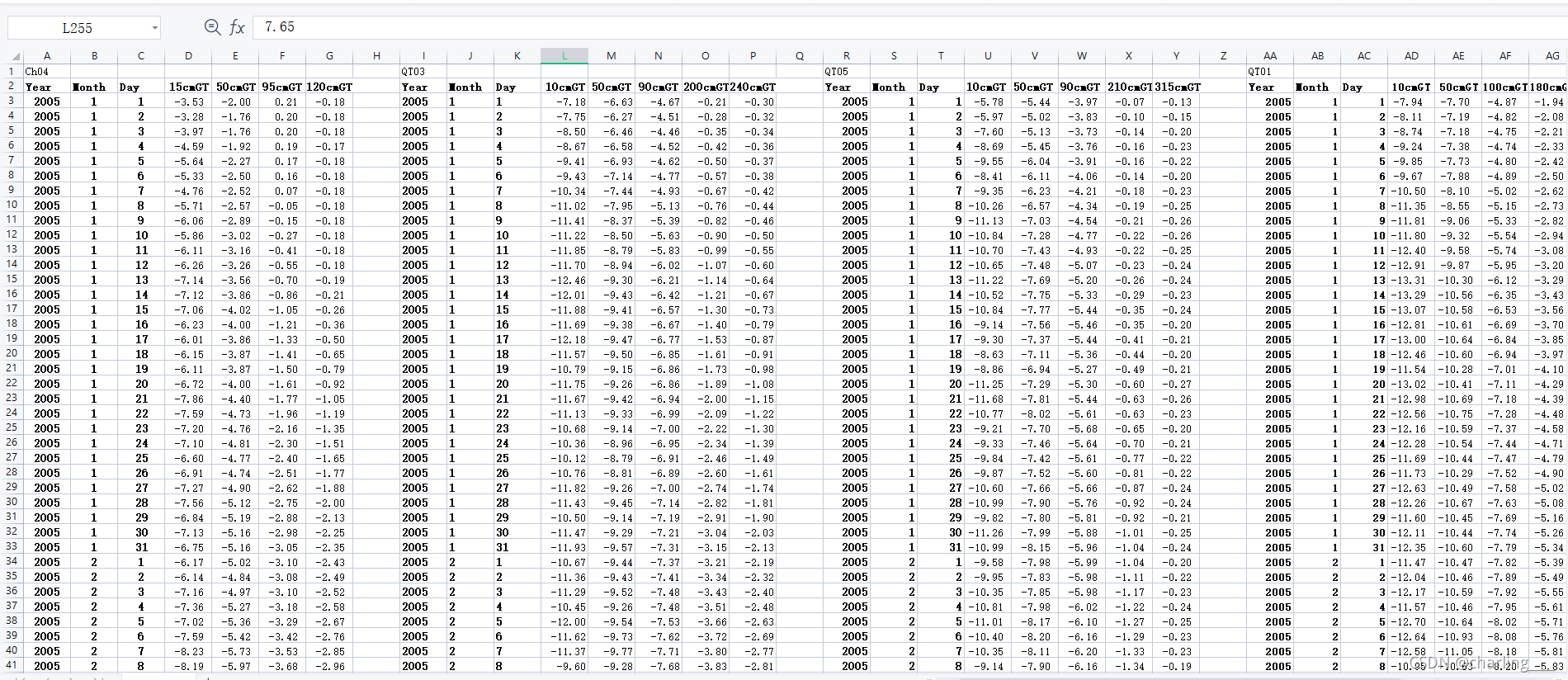 首先读取文件并创建一个dataframe对象
首先读取文件并创建一个dataframe对象 添加一下代码进行替换
添加一下代码进行替换 按道理来说,就可以直接使用mean()函数进行求平均了,通过下面这行代码
按道理来说,就可以直接使用mean()函数进行求平均了,通过下面这行代码 将最开始的读取文件那一行代码替换成下面这段代码
将最开始的读取文件那一行代码替换成下面这段代码 此时数据已经清洗完毕了,再运行一次代码。再次报错,没有要聚合的数字类型。可是查看dataframe的内容时,明明数据都没有错,这究竟是groupby()函数还是mean()函数出了问题?
此时数据已经清洗完毕了,再运行一次代码。再次报错,没有要聚合的数字类型。可是查看dataframe的内容时,明明数据都没有错,这究竟是groupby()函数还是mean()函数出了问题? 
 那么现在的问题就是要将这些数据转换成float型了,尝试了pd.to_numeric和val方法,但是转得都不成功。干脆就不用pandas的函数了,直接使用强制转换.astype(‘float’),然后数据类型就转换好了。 但这里又出现了一个问题,原来data只有24列,而现在a有62列,说明这里还有问题。
那么现在的问题就是要将这些数据转换成float型了,尝试了pd.to_numeric和val方法,但是转得都不成功。干脆就不用pandas的函数了,直接使用强制转换.astype(‘float’),然后数据类型就转换好了。 但这里又出现了一个问题,原来data只有24列,而现在a有62列,说明这里还有问题。
【本文地址】
今日新闻 |
推荐新闻 |