Eviews10.0面板数据操作手册 |
您所在的位置:网站首页 › eviews面板数据回归结果怎么看 › Eviews10.0面板数据操作手册 |
Eviews10.0面板数据操作手册
|
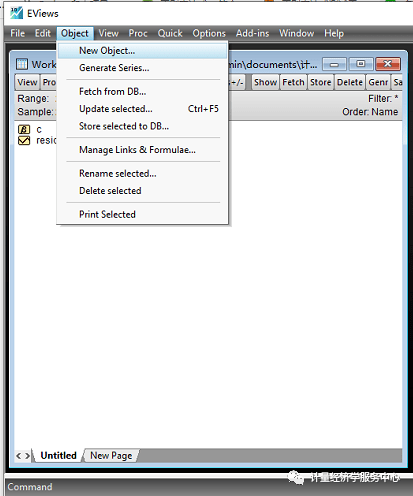
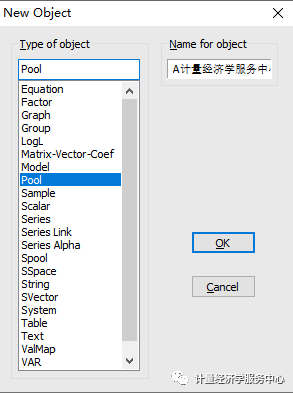
2、创建新对象。 操作如下图。在”new object”文本框的”type of object”选择”pool”,”name for object ”输入新对象的名称。创建成功后的界面如下图所示。
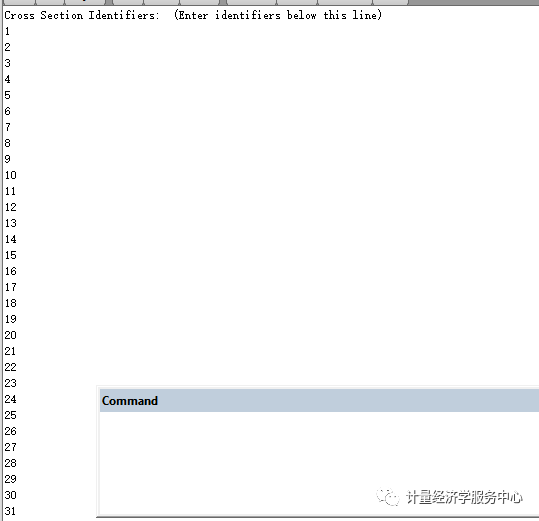
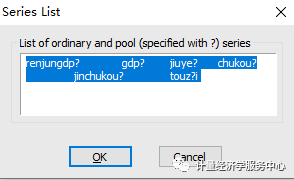
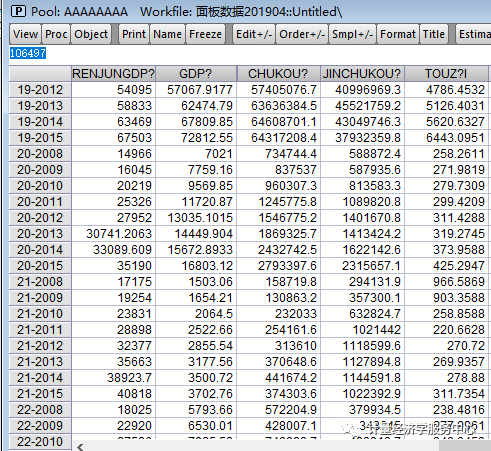
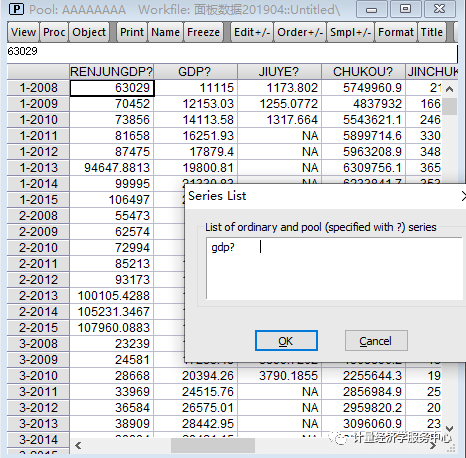
3、输入数据。 双击”workfile”界面的“POOL”,跳出”pool”界面,输入个体。一般输入方式为如下:若上海输入_sh,北京输入_bj,…。个体输入完成后,点击该界面的键,在跳出的”series list”输入变量名称,注意变量后要加问号。格式如下:y? x?。点击”OK”后,跳出数据输入界面,如下图所示。在这个界面上点击键,即可以输入或者从EXCEL处复制数据。 例如很多省份取省份的前面几个字母,点sheet,然后这里以数字1-31为例,相关进行输入!
4、然后点击sheet,定义序列名并输入数据
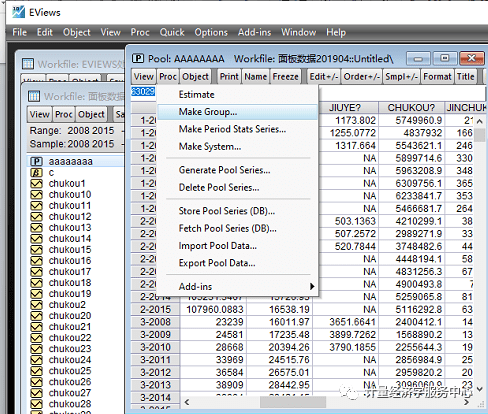
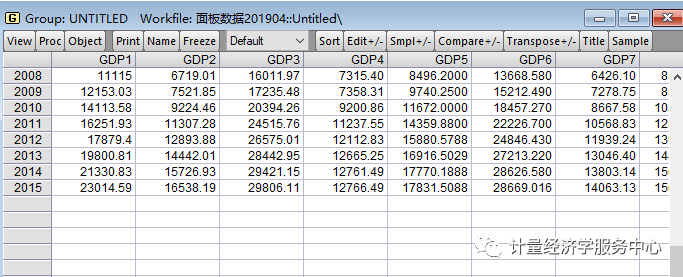
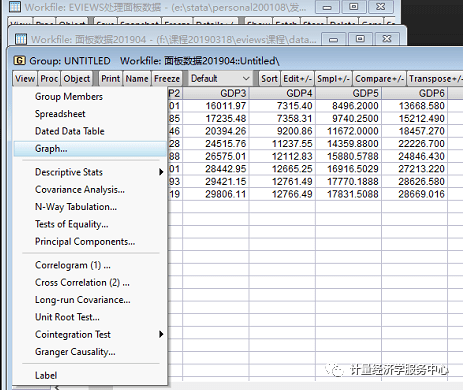
在输入数据后,记得保存数据。保存操作如下: 5、单位根检验。 一般回归前要检验面板数据是否存在单位根,以检验数据的平稳性,避免伪回归,或虚假回归,确保估计的有效性。单位根检验时要分变量检验。(补充:网上对面板数据的单位根检验和协整检验存在不同意见,一般认为时间区间较小的面板数据无需进行这两个检验。) (1)生成数据组。如下图操作。点击”make group”后在跳出的”series list”里输入要单位根检验的变量,完成后就会跳出如下图所示的组数据。
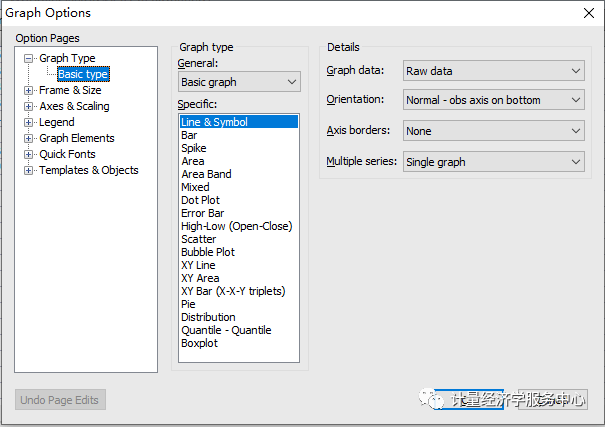
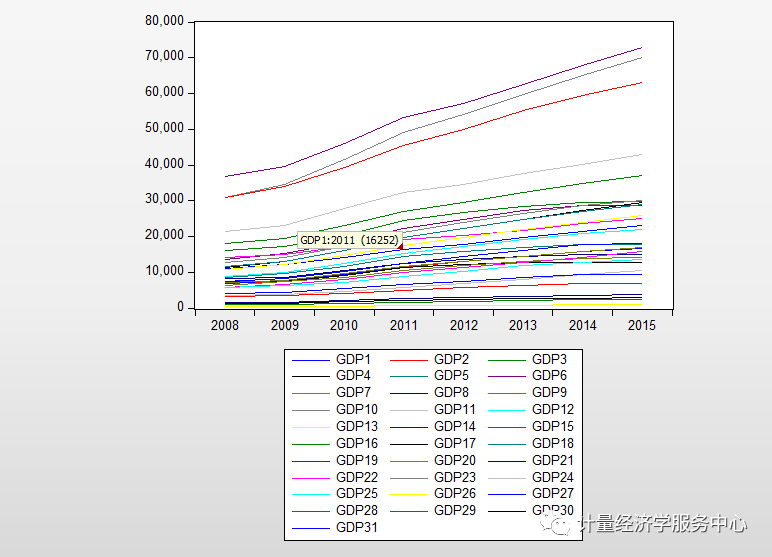
(2)生成时序图。如下图操作。在”gragh options”界面的”specifi”下选择生成的时序图的形状,一般都默认设置,生成的时序图如下图3所示。观察时序图的趋势,以确定单位根检验的检验模式。
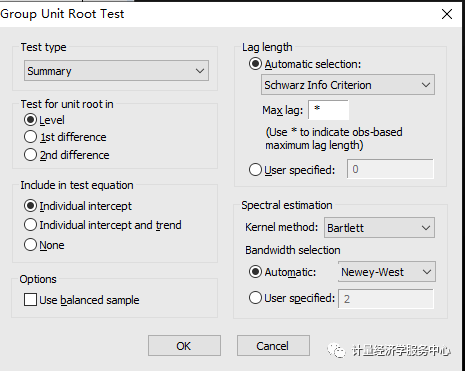
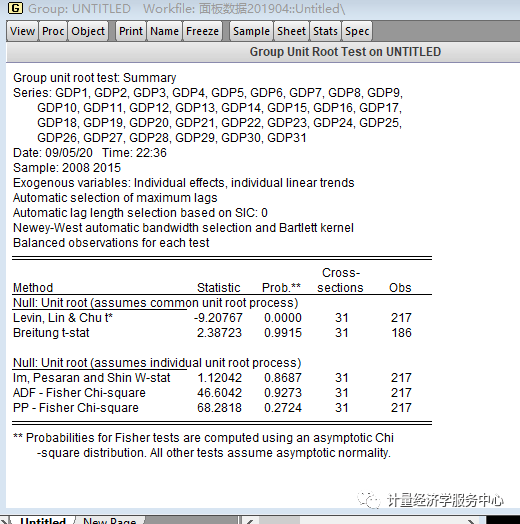
(3)单位根检验。单位根检验时,在”group unit root test”里的”test for root in”按检验结果一步步检验,如果原值”level”的检验结果符合要求,即不存在单位根,则单位根检验就不需要检验下去了,如果不符合要求,则需继续检验一阶差分”1st difference”、二阶差分”2nd difference”。”include in test equation”是检验模式的选择,根据上面时序图的形状来选择。从上面的时序图可以看出,原值的检验模式应该选择含有截距项和趋势的检验模式,即”include in test equation”选择”individual intercept and trend”。检验结果如下图3所示。从检验结果可以看出,检验结果除了levin检验方法外其他方法的结果都不符合要求(Prob.xx小于置信度(如0.05),则认为拒绝单位根的原假设,通过检验)。所以继续检验一阶差分和二阶差分,直到检验结果达到要求。如果变量原值序列通过单位根检验,则称变量为0阶单整;如果变量一阶差分后的序列通过单位根检验,则称变量为一阶单整,以此推之。 注意:单位根检验的方法(test type)较多,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher这5种方法进行面板单位根检验。一般,为了方便起见,只采用相同根单位根检验LLC和不同根单位根检验Fisher-ADF这两种检验方法,如果它们都拒绝存在单位根的原假设,则可以认为此序列是平稳的,反之就是非平稳的。
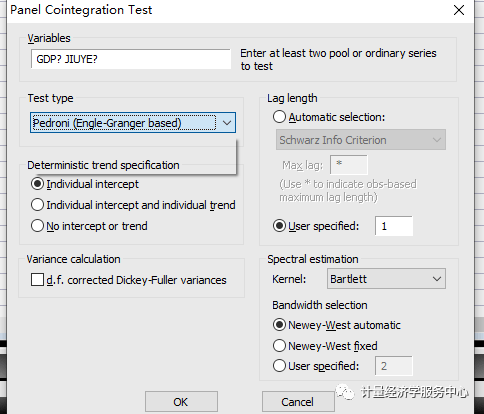
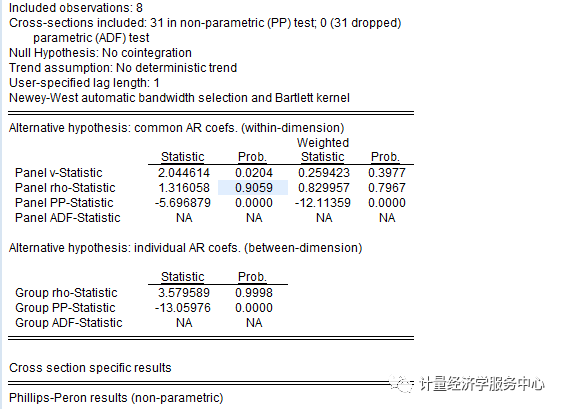
6、协整检验。协整检验检验的是模型的变量之间是否存在长期稳定的关系,其前提是解释变量和被解释变量在单位根检验时为同阶单整。操作如下图所示。
7、回归估计 面板数据模型根据常数项和系数向量是否为常数,分为3种类型:混合回归模型(都为常数)、变截距模型(系数项为常数)和变系数模型(皆非常数)。
判断一个面板数据究竟属于哪种模型,用F统计统计量:
来检验以下两个假设:
估计、选择面板模型 打开一个pool窗口,先输入变量后缀(所要使用的变量)。点击Estimate,打开估计窗口。
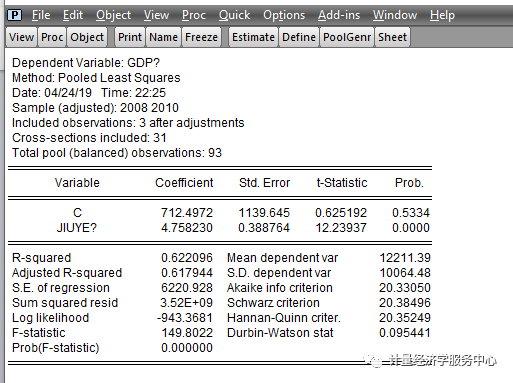
A.混合模型的估计方法 左边的Common表示相同系数,即表示不同个体有相同的斜率。 得到如下输出结果:
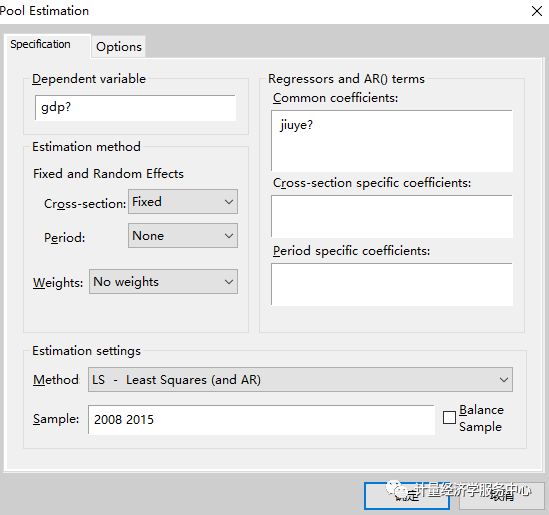
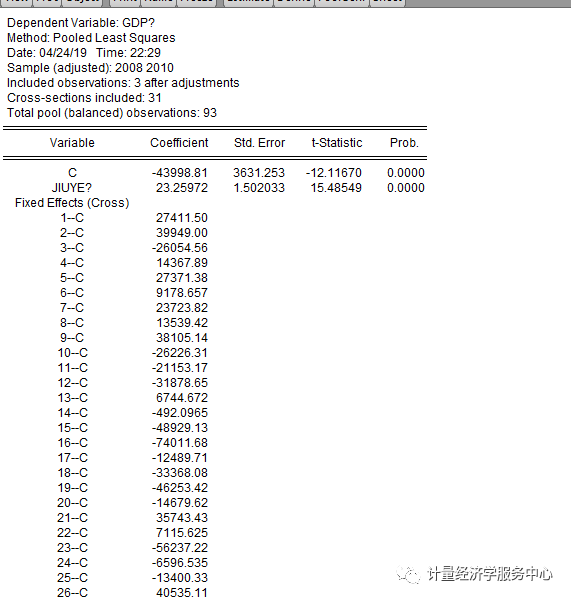
B、个体固定效应回归模型的估计方法 将截距项选择区选**Fixed effects(固定效应)**
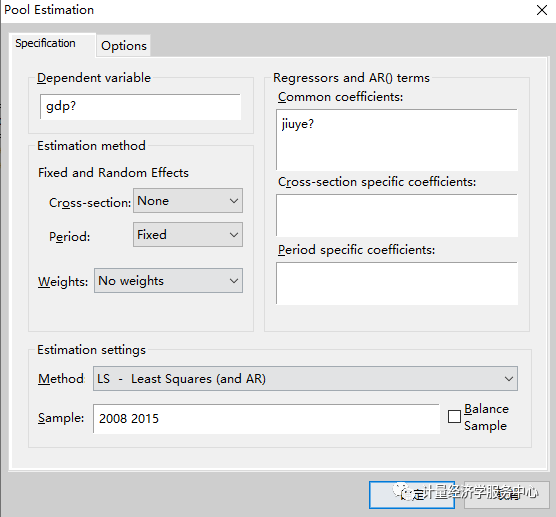
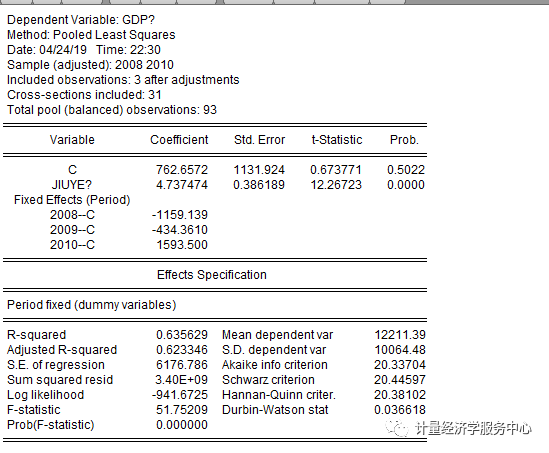
C.时点固定效应回归模型的估计方法 将时间选择为固定效应。
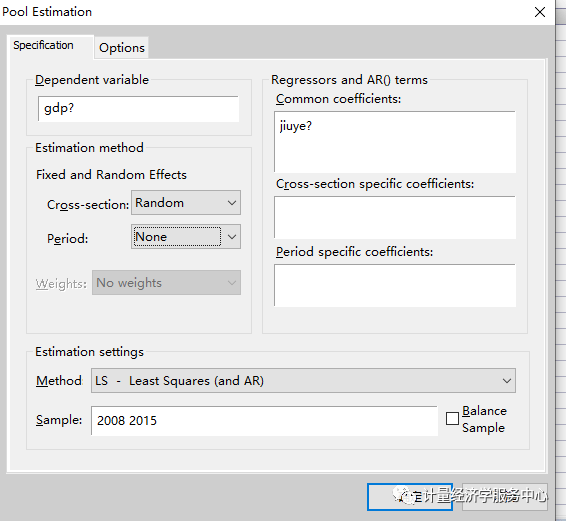
统计量结果解释: 上图列示了回归结果,其中:Coefficient为系数,t-Statistic为t值,检验每一个自变量的合理性。|t|大于临界值表示可拒绝系数为0的假设,即系数合理。Prob为系数的概率,若其小于置信度(如0.05)则表明|t|大于临界值,即认为系数合理。 R-squared为样本决定系数,表示总离差平方和中由回归方程可以解释部分的比例,比例越大说明回归方程可以解释的部分越多。值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,所以可以通过增加自变量的个数来提高模型的R-squared。 Adjust R-seqaured为 修正的R-squared,与R-squared有相似意义。 F-statistic表示模型拟合样本的效果,即选择的所有自变量对因变量的解释力度。F大于临界值则说明拒绝0假设。若Prob(F-statistic)小于置信度(如0.05)则说明F大于临界值,方程显著性明显。 Durbin-Watson stat:检验残差序列的自相关性。其值在0-4之间。 D.个体随机效应回归模型估计 截距项选择Random effects(个体随机效应)**
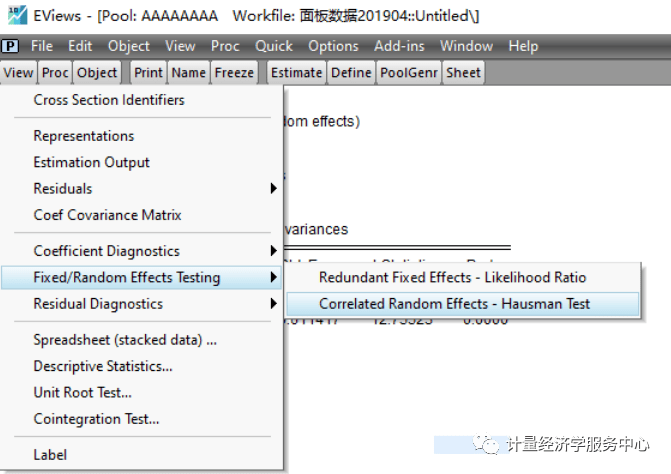
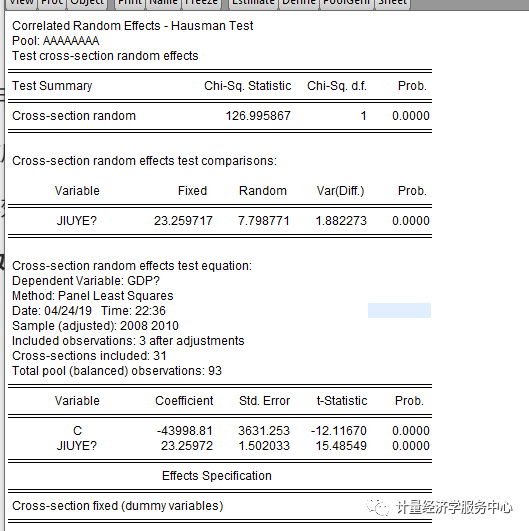
接下来利用Hausman统计量检验应该建立个体随机效应回归模型还是个体固定效应回归模型。 H0个体效应与回归变量无关(个体随机效应回归模型) H1:个体效应与回归变量相关(个体固定效应回归模型) 分析过程如下:
|
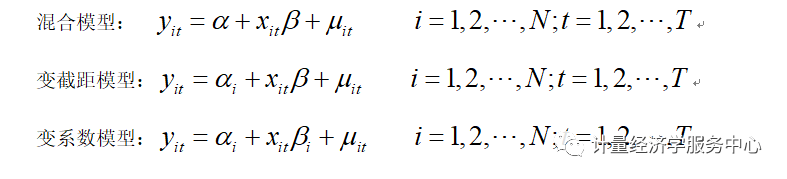
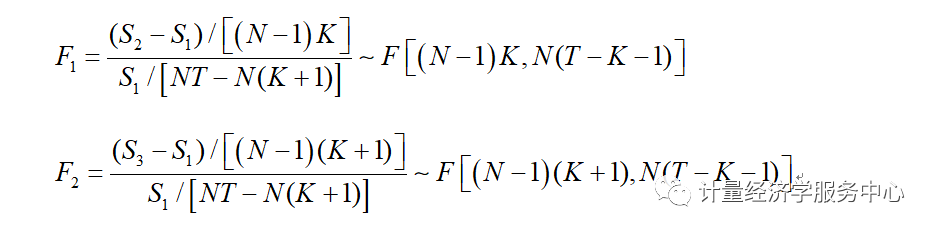


 返回搜狐,查看更多
返回搜狐,查看更多【本文地址】
今日新闻 |
推荐新闻 |