金融时间序列分析 |
您所在的位置:网站首页 › eviews建立garch模型说我数据不连续 › 金融时间序列分析 |
金融时间序列分析
|
来源:雪球App,作者: _至简量化_,(https://xueqiu.com/8185159194/285017930)  这里是至简量化,一个分享量化交易知识和应用的公众号。 我们还有另一个号--复哥读与思,分享财经读书心得和观点,欢迎同步关注。 本篇是金融时间序列分析系列的第5篇,本系列目前计划写10篇。 本系列前面的内容一直忽略了对时间序列的波动性进行建模,这可能是之前的预测效果不够理想的原因之一。 本篇我们首先介绍如何对时间序列的方差建模,这方面常用的模型主要是ARCH和GARCH,还有其它一些由它们派生出的模型,大家有兴趣可以自己了解。GARCH 在金融行业应用广泛,因为许多资产价格都是条件异方差的。接下来我们将前面介绍过的ARMA与GARCH结合起来预测沪深300指数的未来收益率,看是否能取得更好的预测效果。 条件异方差性传统的计量经济学假定时间序列变量的波动幅度是固定的,这显然不符合实际,人们早就发现股票收益的波动幅度是随时间而变化的,并非常数。这一观察推动了金融领域条件异方差的研究。 异方差性 (heteroskedasticity) 指的是一组数据中,不同子集的方差存在差异。换句话说,数据的分散程度会随着某些因素的变化而改变。 在金融领域中,资产收益率的波动往往会导致后续收益率的进一步波动。例如,当股市大幅下跌时,自动风险管理系统会触发止损卖单,进一步推低股价,导致更大的向下波动。在这类抛售中,异方差性与波动性周期相关,这就意味着存在条件异方差性 (conditional heteroskedasticity)。 条件异方差性的一个挑战在于,尽管数据方差随时间变化,但其自相关函数 (ACF) 仍可能看起来像是平稳的白色噪声。为了将条件异方差性纳入模型,我们需要一个模型,该模型能够利用过去方差值来预测未来方差的变化,ARCH就是这样的模型。 ARCH与GARCH模型自回归条件异方差(autoregressive conditionally heteroscedastic,ARCH)模型是一种统计模型,通过分析时间序列的波动性以预测未来的波动性。可以将ARCH(p) 模型简单地视为应用于时间序列方差的 AR(p) 模型,公式表示为:
当我们试图拟合一个AR(p)模型时,我们关注时间序列的ACF图上滞后项的衰减情况,我们可以将相同的逻辑应用于残差的平方。要应用ARCH(p),首先应该用合适的AR(p)等模型对时间序列进行充分拟合,使残差看起来像离散白噪声,即均值为零且自相关为零。然后,检查残差平方的 ACF,如果残差平方的 ACF 缓慢衰减,表明存在异方差性,可以使用 ARCH(p) 模型对其进行建模。 注意,ARCH(p) 模型适用于没有趋势和季节性的时间序列。如果数据存在趋势或季节性,需要先对其进行处理,然后再考虑使用 ARCH(p) 模型。 既然我们可以用AR(p)过程应用于时间序列的方差,为什么我们不能用更综合的ARMA(p,q)过程来处理时间序列的方差呢?当然可以,这就是GARCH模型。 广义自回归条件异方差 (Generalized AutoRegressive Conditional Heteroskedasticity,GARCH) 模型是一种用于分析时间序列数据的统计模型,可以认为是时间序列的ARMA(p,q)过程。公式表示为:
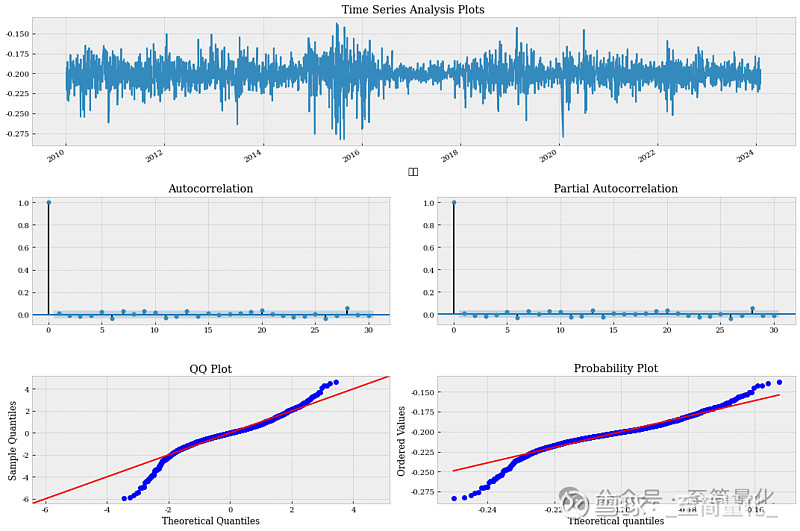
GARCH 模型是 ARCH 模型的扩展,它不仅考虑了过去误差项的影响,还考虑了过去条件方差的影响。因此,GARCH 模型可以更好地捕捉波动率的聚集现象。 ARMA+GRACH实现 ARCH在金融领域应用较少,我们直接用GARCH模型进行时间序列分析,本篇仍以沪深300指数的日频收益率数据为例。流程如下: 1.迭代 ARMA(p, q) 模型的组合以找出最适合我们的时间序列的阶数。 2.根据 AIC 最低的 ARMA(p, q)模型选择 GARCH 模型阶数。 3.将 GARCH(p, q) 模型拟合到我们的时间序列中。 4.检查模型残差和残差平方的自相关性。 我们首先尝试将沪深300日收益率代入到 ARMA 过程并找到最佳顺序。 我们在前面的文章中已经通过迭代找出最适合沪深300指数收益率的ARMA模型是ARMA(4,2),现在我们从这个结论出发,首先用ARMA(4,2)模型拟合指数收益率数据,对残差进行分析。代码如下: #用ARMA拟合指数 model = SARIMAX(endog=pct_csi300, order=(4,0,2), simple_differencing=False) model_fit = model.fit(disp=False) #分析画图函数 import matplotlib.pyplot as plt import statsmodels.tsa.api as smt import statsmodels.api as sm import scipy.stats as scs def tsplot(y, lags=None, figsize=(15, 10), style='bmh'): if not isinstance(y, pd.Series): y = pd.Series(y) with plt.style.context(style): fig = plt.figure(figsize=figsize) #mpl.rcParams['font.family'] = 'Ubuntu Mono' layout = (3, 2) ts_ax = plt.subplot2grid(layout, (0, 0), colspan=2) acf_ax = plt.subplot2grid(layout, (1, 0)) pacf_ax = plt.subplot2grid(layout, (1, 1)) qq_ax = plt.subplot2grid(layout, (2, 0)) pp_ax = plt.subplot2grid(layout, (2, 1)) y.plot(ax=ts_ax) ts_ax.set_title('Time Series Analysis Plots') smt.graphics.plot_acf(y, lags=lags, ax=acf_ax, alpha=0.05) smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax, alpha=0.05) sm.qqplot(y, fit=True,line='45', ax=qq_ax) qq_ax.set_title('QQ Plot') scs.probplot(y, sparams=(y.mean(), y.std()), plot=pp_ax) plt.tight_layout() return #对拟合残差进行分析 tsplot(model_fit.resid , lags=30) 输出结果如下:
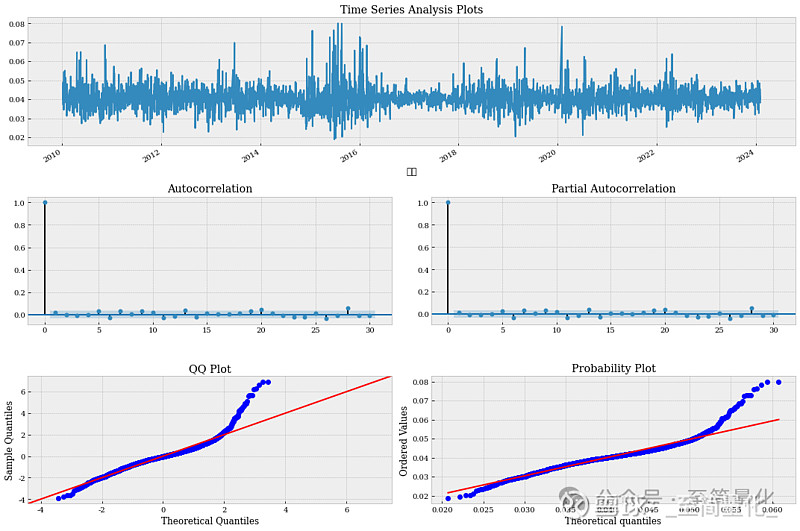
从图中看残差近似于白噪声,下面我们对残差的平方进行分析,代码如下: tsplot(model_fit.resid**2, lags=30) 输出结果如下:
从图中我们可以看到残差平方有明显的自相关性,残差平方的ACF图显示直到滞后30期的自相关系数都很显著,PACF则显示从滞后6期开始系数不再显著,因此我们尝试用GARCH(5,5)来拟合指数时间序列。代码如下: from arch import arch_model am = arch_model(model_fit.resid, p=5,q=5, dist='StudentsT') res = am.fit(update_freq=5, disp='off') print(res.summary()) 接下来对GARCH(5,5)拟合的残差进行分析,代码如下: tsplot(res.resid, lags=30) 输出结果为:
再对GARCH(5,5)拟合的残差平方进行分析,代码如下: tsplot(res.resid**2, lags=30) 输出结果为:
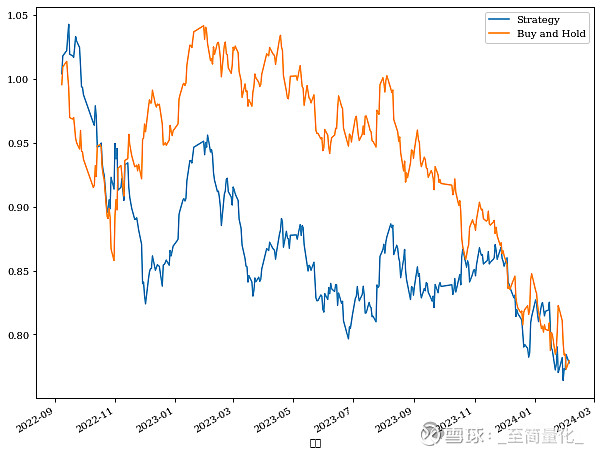
这次我们实现了残差平方的离散白噪声,这表明我们通过同时使用ARMA和 GARCH解释了残差平方中存在的序列相关性。 现在,我们已经成功在时间序列分析中应用ARIMA 和 GARCH的组合拟合股票市场指数,下一步是根据该组合实际生成未来每日收益率的预测,并使用它来创建基本交易策略。 收益率预测的代码如下: from statsmodels.tsa.statespace.sarimax import SARIMAX import arch #pct_csi300 = pct_csi300.to_frame() train = pct_csi300[:int(0.9*len(pct_csi300))] test = pct_csi300[int(0.9*len(pct_csi300)):] pred_df = test.copy() TRAIN_LEN = len(train) HORIZON = len(test) WINDOW = 1 def rolling_forecast(df: pd.DataFrame, train_len: int, horizon: int, window: int, method: str) -> list: total_len = train_len + horizon #以历史均值作为对未来的预测 if method == 'mean': pred_mean = [] for i in range(train_len, total_len, window): mean = np.mean(df[:i].values) pred_mean.extend(mean for _ in range(window)) return pred_mean #以上一个值作为未来值的预测 elif method == 'last': pred_last_value = [] for i in range(train_len, total_len, window): last_value = df[:i].iloc[-1].values[0] pred_last_value.extend(last_value for _ in range(window)) return pred_last_value elif method == 'ARMA': pred_ARMA = [] for i in range(train_len, total_len, window): #order=(4,0,2)代表使用ARMA(4,2)模型 model = SARIMAX(df[:i], order=(4,0,2)) res = model.fit(disp=False) predictions = res.get_prediction(0, i + window - 1) oos_pred = predictions.predicted_mean.iloc[-window:] print(oos_pred) pred_ARMA.extend(oos_pred) return pred_ARMA elif method == 'ARMA_GARCH': pred_ARMA_GARCH = [] for i in range(train_len, total_len, window): #order=(4,0,2)代表使用ARMA(4,2)模型 model = SARIMAX(df[:i], order=(4,0,2)) arma_fit = model.fit(disp=False) # fit a GARCH(1,1) model on the residuals of the ARIMA model garch = arch.arch_model(arma_fit.resid, p=1, q=1) garch_fitted = garch.fit(disp='off') # Use ARMA to predict mu predictions = arma_fit.get_prediction(0, i + window - 1) predicted_mu = predictions.predicted_mean.iloc[-window:] # Use GARCH to predict the residual garch_forecast = garch_fitted.forecast(horizon=1) predicted_et = garch_forecasan['h.1'].iloc[-window:] print('mean:') print(predicted_mu) print('residual:') print(predicted_et) # Combine both models' output: yt = mu + et prediction = pd.Series(predicted_mu.values + predicted_et.values, index=predicted_mu.index) print('prediction:') print(prediction) pred_ARMA_GARCH.extend(prediction) return pred_ARMA_GARCH pred_mean = rolling_forecast(pct_csi300, TRAIN_LEN, HORIZON, WINDOW, 'mean') pred_last_value = rolling_forecast(pct_csi300, TRAIN_LEN, HORIZON, WINDOW, 'last') pred_ARMA = rolling_forecast(pct_csi300, TRAIN_LEN, HORIZON, WINDOW, 'ARMA') pred_ARMA_GARCH = rolling_forecast(pct_csi300, TRAIN_LEN, HORIZON, WINDOW, 'ARMA_GARCH') pred_df['pred_mean'] = pred_mean pred_df['pred_last_value'] = pred_last_value pred_df['pred_ARMA'] = pred_ARMA pred_df['pred_ARMA_GARCH'] = pred_ARMA_GARCH 接下来对四个预测分别计算均方误差: from sklearn.metrics import mean_squared_error mse_mean = mean_squared_error(pred_df['收盘'], pred_df['pred_mean']) mse_last = mean_squared_error(pred_df['收盘'], pred_df['pred_last_value']) mse_ARMA = mean_squared_error(pred_df['收盘'], pred_df['pred_ARMA']) mse_ARMA_GARCH = mean_squared_error(pred_df['收盘'], pred_df['pred_ARMA_GARCH']) print(mse_mean, mse_last, mse_ARMA,mse_ARMA_GARCH) 输出结果为: 9.34414612157773e-05 0.0001814411637768193 9.4063280396096 很遗憾,ARMA_GARCH的预测效果并不太好。接下来我们还是尝试根据ARMA_GARCH的预测结果构建一个简单的策略,如果预测第二天上涨则做多,否则做空,为了验证策略效果,我们将策略执行结果与最简单的买入持有策略做对比。 代码如下: returns = pd.DataFrame(index = pred_df.index, columns=['Buy and Hold', 'Strategy']) returns['Buy and Hold'] = pred_df['收盘'] returns['Strategy'] = np.sign(pred_df['pred_ARMA_GARCH'])*returns['Buy and Hold'] eqCurves = pd.DataFrame(index = pred_df.index, columns=['Buy and Hold', 'Strategy']) eqCurves['Buy and Hold']=returns['Buy and Hold'].cumsum()+1 eqCurves['Strategy'] = returns['Strategy'].cumsum()+1 eqCurves['Strategy'].plot(figsize=(10,8)) eqCurves['Buy and Hold'].plot() plt.legend() plt.show() 输出结果如下:
策略表现结果也一般,这也正常,如果股市那么容易预测那大家都可以随便赚钱了。 本系列到现在为止一直只用指数本身的历史数据预测未来,结果都不太理想,下一篇我们尝试引入其它外部变量,看能否提升预测效果。 参考资料: Time Forcasting in python,Macro Peixeiro 金融时间序列分析--用ARMA模型预测股市涨跌 金融时间序列分析--股市真的不可预测吗? 万0.85开户,十几家大小券商任选! |
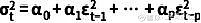
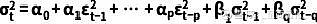
【本文地址】
今日新闻 |
推荐新闻 |