集群监控指标含义、异常原因和处理建议 |
您所在的位置:网站首页 › es日志监控 › 集群监控指标含义、异常原因和处理建议 |
集群监控指标含义、异常原因和处理建议
|
阿里云Elasticsearch为运行中的集群提供了多项基础监控指标(例如集群状态、集群查询QPS、节点CPU使用率、节点磁盘使用率等)和高级监控报警指标(例如Cluster、Index、Note Resource等),用来监测集群的运行状况。您可以根据这些指标,实时了解集群的运行状况,及时处理潜在风险,保障集群稳定运行。本文介绍如何查看集群监控详情,以及各监控指标含义、异常原因和异常处理建议。 监控差异说明 阿里云Elasticsearch集群监控可能与Kibana或第三方监控存在如下差异: 采样周期差异性:采集周期和Kibana或第三方监控存在差异,采集到的数据不同,因此会存在差异。 查询算法差异性:例如,阿里云Elasticsearch集群监控和Kibana监控采集数据时都会受集群稳定性的影响,集群监控QPS指标会因集群的抖动会出现监控突增、负值或无监控等状况,而Kibana监控可能显示为空。 说明 如果集群监控提供的指标比Kibana监控多,在实际使用时,建议将集群监控和Kibana监控结合起来分析集群监控详情。 采集接口差异性:Kibana监控指标依赖于Elasticsearch API,而集群监控部分节点级别的指标(例如CPU使用率、load_1m、磁盘使用率等),调用的是阿里云Elasticsearch底层系统接口,因此监控中除了Elasticsearch进程外还包含了系统级别资源的占用情况。 查看集群监控详情 登录阿里云Elasticsearch控制台。 在左侧导航栏,单击Elasticsearch实例。 进入目标实例。 在顶部菜单栏处,选择资源组和地域。 在左侧导航栏,单击Elasticsearch实例,然后在Elasticsearch实例中单击目标实例ID。 在左侧导航栏,选择监控与日志 > 集群监控。 查看监控详情。 查看高级监控报警详情 单击高级监控报警页签,选择监控时段,查看该时段内的监控详情。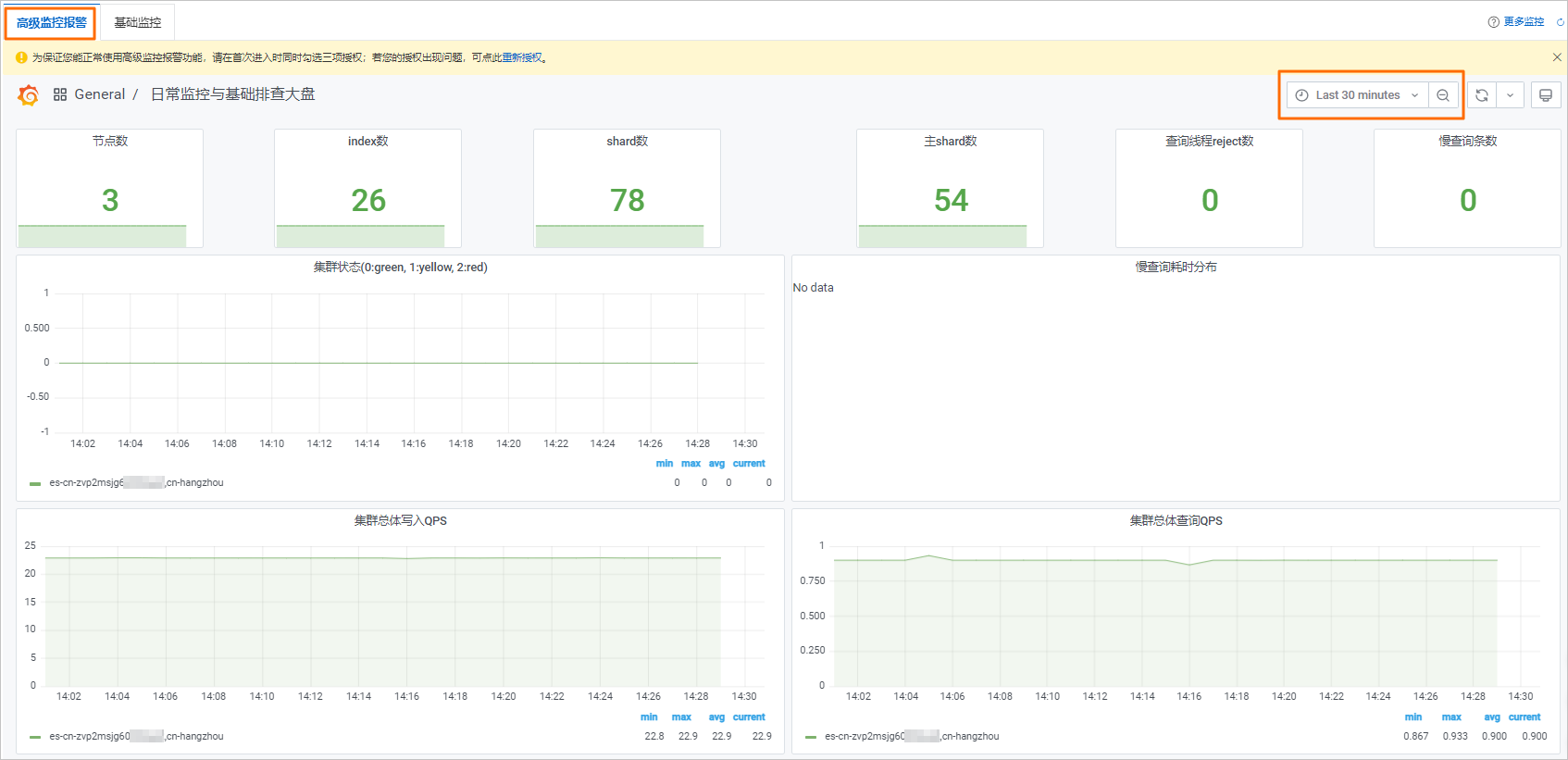 说明
高级监控报警功能目前仅支持杭州、北京、上海、深圳、青岛、张家口、美国东部、美国西部、日本、印度、印度尼西亚、中国香港等地域,具体以控制台为准。详细信息请参见高级监控报警概述。
阿里云Elasticsearch实例的版本不同,支持的高级监控指标也不同,具体以控制台为准。
高级监控报警页面仅展示指标数据在Top 20内的节点的监控信息。
集群的主要监控指标包含(实际以控制台为准):
集群状态(value)
慢查询耗时分布
集群写入QPS(Count/Second)
集群查询QPS(Count/Second)
index bulk写入tps
index查询QPS
节点CPU使用率(%)
节点HeapMemory使用率(%)
节点load_1m(value)
节点磁盘使用率(%)
old区使用
old gc频次
old gc耗时
fielddata内存使用
查看基础监控详情
查看基础监控页签,选择资源类型和监控时段,查看该类别的资源在对应时段内的监控详情。
说明
高级监控报警功能目前仅支持杭州、北京、上海、深圳、青岛、张家口、美国东部、美国西部、日本、印度、印度尼西亚、中国香港等地域,具体以控制台为准。详细信息请参见高级监控报警概述。
阿里云Elasticsearch实例的版本不同,支持的高级监控指标也不同,具体以控制台为准。
高级监控报警页面仅展示指标数据在Top 20内的节点的监控信息。
集群的主要监控指标包含(实际以控制台为准):
集群状态(value)
慢查询耗时分布
集群写入QPS(Count/Second)
集群查询QPS(Count/Second)
index bulk写入tps
index查询QPS
节点CPU使用率(%)
节点HeapMemory使用率(%)
节点load_1m(value)
节点磁盘使用率(%)
old区使用
old gc频次
old gc耗时
fielddata内存使用
查看基础监控详情
查看基础监控页签,选择资源类型和监控时段,查看该类别的资源在对应时段内的监控详情。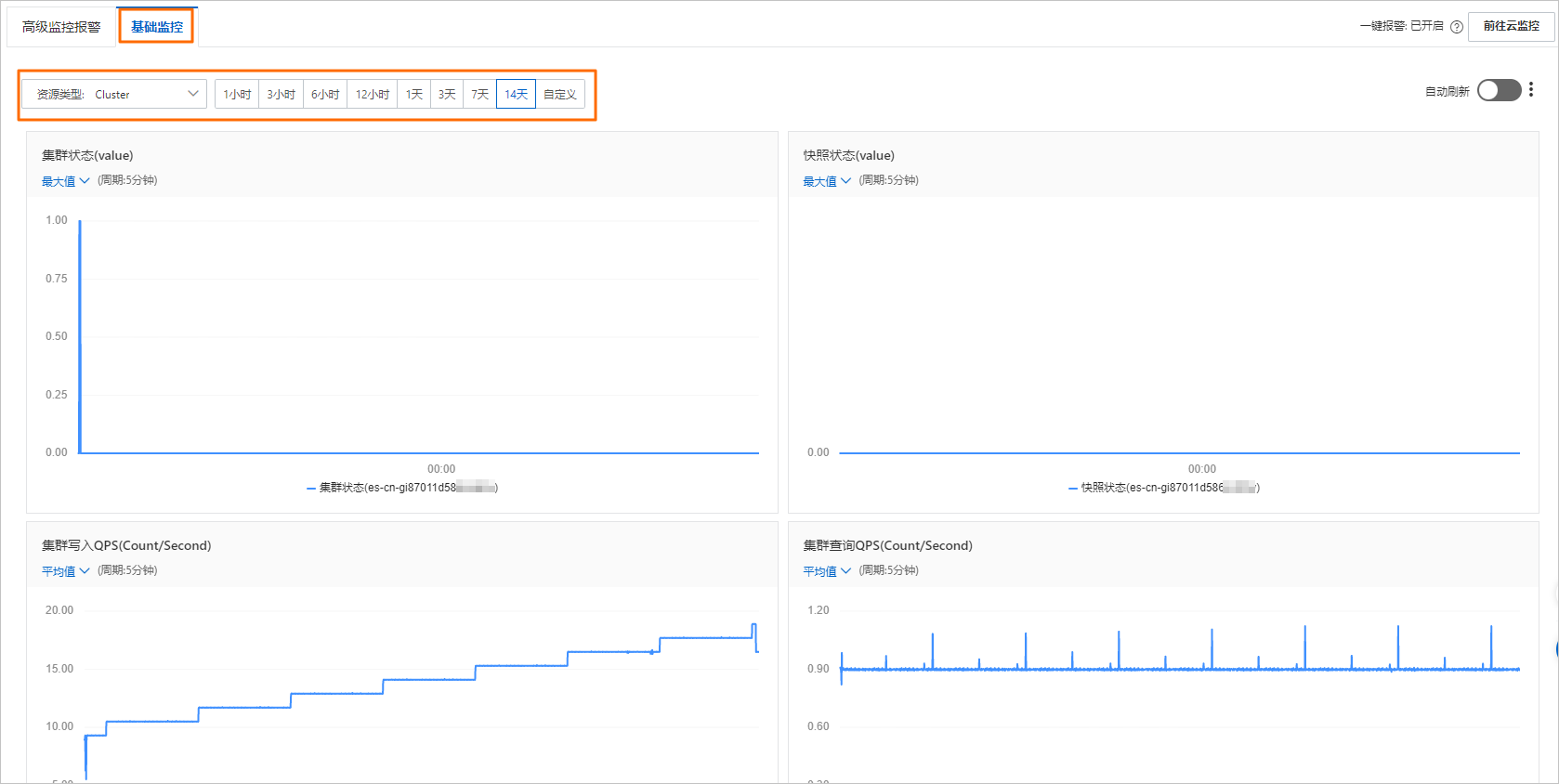 您也可以单击自定义,选择开始时间和结束时间,单击确定,查看自定义时间段内的监控详情。
说明 Elasticsearch实例的监控报警默认为开启状态,因此您可以在集群监控页面查看历史监控数据。目前只保留30天内的监控信息,并且提供分钟粒度的数据。
集群的主要监控指标包含(实际以控制台为准):
集群状态(value)
集群写入QPS(Count/Second)
集群查询QPS(Count/Second)
节点CPU使用率(%)
节点磁盘使用率(%)
节点HeapMemory使用率(%)
节点load_1m(value)
FullGc次数(count)
Exception次数(count)
快照状态(value)
节点网络流入包(count)
节点网络流出包(count)
数据流入率(KB/s)
数据流出率(KB/s)
节点TCP链接数(count)
IOUtil(%)
每秒完成的读请求数量(count)
每秒钟读取的大小(MB/s)
每秒完成的写请求数量(count)
每秒钟写入的大小(MB/s)
集群状态(value)
指标含义
集群状态指标展示了集群的健康度,数值为0.00时表示正常。此监控指标必须配置,配置方法请参见配置集群告警。指标各数值的含义如下。
数值
颜色
状态
说明
2.00
红色
不是所有的主分片都可用。
表示该集群中某个或某几个索引的主分片丢失(unassigned)。
1.00
黄色
所有主分片可用,但不是所有副本分片都可用。
表示该集群中某个或某几个索引的副本分片丢失(unassigned)。
0.00
绿色
所有主分片和副本分片都可用。
表示该集群中的所有索引都很健康,不存在丢失(unassigned)的分片。
说明 表中的颜色是指在实例的基本信息页面所看到的集群状态的颜色。
指标异常原因
监控期间,当指标数值不为0.00时,表示集群状态异常,常见原因如下:
节点的CPU或HeapMemory使用率过高,甚至达到100%。
节点的磁盘使用率过高,例如超过85%,甚至达到100%。
节点的load_1m负载过高。
集群中索引的健康度出现过非健康(非绿色)状态。
异常处理建议
在Kibana控制台的Monitoring页面查看监控信息,或者查看实例的日志,获取问题的具体信息,并排查解决(例如索引占用内存太大,可删除一些索引)。
对于磁盘使用率过高导致集群异常的情况,建议参见集群磁盘使用率过高和read_only问题的排查与处理方法排查解决。
对于1核2 GB规格的实例,遇到实例状态不正常的问题时,建议先按照1:4(CPU:Mem)的规格升配集群,增大实例规格。升配后,如果状态依然异常,建议参见以上两种方案排查解决。
慢查询耗时分布
指标含义
您也可以单击自定义,选择开始时间和结束时间,单击确定,查看自定义时间段内的监控详情。
说明 Elasticsearch实例的监控报警默认为开启状态,因此您可以在集群监控页面查看历史监控数据。目前只保留30天内的监控信息,并且提供分钟粒度的数据。
集群的主要监控指标包含(实际以控制台为准):
集群状态(value)
集群写入QPS(Count/Second)
集群查询QPS(Count/Second)
节点CPU使用率(%)
节点磁盘使用率(%)
节点HeapMemory使用率(%)
节点load_1m(value)
FullGc次数(count)
Exception次数(count)
快照状态(value)
节点网络流入包(count)
节点网络流出包(count)
数据流入率(KB/s)
数据流出率(KB/s)
节点TCP链接数(count)
IOUtil(%)
每秒完成的读请求数量(count)
每秒钟读取的大小(MB/s)
每秒完成的写请求数量(count)
每秒钟写入的大小(MB/s)
集群状态(value)
指标含义
集群状态指标展示了集群的健康度,数值为0.00时表示正常。此监控指标必须配置,配置方法请参见配置集群告警。指标各数值的含义如下。
数值
颜色
状态
说明
2.00
红色
不是所有的主分片都可用。
表示该集群中某个或某几个索引的主分片丢失(unassigned)。
1.00
黄色
所有主分片可用,但不是所有副本分片都可用。
表示该集群中某个或某几个索引的副本分片丢失(unassigned)。
0.00
绿色
所有主分片和副本分片都可用。
表示该集群中的所有索引都很健康,不存在丢失(unassigned)的分片。
说明 表中的颜色是指在实例的基本信息页面所看到的集群状态的颜色。
指标异常原因
监控期间,当指标数值不为0.00时,表示集群状态异常,常见原因如下:
节点的CPU或HeapMemory使用率过高,甚至达到100%。
节点的磁盘使用率过高,例如超过85%,甚至达到100%。
节点的load_1m负载过高。
集群中索引的健康度出现过非健康(非绿色)状态。
异常处理建议
在Kibana控制台的Monitoring页面查看监控信息,或者查看实例的日志,获取问题的具体信息,并排查解决(例如索引占用内存太大,可删除一些索引)。
对于磁盘使用率过高导致集群异常的情况,建议参见集群磁盘使用率过高和read_only问题的排查与处理方法排查解决。
对于1核2 GB规格的实例,遇到实例状态不正常的问题时,建议先按照1:4(CPU:Mem)的规格升配集群,增大实例规格。升配后,如果状态依然异常,建议参见以上两种方案排查解决。
慢查询耗时分布
指标含义
慢查询耗时分布指标展示了集群在每500ms内,慢查询的数量分布。 例如:获取2021.10.15~2021.10.16区间内慢查询分布,0ms≤search_time_ms(慢查询耗时) |
【本文地址】
今日新闻 |
推荐新闻 |