Elasticsearch 底层数据结构 |
您所在的位置:网站首页 › es数据存储和原理 › Elasticsearch 底层数据结构 |
Elasticsearch 底层数据结构
|
Elasticsearch 底层数据结构 介绍最近组内做了个ES底层数据结构的分享,遂记录之。 基本概念Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements. Elasticsearch 是一个高可扩展、开源、全文本的搜索与数据分析引擎。它使您可以近实时地快速存储、搜索和分析大规模数据。它通常用作支持具有复杂搜索功能和要求的应用程序的底层引擎/技术。 Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档。Elasticsearch 不仅存储文档,而且 索引 每个文档的内容,使之可以被检索。在 Elasticsearch 中,我们对文档进行索引、检索、排序和过滤—而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。Elasticsearch 使用 JavaScript Object Notation(或者 JSON)作为文档的序列化格式。 下面这个 JSON 文档代表了一个 user 对象: { "name": "John", "age": 25, "sex": "Male", "info": { "bio": "Eco-warrior and defender of the weak", "tel": 18612344321, "interests": [ "dolphins", "whales" ] }, "join_date": "2014/05/01" }用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
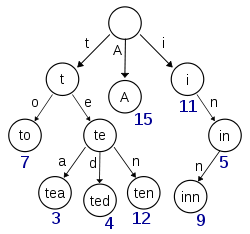
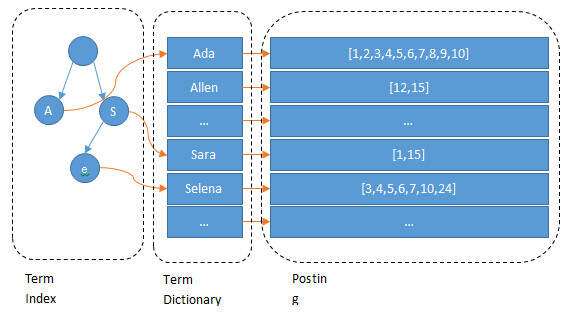
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。 倒排索引Elasticsearch最关键的就是提供强大的索引能力,为了提高搜索的性能,Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。 继续上面的例子,假设有这么几条数据(为了简单,去掉info, join_date这两个field: IDNameAgeSex 1 Kate 24 Female 2 John 24 Male 3 Bill 29 MaleID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下: Name: TermPosting List Kate 1 John 2 Bill 3Age: TermPosting List 24 [1, 2] 29 3Sex: TermPosting List Female 1 Male [2, 4]Posting list Elasticsearch分别为每个field都建立了一个倒排索引,一个字段有一个自己的倒排索引。Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。 那么什么是 term dictionary 和 term index? Term Dictionary 假设我们有很多个 term,比如: Carla,Sara,Elin,Ada,Patty,Kate,Selena 如果按照这样的顺序排列,找出某个特定的 term 一定很慢,因为 term 没有排序,需要全部过滤一遍才能找出特定的 term。排序之后就变成了: Ada,Carla,Elin,Kate,Patty,Sara,Selena 这样我们可以用二分查找的方式,比全遍历更快地找出目标的 term。这个就是 term dictionary。 有了 term dictionary 之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次 random access 大概需要 10ms 的时间)。所以为了尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。于是就有了 term index。 Term index term index 有点像一本字典的大的章节表。比如: A 开头的 term ……………. Xxx 页 C 开头的 term ……………. Xxx 页 E 开头的 term ……………. Xxx 页 如果所有的 term 都是英文字符的话,可能这个 term index 就真的是 26 个英文字符表构成的了。但是实际的情况是,term 未必都是英文字符,term 可以是任意的 byte 数组。而且 26 个英文字符也未必是每一个字符都有均等的 term,比如 x 字符开头的 term 可能一个都没有,而 s 开头的 term 又特别多。实际的 term index 是一棵 trie 树:
例子是一个包含 “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 的 trie 树。这棵树不会包含所有的 term,它包含的是 term 的一些前缀。通过 term index 可以快速地定位到 term dictionary 的某个 offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有 term 的尺寸的几十分之一,使得用内存缓存整个 term index 变成可能。 整体上来说就是这样的效果:
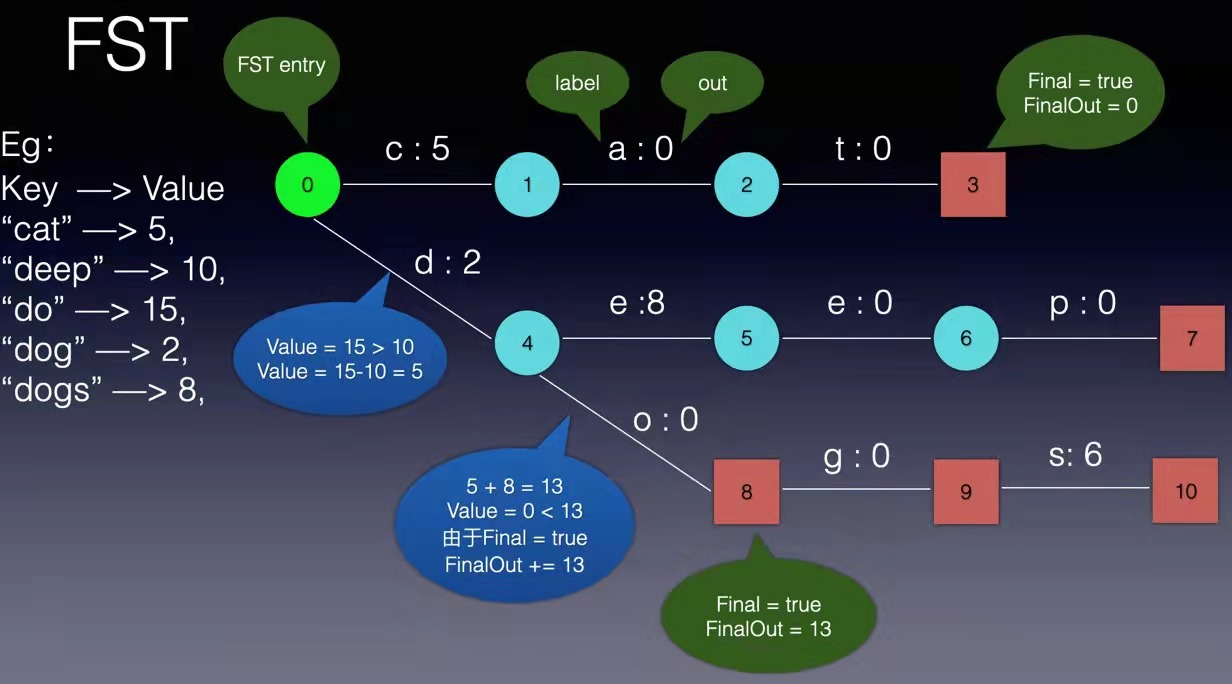
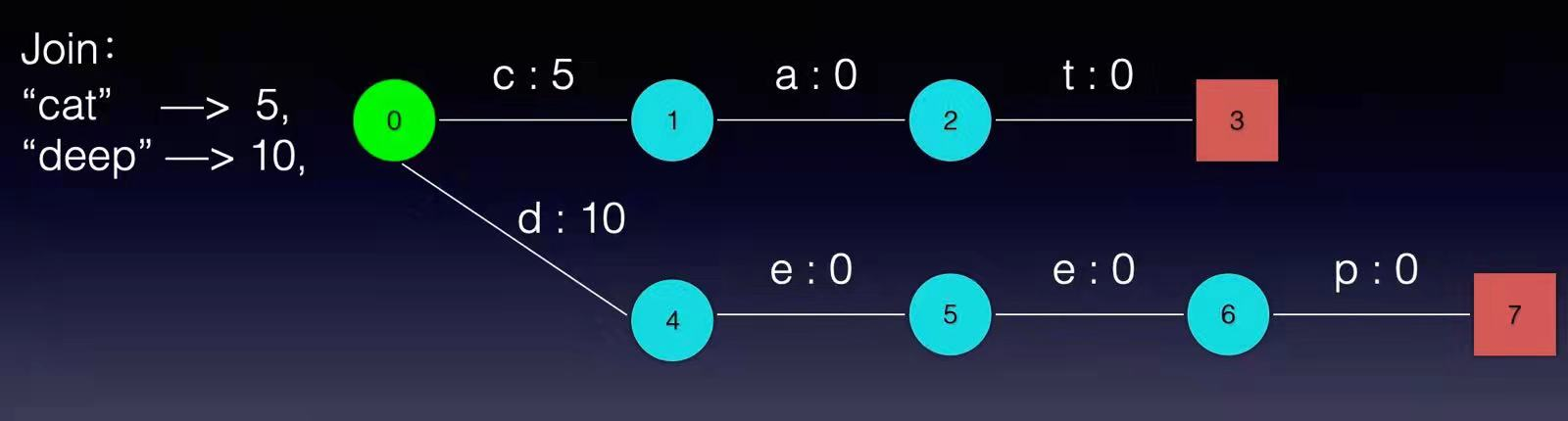
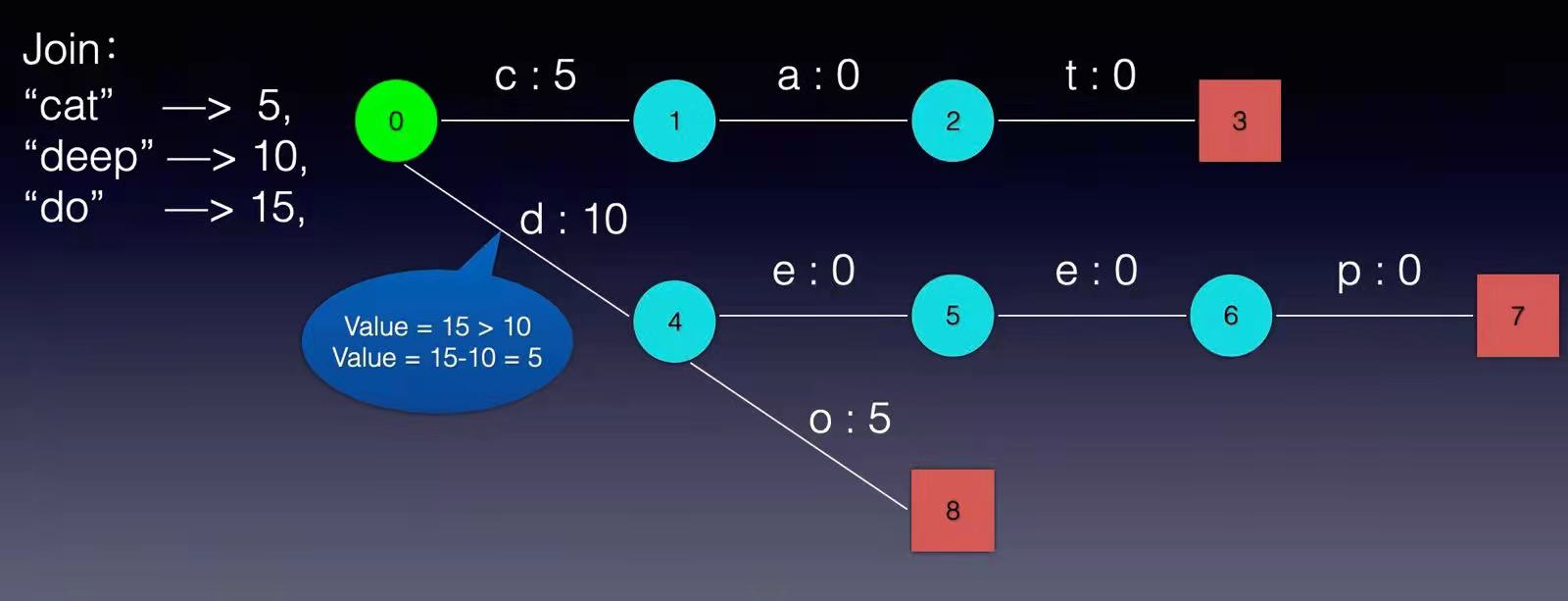
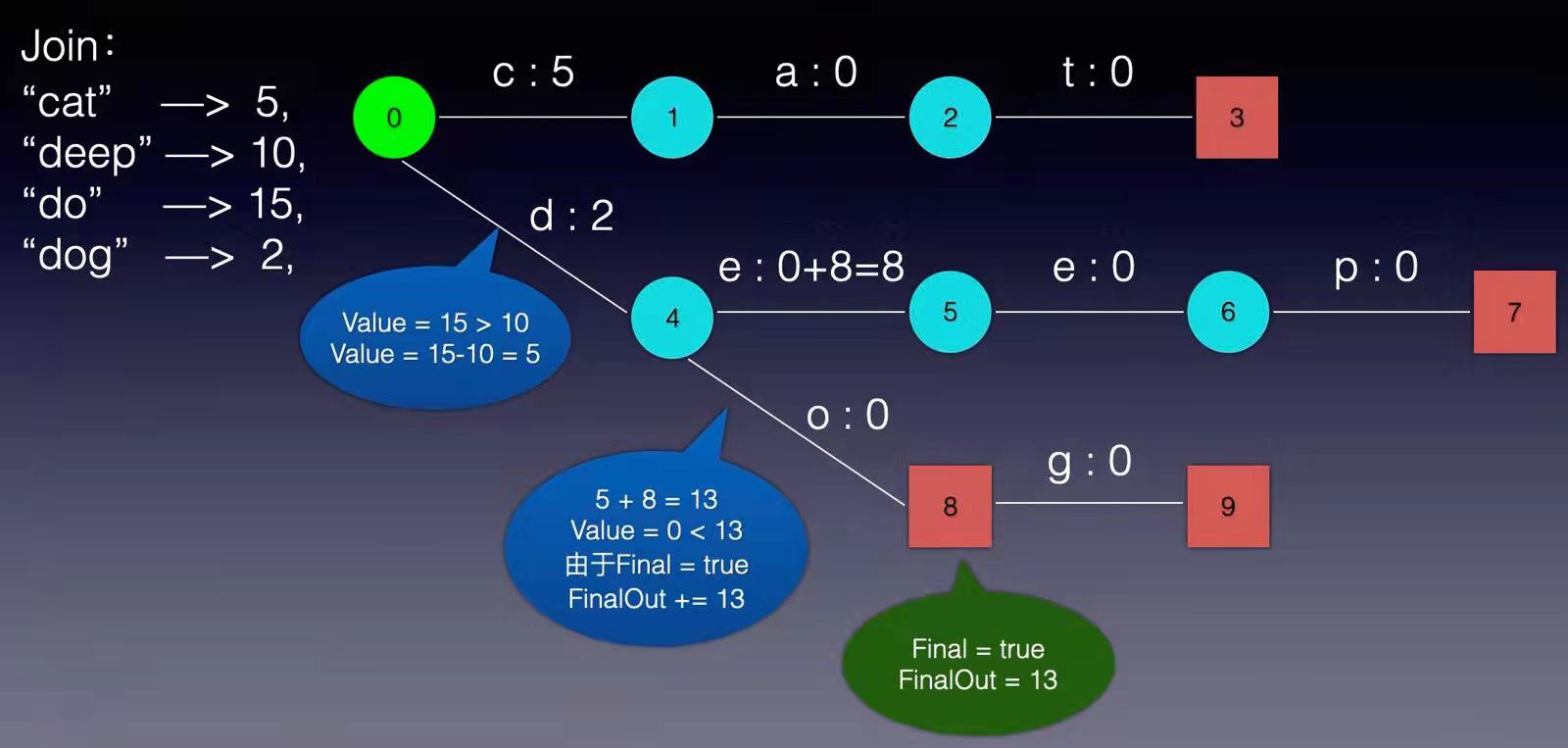
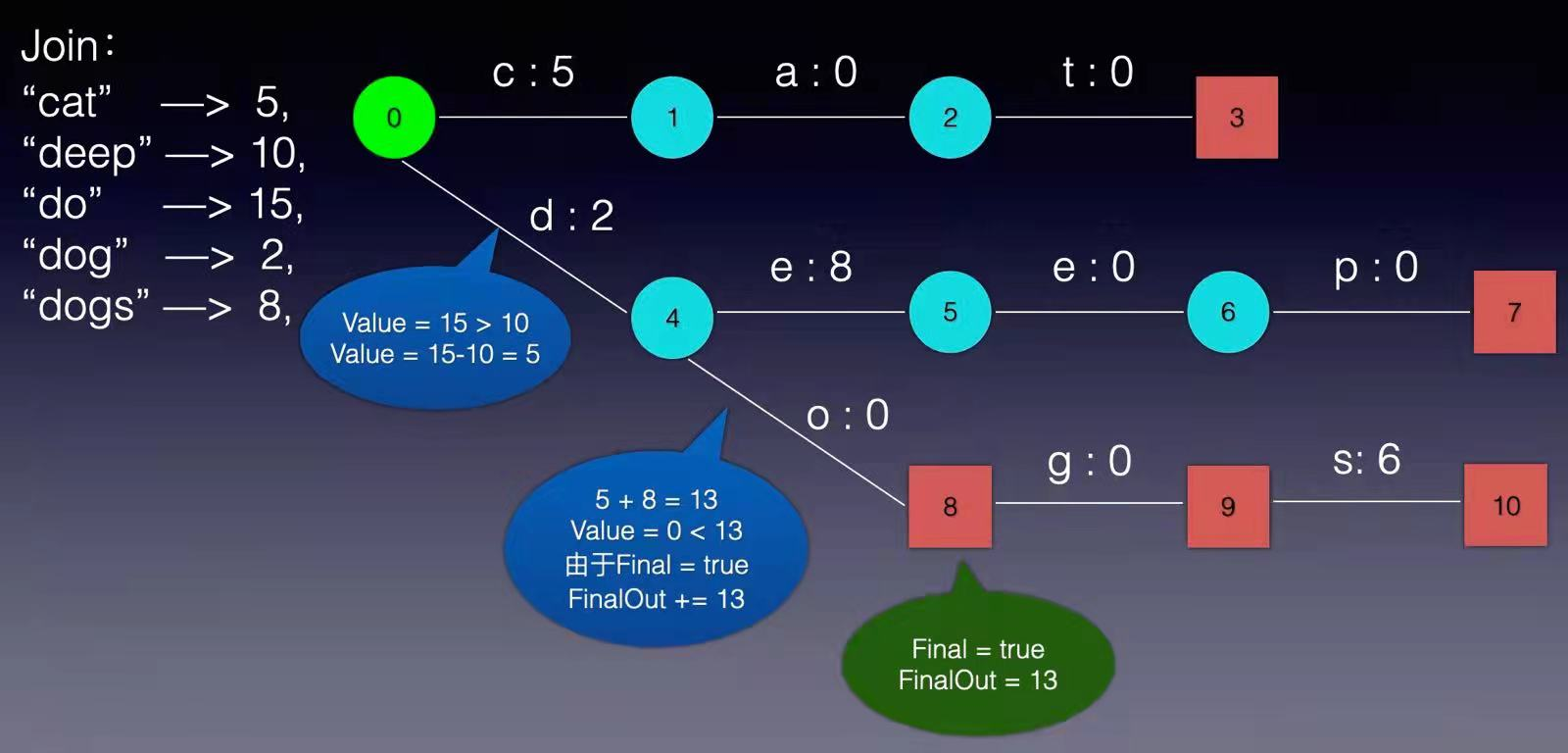
现在我们可以回答“为什么 Elasticsearch/Lucene 检索可以比 Mysql 快了。Mysql 只有 term dictionary 这一层,是以 b-tree 排序的方式存储在磁盘上的。检索一个 term 需要若干次的 random access 的磁盘操作。而 Lucene 在 term dictionary 的基础上添加了 term index 来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数。 term index 在内存中是以 FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary 在磁盘上是以分 block 的方式保存的,一个 block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样 term dictionary 可以比 b-tree 更节约磁盘空间。 Weighted Finite-State Transducer前面我们说到,term index 在内存中是以 FST(finite state transducers)的形式保存的,那到底FST是什么呢? FSM(Finite State Machines)有限状态机: 表示有限个状态(State)集合以及这些状态之间转移和动作的数学模型。其中一个状态被标记为开始状态,0个或更多的状态被标记为final状态。一个FSM同一时间只处于1个状态。 FST有两个优点: 1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间; 2)查询速度快。O(len(str))的查询时间复杂度。 下面简单描述下FST的构造过程(工具演示:http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it%21)。 我们假设创建以下一组映射:Key → Value “cat” - > 5, “deep” - > 10, “do” - > 15 “dog” - > 2, “dogs” - > 8,对于经典FST算法来说,要求Key必须按字典序从小到大加入到FST中,原因主要是因为在处理大数据的情况下,我们不太可能把整个FST数据结构都同时放在内存中,而是要边建图边将建好的图存储在外部文件中,以便节省内存。所以我们第一步要对所有的Key排序,对于我给这个例子来说,已经保证了字典序的顺序。 根据此例子的输入我们可以建立下图所示的FST:
从上图可以看出,每条边有两个属性,一个表示label(key的元素),另一个表示Value(out)。注意Value不一定是数字,还可一是另一个字符串,但要求Value必须满足叠加性,如这里的正整数2 + 8 = 10。字符串的叠加行为: aa + b = aab。 建完这个图之后,我们就可以很容易的查找出任意一个key的Value了。例如:查找dog,我们查找的路径为:0 → 4 → 8 → 9。 其权值和为: 2 + 0 + 0 + 0 = 2。其中最后一个零表示 node[9].finalOut = 0。所以“dog”的Value为2。 到这里,我们已经对FST有了一个感性的认识,下面我们详细讨论FST的建图过程: 1, 建一个空节点,表示FST的入口,所有的Key都从这个入口开始。 2, 如果还有未处理的Key,则枚举Key的每一个label。 处理流程如下: 如果当前节点存在含此label的边,则 如果Value包含该边的out值,则 Value = Value – out 否则 令temp=out–Value; out =Value并使下一个节点的所有边out都加上temp。 如果下一节点是Final节点 则FinalOut += temp 进入下一个节点 否则: 新建一个节点另其out = Value, Value = 0。如果你看不懂,没关系,我们将用例子演示一遍概算法:
之前我们介绍的都是对term进行压缩的方法,但是对于 posting list 也需要压缩。 比如说对于最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Frame Of Reference因此为了能够有效地计算交集和并集,我们需要对这些 posting list 进行排序。这个决定的一个很好的副作用是可以使用增量编码(delta-encoding)压缩 posting list. 例如,假设 posting list 是 [73, 300, 302, 332, 343, 372],则增量列表将是 [73, 227, 2, 30, 11, 29]。这里有趣的是,所有的增量都在 0 到 255 之间,所以每个值只需要一个字节。这是 Lucene 用于在磁盘上编码倒排索引的技术:posting list 被分成包含 256 个文档 ID 的块,然后使用增量编码和位打包(bit packing)分别压缩每个块:Lucene 计算最大位数需要在块中存储增量,将此信息添加到块头,然后使用此位数对块的所有增量进行编码。这种编码技术在文献中被称为Frame Of Reference (FOR),从 Lucene 4.1 开始使用。 这是一个块大小为 3(而不是实际中的 256)的示例:
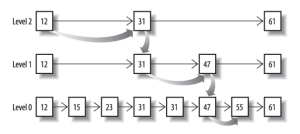
很多文章没有说清楚 bitmap 和 roaring bitmaps 跟 frame of reference 有什么区别,应用场景是什么,这里说明一下。 首先需要明白过滤情况(filtering context)和查询情况(query context)的区别。 Elasticsearch 使用的查询语言(DSL)拥有一套查询组件,这些组件可以以无限组合的方式进行搭配。这套组件可以在以下两种情况下使用:过滤情况(filtering context)和查询情况(query context)。 当使用于 过滤情况 时,查询被设置成一个“不评分”或者“过滤”查询。即,这个查询只是简单的问一个问题:“这篇文档是否匹配?”。回答也是非常的简单,yes 或者 no ,二者必居其一。 当使用于 查询情况 时,查询就变成了一个“评分”的查询。和不评分的查询类似,也要去判断这个文档是否匹配,同时它还需要判断这个文档匹配的有 多好(匹配程度如何)。 过滤查询(Filtering queries)只是简单的检查包含或者排除,这就使得计算起来非常快。考虑到至少有一个过滤查询(filtering query)的结果是 “稀少的”(很少匹配的文档),并且经常使用不评分查询(non-scoring queries),结果会被缓存到内存中以便快速读取,所以有各种各样的手段来优化查询结果。 相反,评分查询(scoring queries)不仅仅要找出匹配的文档,还要计算每个匹配文档的相关性,计算相关性使得它们比不评分查询费力的多。同时,查询结果并不缓存。 过滤(filtering)的目标是减少那些需要通过评分查询(scoring queries)进行检查的文档。 由于我们只缓存常用的过滤器,压缩率并不像倒排索引那么重要,倒排索引需要为每个可能的词条编码匹配文档。但是,我们需要缓存过滤器比重新执行过滤器更快,因此使用良好的数据结构很重要。 很长一段时间以来,Lucene 一直使用 bitmap 来将过滤器缓存到内存中。然而,在 Lucene 5 中,我们切换到 Daniel Lemire 的 roaring bitmaps。 综上,cached filters是保存在内存的,倒排索引是典型的保存在磁盘的。 BitmapBitmap是一种数据结构,假设有某个posting list: [1,3,4,7,10] 对应的bitmap就是: [1,0,1,1,0,0,1,0,0,1] 非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。 Bitmap的缺点是存储空间随着文档个数线性增长。 Roaring bitmaps它首先根据 16 个最高位将发布列表分成块。 这意味着,例如,第一个块将编码介于 0 和 65535 之间的值,第二个块将编码介于 65536 和 131071 之间的值,等等。然后在每个块中我们独立编码最低的 16 位:如果每块的个数少于 4096,将使用数组表示每个数字,否则使用bitmap。 在此阶段需要注意的重要一点是,虽然我们过去使用上述数组编码每个值需要 4 个字节,但这里的数组只需要为每个值存储 2 个字节,因为块 ID 隐含地为我们提供了 16 个最高位。 注意:如果一块超过了4096 个值,直接用bitset存,2个字节就用个简单的数组存放好了,比如short[]。 为什么它使用 4096 作为阈值? 仅仅因为这个块中的文档数量超过这个数,位图变得比数组更节省内存: 这就是 roaring bitmaps 有趣的原因:它们基于两种具有非常不同的压缩特性的快速编码技术,并根据内存效率动态决定使用哪种。 Roaring bit maps 有很多特性,但在 Lucene 的上下文中,真正让我们感兴趣的只有两个: 迭代所有匹配的文档。如果您在缓存过滤器上运行 constant_score 查询,则通常会使用它。 前进到集合中包含的第一个大于或等于给定整数的文档 ID。如果您将过滤器与查询相交,这通常会被使用。 联合索引所以给定查询过滤条件 age=18 的过程就是先从 term index 找到 18 在 term dictionary 的大概位置,然后再从 term dictionary 里精确地找到 18 这个 term,然后得到一个 posting list 或者一个指向 posting list 位置的指针。然后再查询 gender= 女 的过程也是类似的。最后得出 age=18 AND gender= 女 就是把两个 posting list 做一个“与”的合并。 这个理论上的“与”合并的操作可不容易。对于 mysql 来说,如果你给 age 和 gender 两个字段都建立了索引,查询的时候只会选择其中最 selective 的来用,然后另外一个条件是在遍历行的过程中在内存中计算之后过滤掉。那么要如何才能联合使用两个索引呢?有两种办法: 使用 skip list 数据结构。同时遍历 gender 和 age 的 posting list,互相 skip; 使用 bitset 数据结构,对 gender 和 age 两个 filter 分别求出 bitset,对两个 bitset 做 AN 操作。 PostgreSQL 从 8.4 版本开始支持通过 bitmap 联合使用两个索引,就是利用了 bitset 数据结构来做到的。当然一些商业的关系型数据库也支持类似的联合索引的功能。Elasticsearch 支持以上两种的联合索引方式,如果查询的 filter 缓存到了内存中(以 bitset 的形式),那么合并就是两个 bitset 的 AND。如果查询的 filter 没有缓存,那么就用 skip list 的方式去遍历两个 on disk 的 posting list。 Skip list跳跃表具有以下性质: 由多层有序链表组成。 最底层Level 1的链表包含所有的其他链表的元素。 如果一个元素在链表Level n中存在,那么他在Level n以下的所有链表中都存在。 每个节点都包含连个指针,分别指同Level链表的下一个元素和下一层的元素。
从概念上来说,对于一个很长的 posting list,比如: [1,3,13,101,105,108,255,256,257] 我们可以把这个 list 分成三个 block: [1,3,13] [101,105,108] [255,256,257] 然后可以构建出 skip list 的第二层: [1,101,255] 1,101,255 分别指向自己对应的 block。这样就可以很快地跨 block 的移动指向位置了。 Lucene 自然会对这个 block 再次进行压缩。其压缩方式就是之前介绍的 Frame Of Reference 编码。 利用 Bitset 合并Bitset 是一种很直观的数据结构,对应 posting list 如: [1,3,4,7,10] 对应的 bitset 就是: [1,0,1,1,0,0,1,0,0,1] 每个文档按照文档 id 排序对应其中的一个 bit。Bitset 自身就有压缩的特点,其用一个 byte 就可以代表 8 个文档。所以 100 万个文档只需要 12.5 万个 byte。但是考虑到文档可能有数十亿之多,在内存里保存 bitset 仍然是很奢侈的事情。而且对于个每一个 filter 都要消耗一个 bitset,比如 age=18 缓存起来的话是一个 bitset,18 |


【本文地址】