用python写网络爬虫 |
您所在的位置:网站首页 › elissa微博评论老e › 用python写网络爬虫 |
用python写网络爬虫
|
本文详细介绍了如何利用python实现微博评论的爬取,可以爬取指定微博下的评论。基于的策略是找到微博评论接口,先登录微博,获取cookies,使用requests库发送请求,并且将数据存储到.csv文件中。用到的库request, 首先微博的站点有四个,pc 端weibo.com、weibo.cn以及移动端m.weibo.com(无法在电脑上浏览)、https://m.weibo.cn。在网上大致浏览了一下,普遍都认为移动端爬取比较容易,故选择移动端https://m.weibo.cn进行爬取。
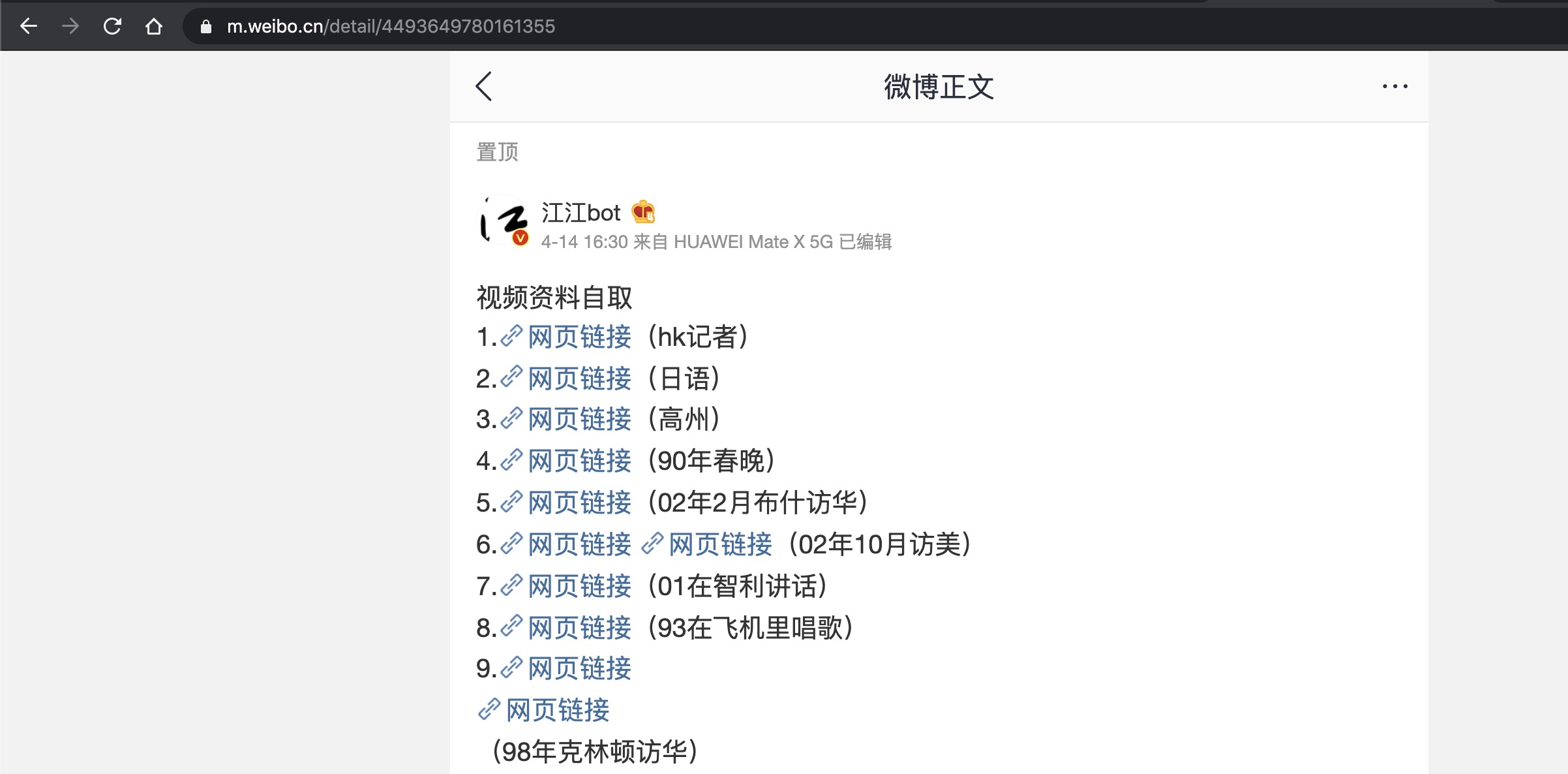
登陆m.weibo.cn之后,找到指定微博,例如如下微博https://m.weibo.cn/detail/4493649780161355:
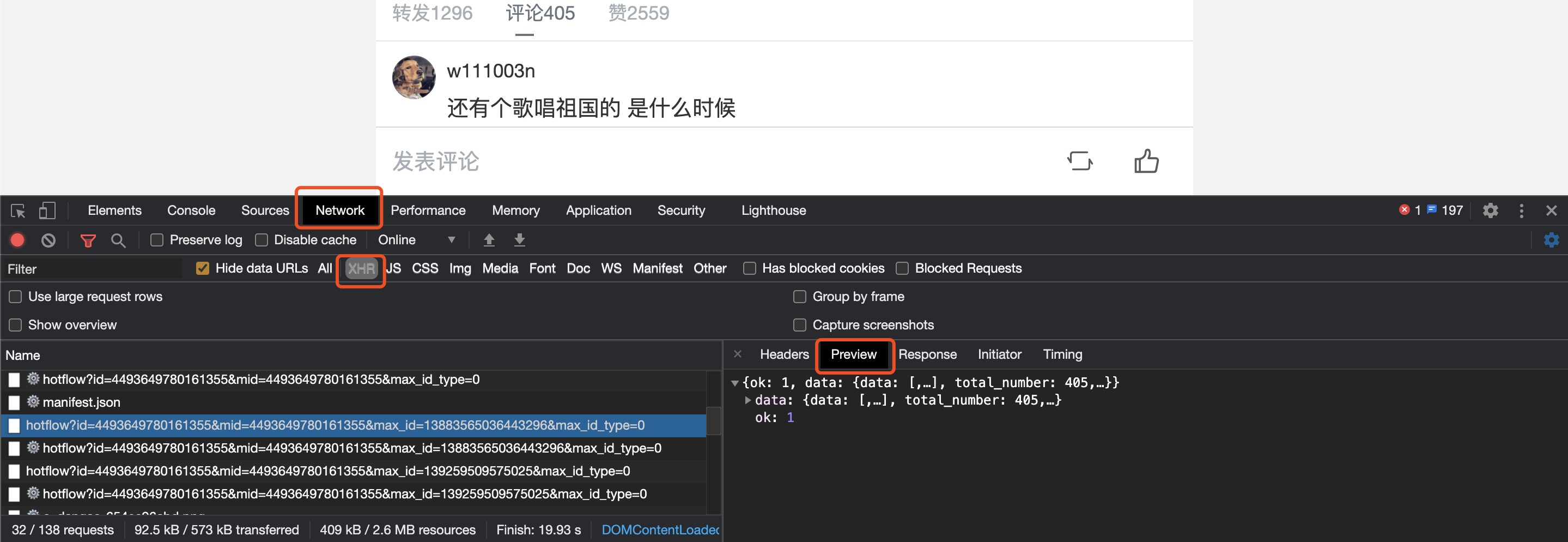
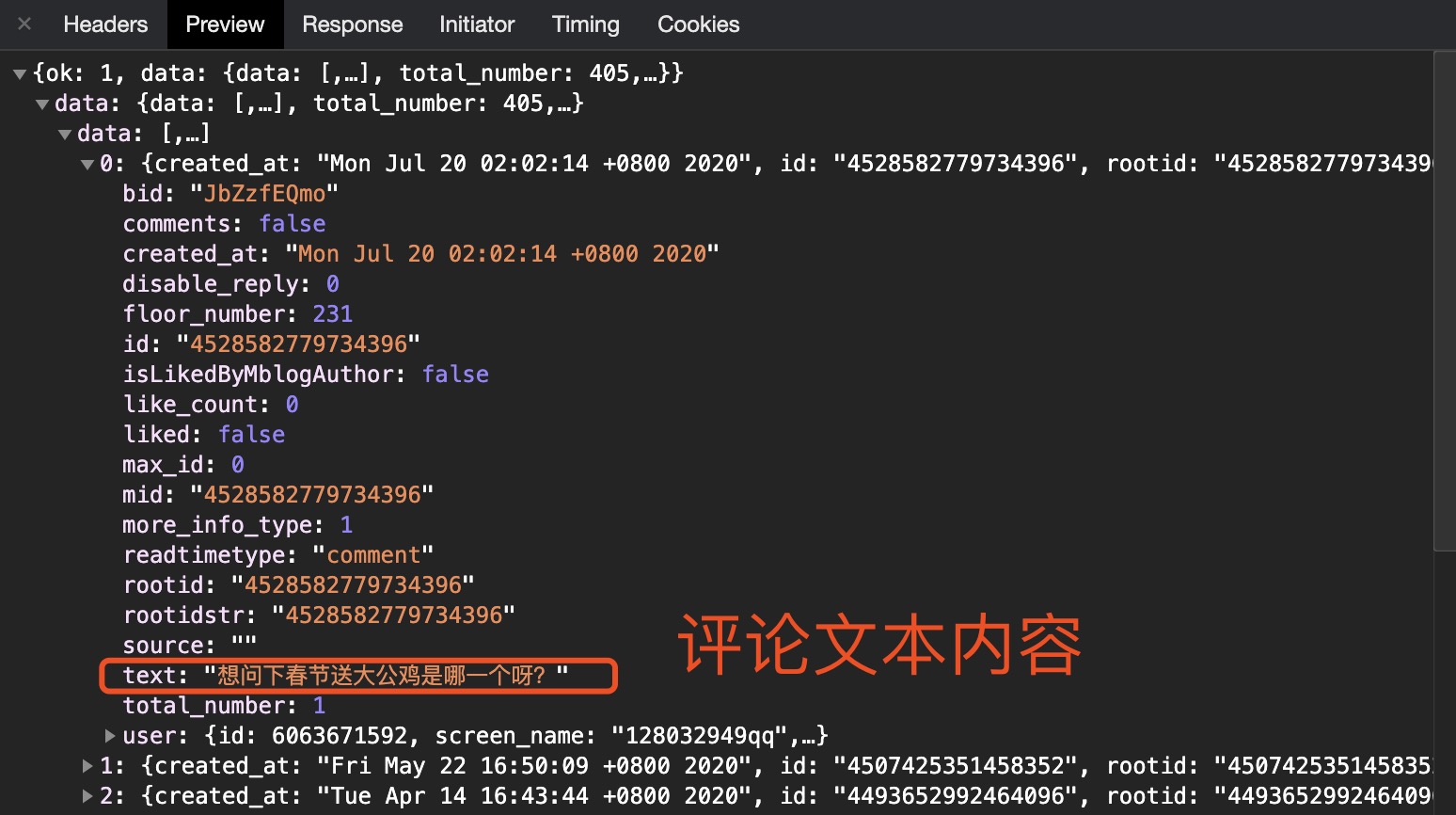
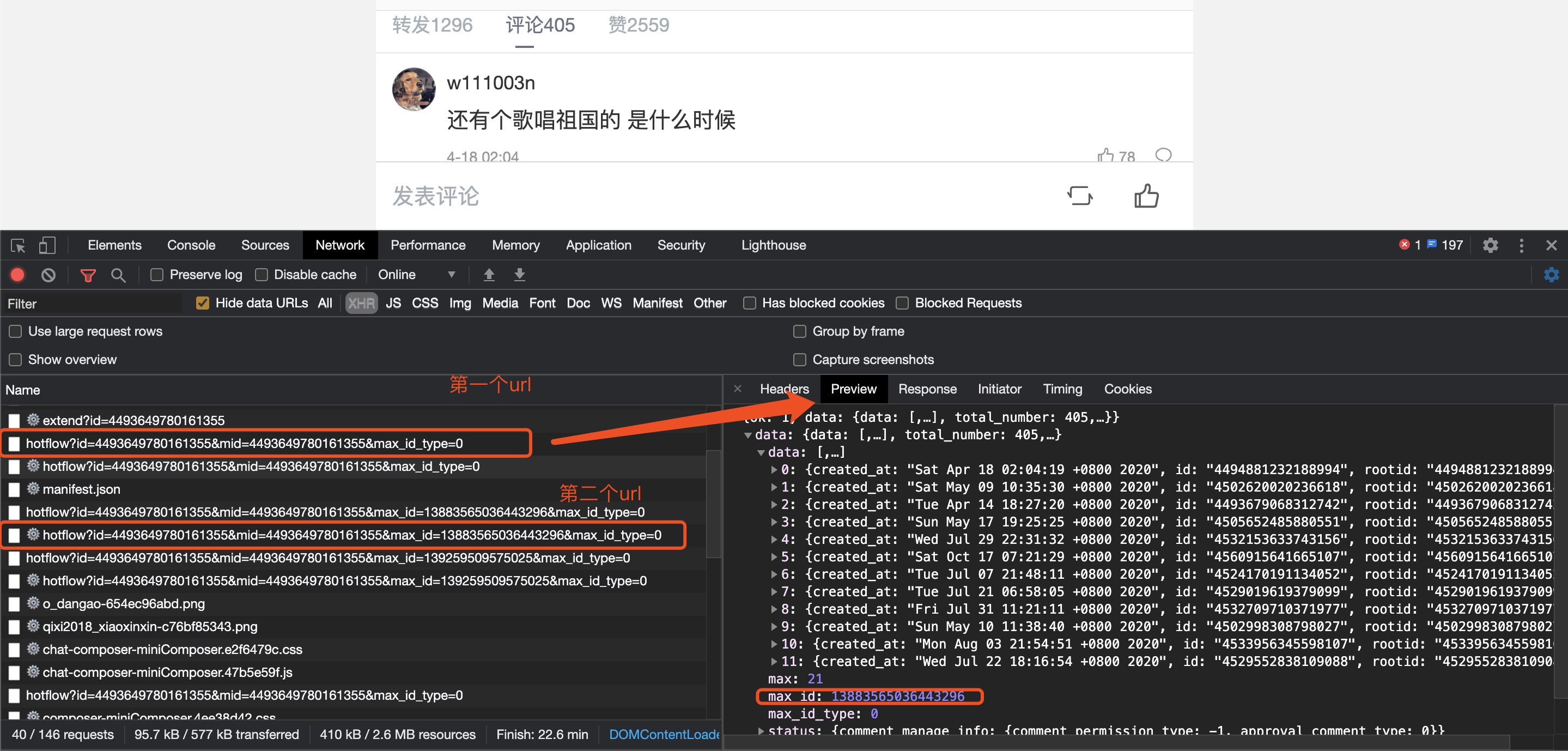
F12打开开发者模式,点击如下图选项,找到评论所在接口 找到接口以及文本内容之后,就是分析请求的url构造规律,找到第一个被请求数据的第一个url: https://m.weibo.cn/comments/hotflow?id=4493649780161355&mid=4493649780161355&max_id_type=0 下拉页面,找到第存在目标数据的二个类似的url: https://m.weibo.cn/comments/hotflow?id=4493649780161355&mid=4493649780161355&max_id=13883565036443296&max_id_type=0 第三个url: https://m.weibo.cn/comments/hotflow?id=4493649780161355&mid=4493649780161355&max_id=139259509575025&max_id_type=0 ... 比较之后我们发现url 的构造字段为https://m.weibo.cn/comments/hotflow? 后面跟上 id=value & mid=vlaue & max_id=value,其中id和mid的值经分析是不会改变的,第一条url中无max_id,往后max_id的值都会发生改变。接着我们在浏览器开发者模式中查看请求返回的数据,例如第一个url请求返回的数据其中就包含max_id 的值且等于第二个url中max_id 的值 因此我们可以使用一个递归函数,将回去的max_id的值返回,用于构造下一次请求的url, 代码如下: 1 import requests 2 import random 3 import time 4 import re 5 import json 6 import csv 7 8 start_url = 'https://m.weibo.cn/comments/hotflow?id=4493649780161355&mid=4493649780161355&max_id_type=0' # 首个url 9 next_url = '"https://m.weibo.cn/comments/hotflow?id=4493649780161355&mid=4493649780161355&max_id={}&max_id_type=0"' # 用于构造后面的url的模板 10 11 continue_url = start_url 12 13 headers = { 14 'cookie': '', # 传入你自己的cookie 15 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', 16 } 17 count = 0 18 19 fileHeader = ["id","评论时间","用户ID","昵称","评论楼层","评论内容"] 20 21 22 23 def get_data(url): 24 for trytime in range(3): # 允许超时次数为3次 25 try: 26 response = requests.get(url=url, headers=headers, timeout=5) 27 data = json.loads(response.text) 28 if response.status_code == 200: 29 break 30 except: 31 print('超时') 32 33 if trytime == 2: # 连续3次超时就退出递归 34 print('连续3次超时') 35 return 36 37 if data['ok'] == 0: # 若没有获取到数据也进行退出 38 print("获取到的数据data['ok']=", 0) 39 return 40 41 elif data['ok'] == 1: # 判断若能够获取到数据 则进行所需数据提取,并且构造下次请求的url,调用函数 42 max_id = data.get("data").get("max_id") 43 comments = data.get('data').get('data') 44 for item in comments: 45 ''' 获取内容creattime;floor——number;text;userid;screen——name;''' 46 global count 47 count += 1 48 create_time = item['created_at'] 49 floor_number = item['floor_number'] 50 text = ''.join(re.findall('[\u4e00-\u9fa5]', item['text'])) # 匹配文本内容 51 userid = item.get('user')['id'] 52 screen_name = item.get('user')['screen_name'] 53 54 # 将内容写入csv文件中 55 csv_opreator([count,create_time,userid,screen_name,floor_number,text]) 56 57 print([count, create_time, userid, screen_name, floor_number, text]) 58 print("第{}条数据获取成功".format(count)) 59 60 global next_url 61 continue_url = next_url.format(str(max_id)) 62 print(continue_url) 63 time.sleep(random.random()*5) 64 get_data(continue_url) # 调用函数本身 65 return 66 67 def csv_opreator(a): 68 69 with open("weibocoments.csv", "a") as f: 70 writer = csv.writer(f) 71 writer.writerow(a) 72 73 74 75 if __name__ == "__main__": 76 csv_opreator(fileHeader) 77 get_data(continue_url)
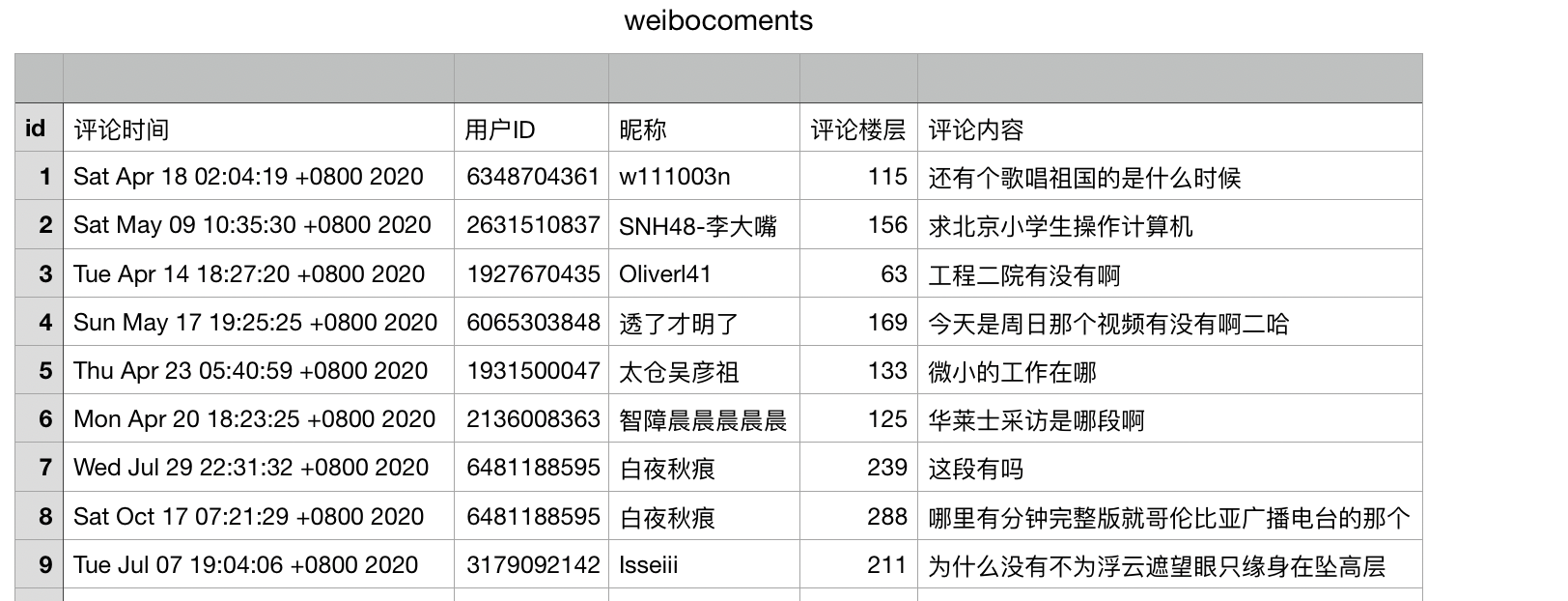
后台输出如下: csv文件结果如下:
可能遇到的问题,由于微博反爬,可先选择更换ip,或者重新登陆,将新的cookies复制进代码。
|

【本文地址】
今日新闻 |
推荐新闻 |