PHP 操作 ElasticSearch7.8.1 |
您所在的位置:网站首页 › elasticsearch中文文档pdf1005无标题 › PHP 操作 ElasticSearch7.8.1 |
PHP 操作 ElasticSearch7.8.1
|
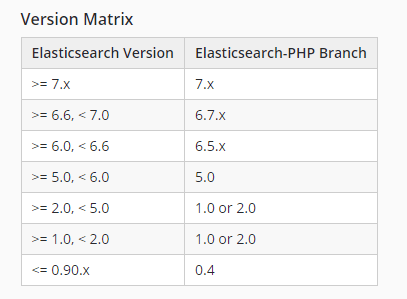
版本
PHP 操作 ElasticSearch 的索引,文档 PHP版本: 7.1.9 ElasticSearch版本:7.8.1ElasticSearch-PHP根据 PHP 版本选择对应的 ElasticSearch-PHP 版本 compose 安装 ElasticSearch-PHP composer require elasticsearch/elasticsearch创建 ElasticSearch 客户端 $params = [ 'host' => "127.0.0.1:9200" ]; //设置主机,并设置重连次数 $client = ClientBuilder::create()->setHosts($params)->setRetries(2)->build(); 使用 PHP 操作索引(增删改查) 创建索引创建一个 users 索引,并添加字段映射 $params = [ 'host' => "127.0.0.1:9200" ]; //设置主机,并设置重连次数 $client = ClientBuilder::create()->setHosts($params)->setRetries(2)->build(); $indexCreateParams = [ 'index' => 'users', //定义索引名字 'body' => [ 'settings' => [ 'number_of_shards' => 3, //设置索引分片数量 'number_of_replicas' => 2 //设置索引副本数量 ], 'mappings' => [ 'properties' => [ 'name' => [ 'type' => 'keyword', 'index' => true, //可以被索引 ], 'age' => [ 'type' => 'integer' ], 'mobile' => [ 'type' => 'text', 'index' => 'true', ], 'email' => [ 'type' => 'text', 'index' => 'true', ], 'address' => [ 'type' => 'text', 'index' => true, 'analyzer' => 'ik_max_word' //使用ik分词器进行分词 ], 'desc' => [ 'type' => 'text', 'index' => true, 'analyzer' => 'ik_max_word' ] ] ] ] ]; $res = $client->indices()->create($indexCreateParams); dd($res); 查看索引 //获取字段映射 $res = $client->indices()->getMapping([ 'index' => 'users' ]); dd($res); ------------------------------返回结果----------------------------------- array:1 [ "users" => array:1 [ "mappings" => array:1 [ "properties" => array:6 [ "address" => array:2 [ "type" => "text" "analyzer" => "ik_max_word" ] "age" => array:1 [ "type" => "integer" ] "desc" => array:2 [ "type" => "text" "analyzer" => "ik_max_word" ] "email" => array:1 [ "type" => "text" ] "mobile" => array:1 [ "type" => "text" ] "name" => array:1 [ "type" => "keyword" ] ] ] ] ]获取索引设置信息 //获取设置信息 $setting = $client->indices()->getSettings([ 'index' => 'users' ]); dd($setting); ---------------------------------返回结果------------------------------------ array:1 [ "users" => array:1 [ "settings" => array:1 [ "index" => array:6 [ "creation_date" => "1630484859730" "number_of_shards" => "3" "number_of_replicas" => "2" "uuid" => "IbvJ_CgtT3monuB8IyEPTQ" "version" => array:1 [ "created" => "7080199" ] "provided_name" => "users" ] ] ] ] 更改索引 $params = [ 'index' => 'users', 'body' => [ 'settings' => [ 'number_of_replicas' => 1,//更改索引的副本为 1 ] ] ]; $res = $client->indices()->putSettings($params); dd($res);ElasticSearch 是不支持索引字段类型变更的,原因是一个字段的类型进行修改之后,ES 会重新建立对这个字段的索引信息,影响到ES对该字段分词方式,相关度,TF/IDF倒排创建等 删除索引 $param = [ 'index' => 'users' ]; $res = $client->indices()->delete($param); dd($res); PHP 操作文档 创建一条数据的文档 $params = [ 'index' => 'users', 'id' => 1, //指定文档生成的id,如果不指定,则 es 自动生成 'body' => [ 'name' => '张三', 'age' => 21, 'mobile' => '16621111111', 'email' => "[email protected]", 'address' => '北京-西二旗', 'desc' => '一个技术宅男,强迫症,爱好美食,电影' ] ]; $res = $client->index($params); dd($res); -------------------------返回结果---------------------------- array:8 [ "_index" => "users" "_type" => "_doc" "_id" => "1" "_version" => 1 "result" => "created" "_shards" => array:3 [ "total" => 3 "successful" => 1 "failed" => 0 ] "_seq_no" => 0 "_primary_term" => 1 ] 创建多条数据的文档(bulk) $data = [ ['name' => '李四', 'age' => '22', 'mobile' => '16622222222','email' => '[email protected]', 'address' => '上海-闵行', 'desc' => '运动,动漫,游戏,电影'], ['name' => '王五', 'age' => '22', 'mobile' => '16622222223','email' => '[email protected]', 'address' => '上海-浦东', 'desc' => '运动,日漫,电影,技术控'], ['name' => '赵六', 'age' => '20', 'mobile' => '16622222224','email' => '[email protected]', 'address' => '上海-长宁', 'desc' => '宅男,小说,游戏,睡觉'], ['name' => '李华', 'age' => '23', 'mobile' => '16622222225','email' => '[email protected]', 'address' => '上海-宝山', 'desc' => '运动,小说,睡觉'], ]; foreach ($data as $k => $document) { $params['body'][] = [ 'index' => [ '_index' => 'users', '_id' => $k+1 ] ]; $params['body'][] = $document; } $res = $client->bulk($params); dd($res); 获取文档Elasticsearch 提供实时获取文档的方法。这意味着只要文档被索引且客户端收到消息确认后,你就可以立即在任何的分片中检索文档。Get 操作通过 index/type/id 方式请求一个文档信息: $params = [ 'index' => 'users', 'id' => 1 ]; $res = $client->get($params); dd($res); -------------------------------返回结果-------------------------------- array:8 [ "_index" => "users" "_type" => "_doc" "_id" => "1" "_version" => 2 "_seq_no" => 1 "_primary_term" => 1 "found" => true "_source" => array:6 [ "name" => "李四" "age" => "22" "mobile" => "16622222222" "email" => "[email protected]" "address" => "上海-闵行" "desc" => "运动,动漫,游戏,电影" ] ] 更改文档如果你要部分更新文档(如更改现存字段 或 添加新字段),你可以在 body 参数中指定一个 doc 参数。这样 doc 参数内的字段会与现存字段进行合并。 $params = [ 'index' => 'users', 'id' => 1, //对id为1的记录修改 'body' => [ 'doc' => [ 'age' => 19, //修改年龄为19 'mobile' => '16633333334' //修改手机号 ], ], ]; $res = $client->update($params); dd($res); ----------------------------再次查询id=1记录-------------------------------- array:8 [ "_index" => "users" "_type" => "_doc" "_id" => "1" "_version" => 4 "_seq_no" => 3 "_primary_term" => 1 "found" => true "_source" => array:6 [ "name" => "李四" "age" => 19 "mobile" => "16633333334" "email" => "[email protected]" "address" => "上海-闵行" "desc" => "运动,动漫,游戏,电影" ] ] 删除文档可以通过id进行删除 $params = [ 'index' => 'users', 'id' => 1, ]; $res = $client->delete($params); dd($res); 搜索查询 获取所有数据 $params = [ 'index' => 'users', ]; $res = $client->search($params); dd($res); --------------------------------返回结果------------------------------- array:4 [ "took" => 0 //查询花费时间,单位毫秒 "timed_out" => false //是否超时 "_shards" => array:4 [ //分片信息 "total" => 3 //分片总数 "successful" => 3 //成功 "skipped" => 0 //忽略 "failed" => 0 //失败 ] "hits" => array:3 [ //搜索命中结果 "total" => array:2 [ //搜索条件匹配的文档总数 "value" => 3 //总命中计数的值 "relation" => "eq" //计数规则 eq 标识计数准确,gte 标识计数不准确 ] "max_score" => 1.0 //匹配度分支 "hits" => array:3 [ //命中结果集合 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 1.0 "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" ] ] 1 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "3" "_score" => 1.0 "_source" => array:6 [ "name" => "赵六" "age" => "20" "mobile" => "16622222224" "email" => "[email protected]" "address" => "上海-长宁" "desc" => "宅男,小说,游戏,睡觉" ] ] 2 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 1.0 "_source" => array:6 [ "name" => "李华" "age" => "23" "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" ] ] ] ] ] 匹配查询match 匹配类型查询,Es 先把查询条件进行分词,然后依据分词进行查询,多个词条之间是 or 的关系 $params = [ 'index' => 'users', 'body' => [ 'query' => [ //match 会先把查询条件进行分词 'match' => [ //desc 的类型是text,进行分词查询,所以查询的时候会先分词成 运动,电影,技术控等词组,然后依据词组进行匹配 'desc' => '运动,日漫,电影,技术控' ] ] ] ]; $res = $client->search($params); dd($res); --------------------------返回结果---------------------------- array:4 [ "took" => 3 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 2 "relation" => "eq" ] "max_score" => 4.811739 "hits" => array:2 [ 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 4.811739 "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" //es在存储的时候会进行分词,此次查询匹配上了运动这个词组 ] ] 1 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 0.5504225 "_source" => array:6 [ "name" => "李华" "age" => "23" "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" ] ] ] ] ] 精准查找 term 查询,精确的关键词匹配查询,不对查询条件进行分词 $params = [ 'index' => 'users', 'body' => [ 'query' => [ 'term' => [ //不会对 运动 进行分词操作,而是直接使用 运动 进行匹配查找 'desc' => '运动' ] ] ] ]; $res = $client->search($params); dd($res); --------------------------------结果--------------------------------- array:4 [ "took" => 0 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 2 "relation" => "eq" ] "max_score" => 0.5504225 "hits" => array:2 [ 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 0.5504225 "_source" => array:6 [ "name" => "李华" "age" => "23" "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" //es存储的倒排索引中有运动这个分词词组,所以可以匹配上 ] ] 1 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 0.42081726 "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" ] ] ] ] ] 多关键字精确查询terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于 mysql 的 in $params = [ 'index' => 'users', 'body' => [ 'query' => [ 'terms' => [ //不会对 运动 进行分词操作,而是直接使用 运动 进行匹配查找 'desc' => ['运动', '游戏'] ] ] ] ]; $res = $client->search($params); dd($res); ---------------------------------结果----------------------------- array:4 [ "took" => 2 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 3 "relation" => "eq" ] "max_score" => 1.0 "hits" => array:3 [ 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 1.0 "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" //包含 运动 ] ] 1 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "3" "_score" => 1.0 "_source" => array:6 [ "name" => "赵六" "age" => "20" "mobile" => "16622222224" "email" => "[email protected]" "address" => "上海-长宁" "desc" => "宅男,小说,游戏,睡觉" //包含 游戏 ] ] 2 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 1.0 "_source" => array:6 [ "name" => "李华" "age" => "23" "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" //包含 运动 ] ] ] ] ] 组合查询bool把各种其它查询通过must(必须 )、must_not(必须不)、should(应该)的方式进行组合 语句 情况 多个 must 查询 must 的交集 must + should 查询 must 交集,如果交集里面包含 should 的部分,则增加打分 must + must_not 查询 must 交集,但是会排除 must_not 条件 多个 should 查询 should 的并集,也就是 a = 1 or a = 2 should + must_not should 的并集,并排除 must_not 的部分 must + must_not + should must 交集,并排除 must_not 部分,返回结果里面有 should 部分,会增加打分 //查询 desc 包含 小说,运动的词组,但是排除年龄是20的,排除之后的结果集中如果名字 = 李华,则增加 _score 分数 $params = [ 'index' => 'users', 'body' => [ 'query' => [ 'bool' => [ 'must' => [ [ 'match' => [ 'desc' => '小说' ] ], [ 'term' => [ 'desc' => '运动' ] ] ], 'must_not' => [ [ 'term' => [ 'age' => '20' ] ] ], 'should' => [ [ 'term' => [ 'name' => '李华' ] ] ] ] ] ] ]; $res = $client->search($params); dd($res); ------------------------------------返回结果--------------------------------- array:4 [ "took" => 8 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 1 "relation" => "eq" ] "max_score" => 2.081674 "hits" => array:1 [ 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 2.081674 //没有加 should 的分数 = 1.100845,加完 should 分值直接提高 1 "_source" => array:6 [ "name" => "李华" "age" => "23" //年龄不等于20 "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" //包含小说,运动 词组 ] ] ] ] ] 返回指定字段默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在 _source 的所有字段都返回。如果我们只想获取其中的部分字段,我们可以添加_source 的过滤 $params = [ 'index' => 'users', '_source' => ['name', 'desc'], //只返回 _source 保存的 name,desc 字段 'body' => [ 'query' => [ 'terms' => [ //不会对 运动 进行分词操作,而是直接使用 运动 进行匹配查找 'desc' => ['运动', '游戏'] ] ] ] ]; $res = $client->search($params); dd($res); ------------------------------------结果----------------------------------- array:4 [ "took" => 0 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 3 "relation" => "eq" ] "max_score" => 1.0 "hits" => array:3 [ 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 1.0 "_source" => array:2 [ "name" => "王五" "desc" => "运动,日漫,电影,技术控" ] ] 1 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "3" "_score" => 1.0 "_source" => array:2 [ "name" => "赵六" "desc" => "宅男,小说,游戏,睡觉" ] ] 2 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 1.0 "_source" => array:2 [ "name" => "李华" "desc" => "运动,小说,睡觉" ] ] ] ] ] 范围查找range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符 符号 说明 gt > gte >= lt [ 'query' => [ 'range' => [ 'age' => [ 'gt' => 20, 'lt' => 30 ] ] ] ] ]; $res = $client->search($params); dd($res); ----------------------------------结果--------------------------------- array:4 [ "took" => 0 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 2 "relation" => "eq" ] "max_score" => 1.0 "hits" => array:2 [ 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 1.0 "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" ] ] 1 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 1.0 "_source" => array:6 [ "name" => "李华" "age" => "23" "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" ] ] ] ] ] 排序sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式。desc 降序,asc升序。 根据年龄进行排序 $params = [ 'index' => 'users', 'body' => [ 'query' => [ 'match' => [ 'desc' => '运动,小说' ] ], 'sort' => [ [ 'age' => [ 'order' => 'desc' ] ] ] ], ]; ----------------------------------------结果-------------------------------- array:4 [ "took" => 9 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 3 "relation" => "eq" ] "max_score" => null "hits" => array:3 [ 0 => array:6 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => null "_source" => array:6 [ "name" => "李华" "age" => "23" "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" ] "sort" => array:1 [ 0 => 23 ] ] 1 => array:6 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => null "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" ] "sort" => array:1 [ 0 => 22 ] ] 2 => array:6 [ "_index" => "users" "_type" => "_doc" "_id" => "3" "_score" => null "_source" => array:6 [ "name" => "赵六" "age" => "20" "mobile" => "16622222224" "email" => "[email protected]" "address" => "上海-长宁" "desc" => "宅男,小说,游戏,睡觉" ] "sort" => array:1 [ 0 => 20 ] ] ] ] ] 多个字段排序,先根据年龄进行排序,如果年龄相等,在根据 _score 分数排序 $params = [ 'index' => 'users', 'body' => [ 'query' => [ 'match' => [ 'desc' => '运动,小说' ] ], 'sort' => [ [ 'age' => [ 'order' => 'desc' ] ], [ '_score' => [ 'order' => "desc" ] ] ] ], ]; $res = $client->search($params); dd($res); --------------------------------结果------------------------------------- array:4 [ "took" => 1 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 4 "relation" => "eq" ] "max_score" => null "hits" => array:4 [ 0 => array:6 [ "_index" => "users" "_type" => "_doc" "_id" => "4" "_score" => 1.100845 "_source" => array:6 [ "name" => "李华" "age" => "23" "mobile" => "16622222225" "email" => "[email protected]" "address" => "上海-宝山" "desc" => "运动,小说,睡觉" ] "sort" => array:2 [ 0 => 23 1 => 1.100845 ] ] 1 => array:6 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 0.42081726 //和韩梅梅的年龄相等,依据 分数进行排序 "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" ] "sort" => array:2 [ 0 => 22 1 => 0.42081726 ] ] 2 => array:6 [ "_index" => "users" "_type" => "_doc" "_id" => "1" "_score" => 0.2876821 "_source" => array:6 [ "name" => "韩梅梅" "age" => "22" "mobile" => "16622222278" "email" => "[email protected]" "address" => "上海-闵行" "desc" => "运动,美食,游戏,电影" ] "sort" => array:2 [ 0 => 22 1 => 0.2876821 ] ] 3 => array:6 [ "_index" => "users" "_type" => "_doc" "_id" => "3" "_score" => 0.45665967 "_source" => array:6 [ "name" => "赵六" "age" => "20" "mobile" => "16622222224" "email" => "[email protected]" "address" => "上海-长宁" "desc" => "宅男,小说,游戏,睡觉" ] "sort" => array:2 [ 0 => 20 1 => 0.45665967 ] ] ] ] ] 分页查询from:当前页的起始索引,默认从 0 开始。 from = (pageNum - 1) * sizesize:每页显示多少条 $params = [ 'index' => 'users', 'body' => [ 'from' => 0, //从0开始 'size' => 1 //查询1条数据 ], ]; $res = $client->search($params); dd($res); ---------------------------结果--------------------------------------- array:4 [ "took" => 7 "timed_out" => false "_shards" => array:4 [ "total" => 3 "successful" => 3 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 4 "relation" => "eq" ] "max_score" => 1.0 "hits" => array:1 [ 0 => array:5 [ "_index" => "users" "_type" => "_doc" "_id" => "2" "_score" => 1.0 "_source" => array:6 [ "name" => "王五" "age" => "22" "mobile" => "16622222223" "email" => "[email protected]" "address" => "上海-浦东" "desc" => "运动,日漫,电影,技术控" ] ] ] ] ] PHP 聚合操作ElasticSearch除了致力于搜索之外,也提供了聚合实时分析数据的功能,它的实时性高,所有的计算结果都是即时返回。聚合的两个主要的概念,分别是 桶 和 指标 桶(Buckets): 简单来说就是满足特定条件的文档的集合。类似SQL中的GROUP BY语法 当聚合开始被执行,每个文档会决定符合哪个桶的条件,如果匹配到,文档将放入相应的桶并接着进行聚合操作 桶可以被嵌套在其他桶里面,像是北京能放在中国桶裡,而中国桶能放在亚洲桶裡 指标(Metrics) : 对桶内的文档进行统计计算(如计算最大值、最小值、平均值等等) 桶能让我们划分文档到有意义的集合, 但是最终我们需要的是对这些桶内的文档进行一些指标的计算指标通常是简单的数学运算(像是min、max、avg、sum),而这些是通过当前桶中的文档的值来计算的,利用指标能让你计算像平均薪资、最高出售价格、95%的查询延迟这样的数据 PHP 中聚合的格式大致为: $params = [ 'index' => 'employees', 'body' => [ //查询 age 最大的是多少岁 'aggs' => [ //es 聚合操作关键字 aggs 或者 aggregations 都可以 'age_max' => [ //es 返回的字段名称,自己随意定义 "max" => [ // 聚合的类型,关键词 'field' => 'age' //对哪个字段进行聚合 ] ] ], ], ];创建案列数据 创建 employees 索引 $indexCreateParams = [ 'index' => 'employees', //创建一个员工表 'body' => [ 'mappings' => [ 'properties' => [ 'name' => [ 'type' => 'keyword' ], 'age' => [ 'type' => 'integer' ], 'gender' => [ 'type' => 'keyword' ], 'job' => [ 'type' => 'text', 'fields' => [ //设置字段能关键词搜索及数据聚合. 'keyword' => [ 'type' => 'keyword', 'ignore_above' => 50 ] ] ], 'salary' => [ 'type' => 'integer' ] ] ] ] ]; $res = $client->indices()->create($indexCreateParams); dd($res);添加文档数据 $data = [ ['name' => '张三', 'age' => 20, 'gender' => '男', 'job' => 'PHP', 'salary' => '1000'], ['name' => '李四', 'age' => 25, 'gender' => '男', 'job' => 'PHP', 'salary' => '2500'], ['name' => '王五', 'age' => 26, 'gender' => '男', 'job' => 'PHP', 'salary' => '2600'], ['name' => '赵六', 'age' => 29, 'gender' => '男', 'job' => 'PHP', 'salary' => '4500'], ['name' => '韩梅梅', 'age' => 24, 'gender' => '女', 'job' => 'UI', 'salary' => '3500'], ['name' => '李华', 'age' => 27, 'gender' => '男', 'job' => '产品', 'salary' => '3600'], ['name' => '李锐', 'age' => 25, 'gender' => '男', 'job' => '产品', 'salary' => '2800'], ['name' => '赵云', 'age' => 28, 'gender' => '男', 'job' => '产品', 'salary' => '5000'], ['name' => '李雷', 'age' => 27, 'gender' => '男', 'job' => '测试', 'salary' => '3600'], ['name' => '李想', 'age' => 23, 'gender' => '男', 'job' => '测试', 'salary' => '2500'], ['name' => '赵雷', 'age' => 30, 'gender' => '男', 'job' => 'PHP', 'salary' => '5500'], ['name' => '张宇', 'age' => 27, 'gender' => '男', 'job' => 'JAVA', 'salary' => '4600'], ['name' => '杨建', 'age' => 24, 'gender' => '男', 'job' => 'JAVA', 'salary' => '3500'], ]; foreach ($data as $k => $document) { $params['body'][] = [ 'index' => [ '_index' => 'employees', '_id' => $k+1 ] ]; $params['body'][] = $document; } $res = $client->bulk($params); dd($res); avg 平均值计算员工的平均薪资 //查询员工平均工资 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'avg_salary' => [ 'avg' => [ 'field' => 'salary' ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); ----------------------------------返回结果------------------------------- array:5 [ "took" => 14 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "avg_salary" => array:1 [ "value" => 3476.9230769231 ] ] ] min,max 最大,最小 //查询员工最高或最低的工资 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'max_salary' => [ 'max' => [ 'field' => 'salary' ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); ----------------------------------结果-------------------------------- array:5 [ "took" => 3 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "max_salary" => array:1 [ "value" => 5500.0 ] ] ] sum 求和 //查询员工总的薪资 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'sum_salary' => [ 'sum' => [ 'field' => 'salary' ] ] ], 'size' => 0, ], ]; ----------------------------------结果--------------------------------- array:5 [ "took" => 2 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "sum_salary" => array:1 [ "value" => 45200.0 ] ] ] cardinality 去重cardinality 计算不重复的字段有多少(相当于mysql中的distinct) //cardinality 去重操作,然后在进行统计,统计工种数量 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'cardinality_info' => [ 'cardinality' => [ 'field' => 'job.keyword' ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); ------------------------------------结果--------------------------------- array:5 [ "took" => 1009 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "cardinality_info" => array:1 [ "value" => 5 ] ] ] status 计算各种聚合通过 status,可以同时返回 count,max,min,sum,avg 的结果 //计算 salary 的总数,最小,最大,平均,总和 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'salary_stats' => [ 'stats' => [ 'field' => 'salary' ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); -------------------------------------结果----------------------------------- array:5 [ "took" => 1 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "salary_stats" => array:5 [ "count" => 13 "min" => 1000.0 "max" => 5500.0 "avg" => 3476.9230769231 "sum" => 45200.0 ] ] ] percentiles 百分比统计对指定字段的值按从小到大累计每个值对应的文档数的占比,返回 指定占比比例对应的值。 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'percentiles' => [ 'percentiles' => [ 'field' => 'salary' ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); ------------------------------结果-------------------------------------- array:5 [ "took" => 2 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "percentiles" => array:1 [ "values" => array:7 [ "1.0" => 1000.0 "5.0" => 1225.0 "25.0" => 2575.0 "50.0" => 3500.0 "75.0" => 4525.0 "95.0" => 5425.0 "99.0" => 5500.0 ] ] ] ]上面的查询可以理解为 1% 的人薪资在1000以下,5% 的人薪资在1225 以下…… 薪资范围 占比 0 ~ 1000 1% 0 ~ 1225.0 5% 0 ~ 2575.0 25% 0 ~ 3500.0 50% 0 ~ 4525.0 75% 0 ~ 5425.0 95% 0 ~ 5500.0 99%默认返回的是 1,5,25,50,75,95,99 对应的文档的值,可以使用 percents 指定某一处的分值 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'percentiles' => [ 'percentiles' => [ 'field' => 'salary', "percents" => [46, 70, 80] //获取占比 46 的薪资范围 ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); ---------------------------结果------------------------------------ array:5 [ "took" => 10 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "percentiles" => array:1 [ "values" => array:3 [ "46.0" => 3500.0 "70.0" => 4140.0 "80.0" => 4590.0 ] ] ] ] percentile_ranks使用 percentile_ranks 可以翻过来,计算某一值在总数中的占比 统计年龄小于25和年龄小于30的文档的占比 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'percentile_ranks_example' => [ 'percentile_ranks' => [ 'field' => 'age', "values" => [22,25] //获取年龄小于22 岁,小于25岁的占比 ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); -------------------------------返回结果-------------------------------- array:5 [ "took" => 9 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "percentile_ranks_example" => array:1 [ "values" => array:2 [ "22.0" => 9.6153846153846 "25.0" => 38.461538461538 ] ] ] ] top_hits 取分桶后的前n条获取到每组前n条数据,相当于sql 中Top(group by 后取出前n条)。 //按照工作进行分组,在对分组后的文档按照年龄进行升序,然后通过top_hits取每组的第一条 $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'job_info' => [ //自己随意起名 'terms' => [ //这里的 terms 表示对 job进行分组,相当于 (group by job) 'field' => 'job.keyword', ], //对 job 的分组数据执行一下操作 'aggs' => [ 'top_job' => [ 'top_hits' => [ 'sort' => [ //对分组数据进行年龄的升序 [ 'age' => [ 'order' => 'desc' ] ] ], "size" => 1 //取每组的一条数据 ] ] ] ], ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); ---------------------------------结果------------------------------------- array:5 [ "took" => 15 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "job_info" => array:3 [ "doc_count_error_upper_bound" => 0 "sum_other_doc_count" => 0 "buckets" => array:5 [ 0 => array:3 [ "key" => "PHP" "doc_count" => 5 "top_job" => array:1 [ "hits" => array:3 [ "total" => array:2 [ "value" => 5 "relation" => "eq" ] "max_score" => null "hits" => array:1 [ 0 => array:6 [ "_index" => "employees" "_type" => "_doc" "_id" => "11" "_score" => null "_source" => array:5 [ "name" => "赵雷" "age" => 30 "gender" => "男" "job" => "PHP" "salary" => "5500" ] "sort" => array:1 [ 0 => 30 ] ] ] ] ] ] 1 => array:3 [ "key" => "产品" "doc_count" => 3 "top_job" => array:1 [ "hits" => array:3 [ "total" => array:2 [ "value" => 3 "relation" => "eq" ] "max_score" => null "hits" => array:1 [ 0 => array:6 [ "_index" => "employees" "_type" => "_doc" "_id" => "8" "_score" => null "_source" => array:5 [ "name" => "赵云" "age" => 28 "gender" => "男" "job" => "产品" "salary" => "5000" ] "sort" => array:1 [ 0 => 28 ] ] ] ] ] ] 2 => array:3 [ "key" => "JAVA" "doc_count" => 2 "top_job" => array:1 [ "hits" => array:3 [ "total" => array:2 [ "value" => 2 "relation" => "eq" ] "max_score" => null "hits" => array:1 [ 0 => array:6 [ "_index" => "employees" "_type" => "_doc" "_id" => "12" "_score" => null "_source" => array:5 [ "name" => "张宇" "age" => 27 "gender" => "男" "job" => "JAVA" "salary" => "4600" ] "sort" => array:1 [ 0 => 27 ] ] ] ] ] ] 3 => array:3 [ "key" => "测试" "doc_count" => 2 "top_job" => array:1 [ "hits" => array:3 [ "total" => array:2 [ "value" => 2 "relation" => "eq" ] "max_score" => null "hits" => array:1 [ 0 => array:6 [ "_index" => "employees" "_type" => "_doc" "_id" => "9" "_score" => null "_source" => array:5 [ "name" => "李雷" "age" => 27 "gender" => "男" "job" => "测试" "salary" => "3600" ] "sort" => array:1 [ 0 => 27 ] ] ] ] ] ] 4 => array:3 [ "key" => "UI" "doc_count" => 1 "top_job" => array:1 [ "hits" => array:3 [ "total" => array:2 [ "value" => 1 "relation" => "eq" ] "max_score" => null "hits" => array:1 [ 0 => array:6 [ "_index" => "employees" "_type" => "_doc" "_id" => "5" "_score" => null "_source" => array:5 [ "name" => "韩梅梅" "age" => 24 "gender" => "女" "job" => "UI" "salary" => "3500" ] "sort" => array:1 [ 0 => 24 ] ] ] ] ] ] ] ] ] ] termsterms 相当于 group by field $params = [ 'index' => 'employees', 'body' => [ 'aggs' => [ 'gorup_by_age' => [ 'terms' => [ //使用 terms 对age进行分桶操作 (group by age) 'field' => 'age' ] ] ], 'size' => 0, ], ]; $res = $client->search($params); dd($res); ---------------------------------结果---------------------------------------- array:5 [ "took" => 23 "timed_out" => false "_shards" => array:4 [ "total" => 1 "successful" => 1 "skipped" => 0 "failed" => 0 ] "hits" => array:3 [ "total" => array:2 [ "value" => 13 "relation" => "eq" ] "max_score" => null "hits" => [] ] "aggregations" => array:1 [ "gorup_by_age" => array:3 [ "doc_count_error_upper_bound" => 0 "sum_other_doc_count" => 0 "buckets" => array:9 [ 0 => array:2 [ "key" => 27 "doc_count" => 3 ] 1 => array:2 [ "key" => 24 "doc_count" => 2 ] 2 => array:2 [ "key" => 25 "doc_count" => 2 ] 3 => array:2 [ "key" => 20 "doc_count" => 1 ] 4 => array:2 [ "key" => 23 "doc_count" => 1 ] 5 => array:2 [ "key" => 26 "doc_count" => 1 ] 6 => array:2 [ "key" => 28 "doc_count" => 1 ] 7 => array:2 [ "key" => 29 "doc_count" => 1 ] 8 => array:2 [ "key" => 30 "doc_count" => 1 ] ] ] ] ] 本作品采用《CC 协议》,转载必须注明作者和本文链接 |
【本文地址】
今日新闻 |
推荐新闻 |