谷歌发布深度学习Efficient Net新架构,各方面表现全面碾压卷积神经网络 |
您所在的位置:网站首页 › effcient和effective差距 › 谷歌发布深度学习Efficient Net新架构,各方面表现全面碾压卷积神经网络 |
谷歌发布深度学习Efficient Net新架构,各方面表现全面碾压卷积神经网络
|
近期谷歌发布了新的深度学习架构Efficient Net,按照谷哥论文中的比较方法,这种架构对于传统的卷积神经网络(ConvNets),在各方面都堪称碾压。
EfficientNet-B7能够达到84.4%的精度,但它比GPipe小8.4倍,快6.1倍,Effective Net-B1比ResNet-152要小7.6倍,还快快5.7倍。不过这篇论文从另一个角度上看,其实反应了科技巨头在当下对于其它初创公司的碾压能力,下面笔者就对于这篇论文进行科普。 卷积神经网络与全连接神神经网络卷积具体的含义可以参考知乎上评分最高的回答:https://www.zhihu.com/question/22298352,这里我引用其中的一幅动态图来说明,
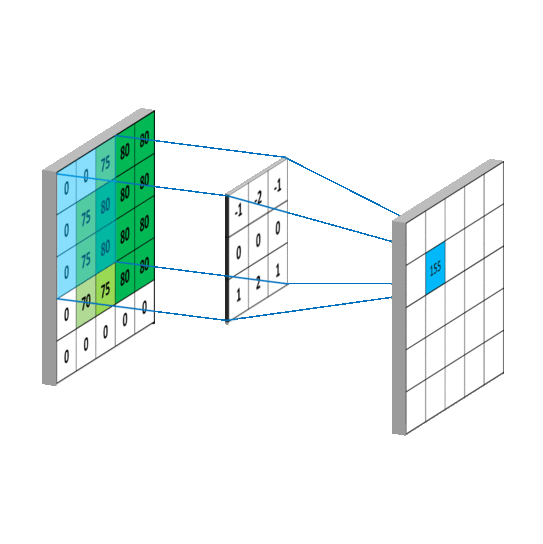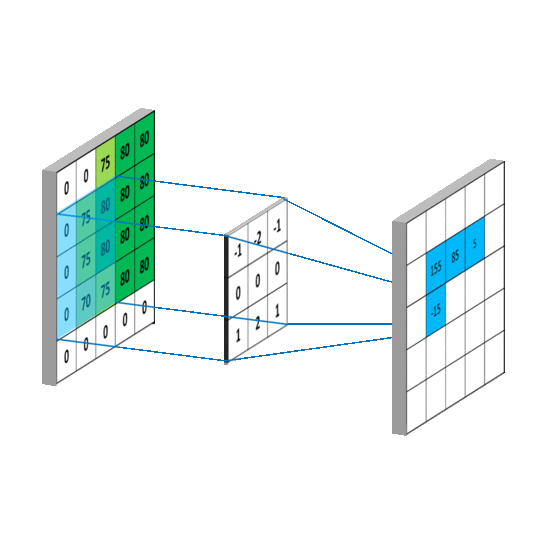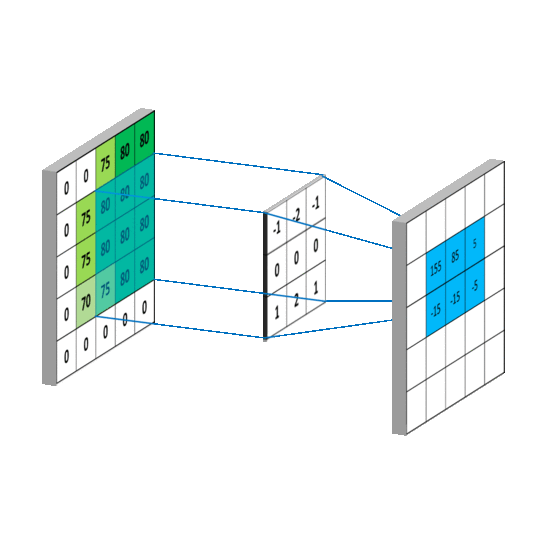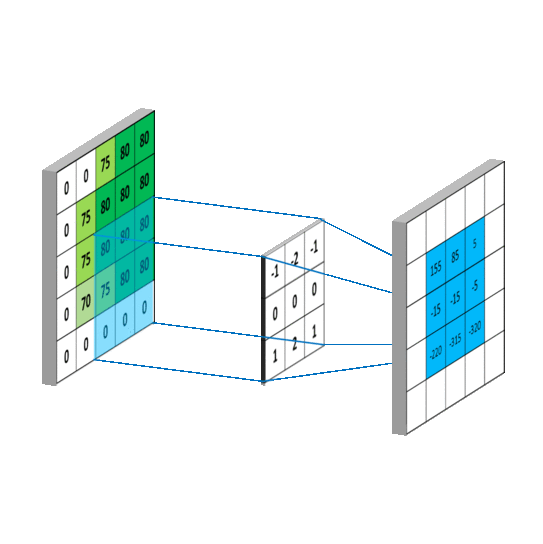
上图就是卷积的工作方式,其本身是一种积分运算,它只关注卷积核内部的数值加权求和后,放在对应位置,所以卷积本质是对输入的缩放: 那么同理卷积神经网络(ConvNets)其实也是是对于全连接(Fully Connected)神经网络的一种缩放,避免全连接所带来的计算灾难。比如下图中左边就是一个典型的全连接神经网络,隐层(hidden layer)中的每个点都相互连接,这样的后果就是不出几层计算量就会高的难以接受。而经过下图右侧卷积缩放之后可以避免这种灾难。
在之前卷积神经网络的参数调试过程中,使用者其实都是不求甚解的,效果达到一定程度后,继续调整参数成本太高。Efficient Net的作者是幸福的,谷哥给他们提供了足够的算力来求最优解。 他们提出按比例对卷积宽度/深度/分辨率各个维度来进行缩放,其原文是这样写的 “depth: d = α φ width: w = β φ resolution: r = γ φ s.t. α · β 2 · γ 2 ≈ 2 α ≥ 1,β ≥ 1,γ ≥ 1 where α,β,γ are constants that can be determined by a small grid search” 也就是用常数α,β,γ对于长宽及分辨率进行缩放,但是后面一句关键了“determined by a small grid search”,也就是α,β,γ是基于网络搜索算法的。 网络搜索算法:其实就是将所有可能的参数值全部试一遍,得到最优解的过程。简单来讲就是通过暴力枚举得到最优解,不过谷歌并没有将其它次优解的性能表现分享出来,其实这篇文章只是告诉大家我算出这题了,怎么算的你们不用关心了.....这也就是我前面所讲的这篇论文其实是体现了谷歌等巨头在算力上对小型公司的碾压,即将笔者有这样的想法,想通过我的GTX1060用网络算法解出缩放常数,至少要一两年的时间根本无法实现。 附上在文地址:https://arxiv.org/pdf/1905.11946.pdf github地址:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
|


【本文地址】
今日新闻 |
推荐新闻 |