Multimodal Fusion(多模态融合) |
您所在的位置:网站首页 › early的各种形式 › Multimodal Fusion(多模态融合) |
Multimodal Fusion(多模态融合)
|
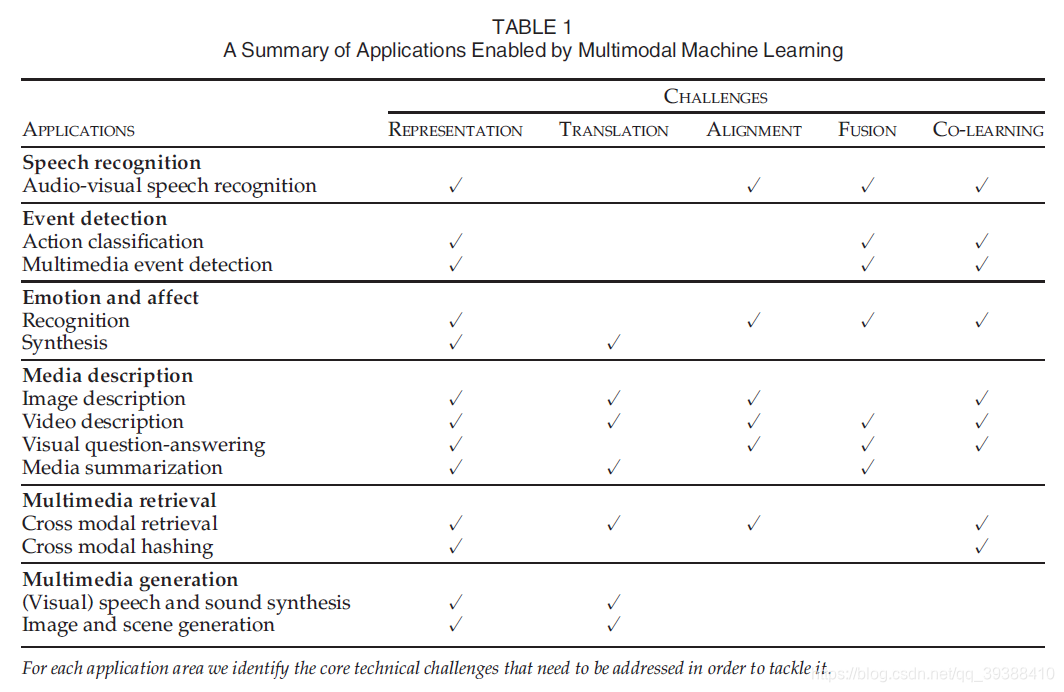
多模态学习 为了使人工智能进一步加强对我们周边事物的理解,它需要具备解释多模态信号的能力。一般多模态需要处理的任务主要如上图有: 表征(Representation)。找到某种对多模态信息的统一表示,分Coordinated representations(每个模态各自映射然后用用相关度距离来约束表示),Joint representations(多个模态一起映射)。翻译(Translation)。一个模态映射到另一个模态,分example-based(有候选集,如检索任务),generative(Decoder-Encoder)。对齐(Alignment)。找模态子成份之间的关系,如某词对应某区域。分显式对齐和隐式对齐,Attention首当其冲。融合(Fusion)。整合信息。分model-agnostic(早晚融合),model-based(融合更深入),也是本篇要整理的内容。联合学习(Co-learning)。通过利用丰富的模态的知识来辅助稀缺的模态,分parallel(如迁移学习),non-parallel(迁移学习,zero shot),hybrid。上图来自多模态综述:Multimodal Machine Learning:A Survey and Taxonomy 接下来重点介绍一些多模态融合方法。 多模态融合 (Multimodal Fusion) 一般来说,模态是指事物发生或存在的方式,多模态是指两个或者两个以上的模态的各种形式的组合。对每一种信息的来源或者形式,都可以称为一种模态(Modality),目前研究领域中主要是对图像,文本,语音三种模态的处理。之所以要对模态进行融合,是因为不同模态的表现方式不一样,看待事物的角度也会不一样,所以存在一些交叉(所以存在信息冗余),互补(所以比单特征更优秀)的现象,甚至模态间可能还存在多种不同的信息交互,如果能合理的处理多模态信息,就能得到丰富特征信息。即概括来说多模态的显著特点是: 冗余性 和 互补性 。 传统特征融合算法主要可以分为三类:1.基于贝叶斯决策理论的算法 2.基于稀疏表示理论的算法 3.基于深度学习理论算法。传统方法不做整理,其中的深度学习方法按照融合的层次从下到上每一层都可以fusion: pixel level。对原始数据最小粒度进行融合。feature level 。对抽象的特征进行融合,这也是用的最多的。包括early 和 late fusion,代表融合发生在特征抽取的早期和晚期,如上图。early是指先将特征融合后(concat、add)再输出模型,缺点是无法充分利用多个模态数据间的互补性,且存在信息冗余问题(可由PCA,AE等方法缓解)。late分融合和不融合两种形式,不融合有点像集成学习,不同模态各自得到的结果了之后再统一打分进行融合,好处是模型独立鲁棒性强。融合的方式即在特征生成过程中(如多层神经网络的中间)进行自由的融合,灵活性比较高,如金字塔融合。decision level 对决策结果进行融合,这就和集成学习很像了。hybrid。混合融合多种融合方法。
就一些详细方法上,这篇文章主要整理部分博主自己看过的paper: 基于矩阵;基于普通神经网络;基于生成模型;基于注意力;其他。如NAS,GAN,Graph等。融合矩阵和特征。shuffle和shift等不需要额外参数的方法。TFN(Multimodal Tensor Fusion Network) 首先是基于矩阵的TFN,TFN属于early fusion,是一个典型通过矩阵运算进行融合特征融合的多模态网络,即直接对三种模态的数据(如Text,Image,Audio)的三个特征向量X,Y,Z,进行: h m = [ h x 1 ] ⊗ [ h y 1 ] ⊗ [ h z 1 ] {h}_{m}=\begin{bmatrix}{{{h}_x}}\\{1}\end{bmatrix}\otimes\begin{bmatrix}{{{h}_y}}\\{1}\end{bmatrix}\otimes\begin{bmatrix}{{{h}_z}}\\{1}\end{bmatrix} hm=[hx1]⊗[hy1]⊗[hz1] 便得到了融合后的结果m,如下图: 缺点:TFN通过模态之间的张量外积(Outer product)计算不同模态的元素之间的相关性,但会极大的增加特征向量的维度,造成模型过大,难以训练。 LMF(Low-rank Multimodal Fusion) 出自论文 Efficient Low-rank Multimodal Fusion with Modality-Specific Factors,ACL2018。是TFN的等价升级版,就具体模型如图。LMF利用对权重进行低秩矩阵分解,将TFN先张量外积再FC的过程变为每个模态先单独线性变换之后再多维度点积,可以看作是多个低秩向量的结果的和,从而减少了模型中的参数数量。 缺点:虽然是TFN的升级,但一旦特征过长,仍然容易参数爆炸。 PTP (polynomialtensor pooling) 出自论文,Deep Multimodal Multilinear Fusion with High-order Polynomial Pooling,NIPS 2019. 以往的双线性或三线性池融合的能力有限,不能释放多线性融合的完全表现力和受限的交互顺序。 更重要的是,简单地同时融合特征忽略了复杂的局部相互关系。所以升级为一个多项式张量池(PTP)块,通过考虑高阶矩来集成多模态特征。即将concat的模型x N之后再做一个低秩分解。 DSSM(Deep Structured Semantic Models) DSSM是搜索领域的模型,属于late fusion。它通过用 DNN 把 Query 和 Title(换成不同的模态数据就行) 表达为低维语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测语义相似度,又可以获得某模态的低维语义向量表达。(可以将两个模态约束至统一表示空间,多模态协同表示。与之对应的多模态联合表示是先concat再FC) Dynamic Fusion for Multimodal Data 以上的融合方法都太过“生硬”,能否有更好更自然的融合方法呢?AE(autoencoder)首当其冲,如图左图,先把所有模态fc即encoder,再用decode还原特征,最后计算特征之间的损失。 有了AE,GAN的出现不会太迟。如图右图,将不采用固定的模态融合方法,而是自动学习“how”融合。先对video和speech转换完成后,和text进行对抗(video往往和speech是搭配的,所以先融合)。 MFN(Memory Fusion Network) 出自Memory Fusion Network for Multi-View Sequential Learning,AAAI 2018。 17,18年是注意力机制开始统治学术界的一年,很多工作都做了这方面的工作。MFN就是一种使用“Delta-memory attention”和“Multi-View Gated Memory”来同时捕捉时序上和模态间的交互,以得到更好的多视图融合。模型图如下,用memory的目的是能保存上一时刻的多模态交互信息,gated过滤,Attention分配权重。 淘宝视频多模态应用 淘宝视频的多模态信息也是十分丰富,而用LMF和TFN参数量往往会爆炸,就不得已要先将每个模态特征降维,然而降维本身是有损的,导致降维后的模态特征再外积不如直接利用不同模态间特征拼接。 不过不要紧,淘宝也就提出了基于Modal Attention的多模态特征融合方法。Modal Attention是用法是,预测基于concat后的多模态联合特征对不同模态的重要性分布概率,再将分布概率与多模态融合特征做点积,得到对于不同模态特征重要性重新加权过后的新的多模态融合特征。 Multi-Interactive MemoryNetwork 这篇文章同样是用了Attention,使用Aspect-guided attention机制来指导模型生成文本和图像的Attention向量。使用的是和Attention很类似的记忆网络技术,具体如下图分为Textual和Visual Memory Network,然后通过GRU+Attention的多跳融合优化特征表达。 其中的重点在于,为了捕获多模态间和单模态内的交互信息,模型又使用了Multi-interactive attention机制。即Textual和Visual在多跳的时候会相互通过Attention来融合信息(感觉很像Co-Attention的处理方法)。 Neural Machine Translation with Universal Visual Representation 补上ICLR2020的文章,这一篇是对Transformer的变形咯,不过变的比较有趣。这篇文章做的是多模态机器翻译任务,即在原来的机器翻译上融入图片信息来辅助翻译,毕竟人类的语言各异,但是认知水平是一样的,对于同一副图像描述出的语义会是一致的。 MCF(Multi-modal Circulant Fusion for Video-to-Language and Backward) 之前整理的工作要么是针对矩阵,要么是针对特征。这篇IJCAI的文章尝试同时使用vector和matrix的融合方式。 Adversarial Multimodal Representation Learning for Click-Through Rate Prediction 继续补上一篇WWW20’的阿里论文,虽然是做点击率预估,这里的融合方法非常有意思。 以往的多模态融合要么将多个模态特征串联起来,相当于给每个模态赋予固定的重要性权重;要么学习不同模态的动态权重,用于不同的项如用Attention融合比较好,但是不同模态本身会有冗余性和互补性(相同的东西和不同的东西),即需要考虑不同的模态特性和模态不变特性。使用冗余信息计算的不同模式的动态权重可能不能正确地反映每种模式的不同重要性。 为了解决这一问题,作者通过不同的考虑模态特异性和模态不变特征来考虑模态的非定性和冗余性。 Cross-modality Person re-identification with Shared-Specific Feature Transfer 继续继续补一篇新鲜的CVPR2020的文章,同样这篇文章是做行人重识别的,但是融合方法很有趣。 还是沿着上一篇博文的思路,现有的研究主要集中在通过将不同的模态嵌入到同一个特征空间中来学习共同的表达。然而,只学习共同特征意味着巨大的信息损失,降低了特征的差异性。 所以如何找不同模态间的 共性 和 个性?一方面不同模态之间的信息有互补作用,另一方面模态自己的特异性又有很强的标识功能。但是怎么把两者分开呢?即如何找到这两种表示。作者提出了一种新的跨模态共享特征转移算法(cm-SSFT):
这里所谓的正交投影的做法是,将输入的特征向量fp投影到公共特征向量fc来限制公共特征向量的模,从而使新的公共特征向量fp*的语义信息仅包含xi的公共语义信息。然后相减两者再投影,就让最后的结果不是与公共特征向量fc正交的任何平面中的任何向量了。 code:https://github.com/Qqinmaster/FP-Net/
Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion 补MM20的文章,这篇文章没有增加额外参数,而且仅在单网络下就完成了融合。首先作者指出现有多模态表示学习的两个问题: 1 现有的多模态训练方法遵循一种常见的设计实践,即单个编码器分支专门针对某个模态(即一般都是双流的操作,这样往往参数会更多,而且两者的异质性没有统一),能否单流就能解决?2 多模态融合的关键要素包括如何设计融合函数和在哪里实现融合,但不管怎么设计,现有融合方法只适用于对称特征(博主 认为这同样也是从双流的视角得到的观点)。所以作者提出的解决方案为: 私有化BN即可统一多模态的表示。由于BN层会在batch里面先激活,再与channel方向仿射参数进行转换得到偏置和方差,从这个角度来说,BN提供了可以把特征转换到任何尺度的可能性。 所以那么为什么不贡献网络参数,只私有化BN呢?这样就可以在单网络中完成多模态的表示。具体如下图,粉色的conv都是共享的,而不同模态的BN是私有的。 双向不对称fusion。用shuffle+shift的方式,以不增加参数的方式完成模态间的交互。channel shuffle操作加强了channel间的多模态特征交互,提高了整体特征表示能力,如下图a。而shift像素移位操作作为每个通道内空间方向的融合(这个其实就与上篇文章里面的circulant matrix很像了),倾向于增强空间特征识别,所以能在对象边缘捕获细粒度信息,特别是对于小目标,结构如下图b。同时,这两者都是无参数的!具体的融合方法如下图的c,在两个模态间做shuffle,同时完成不对称的shift。 Adaptive Multimodal Fusion for Facial Action Units Recognition 继续补文章。来自MM2020的文章,同样的我们也只看融合部分的做法。文章题目中 自适应 的意思是模型可以自动从模态中选取最合适的模态特征,这样可以使模型具有鲁棒性和自适应性,而这一步骤是通过采样来完成的! 即同时从三个模态的特征中进行采样。具体见图的后半段,单个模态得到特征后橫着拼接成矩阵,然后通过采样在每维上自动选取最合适的特征,并且可以通过多次采样得到更丰富的表示。不过值得注意的是,此时采样之后变成离散的了,无法进行梯度传播,所以作者借用了VAE里面重参数技巧,用Gumbel Softmax来解决了。
Attention Bottlenecks for Multimodal Fusion 好久不见,继续更新21年的文章啦。这篇文章的融合方式是在两个Transformer间使用一个shared token,从而使这个token成为不同模态的通信bottleneck以节省计算注意力的代价,如下图是四种方式示意图。 这样做可以将多模态的交互限制在若干的shared token处。 paper:https://arxiv.org/abs/2107.00135 这篇博文好像越补越多了…不过如果您有其他有关多模态融合有意思的论文,欢迎在文章后面留言。 另外,下一篇博文整理了在多模态领域中也很常见的应用领域: Cross-modal Retrieval 跨模态检索Cross-modal Video Moment Retrieval(跨模态视频时刻检索)Cross-modal Pretraining in BERT(跨模态预训练)Diversified Retrieval(多样性检索)Ad-hoc Video Search(AVS跨模态视频检索)Domain Adaptation(领域自适应,MMD,DANN)多模态信息用于推荐系统问题(MMGCN,MKGAT)Zero-Shot Image Retrieval(零样本跨模态检索)Multi-Label Image Classification(多标签图像分类)Video Caption(跨模态视频摘要生成)多模态预训练中的Prompt(MAnTiS,ActionCLIP,CPT,CoOp)多模态预训练Prompt续篇(ALPRO,Frozen)以上篇章不定期更新,更全更及时的集合请参考博主的索引: 博文目录索引 |
 Jeff Dean:我认为,2020年在多任务学习和多模态学习方面会有很大进展,解决更多的问题。我觉得那会很有趣。
Jeff Dean:我认为,2020年在多任务学习和多模态学习方面会有很大进展,解决更多的问题。我觉得那会很有趣。


 关于对矩阵的操作还有一种处理方法,就是如下图这种两两组合的方式。图出自NEURAL TENSOR NETWORK(NTN),本来是做实体关系检测的,同样也是博主觉得觉得这种方法也挺有意思的。这个小模块的大致的思路就是,让我们把APO都各自看成三个模态吧,然后两两组合得到矩阵T1,T2,再继续组合最后得到U这个融合/预测的结果。
关于对矩阵的操作还有一种处理方法,就是如下图这种两两组合的方式。图出自NEURAL TENSOR NETWORK(NTN),本来是做实体关系检测的,同样也是博主觉得觉得这种方法也挺有意思的。这个小模块的大致的思路就是,让我们把APO都各自看成三个模态吧,然后两两组合得到矩阵T1,T2,再继续组合最后得到U这个融合/预测的结果。  深度学习浪潮来袭后,可以在一定程度上缓解矩阵方法的缺点。
深度学习浪潮来袭后,可以在一定程度上缓解矩阵方法的缺点。 其他玩法:可以在DNN的过程中,用recurrent residual fusion (RRF) ,多个残差,然后将3次recurrent的结果与最开始的输入concat起来,最后将concat得到的结果做融合。
其他玩法:可以在DNN的过程中,用recurrent residual fusion (RRF) ,多个残差,然后将3次recurrent的结果与最开始的输入concat起来,最后将concat得到的结果做融合。 另外在CVPR2019,有一篇–MFAS:Multimodal Fusion Architecture Search,首次用神经架构搜索做how融合。
另外在CVPR2019,有一篇–MFAS:Multimodal Fusion Architecture Search,首次用神经架构搜索做how融合。
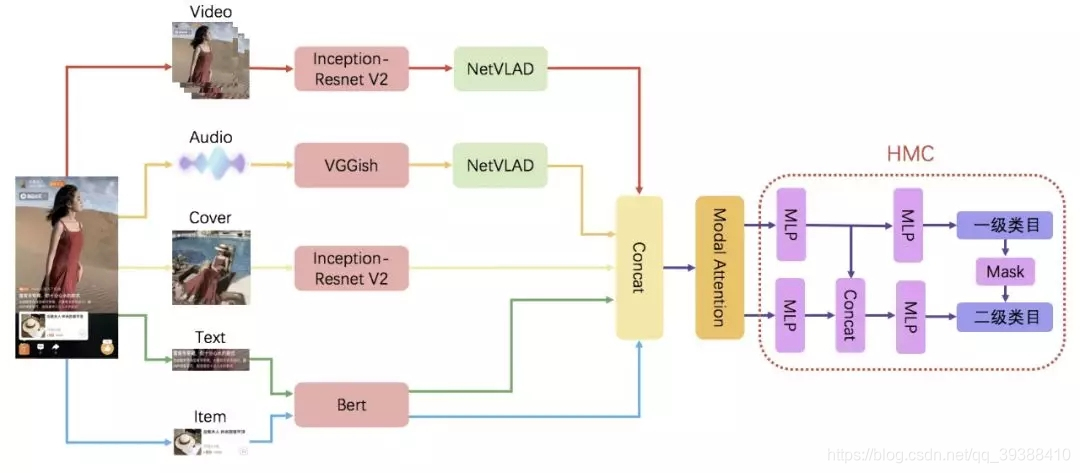 最后还想提一下的是一般的分类任务都只有单一的目标,而淘宝的标签体系是结构化分层的,所以他们在后面做了HMC(分层多标签分类器)用基于类别不匹配的多目标损失函数,即损失函数由一级类别,二级类别,一二级类别不匹配损失三个部分组成。
最后还想提一下的是一般的分类任务都只有单一的目标,而淘宝的标签体系是结构化分层的,所以他们在后面做了HMC(分层多标签分类器)用基于类别不匹配的多目标损失函数,即损失函数由一级类别,二级类别,一二级类别不匹配损失三个部分组成。 其他玩法:不止是Co-Attention咯,就把Attention的其他各种变体一直到Transformer,BERT系列,各种预训练模型再应用一遍。。。不过这个属于专门的多模态预训练了在另一篇文章有整理:传送门。
其他玩法:不止是Co-Attention咯,就把Attention的其他各种变体一直到Transformer,BERT系列,各种预训练模型再应用一遍。。。不过这个属于专门的多模态预训练了在另一篇文章有整理:传送门。 做法比较干脆利落,在Transformer的Dncoder端把图片的表示也输入进去(即上图中中间那个部分),意思应该是以句子编码为Q(图中的表示是H),然后图像的特征为K和V,即在图像中找语义相似的部分做Attention的fusion,最后一起送到Decoder端做翻译。
做法比较干脆利落,在Transformer的Dncoder端把图片的表示也输入进去(即上图中中间那个部分),意思应该是以句子编码为Q(图中的表示是H),然后图像的特征为K和V,即在图像中找语义相似的部分做Attention的fusion,最后一起送到Decoder端做翻译。 这篇文章最关键的点在于circulant matrix,具体的操作方式其实就是vector的每一行都平移一个元素得到matrix,这样以探索不同模态向量的所有可能交互。简单来说以V和C为视觉和文本特征,则有:
A
=
c
i
r
c
(
V
)
A=circ(V)
A=circ(V)
B
=
c
i
r
c
(
C
)
B=circ(C)
B=circ(C)得到矩阵之后再结合原特征做交互即可
G
=
1
d
∑
i
=
1
d
a
i
⋅
C
G=\frac{1}{d}\sum^d_{i=1}a_i\cdot C
G=d1i=1∑dai⋅C
F
=
1
d
∑
i
=
1
d
b
i
⋅
V
F=\frac{1}{d}\sum^d_{i=1}b_i\cdot V
F=d1i=1∑dbi⋅V
这篇文章最关键的点在于circulant matrix,具体的操作方式其实就是vector的每一行都平移一个元素得到matrix,这样以探索不同模态向量的所有可能交互。简单来说以V和C为视觉和文本特征,则有:
A
=
c
i
r
c
(
V
)
A=circ(V)
A=circ(V)
B
=
c
i
r
c
(
C
)
B=circ(C)
B=circ(C)得到矩阵之后再结合原特征做交互即可
G
=
1
d
∑
i
=
1
d
a
i
⋅
C
G=\frac{1}{d}\sum^d_{i=1}a_i\cdot C
G=d1i=1∑dai⋅C
F
=
1
d
∑
i
=
1
d
b
i
⋅
V
F=\frac{1}{d}\sum^d_{i=1}b_i\cdot V
F=d1i=1∑dbi⋅V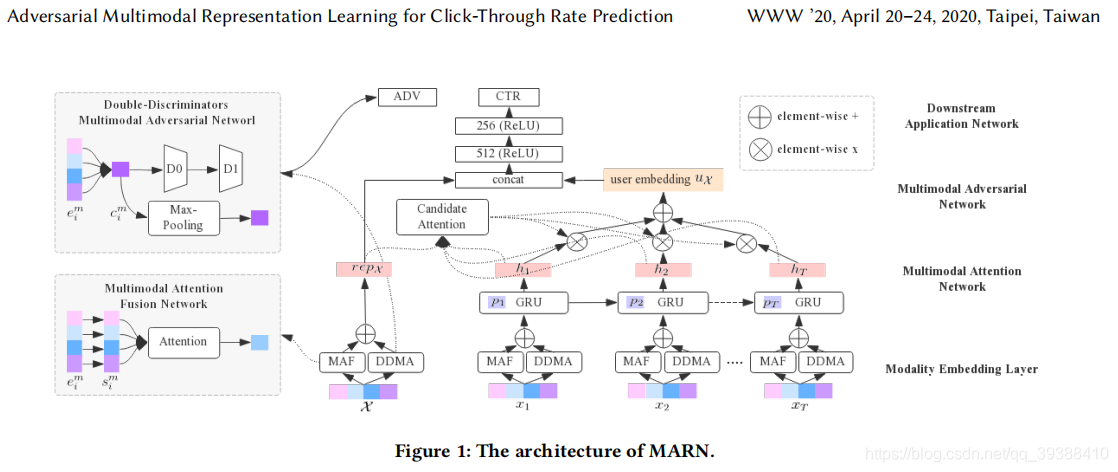 所以在多模态融合(普通的Attention融合,即图中的MAF)旁边加上一个双判别器对抗网络(即图中的DDMA),即分别捕捉动态共性,和不变性。DDMA如下图:
所以在多模态融合(普通的Attention融合,即图中的MAF)旁边加上一个双判别器对抗网络(即图中的DDMA),即分别捕捉动态共性,和不变性。DDMA如下图:  双判别器是为了挖掘:
双判别器是为了挖掘: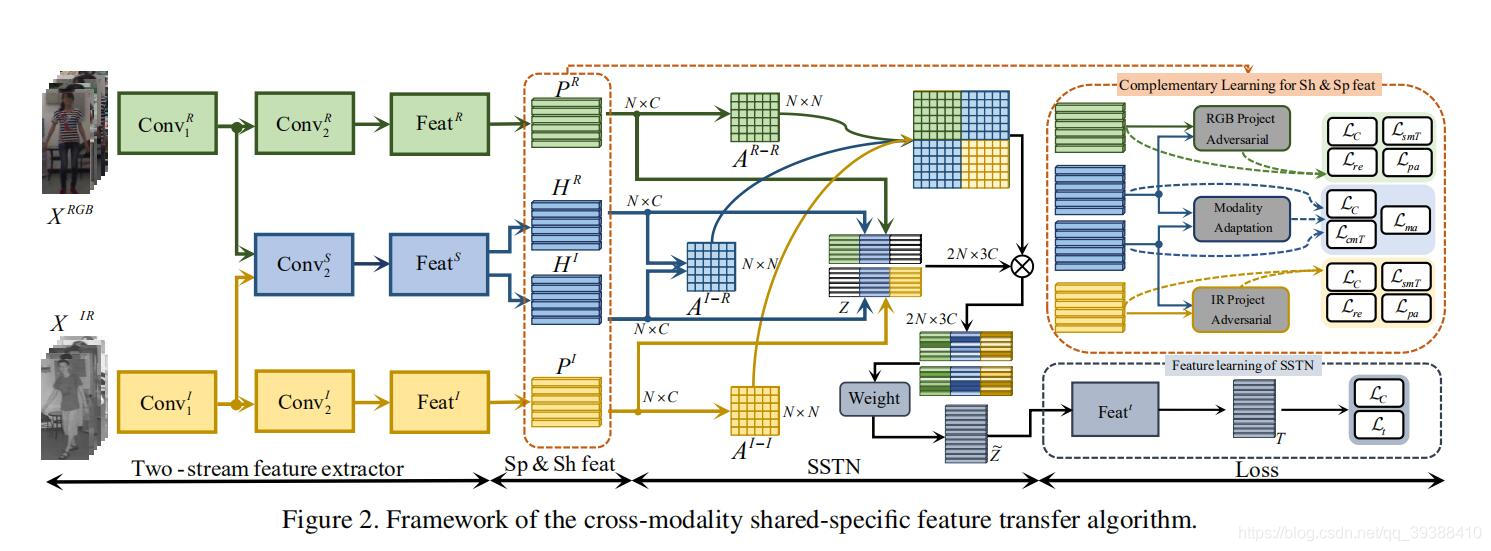 (注:RGB图和红外IR图是两种模态)
(注:RGB图和红外IR图是两种模态) Feature Projection for Improved Text Classification. 共性和个性的文章还有这一篇,ACL 2020。基础思路是用特征投影来改善文本分类。直接看模型有两个网络,分别是projection network (P-net)和common feature learning network (C-net)。
Feature Projection for Improved Text Classification. 共性和个性的文章还有这一篇,ACL 2020。基础思路是用特征投影来改善文本分类。直接看模型有两个网络,分别是projection network (P-net)和common feature learning network (C-net)。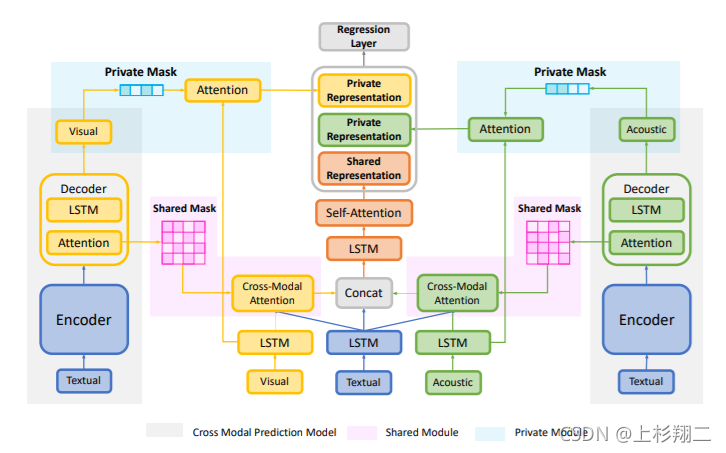 [ACL2021] A Text-Centered Shared-Private Framework via Cross-Modal Prediction for Multimodal Sentiment Analysis 继续补挖掘共性和个性的文章,来自ACL21。这篇文章的任务是情感分析。首先作者认为在这个任务中,并不是所有模态都同等重要,即1文本在这个任务中更重要。因此2其他模态只是提供辅助信息,且可以被分为共享语义和私有语义。模型框架如上图,具体实现是通过掩码矩阵完成的。掩码矩阵的具体做法如下图,即1展开特征的每一维,可以利用注意力计算一些上下文权重,2卡阈值大的作为共享语义(图2中的卡了大于0.2),3所有维计算完毕后得到图3的结果作为共享掩码矩阵即可。而个性掩码矩阵是没有连上边的部分,数据模态独有的信息。
[ACL2021] A Text-Centered Shared-Private Framework via Cross-Modal Prediction for Multimodal Sentiment Analysis 继续补挖掘共性和个性的文章,来自ACL21。这篇文章的任务是情感分析。首先作者认为在这个任务中,并不是所有模态都同等重要,即1文本在这个任务中更重要。因此2其他模态只是提供辅助信息,且可以被分为共享语义和私有语义。模型框架如上图,具体实现是通过掩码矩阵完成的。掩码矩阵的具体做法如下图,即1展开特征的每一维,可以利用注意力计算一些上下文权重,2卡阈值大的作为共享语义(图2中的卡了大于0.2),3所有维计算完毕后得到图3的结果作为共享掩码矩阵即可。而个性掩码矩阵是没有连上边的部分,数据模态独有的信息。  之后再利用掩码矩阵来算各种注意力。在Transformer架构的后面concat共享语义和两种私有语义即可以。
之后再利用掩码矩阵来算各种注意力。在Transformer架构的后面concat共享语义和两种私有语义即可以。


【本文地址】
今日新闻 |
推荐新闻 |