谷歌|基于大型语言模型的语义解析方法 |
您所在的位置:网站首页 › dynamic各种词性 › 谷歌|基于大型语言模型的语义解析方法 |
谷歌|基于大型语言模型的语义解析方法
|
人类在遇到新任务时可以进行组合推理。以前的研究表明,适当的提示技术使大型语言模型(LLMs)能够解决诸多任务。在这项工作中,我们确定了在具有更大词汇量的更现实的语义解析任务中的挑战,并完善通过完善 prompt 技术以解决这些问题。 我们提出的方法是 dynamic least-to-most prompting:它首先基于树结构问题进行分解,然后使用候选池来选择适当的示例,并依次生成语义解析。这种方法使我们能够成为语义解析任务的 SOTA,同时只需要传统方法所使用的 1% 的训练数据。由于我们方法的普遍性,我们预计类似的努力将在其他任务和领域中带来新的结果,特别是对于知识密集型的应用。
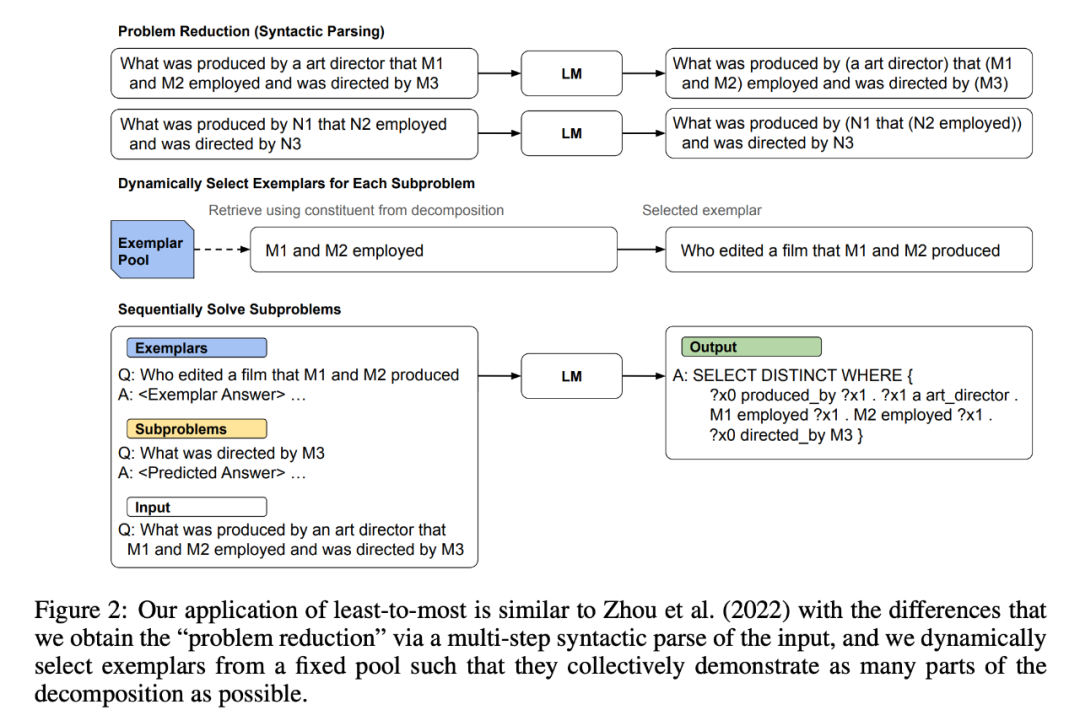
论文标题:Compositional Semantic Parsing with Large Language Models 论文链接:https://arxiv.org/pdf/2209.15003.pdf 组合性是人类智慧的关键部分,因为它使我们能够理解和产生可能无限数量的已知组件的新颖组合。相比之下,标准神经序列模型、transformer 和递归神经网络通常无法捕获问题域的组成结构,因此无法在组成上进行概括。先前改进组合泛化的工作主要依赖于专门的架构或训练程序。尽管有效,但这些可能是针对特定任务的。 另一方面,由于 prompt 方法足够灵活,并且随着最近大规模预训练语言模型 (LLM) 的进步,prompt 已成为解决广泛 NLU 问题的有效且通用的方法 。在许多情况下,prompt 现在的性能与模型微调后的性能相当或更好(Wei 等人,2022b;Chowdhery 等人,2022;Wei 等人,2022a;Kojima 等人,2022;Ahn 等人,2022) ,并且可能适用于提高语言模型在组合泛化方面的性能。 特别是,最近的工作发现,从 least-to-most prompting(最少到最多的提示)显示了将 LLM 用于组合泛化的很大潜力,在 SCAN(一种常用的组合泛化基准任务)上实现了 99.7% 的准确率。 其中 least-to-most prompting 将每个问题分解为一系列子问题,然后依次解决一个接一个。当将 Least-to-most prompting 应用于更现实的语义解析基准时,会出现其他挑战。除其他外,他们可能需要的信息超出了单个提示中的范围。此外,分解问题比使用 SCAN 更困难,无法独立于其上下文进行翻译的成分加剧了这一问题。 基于此,作者设计了 dynamic least-to-most prompting 来应对这些挑战,这是对该方法的通用细化,涉及以下步骤:1)通过大规模语言模型通过语法解析对自然语言的输入(query)进行树结构分解;2)使用基于分解的示例动态选择策略,以及 3)将分解树线性化,并提示模型按顺序生成子问题的答案。 挑战 作者提出了以下三种挑战: 1. 分解挑战:简单来讲,传统的语义解析对于语句的分解类似于具有标准算术运算的数学表达式,或使用简单的 prompting 的语言模型来进行预测。然而真实场景句法分析代表了更丰富的自然语言子集,这意味着各种组件及其交互涉及语法特征,例如不同的词性、语法语音、连词和代词。这使得分解更具挑战性,因为它需要深入理解底层语言结构; 2. 单一的 prompt 不足以表示完整的标签空间:句法分析数据集 CFQ 中使用了 50 多种不同的 Freebase 类型和关系,我们不能期望模型在没有看到示例中使用的情况下就知道这些关系的名称。同样,COGS 使用了数百个动词,仅用单一的 prompt 很难覆盖整个数据集的庞大细节; 3. 依赖于上下文:例如 在进行无语境时翻译,翻译"走两步"--“WALK TWICE”,它总是被翻译成 "WALK WALK",很可能之前的上下文中包含了相应的信息而模型未能捕获,这也同样说明了上下文的重要性。 方法 在本节中,我们将介绍 dynamic least-to-most prompying,它是 least-to-most 提示的扩展,它使我们能够克服上述挑战,从而将 least-to-most 提示应用于更现实的自然语言任务。模型图如下:
作者提出以下三种方法: 使用基于 LM 的语法解析进行分解:我们使用一系列 prompt 来教授语言模型对所有可能的输入句子进行语法解析。本文使用基于树的分解(即标注词性后分解),它可以遍历所有的句法分解。而不是通过传统的 dynamic least-to-most prompting 获得的线性分解(问题分解子问题)。
2. 基于分解示例的动态选择:我们采样了 train 的一小部分(1000条),作为候选者池。对于要处理的每个新输入句,我们从这个池中动态选择示例,以便它们集体展示翻译输入句子所需的相关知识。这是通过将输入的分解树与候选示例的分解树匹配来完成的。(为每个问题从池子里构建候选 prompting)。 3. 基于分解的连续解:我们使用输入句子的基于树的分解来生成其他相关更简单句子的线性序列。然后,我们构建一个包含动态选择示例的提示,并在生成最终输出之前使用它来连续预测更简单句子的解决方案。(将子问题,候选池拼接,进行语义解析)。
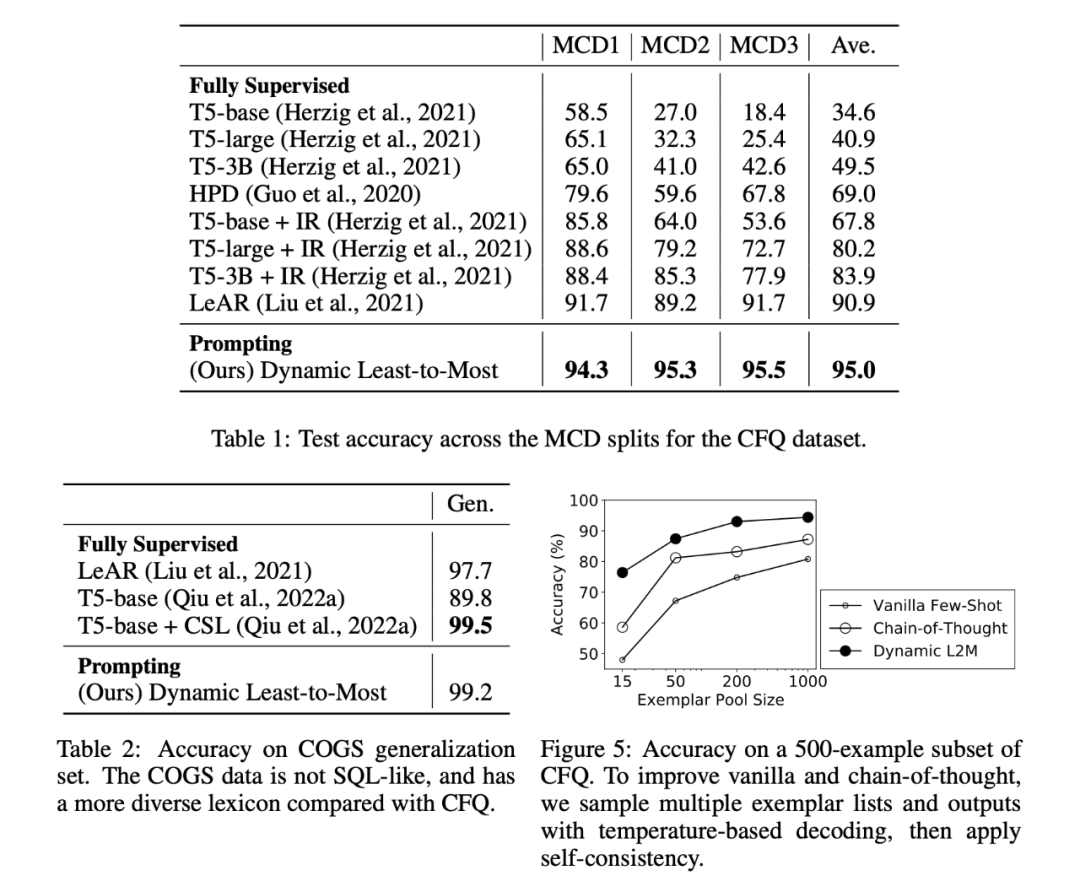
数据集:语义解析数据集 CFQ(Keysers 等人,2020 年)并且有三个最大分裂集(MCD1,MCD2,MCD3),用于测量成分泛化,每个分裂集的 train/valid/test 分裂中都有 95743/11968/11968 sentences。COGS(Kim 和 Linzen,2020 年)在 train/valid/test 中有 24155/3000/21000 句话。 候选池:对于每个 CFQ 拆分,我们采样了 1000 个训练示例,用作潜在示例(约占训练数据的 1%)。对于 COGS,我们手动选择了 89 个 train 示例作为潜在示例(约占培训数据的 0.4%)。 Metri:我们使用精确匹配(EM)来衡量准确性。这是作为 groundtruth 和 predict 之间的精确字符串匹配计算的。为了使该指标对 CFQ 具有可解释性,我们对输出应用规范化,包括对属性进行排序和应用确定性参数排序。 实验 本文并没有是用全监督的设置,即直接使用 prompt 提示预训练的模型,放弃微调阶段。因为存在候选池,所以约使用 1% 的训练数据,而其他方法均是全监督。
|



【本文地址】
今日新闻 |
推荐新闻 |